excel搭配python这个话题在楼主看来有点别扭,其实excel本身已经非常强大了,可以这么说,excel+python能实现的,excel单独也能实现。
excel单独就能连接sql server数据库,发送sql语句获取数据,驾驭海量数据;
excel单独就能设计出自定义的可视化用户交互界面(userform);
excel甚至可以做爬虫。。。
楼主自己的实际工作,快10年了,在做了的四、五十个项目中,真正用上excel+python的就两个项目
不过,有些事情单独使用excel确实费时费力,用vb写代码,还真没用python写来的舒服省力。
那废话就不多说了,开一个系列来讲excel+python,涉及到的两个主要的库就是pandas和xlwings。
先来讲pandas,主要会围绕pandas与excel相关的知识点来讲
本篇文章呢我们来详细的了解一下read_excel,这个pandas的数据读取函数
pandas可以读取多种的数据格式,针对excel来说,读取的方法为read_excel,假设我有一个名为”test.xlsx“的文件,那么如果要读取我们可以这样写:
import pandas as pd
df = pd.read_excel("test.xlsx")简单吧?非常简单
但有一个隐藏的细节要注意,就是pandas在读取excel文件的时候需要调用读取文件的第三方库(称为引擎)。
举个不太恰当的例子,张三买车得到了一次砸金蛋的机会,他当然不能用手砸,于是他顺手抄起旁边的锤子就砸了一个金蛋。
这个例子里面的张三相当于pandas,金蛋就是excel文件,锤子就是读取文件的引擎。
我们来看一下pandas的API文档中对读取引擎的描述:
Supported engines: “xlrd”, “openpyxl”, “odf”, “pyxlsb”. Engine compatibility :
“xlrd” supports old-style Excel files (.xls).
“openpyxl” supports newer Excel file formats.
“odf” supports OpenDocument file formats (.odf, .ods, .odt).
“pyxlsb” supports Binary Excel files.
也就是说,pandas支持4种excel文件的读取引擎,我们用的最多的是"xlrd"和"openpyxl"
其中"xlrd"是用来读取".xls"文件的,而"openpyxl"是用来读取".xlsx"及其他07版以后的新格式
其实"xlrd"和"openpyxl"都是python的库,可以单独的安装使用
不同的库对于一些细节上的处理会有不同的表现,比如日期格式的处理等,如果要指定使用哪个引擎的化可以用入参:engine,比如engine="xlrd"
当然作为使用者我们在大部分情况下不需要指定引擎,pandas会帮我们判断
除了引擎以外read_excel还有很多入参,完整的如下:
pandas.read_excel( io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
这么多东西,不用全记,几个比较重要的是:
有了基本了解后我们就来通过一些例子来详细的讲解一下上面提到的几个参数
我们先来看index_col这个参数,直接看图:
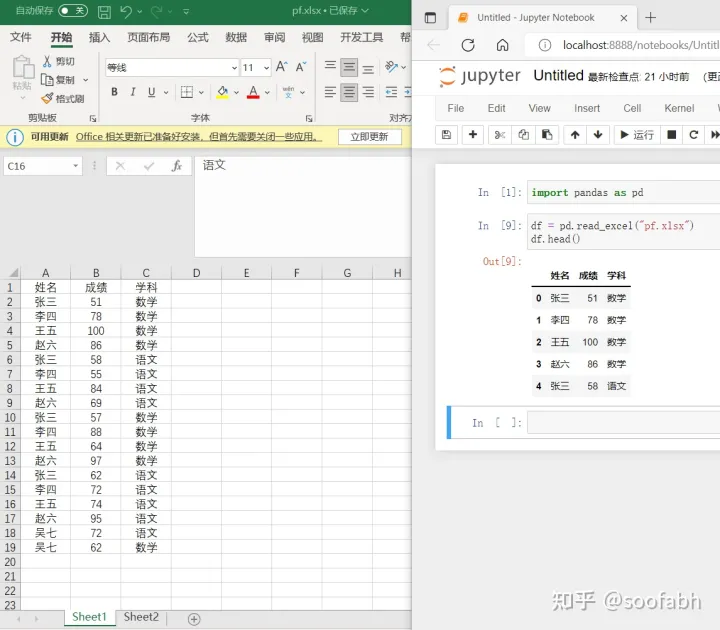
图1
代码中的df.head()是用来查看数据的前5行的。
pandas读取到数据后会在数据前加一行索引(index),也就是图右边代码块中"姓名"前面的那一列。这个行索引很重要,是我们定位数据的一个必备条件。这个索引的建立由上面提到的index_col这个来定义,默认情况下,index_col=None,也就是说默认会添加一列自增的行索引。
如果数据本身已经有索引列了,那我们可以指定,如果索引在第一列那我们就写index_col=0,第二列就写index_col=1。。。
比如:
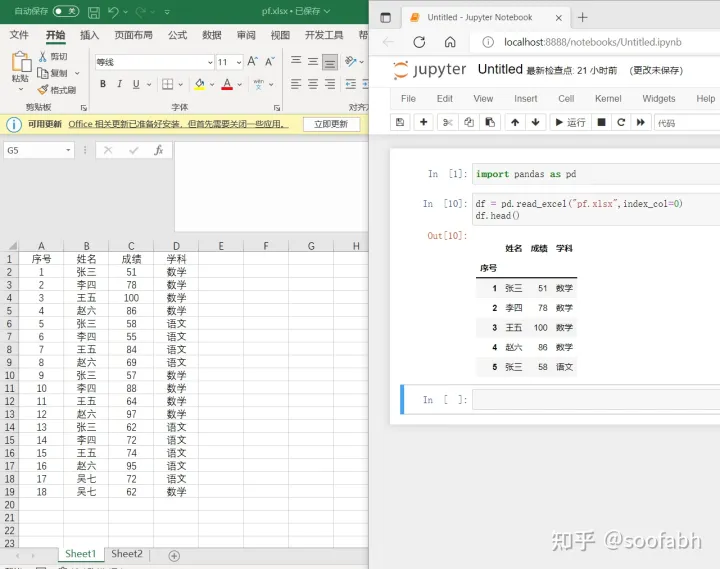
图2
索引可以不唯一,也可以有多层索引(MultiIndex)
