文献:A survey on computation offloading modeling for edge computing
边缘计算:在网络边缘、代表云服务的下游数据和代表物联网服务的上游数据上执行计算。
优势:
计算或云计算包括:与本地计算相比,EC可以克服终端设备(ED)有限计算能力的限制。与向远程云卸载计算相比,EC可以避免将某些任务卸载到远程云导致的高延迟。
计算卸载将计算任务卸载到EC,由传输过程、远程执行过程和结果发回过程组成。
关键因素:任务分区、卸载决策、资源分配(计算资源、通信资源和能量)。
卸载目标:找到最佳解决方案(怎么划分任务、分配资源)
Mobile edge computing: A survey.强调了MEC相关的研究和未来方向。
A survey on computation offloading for mobile edge computing information简要讨论了一些卸载算法,根据不同的目标对其进行分类,如执行延迟最小化、能耗最小化以及能耗和执行延迟之间的权衡。
两层架构使EC能够单独处理计算任务,而在三层架构中,EC作为云计算的补充。
1)两层架构/框架ED-EC
EC框架:MAUI——ULOOF——ETSI MEC(移动边缘系统级、移动边缘主机级和网络级)
2)三层架构/框架ED-EC-Cloud
3)特定应用程序的体系结构/框架
Stack4things as a fog computing platform for smart city applications
Stack4Things EC平台为用户提供基于云的虚拟化网络、情境化和智能城市应用程序的复杂事件处理。
Evaluation of docker as edge computing platform.
评估了Docker作为EC平台时的性能。作者评估了资源和服务管理、容错和缓存等功能。他们认为Docker在基于VM的EC平台上提供了快速部署、弹性和良好性能。
4)讨论
双层体系结构在边缘处理所有任务,因此它适用于时间敏感的应用程序。
三层架构适用于同时具有时间敏感任务和计算密集型任务的应用程序。时间敏感任务在边缘处理,计算密集型任务在云上执行。
Serverless computing: Current trends and open problems
无服务器计算是指构建和运行不需要服务器管理的应用程序的概念。
1)从EDs到EC的卸载;
ED在本地执行计算任务或将其卸载到EC。
2) 从EC卸载到云计算;
EC被认为是云计算的补充。ED总是将其任务发送到附近的EC服务器,该服务器决定是自己执行接收到的任务还是将其卸载到云。
EC处理延迟敏感的任务;云处理延迟容忍的任务。
3) 从一个EC服务器卸载到另一个(其他);
当一个EC服务器接收到计算任务时,它决定在本地执行该任务或将其卸载到同一集群内的其他EC服务器。
4) 分层卸载。
任务可以卸载到不同层,如果任务是可分割的,它可以分为四部分:一部分用于本地执行,一部分用于EC,一部分为云,最后一部分被拒绝。
1)一对一场景;
一个ED和一个EC服务器组成的系统。
2)一对多场景;
一个ED和多个EC服务器,ED决定是否卸载,并决定应将任务卸载到哪个服务器。
3)多对一场景;
多个ED和一个EC服务器。多个ED将其任务卸载到一台服务器。
4)多对多场景的卸载。
分布式方法更适合解决多对多卸载问题。
集中式建模方法适用于一对一或一对多卸载场景,而分布式建模适用于多对一或多对多场景。
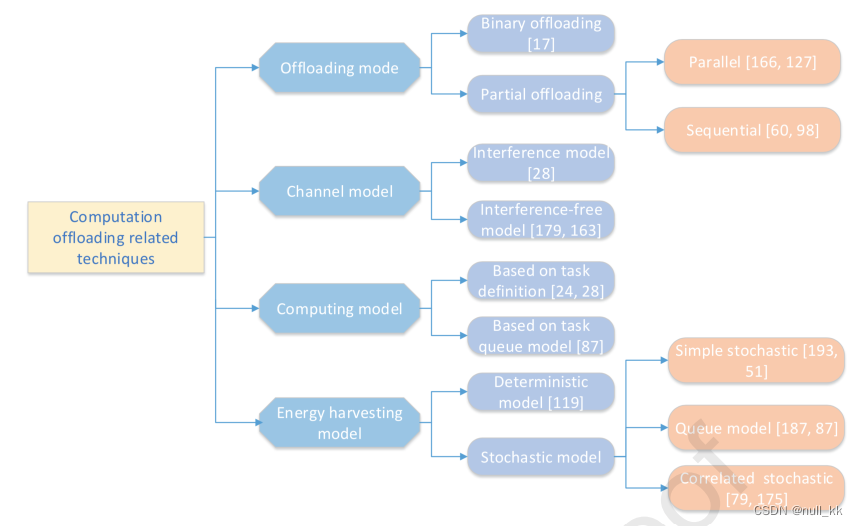
卸载模式:二进制卸载、部分卸载(并行、顺序)
信道模型:干扰模型、无干扰模型
计算模型:延迟、能耗
能量收集模型:确定性、随机性
二进制模式:任务的数据集必须作为一个整体在EC服务器上本地或远程执行。适用于无法分区的简单任务。
使用穷举搜索可以解决二进制卸载问题,N个终端设备的决策数量为2^N。为了降低计算复杂性,采用一些优化算法或方法。
部分卸载模式:允许任务分区。任务被划分为几个组件,这些组件被卸载到EC服务器,或者一些组件在本地执行。适用于由多个并行段组成的一些复杂任务。
可分区任务:面向数据分区的任务、面向代码分区的任务和连续执行任务。
在卸载模型中,这些任务分为两类:并行或顺序。
并行执行的组件:卸载策略只需要决定将组件放置在何处。
顺序执行的组件:组件之间存在依赖关系,需要定义组件的位置及其调度。分量之间依赖关系用有向无环图描述。
优化目标:找到最佳卸载比率,即卸载的比特与总比特的比率。
在无线接入网覆盖范围内,建立多个用户无线信道连接时所使用的方法就是多址技术。多址技术解决的就是多个用户同时接入网络时,如何有效区分的问题。
多址技术:FDMA(频分多址)、TDMA(时分多址)、CDMA(码分多址)、SDMA(空分多址)、OFDMA(正交频分多址)。
FDMA(频分多址是以不同的频率信道实现多址通信的。把总带宽分隔成多个正交的信道,每个用户占用一个信道。
TDMA(时分多址是以不同时隙来实现多址通信的。允许多个用户在不同的时间片(时隙)来使用相同的频率。
CDMA(码分多址是以不同的代码序列来实现通信的。每个用户分配各自特定的地址码,利用公共信道来传输信息。地址具有准正交性,接收端唯有使用完全一致的地址码才能解调信号。
SDMA(空分多址是以不同的方位信息来实现多址通信的。假设房间里有一个盲人,但他能够根据话语传来的不同方向区别不同的发言者,即便是这些发言者同时发言。那么这个盲人就具有一项特异功能——空分多址(SDMA)。
OFDMA(正交频分多址正交频分多址是频分多址的延伸。OFDMA 技术与 OFDM 技术相比,用户可以选择条件较好的子载波进行数据传输,而不是在整个频道内传送。
对于无干扰模型,例如使用时分多址(TDMA)或正交频分多址(OFDMA)。传输速率为:
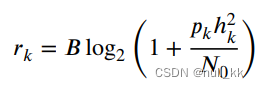
传输速率模型中(信道增益和复高斯白噪声的方差)是恒定的时,根据凸函数找到最佳解决方案。如果参数不是恒定的,则应考虑白高斯信道噪声和信道增益的随机过程。
对于使用码分多址(CDMA)的干扰模型。传输速率为:
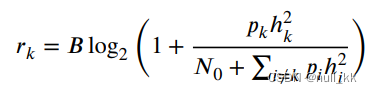
An efficient computation offloading management scheme in the densely deployed small cell networks with mobile edge computing
ED可以连接到宏基站(MBS)或小蜂窝基站(SBS)。ED和MBS之间的通信被认为是无干扰的,因此(1)被用于传输速率计算。当ED和SBS之间的通信考虑到干扰时,(2)用于计算传输速率。
3、计算模型
能耗优化和延迟最小化
4、能量收集模型
略。
计算卸载操作:
卸载决策:任务卸载到哪,任务怎么分区。
服务器选择:一对多场景,选择合适的服务器。
无线资源分配:分配给任务的频率、时间等。
传输功率设置:为任务传输设置适当的功率。
计算资源分配:本地、边缘的计算资源分配。
时隙划分:无线功率传输WPT场景。(EH、卸载)
计算卸载目标:
延迟最小化:传输延迟和执行延迟。
能源消耗最小化:卸载的情况下传输和执行所消耗的能源。
任务丢弃最小化:最小化由于资源不足而导致的任务丢弃。
计算速率最大化:能量和计算资源限制的情况下。
计算效率最大化:计算效率是总计算比特数除以消耗的能量。
支付最小化:ED必须为EC或云计算中使用的资源付费的场景。
优化工作:(非)凸优化、MDP、博弈论、Lyapunov优化和机器学习。
1、凸和非凸优化
2、马尔可夫决策过程
3、博弈论
4、李雅普诺夫优化
5、机器学习
6、其他建模方法:PSO、GA……
Maga: A mobility-aware computation offloading decision for distributed mobile cloud computing
使用遗传算法进行卸载建模,其中染色体编码为n(任务数)整数,每个整数表示相应任务的卸载策略。目标是在满足作业完成时间要求的同时,提高卸载成功率并降低ED的能耗。
Fine-granularity based application offloading policy in cloud-enhanced small cell networks
卸载问题被表述为具有延迟约束的0-1整数规划模型。为了解决这个问题,作者提出了一种称为二进制粒子群优化(BPSO)的算法,其中每个被称为“粒子”的个体都代表一个潜在的解决方案。每个“粒子”遵循两个解决方案。一个是自己的最佳解决方案,另一个是群体的最佳解决办法。随着发展,可以确定最佳卸载解决方案。
卸载建模方法的比较
场景:集中式/分布式;是否可扩展;静态/动态
(非)凸优化具有实现全局或接近全局优化的优点。但是需要引入一个集中的实体来收集所有必要的信息并为所有用户做出决策,模型不可扩展,不适合大规模的卸载场景。(非)凸优化静态建模,不适用于信道条件和网络拓扑等环境频繁变化的动态卸载场景。
MDP的好处是它可以应用于集中式和分布式场景。但是存在信息收集的问题,MDP不可扩展。
博弈论建模的优势在于其固有的分布式特性,在大规模卸载场景中运行良好。但是博弈论建模只能保证实现纳什均衡,而纳什均衡可能不是全局最优解。
Lyapunov优化可以同时实现卸载优化和Lyapunov-漂移优化。Lyapunov优化是一种集中式建模方法。只能实现局部优化。
强化学习适用于高复杂度大规模卸载场景,适合于动态场景。但是支持强化学习通常超出了ED的能力。
在实践中有多种任务。例如,一些任务是抢先的(即,任务可以抢先其他任务),而其他任务则不是。这种任务的异构性显著增加了建模的复杂性。异构性也可能来自计算单元(硬件)。
大规模网络显著增加了所有类型卸载模型的复杂性,这又增加了卸载决策延迟,从而导致整个卸载延迟的增加。
大规模网络中的信息收集可能会使网络过载,并违反卸载决策的实时要求。
ED——EC,移动ED需要确保服务连续性和QoS要求。
移动面临问题:迁移成本与延迟和通信成本降低之间存在权衡。
在ED和EC服务器之间提供保密性、完整性、可用性、访问控制和身份验证等机制,以便保护计算卸载过程。
EC服务器充当ED的安全代理。由于ED的异构性,包括各种类型的通信标准、动态安全配置(或更新)等,这种机制需要全面的安全保护。
大多数使用状态-动作模型来描述计算卸载。使用人工智能方法来解决状态-动作模型描述的问题的基于强化学习RL的方案在EC的计算卸载方面比其他方案具有一些优势。
边缘智能EI中的计算卸载应该是需要进一步研究的主要领域。
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我最近决定从我的系统中卸载RVM。在thispage提出的一些论点说服我:实际上,我的决定是,我根本不想担心Ruby的多个版本。我只想使用1.9.2-p290版本而不用担心其他任何事情。但是,当我在我的Mac上运行ruby--version时,它告诉我我的版本是1.8.7。我四处寻找如何简单地从我的Mac上卸载这个Ruby,但奇怪的是我没有找到任何东西。似乎唯一想卸载Ruby的人运行linux,而使用Mac的每个人都推荐RVM。如何从我的Mac上卸载Ruby1.8.7?我想升级到1.9.2-p290版本,并且我希望我的系统上只有一个版本。 最佳答案
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
我已经通过提供MagickWand.h的路径尝试了一切,我安装了命令工具。谁能帮帮我?$geminstallrmagick-v2.13.1Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingrmagick:ERROR:Failedtobuildgemnativeextension./Users/ghazanfarali/.rvm/rubies/ruby-1.8.7-p357/bin/rubyextconf.rbcheckingforRubyversion>=1.8.5...yescheckingfor/
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包