从演化历史看大型网站架构
杨传伟
(石家庄铁道大学信息科学与技术学院,河北省,石家庄市,050043)
摘 要:本文以大型网站系统的特点、大型网站架构演化发展历程以及大数据与高并发为切入和论述点,由浅入深、由简到繁地对大型网站架构设计展开叙述,首先通述其特点,之后介绍大型网站架构的历史发展历程,从其发展历程中总结出每一代架构是如何一步步发现问题并解决问题的。最后会以大数据和高并发为重点,着重介绍秒杀架构设计是如何实现高并发的。通过这篇文章,您可以对大型网站架构有一个整体的认识和了解。
关键词:高并发;大数据;分布式
一个成熟的大型网站(如淘宝、京东等)的系统架构并不是开始设计就具备完整的高性能、高可用、安全等特性,它总是随着用户量的增加,业务功能的扩展逐渐演变完善的,在这个过程中,开发模式、技术架构、设计思想也发生了很大的变化,就连技术人员也从几个人发展到一个部门甚至一条产品线。所以成熟的系统架构是随业务扩展而完善出来的,并不是一蹴而就;不同业务特征的系统,会有各自的侧重点,例如淘宝,要解决海量的商品信息的搜索、下单、支付,例如腾讯,要解决数亿的用户实时消息传输,百度它要处理海量的搜索请求,他们都有各自的业务特性,系统架构也有所不同。尽管如此我们也可以从这些不同的网站背景下,找出其中共用的技术,这些技术和手段可以广泛运行在大型网站系统的架构中,下面就通过介绍大型网站系统的特点和演化过程,来认识这些技术和手段。
高并发,大流量:需要面对高并发用户,大流量访问。Google 日均 PV 35 亿,日IP访问数 3 亿;腾讯 QQ 的最大在线用户数 1.4 亿 (2011年数据)。
高可用:系统 7 x 24 小时不间断服务。
海量数据:需要存储、管理海量数据,需要使用大量服务器。Facebook 每周上传的照片数量接近10 亿,百度收录的网页数目有数百亿,Google 有近百万台服务器为全球用户提供服务。
用户分布广泛,网络情况复杂:许多大型互联网站都是为全球用户提供服务的,用户分布范围广,各地网络情况千差万别。在国内,还有各个运营 商网络互通困难的问题。
安全环境恶劣:由于互联网的开放性,使得互联网站更容易受到攻击,大型网站几乎每天都会被黑客攻击。
