SALib是一个基于python进行敏感性分析的开源库,SALib提供一个解耦的工作流,意味着它不直接与数学或计算模型交互,SALib 负责使用其中一个采样函数(sample functions)生成模型输入,并使用其中一个分析函数(analyze functions)计算模型输出的灵敏度指数。使用 SALib 进行敏感性分析遵循四个步骤:
对Ishigami function进行Sobol敏感性分析,因为Ishigami函数表现出很强的非线性和非单调性,所以常用来测试不确定性和敏感性分析方法

SALib的采样和分析存储在不同的模块中,例如导入saltelli采样函数和sobol分析函数,使用Ishigami作为测试函数,numpy用于存储模型输入和输出
from SALib.sample import saltelli
from SALib.analyze import sobol
from SALib.test_functions import Ishigami
import numpy as npproblem = {
'num_vars':3,
'names':['x1','x2','x3'],
'bounds':[[-3.14159265359, 3.14159265359],
[-3.14159265359, 3.14159265359],
[-3.14159265359, 3.14159265359]]
}
使用saltelli生成样本
param_values = saltelli.sample(problem,1024)
param_values是一个numpy矩阵,其大小为(8192, 3),saltelli会生成N*(2D+2)个样本,其中N=1024(传入参数),D=3(模型输入数量)。参数calc_second_order=False表示不包括二阶指数,采样数变为N*(D+2)
param_values
array([[-3.13238877, -0.77619428, -0.32827189],
[-0.08283496, -0.77619428, -0.32827189],
[-3.13238877, 0.3589515 , -0.32827189],
...,
[-0.93572828, 0.80073797, 0.99095159],
[-0.93572828, 0.81914574, 2.70901007],
[-0.93572828, 0.81914574, 0.99095159]])param_values.shape
(8192, 3)SALib不直接参与数学或计算模型的评估,如果模型是用python书写,可以直接循环遍历每个样本输入和评估模型
Y = np.zeros([param_values.shape[0]])
for i,X in enumerate(param_values):
Y[i] = evaluate_model(X)如果模型不是python书写,可以保存模型的输入输出
np.savetext('param_values.txt',param_values)
Y = np.loadtxt('outputs.txt',float)本例中使用Ishigami函数评估样本数据
Y = Ishigami.evaluate(param_values)
Yarray([ 3.426362 , 3.3527401 , 0.85463176, ..., 2.72470174,
-1.40463805, 2.85339365])在得到模型的输出后可以计算敏感性指数。本例中使用sobol.analyze,会计算一阶,二阶和总阶指数
Si = sobol.analyze(problem,Y,print_to_console=True) ST ST_conf
x1 0.555860 0.080045
x2 0.441898 0.034177
x3 0.244675 0.025569
S1 S1_conf
x1 0.316832 0.068707
x2 0.443763 0.046636
x3 0.012203 0.064176
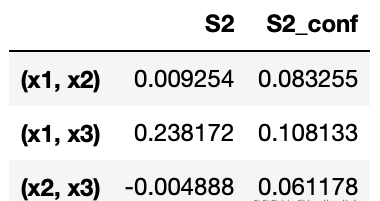
S2 S2_con
(x1, x2) 0.009254 0.093058
