目录
一.剑指 Offer 03. 数组中重复的数字(原地哈希思想)
问题描述:
- 🤪在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。🤪
示例 :
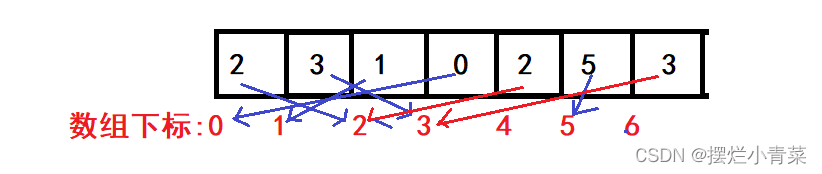
输入: [2, 3, 1, 0, 2, 5, 3] 输出:2 或 3
问题分析:
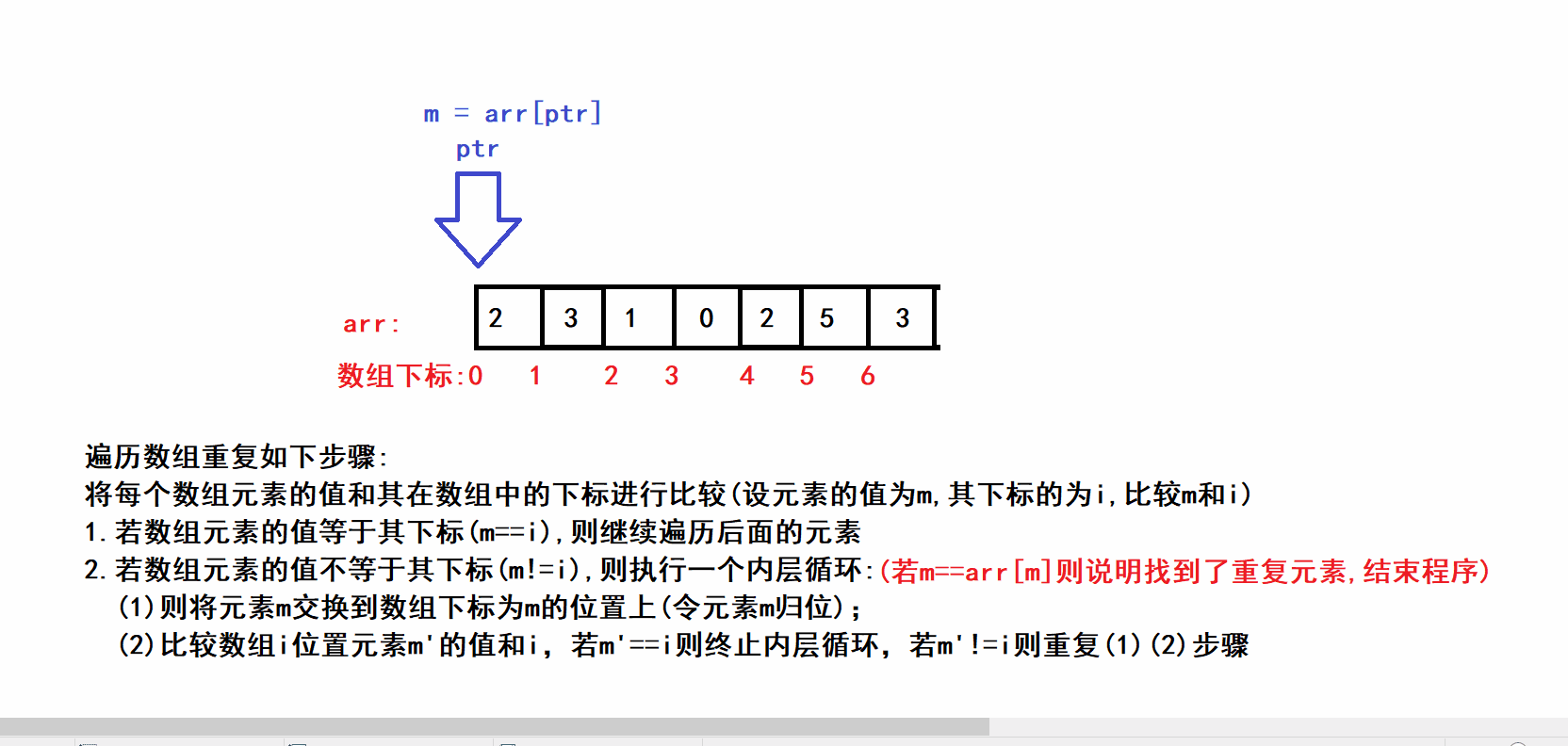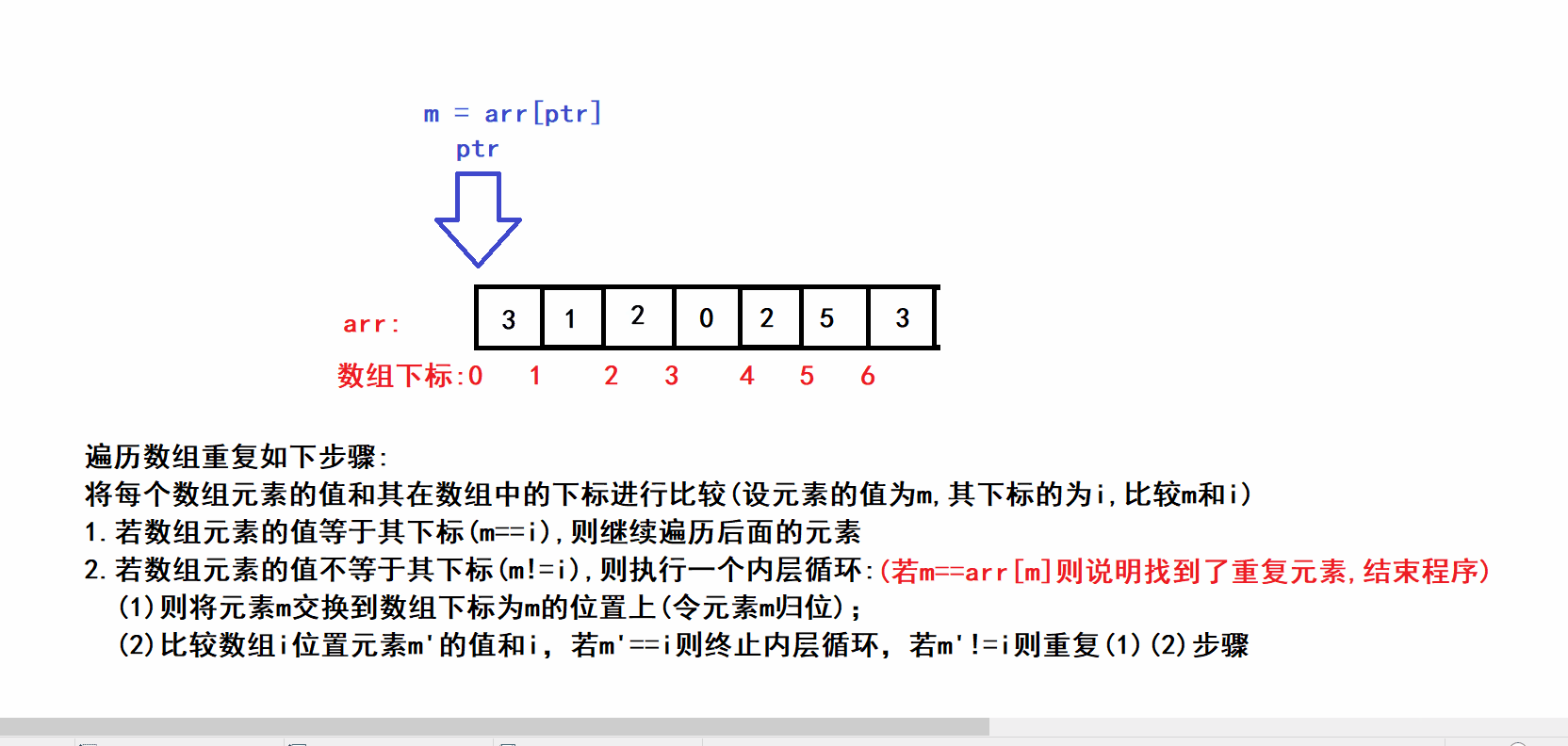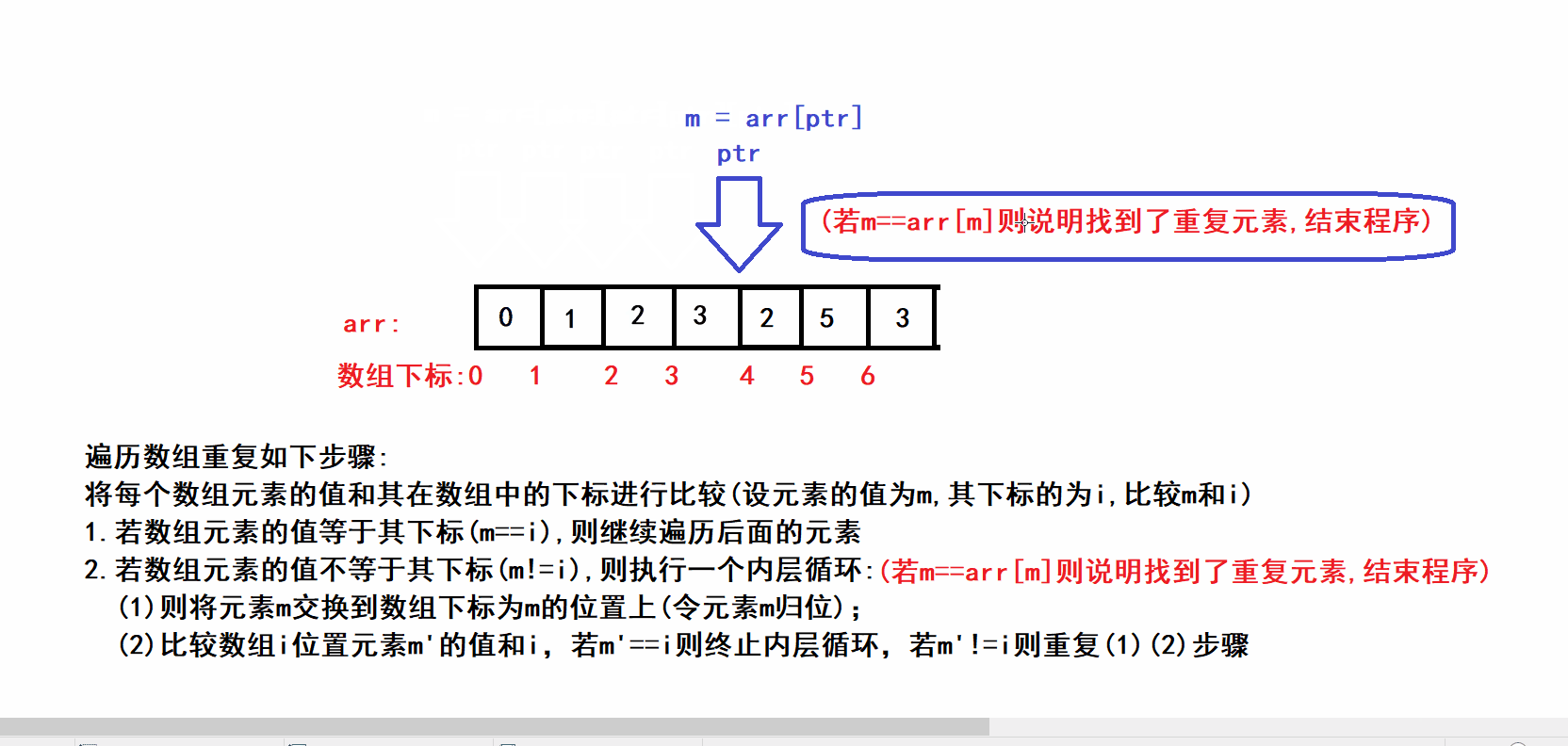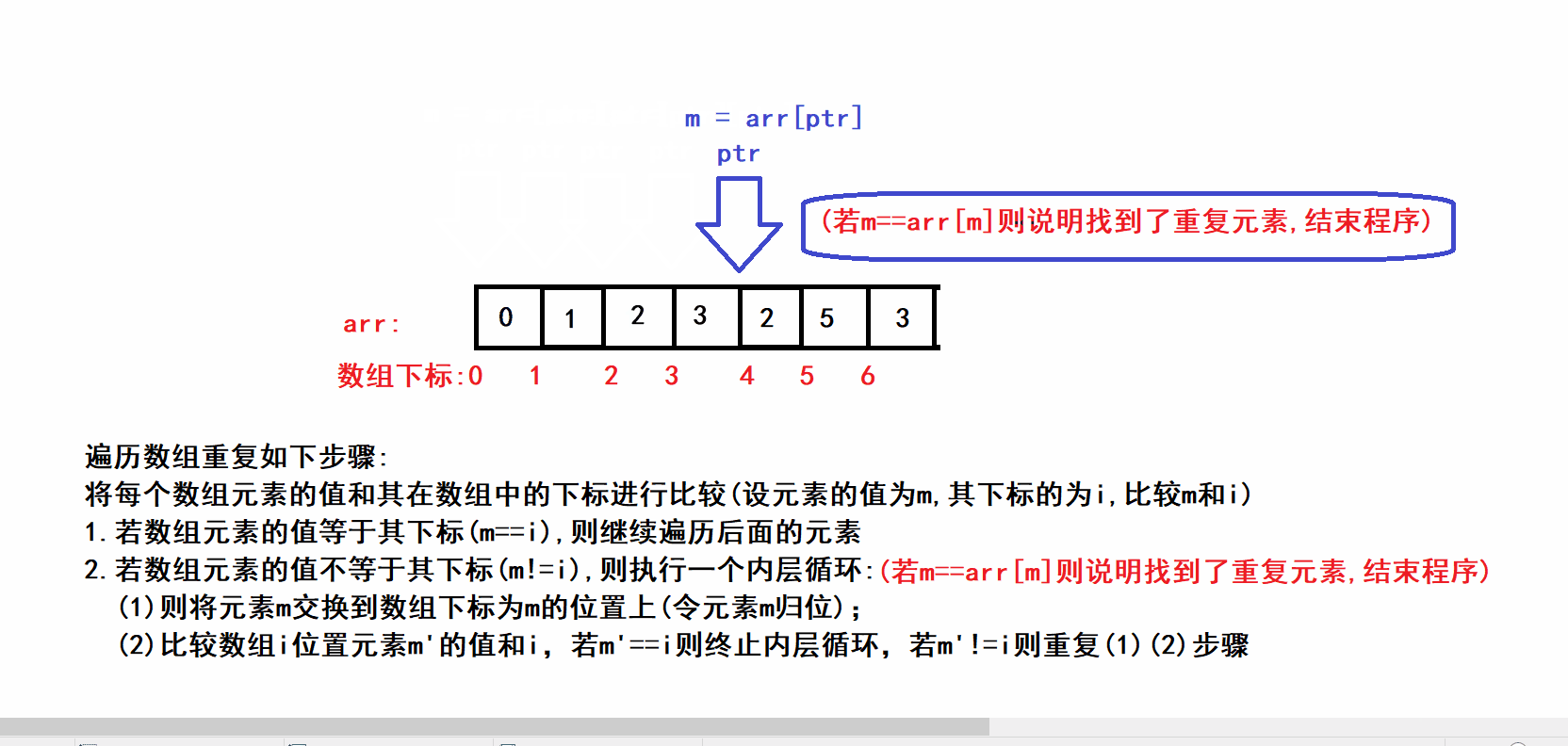
- 🤪问题中数组长度为n,且其中的元素的值都被限制在了 0 ~ n-1的范围内,因此我们将数组的每一个元素m都交换到数组下标为m的位置上(类似于鸽巢思想)(数组下标与元素值建立绝对映射),通过这种方式可以完成时间复杂度为O(N),空间复杂度为O(1)的哈希思想排序,在排序的过程中可以加上简单的重复数字判断语句便可以完成本题的求解.🤪
原地哈希思想排序:
题解算法gif:
算法接口:
class Solution { public: int findRepeatNumber(vector<int>& nums) { int size = nums.size(); int ptr = 0; //用于遍历数组(相当于算法描述中的下标i) while(ptr<size) { int m = nums[ptr]; if(m==ptr) //判断元素的值和其下标是否相同(相同则表明元素已经归位) { ++ptr; } else { while(m != ptr) //内层循环 { if(m==nums[m]) //判断元素是否重复 { return m; } swap(nums[ptr],nums[m]); //令m元素归位 m=nums[ptr]; //更新m元素,继续完成其余元素的归位 } } } return false; } };
- 😃算法中每个元素只需完成一次归位,因此算法的时间复杂度为O(N)
- 😃算法的空间复杂度为O(1)
问题描述:
- 😝在一个 n * m 的二维数组中,每一行都按照从左到右 非递减 的顺序排序,每一列都按照从上到下 非递减 的顺序排序。请完成一个高效的函数,输入如前所述的一个二维数组和一个整数target,判断数组中是否含有target。
😜示例:
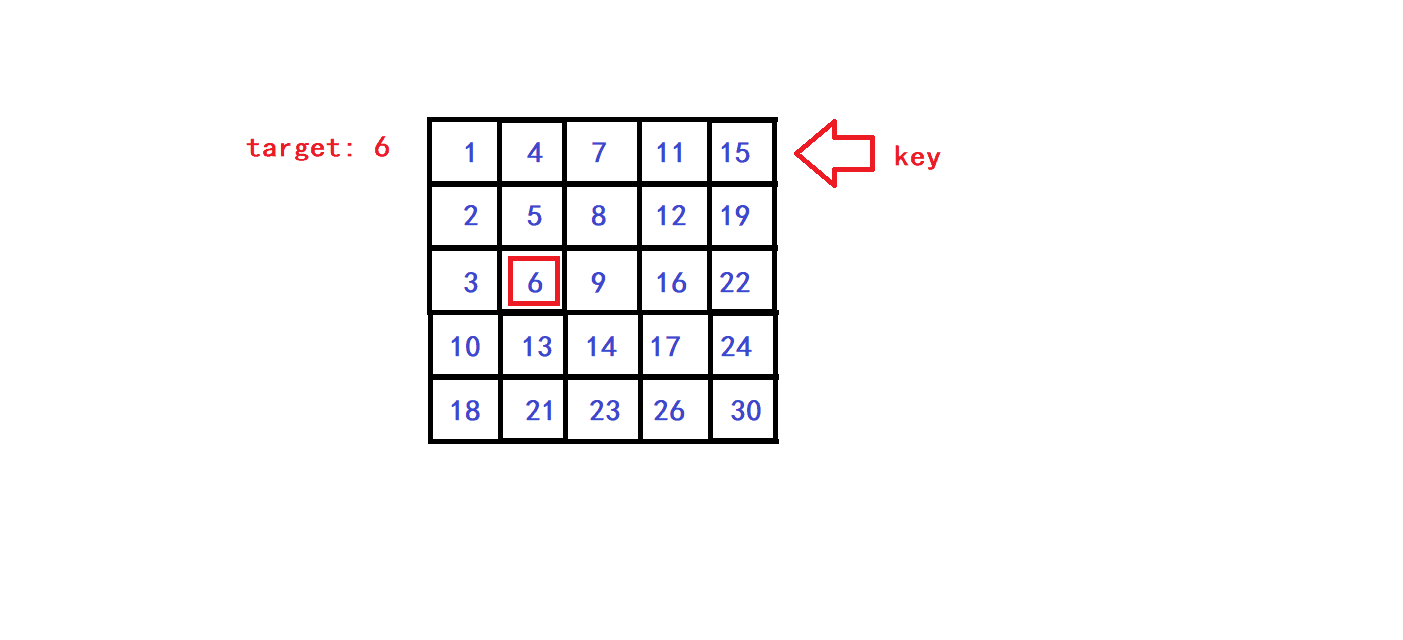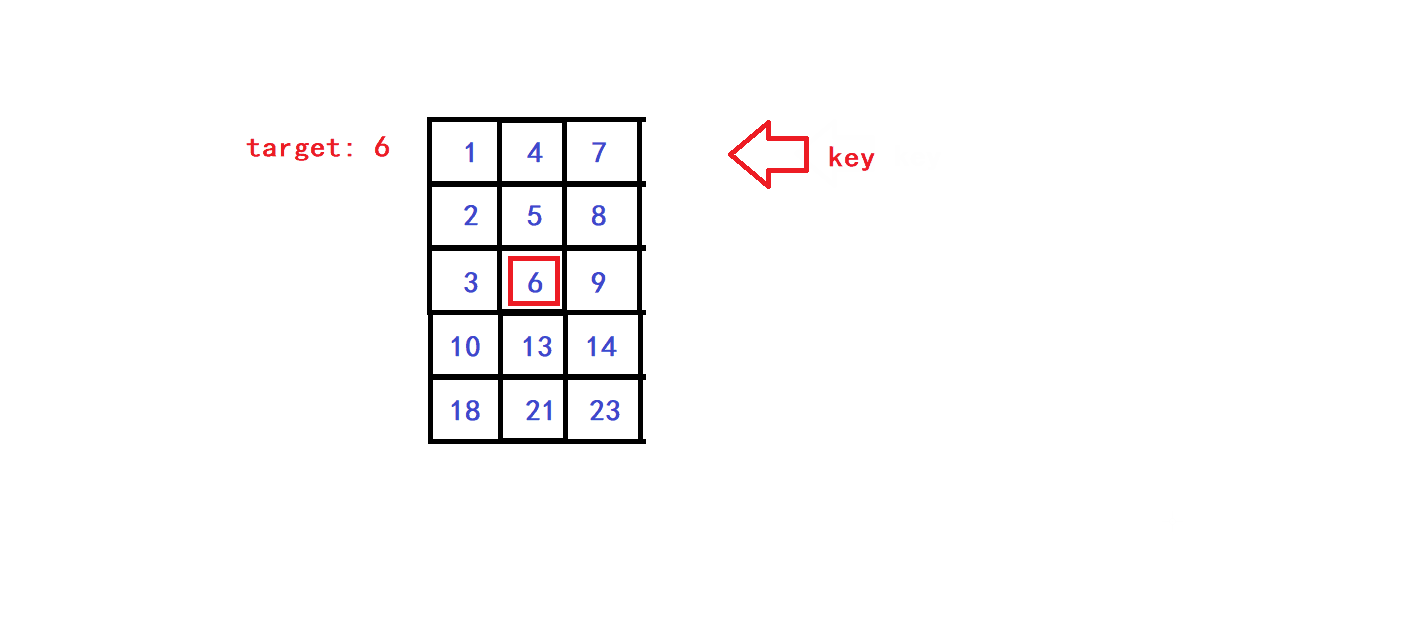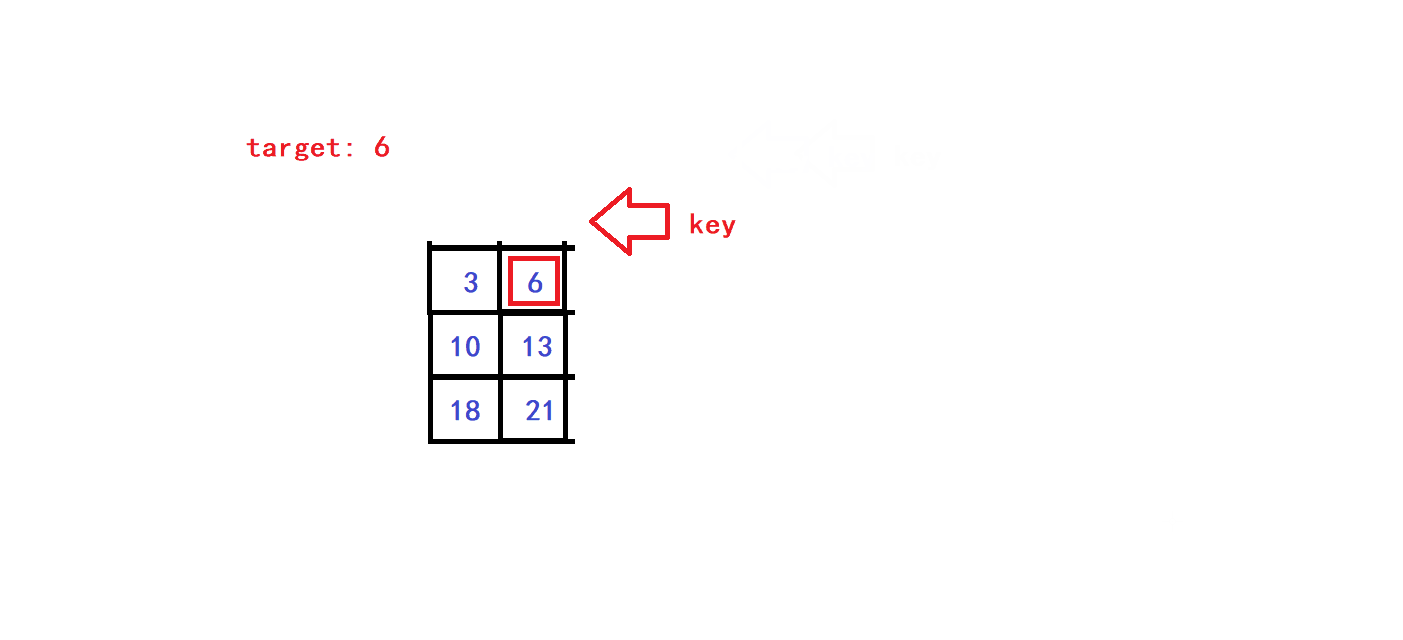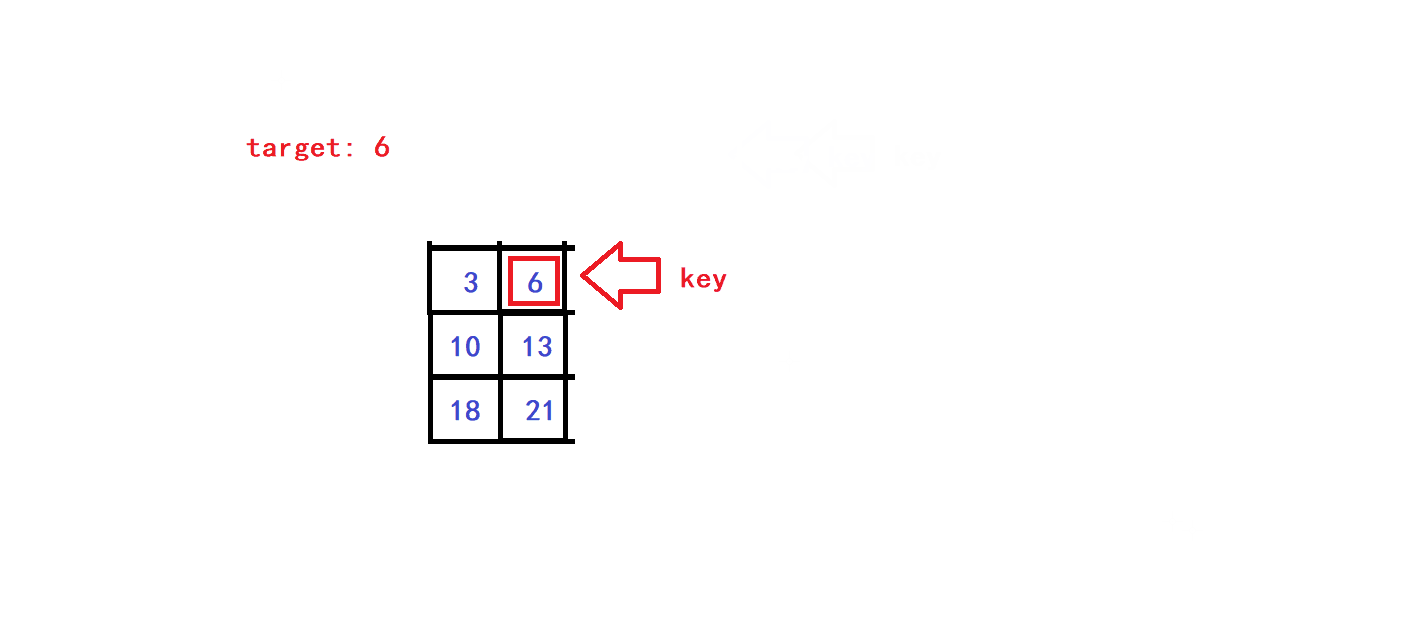
😜现有矩阵 matrix 如下:
[1, 4, 7, 11, 15] [2, 5, 8, 12, 19] [3, 6, 9, 16, 22] [10, 13, 14, 17, 24] [18, 21, 23, 26, 30]
- 😜给定 target =
