大家好,我是 Jack。
因 ChatGPT、Stable Diffusion 让 AI 在文本、图像生成领域火出了圈。
但 AI 在生成方面的能力,可不仅如此,音频领域也出现了很多优秀的项目。
我用我本人的音频数据,训练了一个 AI 模型,生成了几段歌曲,效果已经在我最新一期的视频中展示了,感兴趣的可以看下:
https://www.bilibili.com/video/BV1x24y147yq
视频、教程制作不易,跪求三连支持,一个免费的赞也行~
勿用技术做恶,必须放在第一个来说。
请勿用该技术从事诈骗等违法行为,请遵守《互联网信息服务深度合成管理规定》等法律法规。
本教程仅供交流学习使用,同时,本人也不提供任何人的训练好的音频模型。
视频里所使用的技术是 so-vits-svc,是音频转音频,属于音色转换算法,支持正常的说话,也支持歌声的音色转换。
项目不提供任何人的音频训练模型,所以想要体验,必须先自己训练模型。
显卡建议使用 N 卡,且显存 8G 以上,我的显卡是 RTX 2060 S,训练自己的模型大概用了 14 个小时。
训练数据很关键,需要准备至少 1 个小时的音频,越多高质量的音频数据,效果越好。
比如我的本次训练,就是使用了我往期视频的音频数据,数据时长 1 个小时。
我家里的电脑是 Windows,所以本教程以 Windows 为例进行讲解。
我将项目所需要的代码、环境、工具,进行了打包,可以一键运行:
下载地址(网盘提取码:qi2p):
https://pan.baidu.com/s/1Jm-p_DZ2IVcNkkOYVULerg?pwd=qi2p
当然,也可以直接用作者开源的代码直接部署:
https://github.com/StarStringStudio/so-vits-svc
本项目不支持文本转音频,如果需要文本转音频,可以移步看看这个:
https://github.com/jaywalnut310/vits
训练数据、还有预测推理的数据,都必须是人物的干声。
也就是说,不能包括背景音、伴奏、合声等,所以无论是训练和预测,都需要对数据进行处理。
这里用到的工具是 UVR5,我提供的整合包里包含了这个工具。
在 Windows 下可以直接使用,打开软件,按照如下配置:
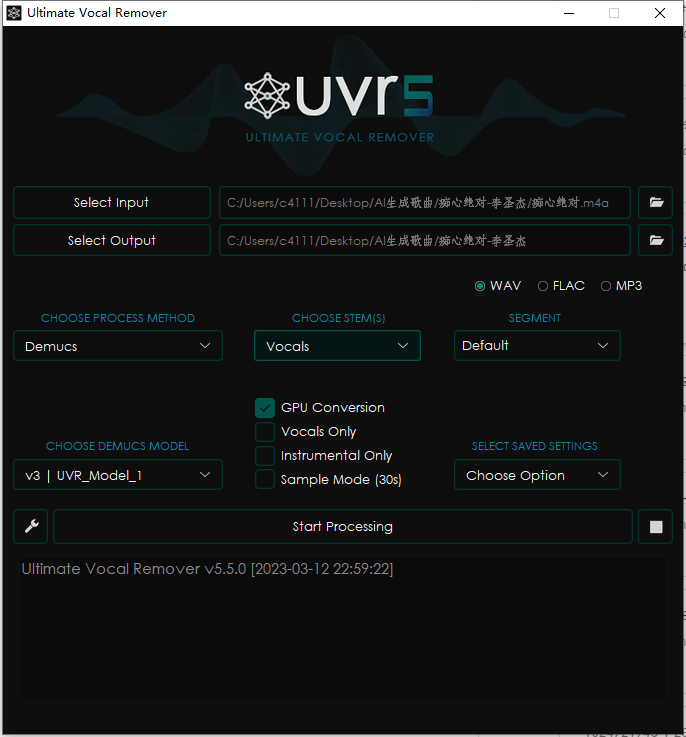
运行即可分离人声和伴奏:

