可以参考新发布的文章
1.BP神经网络预测(python)
2.mlp多层感知机预测(python)
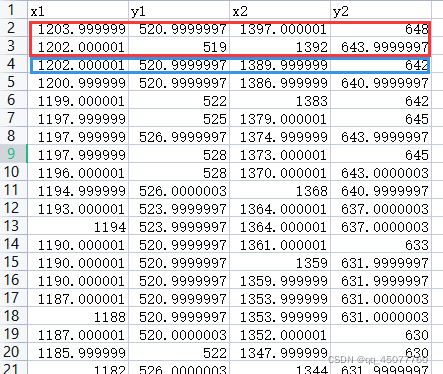
下边是基于Python的简单的LSTM和GRU神经网络预测,多输入多输出,下边是我的数据,红色部分预测蓝色
2,3行输入,第4行输出
3,4行输入,第5行输出
…以此类推
简单利索,直接上代码
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import sklearn.metrics
from IPython.core.display import SVG
from keras.layers import LSTM, Dense, Bidirectional
from keras.losses import mean_squared_error
from keras.models import Sequential
from keras.utils.vis_utils import model_to_dot, plot_model
from matplotlib import ticker
from keras import regularizers
from pandas import DataFrame, concat
from sklearn import metrics
# from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
#from statsmodels.tsa.seasonal import seasonal_decompose
import tensorflow as tf
import seaborn as sns
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
def load_data(path):
data_origin = pd.read_excel(path)
# 把object类型转换为float
data_origin = DataFrame(data_origin, dtype=float)
# 打印显示所有列
pd.set_option('display.max_columns', None)
# 获得数据的描述信息
# print(data_dropDate.describe())
return data_origin
#单维最大最小归一化和反归一化函数
# 对于训练数据进行归一化之后。使用训练数据的最大最小值(训练数据的范围)对于测试数据进行归一化 保留周期和范围信息
def Normalize(df,low,high):
delta = high - low
for i in range(0,df.shape[0]):
for j in range(0,df.shape[1]):
df[i][j] = (df[i][j]-low[j])/delta[j]
return df
# 定义反归一化函数
def FNormalize(df,low,high):
delta = high - low
for i in range(0,df.shape[0]):
for j in range(0,df.shape[1]):
df[i][j] = df[i][j] * delta[j] + low[j]
return df
# 数据集转换成监督学习问题
# 数据集转换成监督学习函数
def series_to_supervise(data,n_in=1,n_out=1,dropnan=True):
'''该函数有四个参数:
data:作为列表或 2D NumPy 数组的观察序列。必需的。
n_in :作为输入 ( X )的滞后观察数。值可能在 [1..len(data)] 之间可选。默认为 1。
n_out:作为输出的观察数(y)。值可能在 [0..len(data)-1] 之间。可选的。默认为 1。
dropnan:布尔值是否删除具有 NaN 值的行。可选的。默认为真。
该函数返回一个值:
return:用于监督学习的系列 Pandas DataFrame。'''
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols , names = list(),list()
# input sequence(t-n,...,t-1)
for i in range(n_in,0,-1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' %(j+1,i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
# 定义一个名为split_sequences()的函数,它将采用我们定义的数据集,其中包含时间步长的行和并行序列的列,并返回输入/输出样本。
# split a multivariate sequence into samples
def split_sequences(sequences, n_steps):
X, y = list(), list()
for i in range(len(sequences)):
# # find the end of this pattern
end_ix = i + n_steps
if end_ix > len(sequences)-n_steps:
break
# gather input and output parts of the pattern
seq_x,seq_y = sequences[i:end_ix,:-1],sequences[end_ix,:-1]
X.append(seq_x)
y.append(seq_y)
return np.array(X),np.array(y)
path = 'E:/YOLO/yolov5-master/digui/1/origin.xlsx'
data_origin = load_data(path)
print(data_origin.shape)
# 先将数据集分成训练集和测试集
train_Standard = data_origin.iloc[:60,:] # (145,23),前60行
test_Standard = data_origin.iloc[60:,:] # (38,23),后边
# 再转换为监督学习问题
n_in = 2
n_out = 1
train_Standard_supervise = series_to_supervise(train_Standard,n_in,n_out) # (144,46)
test_Standard_supervise = series_to_supervise(test_Standard,n_in,n_out) # (37,46)
print('test_Standard_supervise')
print(test_Standard_supervise.head())
# 将训练集和测试集分别分成输入和输出变量。最后,将输入(X)重构为 LSTM 预期的 3D 格式,即 [样本,时间步,特征]
# split into input and output
train_Standard_supervise = train_Standard_supervise.values
test_Standard_supervise = test_Standard_supervise.values
train_X,train_y = train_Standard_supervise[:,:8],train_Standard_supervise[:,8:]
test_X,test_y = test_Standard_supervise[:,:8],test_Standard_supervise[:,8:]
#归一化
scaler = StandardScaler()
train_X=scaler.fit_transform(train_X)
train_y = train_y.reshape(train_y.shape[0],4)
train_y=scaler.fit_transform(train_y)
test_X=scaler.fit_transform(test_X)
test_y = test_y.reshape(test_y.shape[0],4)
test_y=scaler.fit_transform(test_y)
# reshape input to be 3D [samples,timeseps,features]
train_X = train_X.reshape((train_X.shape[0],1,train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0],1,test_X.shape[1]))
print(train_X.shape,train_y.shape,test_X.shape,test_y.shape) #(145, 1, 22) (145,) (38, 1, 22) (38,)
groups = [10]
i = 1
plt.figure()
for group in groups:
# 定义模型
model = Sequential()
# 输入层维度:input_shape(步长,特征数)
model.add(LSTM(64, input_shape=(train_X.shape[1], train_X.shape[2]),recurrent_regularizer=regularizers.l2(0.4))) #,return_sequences=True
model.add(Dense(4))
model.compile(loss='mae', optimizer='adam')
# 拟合模型
history = model.fit(train_X, train_y, epochs=100, batch_size=group, validation_data=(test_X, test_y))
plt.subplot(len(groups),1,i)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('batch_size = %d' %group)
plt.legend()
i += 1
plt.show()
# 预测测试集
yhat = model.predict(test_X)
test_X = test_X.reshape((test_X.shape[0], test_X.shape[2]))
# invert scaling for forecast
# invert scaling for actual
test_y = test_y.reshape((len(test_y), 4))
yhat=scaler.inverse_transform(yhat)
test_y=scaler.inverse_transform(test_y)
# calculate RMSE
#print(test_y)
#print(yhat)
rmse = np.sqrt(mean_squared_error(test_y, yhat))
mape = np.mean(np.abs((yhat-test_y)/test_y))*100
print('=============rmse==============')
print(rmse)
print('=============mape==============')
print(mape,'%')
print("R2 = ",metrics.r2_score(test_y, yhat)) # R2
# 画出真实数据和预测数据的对比曲线图
plt.plot(test_y,color = 'red',label = 'true')
plt.plot(yhat,color = 'blue', label = 'pred')
plt.title('Prediction')
plt.xlabel('Time')
plt.ylabel('value')
plt.legend()
plt.show()
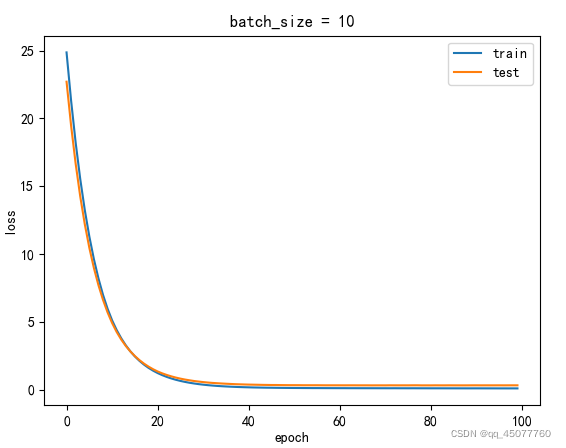
这是出来的训练集和测试集损失图
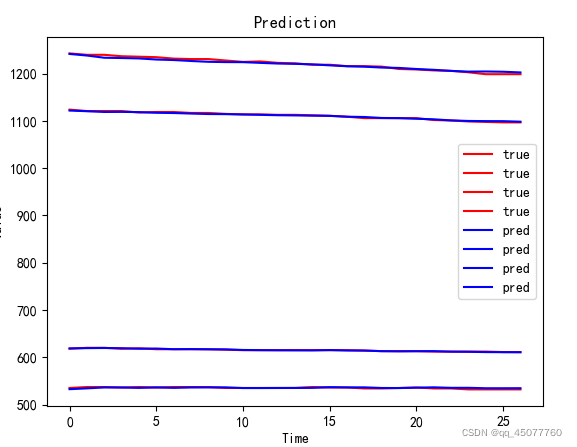
下边是预测值和真实值的结果图,其中
mape=0.15912692740815412 %
R2 = 0.9762727107502187
GRU的修改
把
model = Sequential()
# 输入层维度:input_shape(步长,特征数)
model.add(LSTM(64, input_shape=(train_X.shape[1], train_X.shape[2]),recurrent_regularizer=regularizers.l2(0.4))) #,return_sequences=True
model.add(Dense(4))
model.compile(loss='mae', optimizer='adam')
# 拟合模型
history = model.fit(train_X, train_y, epochs=100, batch_size=group, validation_data=(test_X, test_y))
改成
model = Sequential()
model.add(Dense(128, input_shape=(train_X.shape[1], train_X.shape[2]),
activation='relu'
)
)
model.add(Dense(64, activation='relu'))
model.add(Dense(1,
activation='sigmoid'
))
model.compile(loss='mae',optimizer='rmsprop')
# 拟合模型
batchsize = 10
history = model.fit(train_X, train_y, epochs=100, batch_size=batchsize, validation_data=(test_X, test_y))
剩下的就剩调参了
可以加群:1029655667,进行沟通交流
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我需要检查DateTime是否采用有效的ISO8601格式。喜欢:#iso8601?我检查了ruby是否有特定方法,但没有找到。目前我正在使用date.iso8601==date来检查这个。有什么好的方法吗?编辑解释我的环境,并改变问题的范围。因此,我的项目将使用jsapiFullCalendar,这就是我需要iso8601字符串格式的原因。我想知道更好或正确的方法是什么,以正确的格式将日期保存在数据库中,或者让ActiveRecord完成它们的工作并在我需要时间信息时对其进行操作。 最佳答案 我不太明白你的问题。我假设您想检查
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决