需求快速变更,发布频繁:和传统软件的版本发布频率不同,互联网产品为快速适应市场,满足用户需求,其产品发布频率极高。一般大型网站的产品每周都有新版本发布上线,中小型网站的发布更频繁,有时候一天会发布几十次。
渐进式发展:几乎所有的大型互联网网站都是从一个小网站开始,渐进地发展起来的。Facebook是扎克伯格同学在哈佛大学的宿舍里开发的;Google的第一台服务器部署在斯坦福大学的实验室;阿里巴巴是在马云家的客厅诞生的。好的互联网产品都是慢慢运营出来的,不是一开始就开发好的,这也正好与网站架构的发展演化过程对应。
大型网站都是从小型网站发展而来,网站架构也是一样,是从小型网站架构逐步演化而来。小型网站最开始没有太多人访问,只需要一台服务器就绰绰有余,这时的网站架构如下图所示:
应用程序、数据库、文件等所有资源都在一台服务器上。
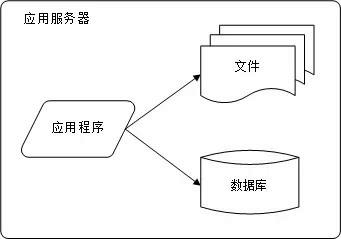
图2-1 初始网站架构
随着网站业务的发展,一台服务器逐渐不能满足需求:越来越多的用户访问导致性能越来越差,越来越多的数据导致存储空间不足。这时就需要将应用和数据分离。应用和数据分离后整个网站使用3台服务器:应用服务器、文件服务器和数据库服务器。这3台服务器对硬件资源的要求各不相同:
(1)应用服务器需要处理大量的业务逻辑,因此需要更快更强大的CPU;
(2)数据库服务器需要快速磁盘检索和数据缓存,因此需要更快的磁盘和更大的内存;
(3)文件服务器需要存储大量用户上传的文件,因此需要更大的硬盘。
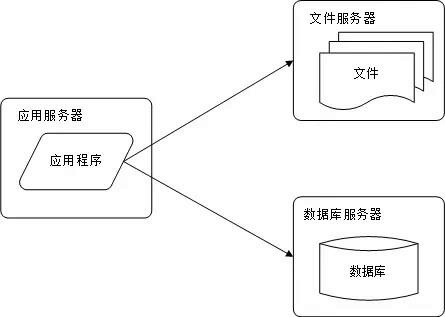
图2-2 应用服务与数据服务分离
网站访问的特点和现实世界的财富分配一样遵循二八定律:80% 的业务访问集中在20% 的数据上。既然大部分业务访问集中在一小部分数据上,那么如果把这一小部分数据缓存在内存中,就可以减少数据库的访问压力,提高整个网站的数据访问速度,改善数据库的写入性能了。网站使用的缓存可以分为两种:缓存在应用服务器上的本地缓存和缓存在专门的分布式缓存服务器上的远程缓存。
(1)本地缓存的访问速度更快一些,但是受应用服务器内存限制,其缓存数据量有限,而且会出现和应用程序争用内存的情况。