然后再按照如下配置,去除合声:
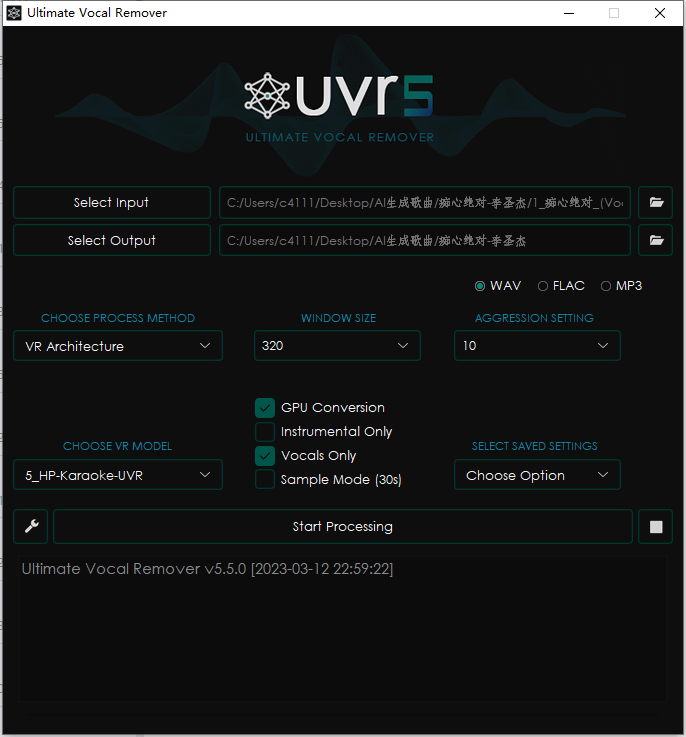
有 Vocals_Vocals 后缀的音频就是处理后的,这个音频就可以用来训练。

不过因为音频太长,很容易爆显存,可以对音频文件进行切片,这个整合包里也提供了饮品切分工具 Audio Slicer,直接运行 slicer-gui.exe。
填写输入路径,填写输出路径,其它参数都默认即可,这样你就会得到切分好的音频段。
在项目的 so-vits-svc-4.0/dataset_raw 目录下创建一个文件夹,比如我的是 jackcui_processed,将处理好的数据放到里面:
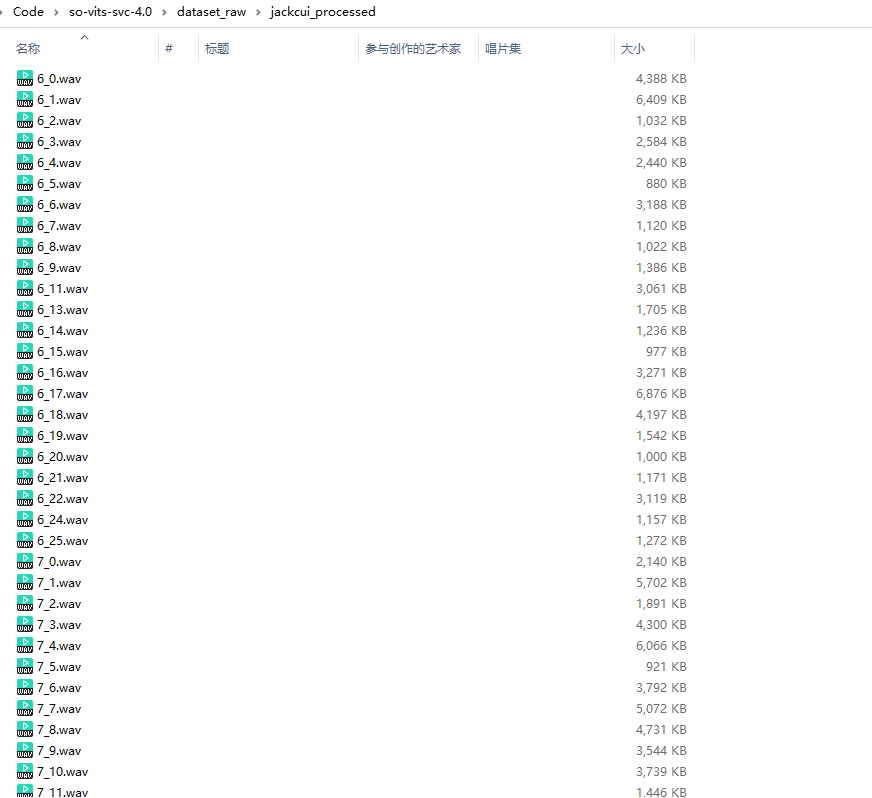
这样数据的准备工作,手动配置的部分就完成了。
接下来可以直接运行我提供的整合包里的脚本 1、数据预处理.bat。
这个脚本就是按照步骤,运行各个 py 脚本:
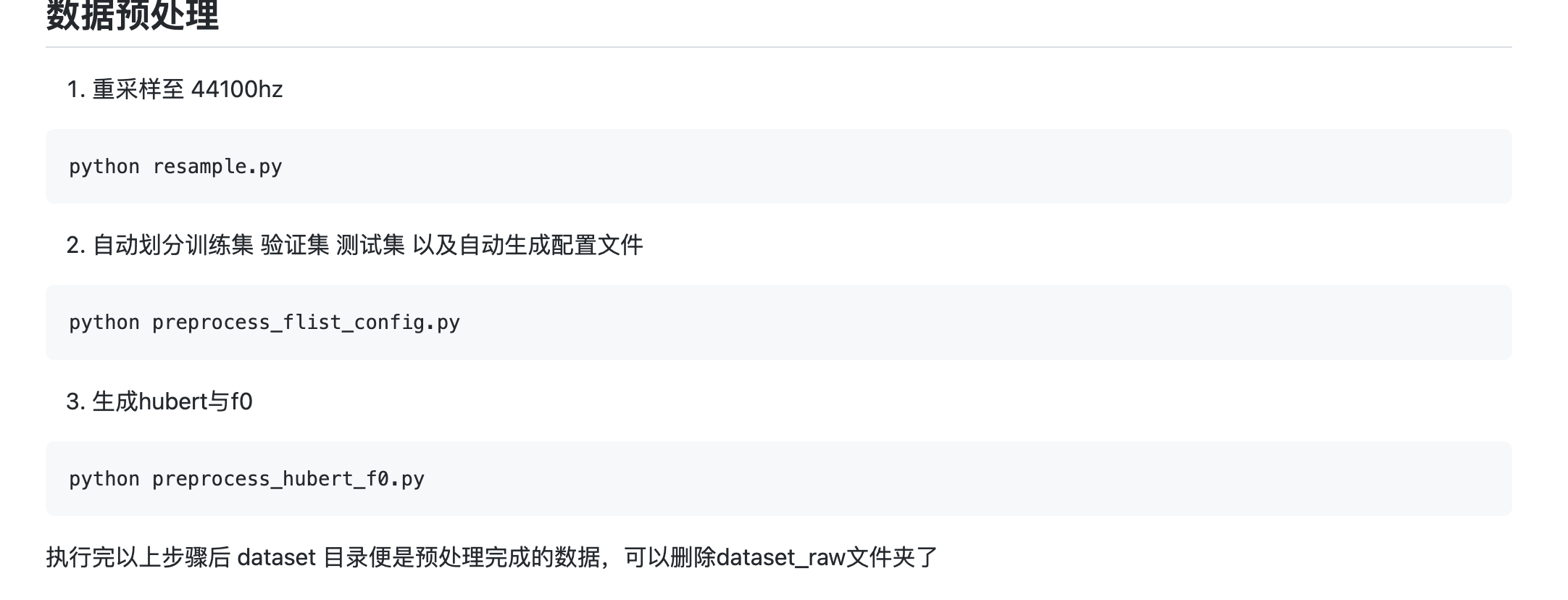
大约跑个几分钟,就能处理完成,处理完毕后,会在 datset/44k 下生成一个文件夹,里面的数据如下图所示:
直接运行 2、训练.bat 即可开启训练。
如果你的显卡够好,可以增加 batch_size 提高训练速度,对应的配置文件在 configs/config.json 文件里。
这个训练时间很长,大概需要几个小时的时间。
推理预测同理,新运行 3、训练聚类模型.bat 生成数据 pt 文件。几分钟即可跑完。
然后修改 app.py 里的这一行:
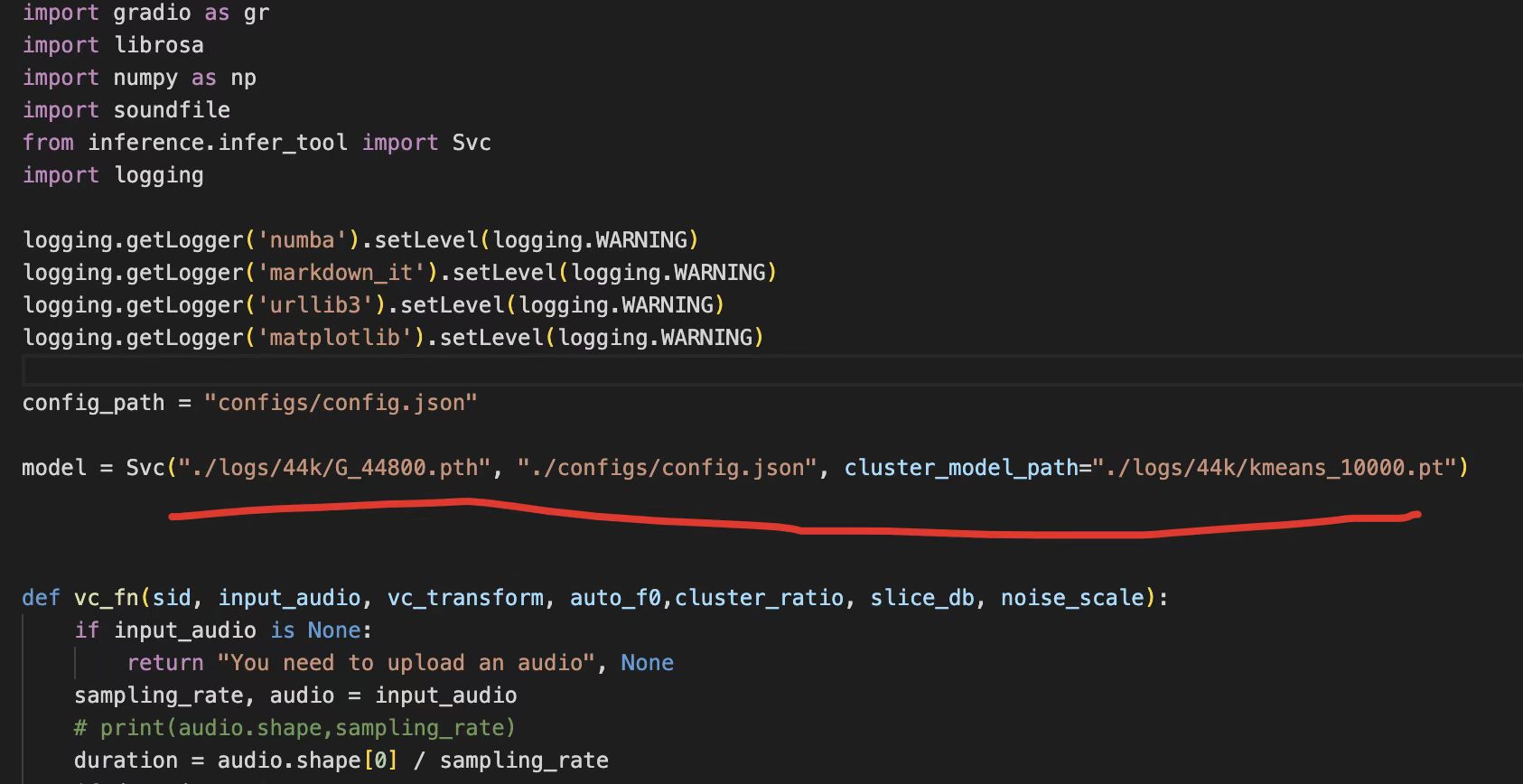
训练好的模型存放在了 logs/44k 目录下,这里改为你训练好的模型地址,以及对应的配置文件,最后是第三步生成的 pt 文件路径。
记住这里 app.py 必须改好,否则第四步会报错。
最后运行 4、推理预测.bat 文件。
程序会直接开启一个 webui,将开启的 url,直接复制到浏览器地址栏中打开即可。
就是一个简单的 Web 页面,里面的参数,可以直接使用默认的,放入一个音频,即可转换音色,很简单,这里就不展示了。
确认流程都跑通后,可以试着调整一些参数,个人影响太大,主要还是看训练数据,也就是用软件分离的干声质量。
最后也再强调一下,请勿用技术做恶!