(x1, x3) 0.238172 0.111655
(x2, x3) -0.004888 0.066105
Si是一个字典,关键词有"S1", “S2”, “ST”, “S1_conf”, “S2_conf”, and “ST_conf”。_conf存储相应的置信区间,置信水平在95%。可以使用print_to_console=True 打印所有的指数,或者直接取键值。
Si{'S1': array([0.31683154, 0.44376306, 0.01220312]),
'S1_conf': array([0.06314249, 0.05230396, 0.05764901]),
'ST': array([0.55586009, 0.44189807, 0.24467539]),
'ST_conf': array([0.08582851, 0.04184123, 0.02424759]),
'S2': array([[ nan, 0.00925429, 0.23817211],
[ nan, nan, -0.0048877 ],
[ nan, nan, nan]]),
'S2_conf': array([[ nan, 0.08325501, 0.10813299],
[ nan, nan, 0.06117807],
[ nan, nan, nan]])}print(Si['S1'])[0.31683154 0.44376306 0.01220312]可以看出x1和x2表现出了一阶灵敏性,但是x3没有一阶效应
如果总阶指数基本上比一阶指数大,则可能发生了高阶交互作用,可以查看二阶指数
print('x1-x2:',Si['S2'][0,1])
print('x1-x3:',Si['S2'][0,2])
print('x2-x3:',Si['S2'][1,2])x1-x2: 0.00925429303490799
x1-x3: 0.2381721095685646
x2-x3: -0.004887704633467273
x1和x3之间有较强的交互,有时也会出现计算误差,如x2-x3指数为负,随着样本的增加,这些误差会缩小。
输出也可以变成Pandas DataFrame从而进行其它分析
total_si,first_si,second_si = Si.to_df()
second_si
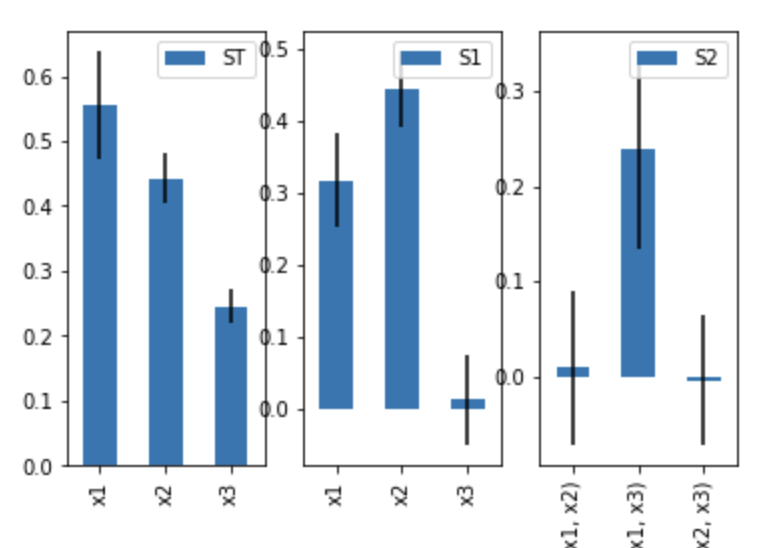
为了方便起见,SALib提供了基本的绘图功能
Si.plot()

参数a,b将接受敏感性分析,但是x不会
首先导入需要的库
import numpy as np
import matplotlib.pyplot as plt
from SALib.sample import saltelli
from SALib.analyze import sobol定义抛物线函数
def parabola(x,a,b):
return a + b*x**2字典描述只包含a,b的问题
problem = {
'num_vars':2,
'names':['a','b'],
'bounds':[[0,1]]*2
}采样,评估,分析。此例中选举100个x的取值,针对需要进行敏感性分析的a,b的每个样本(共384个)计算y值,因此y的大小为(384, 100)
param_values = saltelli.sample(problem,2**6)
print(param_values.shape)(384, 2)x = np.linspace(-1,1,100)
y = np.array([parabola(x,*params) for params in param_values])print(x.shape)
print(y.shape)(100,)
(384, 100)print(y)[[0.421875 0.40593913 0.39032847 ... 0.39032847 0.40593913 0.421875 ]
[1.21875 1.20281413 1.18720347 ... 1.18720347 1.20281413 1.21875 ]