(2)远程分布式缓存可以使用集群的方式,部署大内存的服务器作为专门的缓存服务器,可以在理论上做到不受内存容量限制的缓存服务。
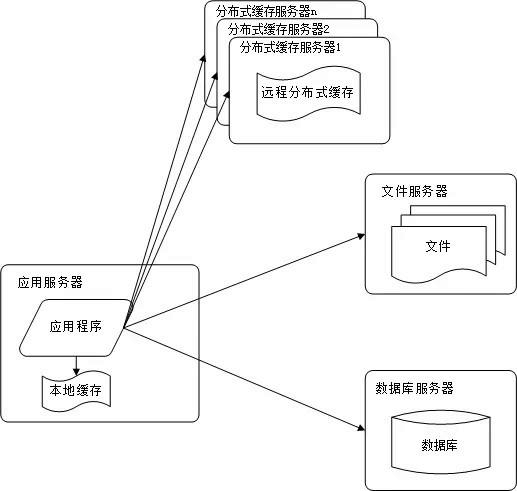
图2-3 缓存改善性能
使用集群是网站解决高并发、海量数据问题的常用手段。当一台服务器的处理能力、存储空间不足时,不要企图去更换更强大的服务器,对大型网站而言,不管多么强大的服务器,都满足不了网站持续增长的业务需求。这种情况下,更恰当的做法是增加一台服务器分担原有服务器的访问及存储压力。对网站架构而言,只要能通过增加一台服务器的方式改善负载压力,就可以以同样的方式持续增加服务器不断改善系统性能,从而实现系统的可伸缩性。应用服务器实现集群是网站可伸缩架构设计中较为简单成熟的一种,如下图所示:
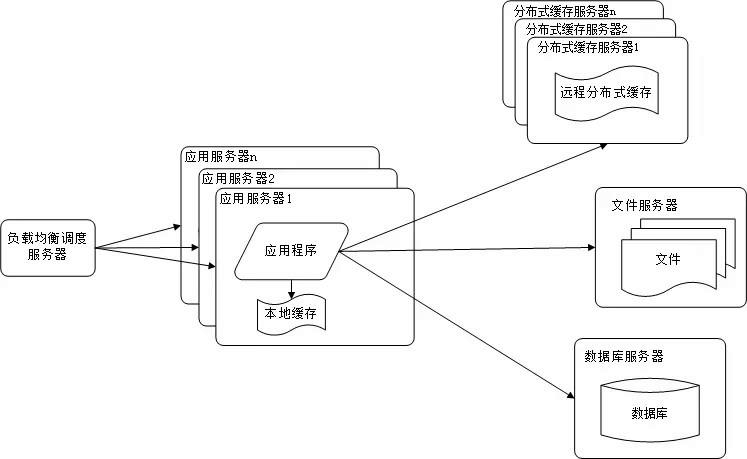
图2-4 应用服务器集群
随着网站业务不断发展,用户规模越来越大,由于中国复杂的网络环境,不同地区的用户访问网站时,速度差别也极大。有研究表明,网站访问延迟和用户流失率正相关,网站访问越慢,用户越容易失去耐心而离开。为了提供更好的用户体验,留住用户,网站需要加速网站访问速度。主要手段有使用 CDN 和方向代理。如下图所示:
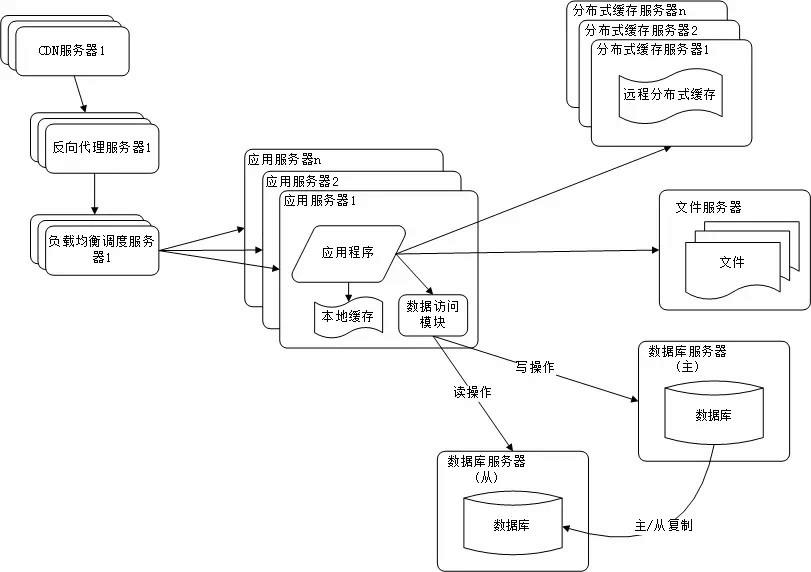
图2-5 反向代理和CDN加速
任何强大的单一服务器都满足不了大型网站持续增长的业务需求。数据库经过读写分离后,从一台服务器拆分成两台服务器,但是随着网站业务的发展依然不能满足需求,这时需要使用分布式数据库。文件系统也一样,需要使用分布式文件系统。分布式数据库是网站数据库拆分的最后手段,只有在单表数据规模非常庞大的时候才使用。不到不得已时,网站更常用的数据库拆分手段是业务分库,将不同业务的数据部署在不同的物理服务器上。如下图所示:
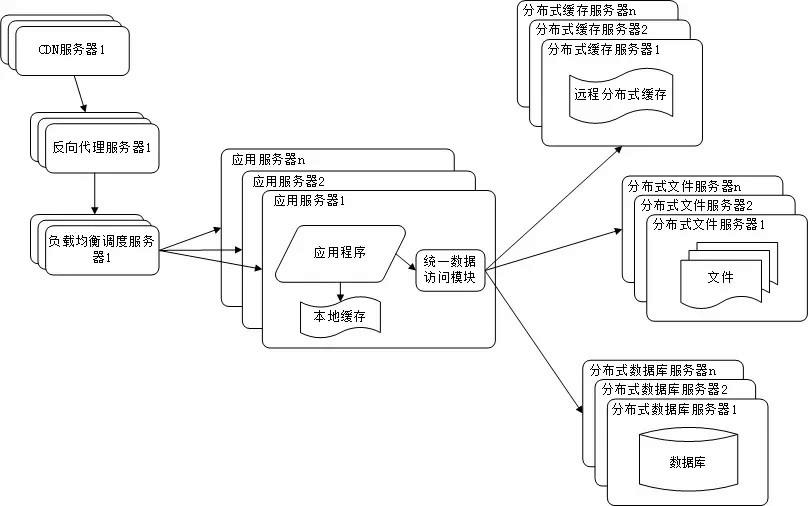
图2-6 分布式文件系统和数据库
随着业务拆分越来越小,存储系统越来越庞大,应用系统的整体复杂度呈指数级增加,部署维护越来越困难。由于所有应用要和所有数据库系统连接,在数万台服务器规模的网站中,这些连接的数目是服务器规模的平方,导致数据库连接资源不足,拒绝服务。