如果有多层索引,那么index_col需要传入一个数组,我们看下面的例子:
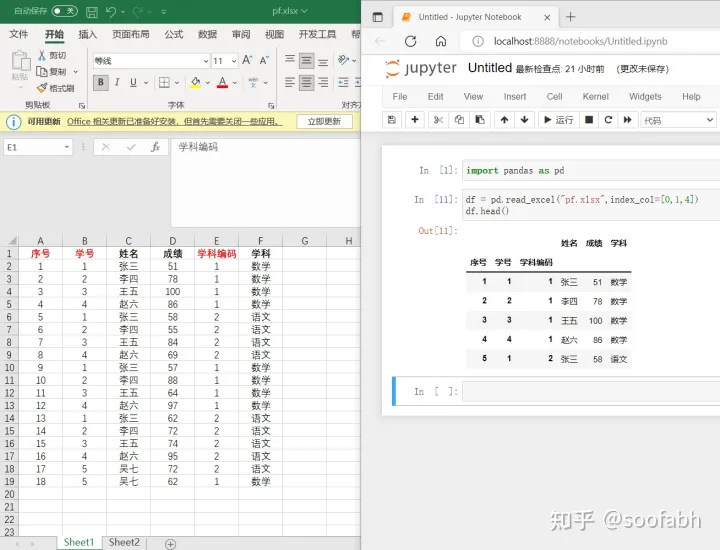
图3
这里定义了三个索引,分别是a,b,e这三列
不过一般来说楼主不建议定义多个行索引,用自增列就行,后面可以用groupby来实现索引分组
我们再修改一下数据来讲解另一个参数,header,看图:
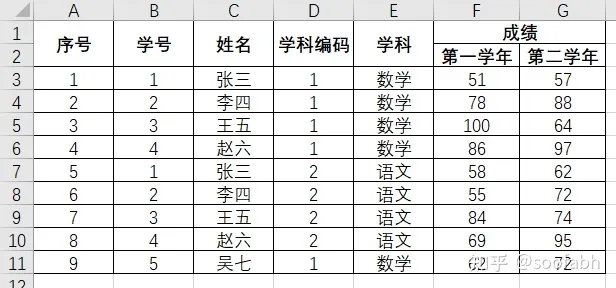
图4
这个数据我们该怎么导入呢?这里就要用到上面说的另一个入参,header
本来不指定的话默认第一行为列索引,那现在有两层列索引,那我们就需要写header=[0,1],也就告诉pandas第一行和第二行是列索引,我们来看:
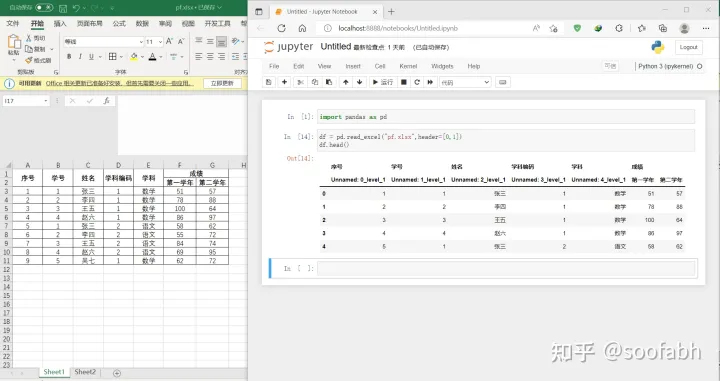
图5
这导入结果在楼主这种强迫症看来就是不忍直视,太难看了,告诉大家两点:
上面的数据排版在excel里面是比较好看,但不实用,建议修改一下数据格式然后导入,可以改成这样:
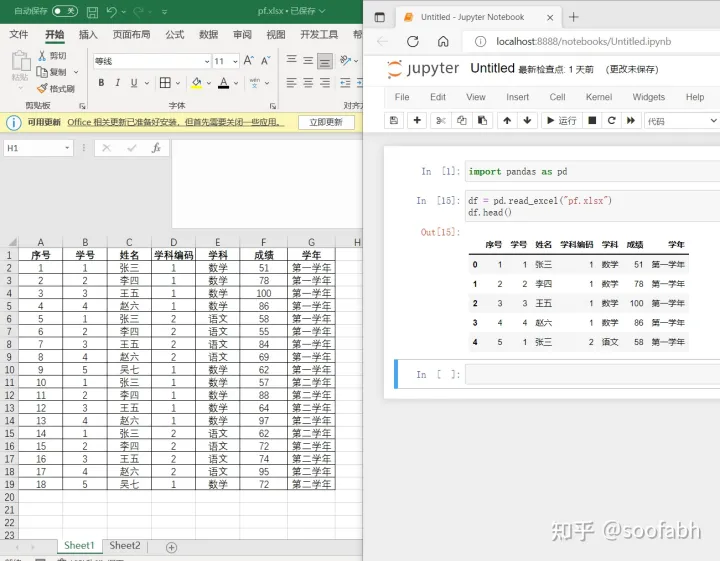
图6
如果还是图6里面的数据,我们不想要序号和学科编号那两列了,那我们就可以用usecols参数。代码有三张写法
代码分别是:
df = pd.read_excel("pf.xlsx",usecols=["B,C,E:G"])
df = pd.read_excel("pf.xlsx",usecols=[1,2,4,5,6])
df = pd.read_excel("pf.xlsx",usecols=["学号,姓名,学科,成绩,学年"])上面三个读取方式是等效的
不过楼主觉得大部分情况直接读取所有的列就行。真要去掉一定不要的列,读取完成后再去掉也可以
这个参数还是比较重要的,如果我们的数据中学号是从001开始的,那我们直接读取的话会怎么样呢,我们来看一下:
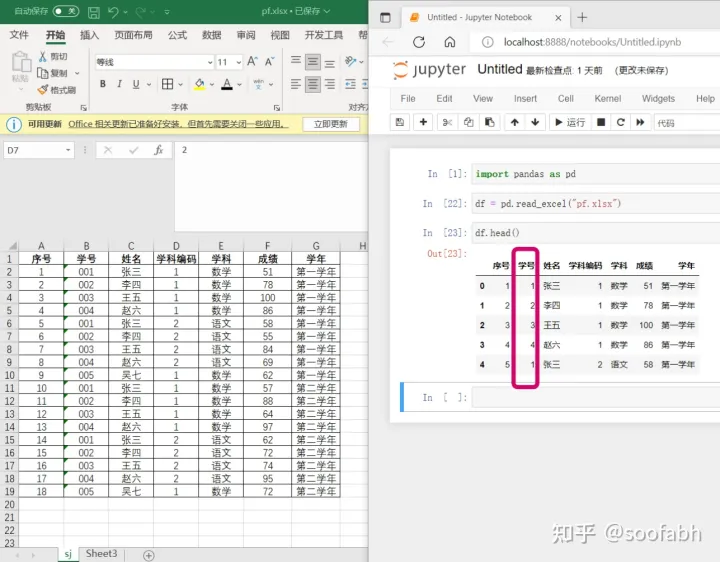
图7