我的训练数据,只用了往期视频的音频文件,数据丰富度很差,都是叙事的语调,缺少高低音的歌唱数据。
所以效果上,高低起伏的变化少了,听起来就是,全是技巧,莫得感情。
但是如果用于普通对话的音色转换,绝对是够用了。
视频结尾也展示了一个惊艳一些的效果,歌手的数据就丰富很多了,所以效果更好。
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
相信很多人在录制视频的时候都会遇到各种各样的问题,比如录制的视频没有声音。屏幕录制为什么没声音?今天小编就和大家分享一下如何录制音画同步视频的具体操作方法。如果你有录制的视频没有声音,你可以试试这个方法。 一、检查是否打开电脑系统声音相信很多小伙伴在录制视频后会发现录制的视频没有声音,屏幕录制为什么没声音?如果当时没有打开音频录制,则录制好的视频是没有声音的。因此,建议在录制前进行检查。屏幕上没有声音,很可能是因为你的电脑系统的声音被禁止了。您只需打开电脑系统的声音,即可录制音频和图画同步视频。操作方法:步骤1:点击电脑屏幕右下侧的“小喇叭”图案,在上方的选项中,选择“声音”。 步骤2:在“声
我最近开始从事一个项目,该项目使用git进行存储并使用ruby作为前端。我的脚本的第一个版本使用了ruby-git,虽然非常简单,但还不错。当我需要对我的提交和日志做更具体的工作时,建议我转向砂砾。然而,我在早期遇到了障碍——grit似乎无法克隆远程存储库。我发现使用Repository类的所有示例都创建了一个本地存储库并搜索了我发现Grit的clone方法未定义的源代码。给了什么?这是我的第一个StackOverflow问题,在此先感谢您的帮助。 最佳答案 由于Git结构良好,Grit使用缺少的方法(Grit::Git#m
我的Ruby代码中有一个看起来有点像这样的结构Parameter=Struct.new(:name,:id,:default_value,:minimum,:maximum)稍后,我使用创建了这个结构的一个实例freq=Parameter.new('frequency',15,1000.0,20.0,20000.0)在某些时候,我需要这个结构的精确副本,所以我调用newFreq=freq.clone然后,我更改newFreq的名称newFreq.name.sub!('f','newF')奇迹般地,它也改变了freq.name!像newFreq.name='newFrequency'这样
我要遍历一棵树。当我遍历它时,我保留了一堆枚举器,其中每个枚举器都用于枚举树的子级。我希望能够复制这个枚举器堆栈并将其交给另一个对象,以便它可以从堆栈状态指示的位置开始遍历树。当我尝试调用Enumerator上的#dup时,出现错误。是否可以复制枚举器?如果没有,我怎么能完成同样的事情?(我考虑过将一堆整数作为索引,但担心效率。这里有一些代码来展示我所看到的...一旦第一个枚举器启动,您就无法复制它。这就是我的情况。a=[1,2,3].each=>#a.next=>1b=a.dupTypeError:can'tcopyexecutioncontextfrom(irb):3:in`ini
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭6年前。Improvethisquestion是否有任何用Ruby或Python编写的生产就绪的开源Twitter克隆?我对功能丰富的实现更感兴趣,而不仅仅是简单的Twitter消息(例如:API、FBconnect、通知等)谢谢!
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭11年前。在哪里可以找到python的中期或长期路线图。借此,我可以了解决策者最关心的是什么,以及他们眼中这门语言的future是什么?一段时间以来,我一直在玩弄Python和Ruby,制作我在开发中需要的中小型工具,通过比较不同但相似的语言来获得乐趣和学习。Python和Ruby的许多特性可以互换,或者易于模仿。两者都引入了一些函数式风格并且发展迅速(Py300
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
这是2009年,早在2001年左右,ruby中的声音播放就没有好的绑定(bind)。有变化吗?我正在寻找可以控制原始声音或mp3、ogg和flac播放的东西。我的谷歌搜索已经枯竭。编辑:Linux、OSX,如果可能的话还有Windows。 最佳答案 您没有提到平台。Thispage描述了win32-sound库,它似乎至少支持WAV播放。对于一个更加平台中立的方式,Ruby/SDL为广受欢迎的SDL提供绑定(bind)图书馆。 关于ruby声音播放,我们在StackOverflow上找到