既然每一个应用系统都需要执行许多相同的业务操作,比如用户管理、商品管理等,那么可以将这些共用的业务提取出来,独立部署。由这些可复用的业务连接数据库,提供共用业务服务,而应用系统只需要管理用户界面,通过分布式服务调用共用业务服务完成具体业务操作。如下图所示:
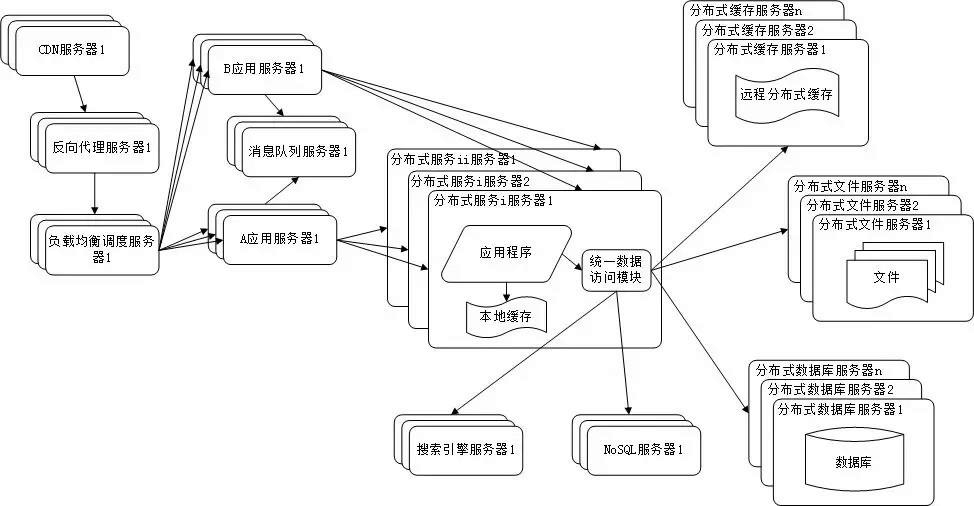
图2-7 分布式微服务
什么是秒杀?通俗一点讲就是网络商家为促销等目的组织的网上限时抢购活动。
比如说京东秒杀,就是一种定时定量秒杀,在规定的时间内,无论商品是否秒杀完毕,该场次的秒杀活动都会结束。这种秒杀,对时间不是特别严格,只要下手快点,秒中的概率还是比较大的。 淘宝以前就做过一元抢购,一般都是限量 1 件商品,同时价格低到令人发齿,这种秒杀一般都在开始时间 1 到 3 秒内就已经抢光了,参与这个秒杀一般都是看运气的,不必太强求。
瞬时并发量大:秒杀时会有大量用户在同一时间进行抢购,瞬时并发访问量突增 10 倍,甚至 100 倍以上都有。
库存量少:一般秒杀活动商品量很少,这就导致了只有极少量用户能成功购买到。
业务简单:流程比较简单,一般都是下订单、扣库存、支付订单。
现有业务的冲击:秒杀是营销活动中的一种,如果和其他营销活动应用部署在同一服务器上,肯定会对现有其他活动造成冲击,极端情况下可能导致整个电商系统服务宕机。
直接下订单:下单页面是一个正常的 URL 地址,需要控制在秒杀开始前,不能下订单,只能浏览对应活动商品的信息。简单来说,需要 Disable 订单按钮。
页面流量突增:秒杀活动开始前后,会有很多用户请求对应商品页面,会造成后台服务器的流量突增,同时对应的网络带宽增加,需要控制商品页面的流量不会对后台服务器、DB、Redis 等组件的造成过大的压力
限流:由于活动库存量一般都是很少,对应的只有少部分用户才能秒杀成功。所以我们需要限制大部分用户流量,只准少量用户流量进入后端服务器。
削峰:秒杀开始的那一瞬间,会有大量用户冲击进来,所以在开始时候会有一个瞬间流量峰值。如何把瞬间的流量峰值变得更平缓,是能否成功设计好秒杀系统的关键因素。实现流量削峰填谷,一般的采用缓存和MQ中间件来解决。
异步:秒杀其实可以当做高并发系统来处理,在这个时候,可以考虑从业务上做兼容,将同步的业务,设计成异步处理的任务,提高网站的整体可用性。
缓存:秒杀系统的瓶颈主要体现在下订单、扣减库存流程中。在这些流程中主要用到 OLTP 的数据库,类似 MySQL、 SQLServer、Oracle。由于数据库底层采用 B+ 树的储存结构,对应我们随机写入与读取的效率,相对较低。如果我们把部分业务逻辑迁移到内存的缓存或者 Redis 中,会极大的提高并发效率。
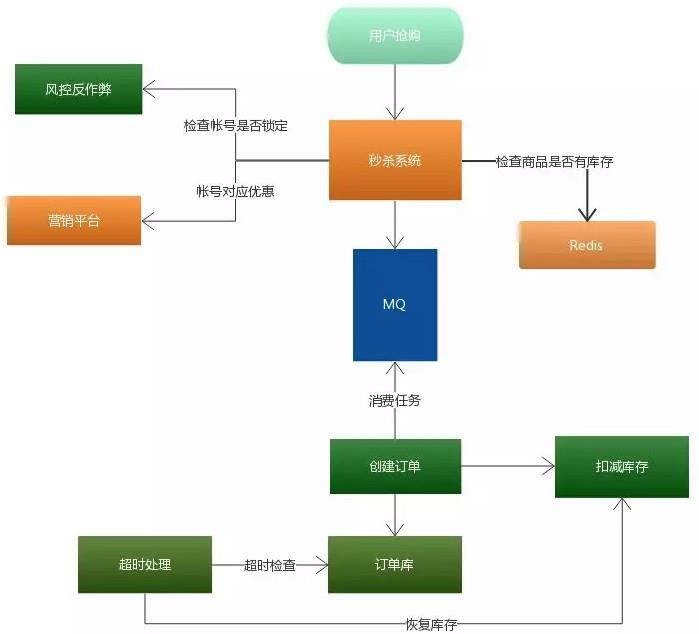
秒杀系统核心在于层层过滤,逐渐递减瞬时访问压力,减少最终对数据库的冲击。通过上面流程图就会发现压力最大的地方在哪里?
MQ 排队服务,只要 MQ 排队服务顶住,后面下订单与扣减库存的压力都是自己能控制的,根据数据库的压力,可以定制化创建订单消费者的数量,避免出现消费者数据量过多,导致数据库压力过大或者直接宕机。
库存服务专门为秒杀的商品提供库存管理,实现提前锁定库存,避免超卖的现象。同时通过超时处理任务发现已抢到商品,但未付款的订单,并在规定付款时间后,处理这些订单,将恢复订单商品对应的库存量。整体架构如下图所示:
[1] 阿里巴巴面试官手册
[2] 简书 互联网三高架构:高并发、高性能、高可用 作者pigness
https://www.jianshu.com/p/fd8ff58ba5d2
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
在我的路线文件中我有:match'graphs/(:id(/:action))'=>'graphs#(:action)'如果是GET请求(工作)或POST请求(不工作),我想匹配它我知道我可以使用以下方法在资源中声明POST请求:post'/'=>:show,:on=>:member但是我怎样才能为比赛做到这一点呢?谢谢。 最佳答案 如果你同时想要POST和GETmatch'graphs/(:id(/:action))'=>'graphs#(:action)',:via=>[:get,:post]编辑默认值可以设置如下match'g
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分