可以看到,读取之后,学号被推断成了int类型
这时候我们就要用到dtype这个参数了,我们直接来看结果:

图8
还有几个不常用但有些用处的参数,我们简单的来讲一下
接下来让我们来看另一种情况,如果第一学年和第二学年的数据被分别放在两张表面,我们该怎么读取数据呢?首先,笨办法我们可以写两遍read_excel,搭配sheet_name参数。但还有一种更加简单也节约时间的方法:
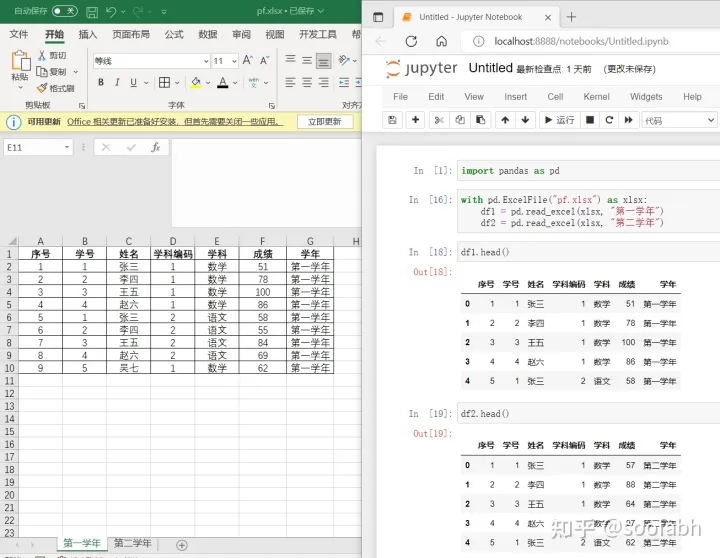
图7
这个例子里面使用了ExcelFile这个方法,打开一次,读取多张表
另外还有一种方法,就是直接在read_excel里面直接传入表名的列表,代码如下:
data = pd.read_excel("pf.xlsx", ["第一学年", "第二学年"])但还是推荐用ExcelFile方法,因为直接用read_excel的话无法对两张表就行不同的操作。比如,如果第一表的行索引在第一列,第二张表的行索引在第二列,那直接用read_excel就无法处理。
关于read_excel就先讲这么多了,如果有什么遗漏或者不清楚的大家可以私信楼主
下一篇我们来讲to_excel,也就是pandas导出excel文件
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
CSV.open(name,"r").eachdo|row|putsrowend我得到以下错误:CSV::MalformedCSVErrorUnquotedfieldsdonotallow\ror\n文件名是一个.txt制表符分隔文件。我是专门做的。我有一个.csv文件,我转到excel,并将文件保存为.txt制表符分隔的文件。所以它是制表符分隔的。CSV.open不应该能够读取制表符分隔的文件吗? 最佳答案 尝试像这样指定字段分隔符:CSV.open("name","r",{:col_sep=>"\t"}).eachdo|row|
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于