5,返回true。- 😜给定 target =
20,返回false。
算法思想:
🧐待查找矩阵的行数为Row,列数为Col
🧐矩阵首元素的坐标为(0,0)
- 🧐选取右上角(或者左下角)元素为key元素
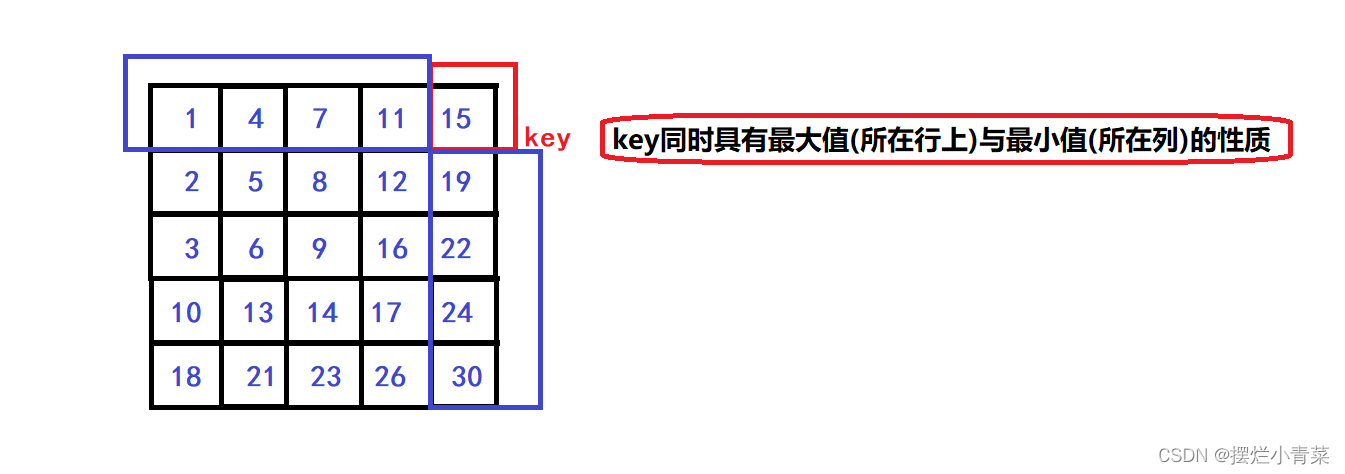
- 🧐key元素具有如下特征:
- 😀key是其所在行的最大元素
- 😀key是其所在列的最小元素
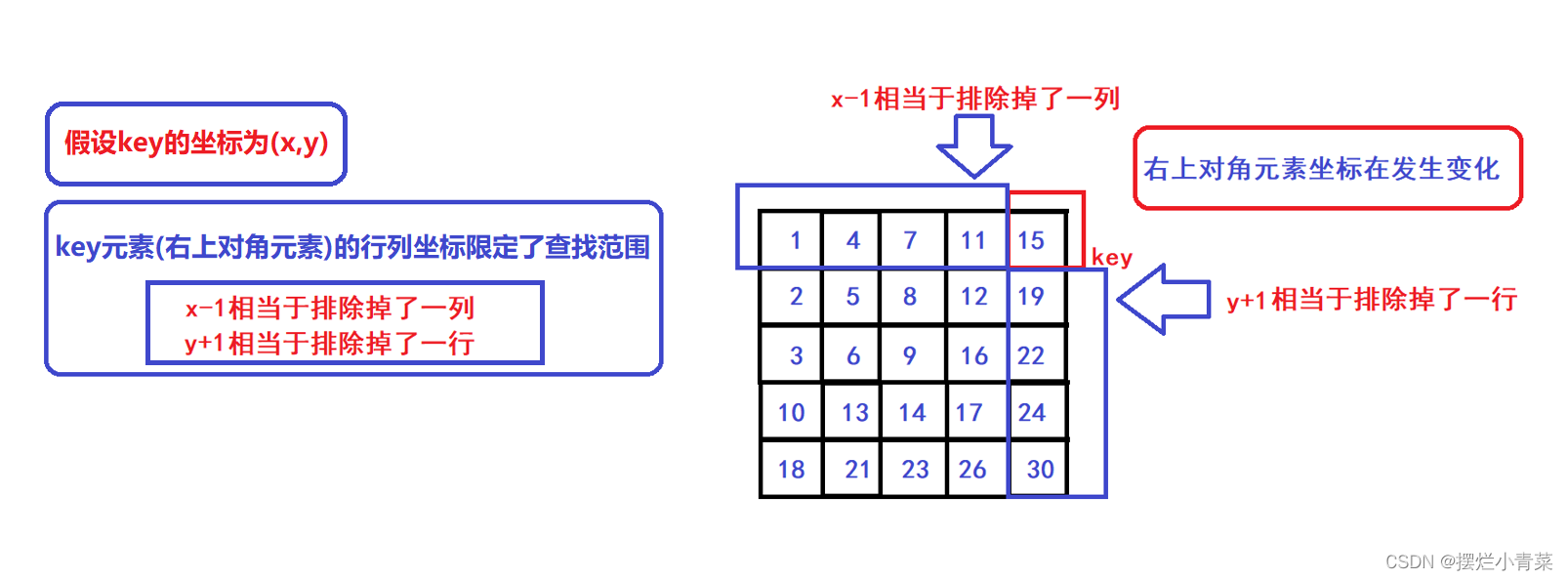
- 😀每一个查找过程的子步骤中,将target与key进行比较,根据比较结果可以分为三种情况:
- 😀假设key元素的坐标为(x,y)(第x列,第y行),则我们的查找范围的列坐标范围为[0,x],查找范围的行坐标范围为[y,Col-1],即我们取以key为右上对角元素的矩阵为每个子步骤中的待搜索矩阵,于是通过改变(x,y)坐标就可以实现查找范围的缩小:
- 😀可知,每一次单趟查找我们就可以排除当前待搜索矩阵的一行元素或一列元素,因此该查找算法的时间复杂度为O(Row + Col).
算法gif:
算法接口实现:
class Solution { public: bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) { int height= matrix.size(); if(height == 0) { return false; } int lenth = matrix[0].size(); int x = lenth-1; //初始右上角元素横坐标 int y = 0; //初始右上角元素纵坐标 while(x>=0 && y<=height-1) //当x和y其中一个坐标越界时说明target不在矩阵中 { int key = matrix[y][x]; if(key == target) { return true; } else if(key>target) //可以排除key所在一列元素 { --x; } else //可以排除key所在一行元素 { ++y; } } return false; //x或y有一个越界说明target不存在 } };
- 注意循环结束的边界条件
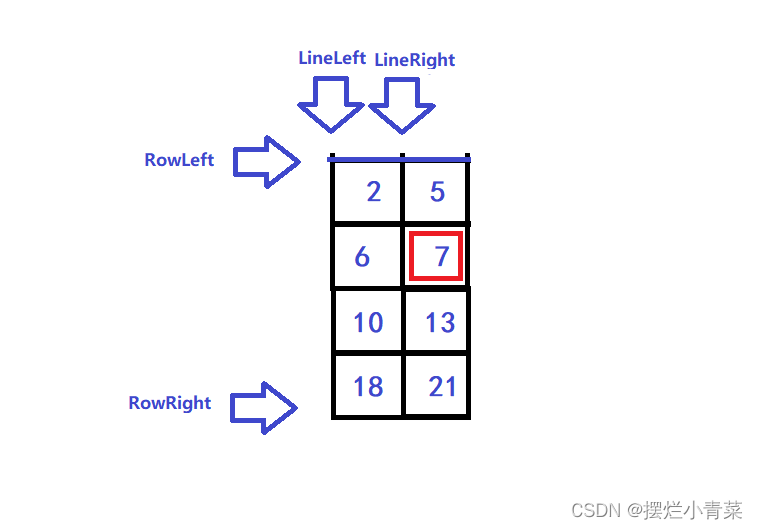
基本思想介绍:
🧐待查找矩阵的行数为Row,列数为Col
🧐矩阵首元素的坐标为(0,0)
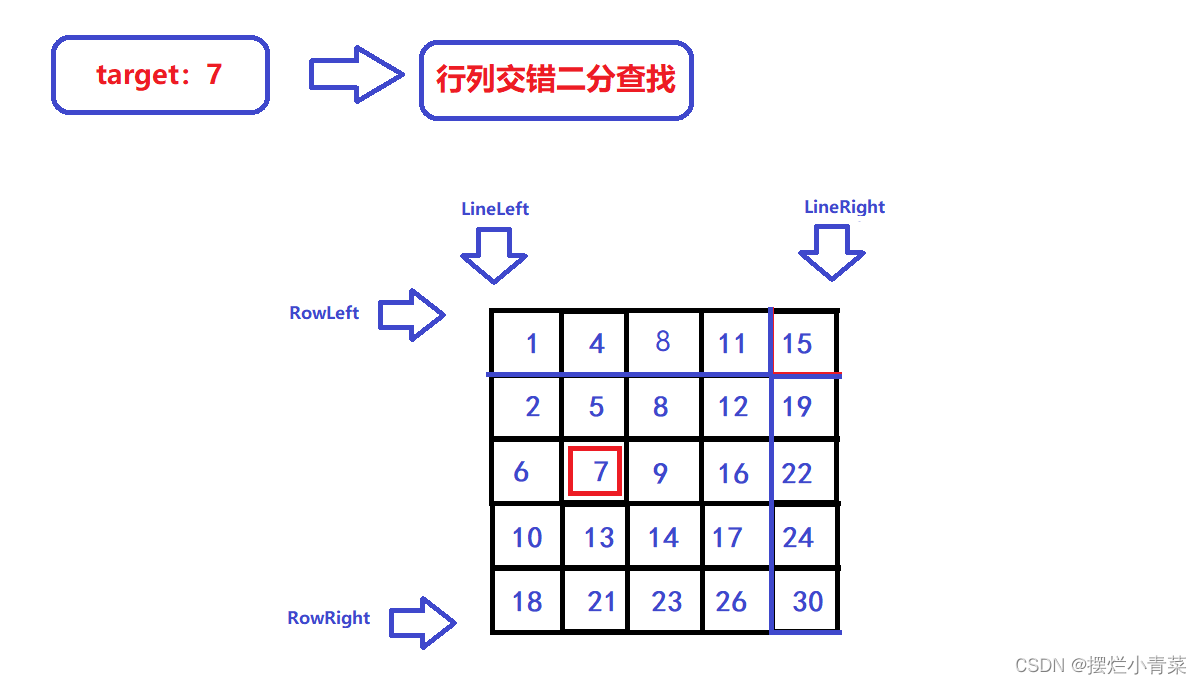
- 😃如上图所示,查找过程中我们保持LineLeft和RowRight指针不变,待搜索的行范围为[RowLeft,RowRight],待搜索的列范围为[LineLeft,LineRight]
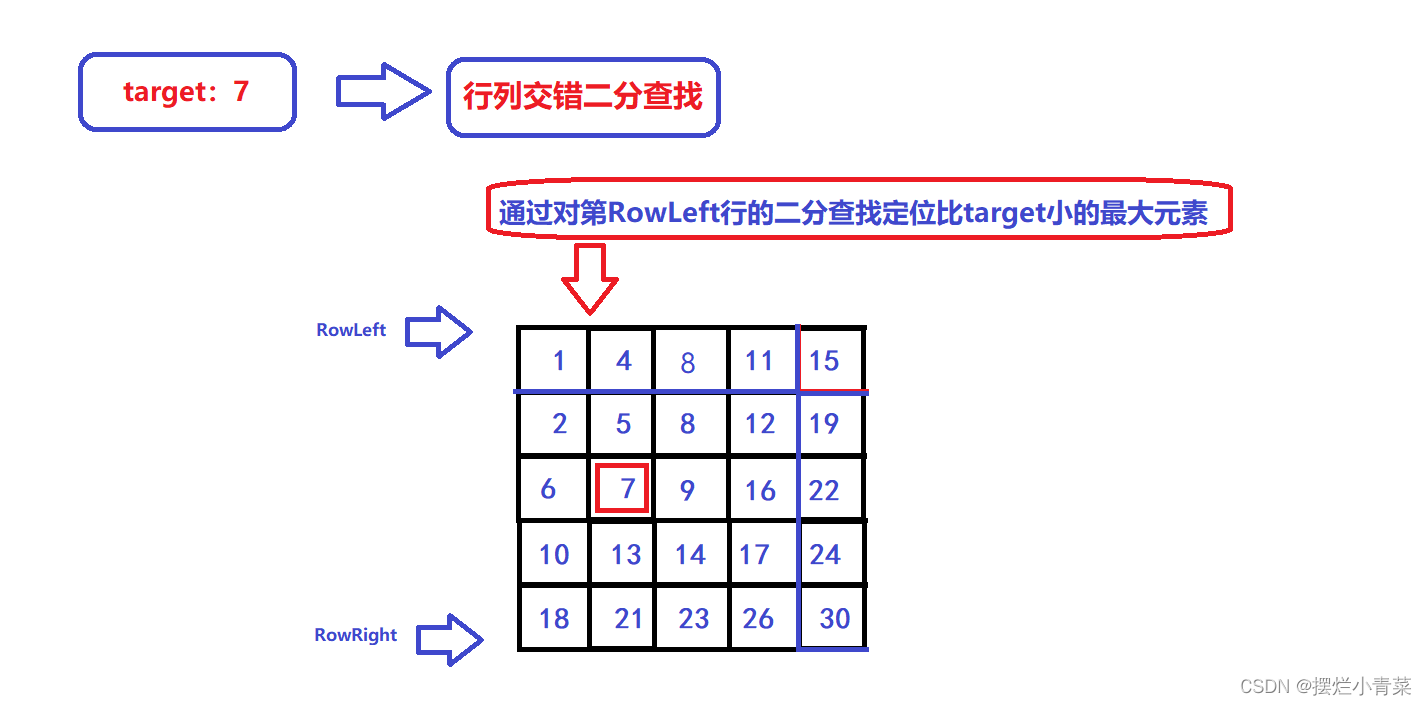
- 😃先对第RowLeft行进行二分查找,如上图所示,7不存在于第RowLeft行,则我们需要通过二分查找接口定位比target小的最大元素(上图中的4):
😃接下来更新LineRight指针(同时令RowLeft加一):
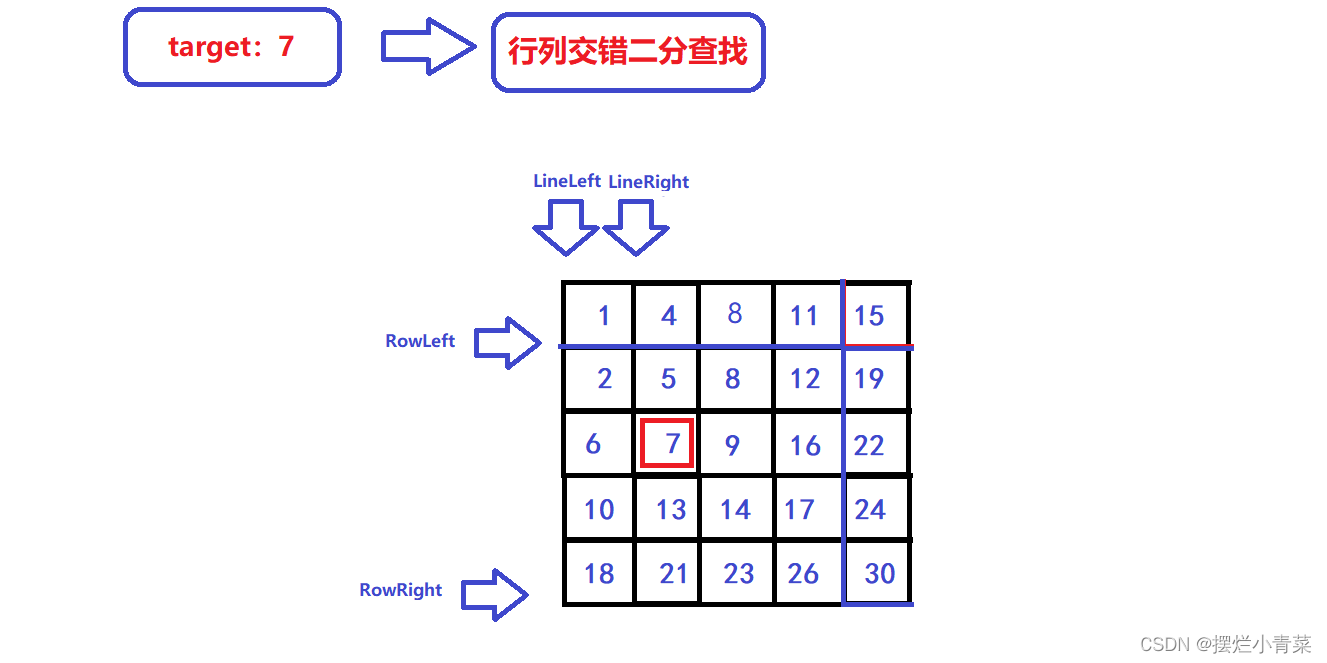
- 😃这时候我们的查找范围就变成了下图中的矩阵:
- 😍可见查找范围一下子缩小了一大半😍
- 😍接下来再对第LineRight列进行二分查找,则可以找到元素7
- 😍在一般情况下,对第LineRight列进行二分查找若没有找到target,我们同样需要通过二分查找接口定位比target小的最大元素并且更新RowLeft指针,接着重复上述行列交叉二分查找的过程直到找到target或RowLeft(或LineRight)指针超出边界条件为止
- 😍上述算法的时间复杂度在大多数情况下可以达到log(Row*Col)(相当于每次单趟查找都可以二分整个矩阵)
算法实现:
- 😭算法的边界问题很伤人脑筋😭
class Solution { //行二分查找接口 //参数Line标识待查找的行标 bool binaryLineSearch(vector<vector<int>>& arr, int Line, int* returnlimit, int left, int right, int target) { while (right >= left) { int mid = left + ((right - left) >> 2); if (arr[Line][mid] > target) //右边界缩进 { right = mid - 1; } else if (arr[Line][mid] < target) //左边界缩进 { left = mid + 1; } else { *returnlimit = mid; return true; } } *returnlimit = right; //返回行上比target小的最大元素列下标 return false; } //列二分查找接口 //参数Row标识待查找的列标 bool binaryRowSearch(vector<vector<int>>& arr, int Row, int* returnlimit, int left, int right, int target) { if (Row < 0) { return false; } while (right >= left) { int mid = left + ((right - left) >> 2); if (arr[mid][Row] > target) //右边界缩进 { right = mid - 1; } else if (arr[mid][Row] < target) //左边界缩进 { left = mid + 1; } else { *returnlimit = mid; return true; } } *returnlimit = right; //返回列上比target小的最大元素行下标 return false; } public: bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) { int height = matrix.size(); if (height == 0) { return false; } int lenth = matrix[0].size(); //列查找右边界不动 const int Rowright = height - 1; int RowLeft = 0; int Row = 0; //用于记录下一次要进行二分查找的行 //行查找左边界不动 const int LineLeft = 0; int LineRight = lenth - 1; int Line = 0; //用于记录下一次要进行二分查找的列 //当矩阵只有一行(或一列)元素时,则只需进行一次行(或列)的二分查找 if (LineRight == 0) { return binaryRowSearch(matrix, 0, &Line, 0, Rowright, target); } else if (Rowright == 0) { return binaryLineSearch(matrix, 0, &Row, 0, LineRight, target); } //行列交叉二分查找 while (LineRight >= 0 && LineRight <= lenth - 1 && RowLeft >= 0 && RowLeft <= height - 1) { if (binaryLineSearch(matrix, Line, &Row, LineLeft, LineRight, target)) { return true; //找到元素返回true } LineRight = Row; ++RowLeft; if (binaryRowSearch(matrix, Row, &Line, RowLeft, Rowright, target)) { return true; //找到元素返回true } ++Line; RowLeft = Line; } return false; } };

我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我的代码目前看起来像这样numbers=[1,2,3,4,5]defpop_threepop=[]3.times{pop有没有办法在一行中完成pop_three方法中的内容?我基本上想做类似numbers.slice(0,3)的事情,但要删除切片中的数组项。嗯...嗯,我想我刚刚意识到我可以试试slice! 最佳答案 是numbers.pop(3)或者numbers.shift(3)如果你想要另一边。 关于ruby-多次弹出/移动ruby数组,我们在StackOverflow上找到一
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我正在尝试在Ruby中制作一个cli应用程序,它接受一个给定的数组,然后将其显示为一个列表,我可以使用箭头键浏览它。我觉得我已经在Ruby中看到一个库已经这样做了,但我记不起它的名字了。我正在尝试对soundcloud2000中的代码进行逆向工程做类似的事情,但他的代码与SoundcloudAPI的使用紧密耦合。我知道cursesgem,我正在考虑更抽象的东西。广告有没有人见过可以做到这一点的库或一些概念证明的Ruby代码可以做到这一点? 最佳答案 我不知道这是否是您正在寻找的,但也许您可以使用我的想法。由于我没有关于您要完成的工作
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用