[0.859375 0.82594091 0.79318915 ... 0.79318915 0.82594091 0.859375 ]
...
[0.640625 0.61531508 0.59052169 ... 0.59052169 0.61531508 0.640625 ]
[1.21875 1.19219021 1.16617246 ... 1.16617246 1.19219021 1.21875 ]
[1.1875 1.16219008 1.13739669 ... 1.13739669 1.16219008 1.1875 ]]
此例中的敏感性指数是一个长度为100的列表,每个元素是一个如上例中的字典
sobol_indices = [sobol.analyze(problem,Y) for Y in y.T]
sobol_indices[0]{'S1': array([0.49526584, 0.49526584]),
'S1_conf': array([0.17061222, 0.21853518]),
'ST': array([0.49745084, 0.49672251]),
'ST_conf': array([0.15376801, 0.16325137]),
'S2': array([[ nan, 0.00436999],
[ nan, nan]]),
'S2_conf': array([[ nan, 0.39998034],
[ nan, nan]])}len(sobol_indices)100
接下来单独分析每个x对应的指数,提取一阶指数绘图
# 提取100个a,b一阶指数
S1s = np.array([s['S1'] for s in sobol_indices])
fig = plt.figure(figsize=(10,6),constrained_layout = True)
gs = fig.add_gridspec(2,2)
ax0 = fig.add_subplot(gs[:,0])
ax1 = fig.add_subplot(gs[0,1])
ax2 = fig.add_subplot(gs[1,1])
for i,ax in enumerate([ax1,ax2]):
ax.plot(x,S1s[:,i],
label=r'S1$_\mathregular{{{}}}$'.format(problem["names"][i]),
color = 'black')
ax.set_xlabel('x')
ax.set_ylabel('First-order Sobol index')
ax.set_ylim(0,1.04)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax.legend(loc='upper right')
ax0.plot(x,np.mean(y,axis=0),label="Mean", color='black')
prediction_interval = 95
ax0.fill_between(x,
np.percentile(y, 50 - prediction_interval/2., axis=0),
np.percentile(y, 50 + prediction_interval/2., axis=0),
alpha=0.5, color='black',
label=f"{prediction_interval} % prediction interval")
ax0.set_xlabel("x")
ax0.set_ylabel("y")
ax0.legend(title=r"$y=a+b\cdot x^2$",
loc='upper center')._legend_box.align = "left"
plt.show()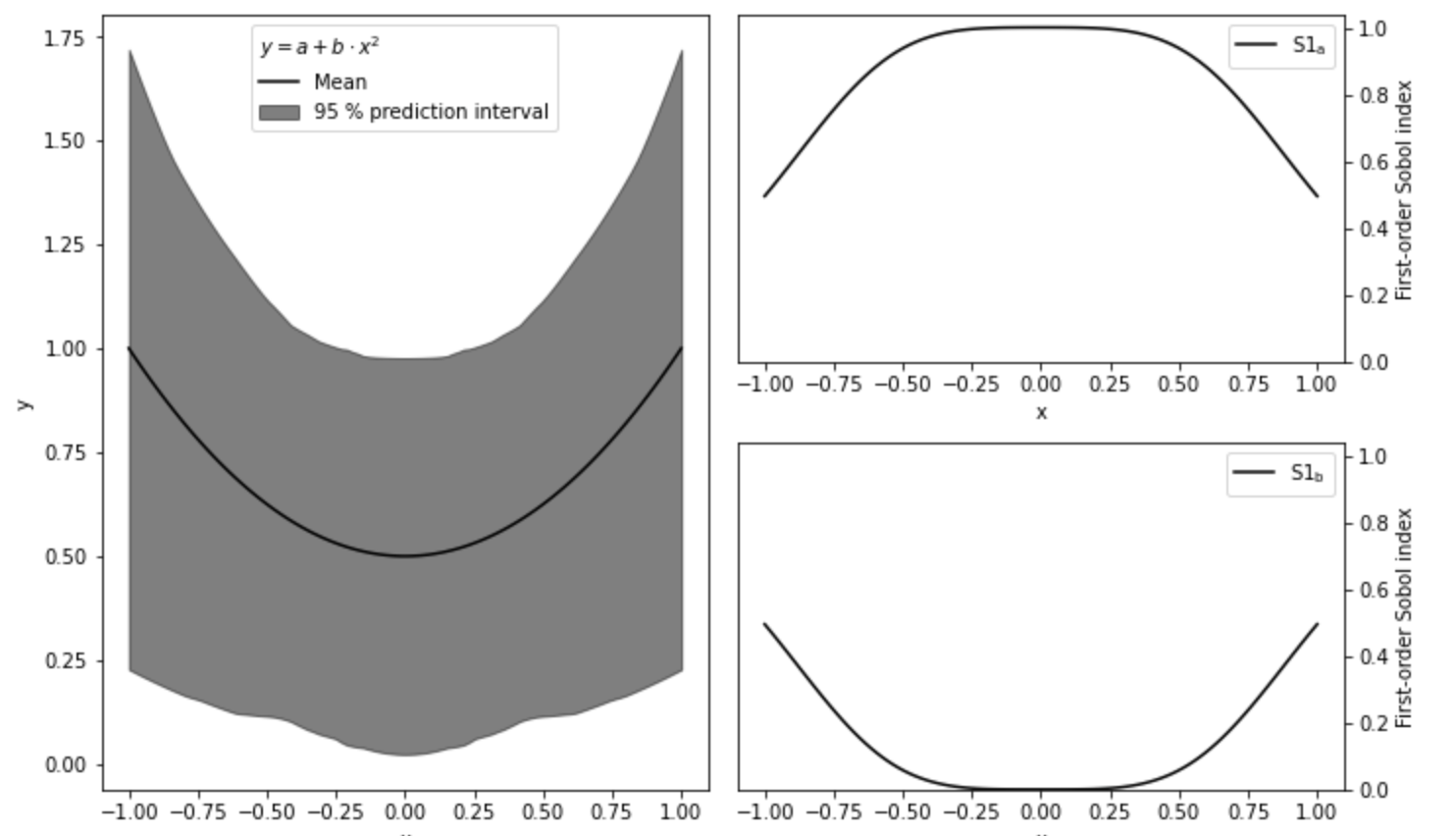
左图为每个x对应不同a,b取值下y的均值以及95%置信区间,右图为参数a,b的一阶指数。由图可知,在x=0时,y完全由参数a决定,参数b由于x而消失,x的绝对值越大,参数b对变化贡献越大,参数a相应越小
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht