| 姓名(name) | 学科(subject) | 成绩(score) |
|---|---|---|
| A | 语文 | 70 |
| A | 数学 | 80 |
| A | 英语 | 90 |
| B | 语文 | 75 |
| B | 数学 | 85 |
| B | 英语 | 95 |
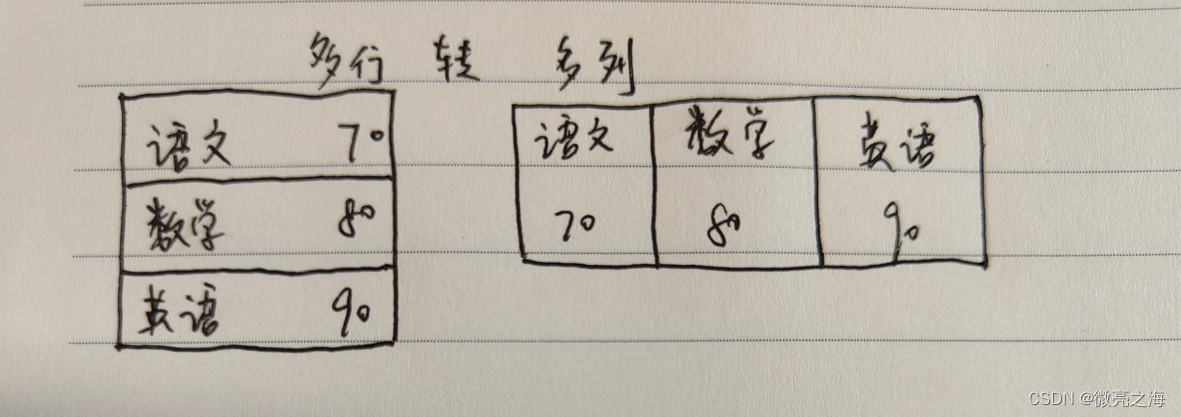
行列转换思路分析及实现
多行转多列
如果需要将上⾯的样例表转换为
姓名 | 语⽂成绩 | 数学成绩 | 英语成绩
这样的格式,就是 多行转多列
思路:
涉及到行转成列,肯定是会按照某⼀列或者某⼏列的值进⾏分组来压缩⾏数,所以会⽤到group by。
分组之后需要⽤到聚合函数,由于多列中的每列只关⼼⾃⼰对应的数据,所以要使⽤case语句进⾏选择,⾄于聚合函数,只要数据能保证唯一性,max、min、avg(数值类型)等都可以
样例SQL
select
name
,max(case subject when '数学' then score else 0 end) math
,max(case subject when '英语' then score else 0 end) english
,max(case subject when '语文' then score else 0 end) chinese
from ts
group by name;
输出过程
| name | chinese | math | english |
|---|---|---|---|
| A | max(70,0,0) | max(80,0,0) | max(90,0,0) |
| B | max(75,0,0) | max(85,0,0) | max(95,0,0) |
输出结果
| name | chinese | math | english |
|---|---|---|---|
| A | 70 | 80 | 90 |
| B | 75 | 85 | 95 |

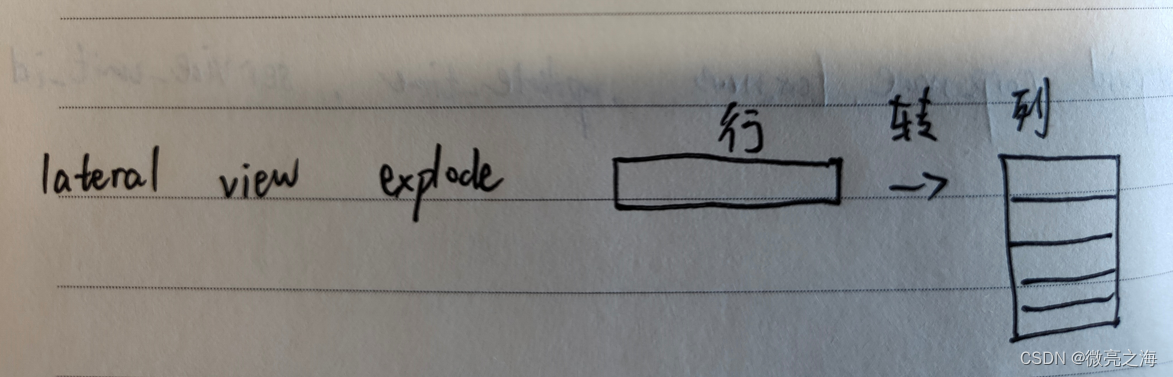
将上⾯⾏转多列的结果再转回成原始表结构的过程,就是多列转⾏
思路
列转⾏,会涉及到⾏数的增加,所以会⽤到UDTF(一进多出),⽽UDTF只是针对某⼀列的,要把这列扩展后⽣成的多⾏数据和源表中的各列拼接在⼀起,需要⽤到lateral view语法;
需要将多列⾥各列的列名(业务含义),在新数据中当做⼀个标识列,⽽与lateral view联合使⽤的explode函数是⽀持Map类型的,所以要先将原表⾥的多列变换成Map类型的⼀列,然后再⽤lateral view拆开。
样例SQL
select name,subject,score from
(
select name,map('语文',chinese,'数学',math,'英语',english) scores from
(select
name
,max(case subject when '语文' then score else 0 end) chinese
,max(case subject when '数学' then score else 0 end) math
,max(case subject when '英语' then score else 0 end) english
from ts
group by name)ts1
)ts2
lateral view explode(scores) ts3 as subject,score
ts1
| name | chinese | math | english |
|---|---|---|---|
| A | 70 | 80 | 90 |
| B | 75 | 85 | 95 |
ts2
| name | scores |
|---|---|
| A | {“语文”:“70”,“数学”:“80”,“英语”:“90”} |
| B | {“语文”:“75”,“数学”:“85”,“英语”:“95”} |
select explode(scores) from ts2;
| key | value |
|---|---|
| 语文 | 70 |
| 数学 | 80 |
| 英语 | 90 |
| 语文 | 75 |
| 数学 | 85 |
| 英语 | 95 |
输出结果
| name | subject | score |
|---|---|---|
| A | 语文 | 70 |
| A | 数学 | 80 |
| A | 英语 | 90 |
| B | 语文 | 75 |
| B | 数学 | 85 |
| B | 英语 | 95 |

| id | num | name |
|---|---|---|
| 1 | zs | 合肥 |
| 1 | ls | 南京 |
| 1 | ww | 杭州 |
| 1 | zl | 重庆 |
| 1 | sq | 郑州 |
| 2 | wb | 六安 |
| 2 | lq | 青岛 |
| 3 | dd | 三亚 |
| 3 | si | 常州 |
| 3 | sh | 武汉 |
SQL
select id,collect_list(name) names from ts group by id;
输出结果
| id | names |
|---|---|
| 3 | [“三亚”,“常州”,“武汉”] |
| 1 | [“杭州”,“合肥”,“南京”,“郑州”,“重庆”] |
| 2 | [“青岛”,“六安”] |
SQL 外面套一层concat_ws(),输出以’,'分割的字符串
select id,concat_ws(',',collect_list(name)) names from ts group by id;
输出结果
| id | names |
|---|---|
| 3 | 三亚,常州,武汉 |
| 1 | 杭州,合肥,南京,郑州,重庆 |
| 2 | 青岛,六安 |
| id | names |
|---|---|
| 3 | 三亚,常州,武汉 |
| 1 | 杭州,合肥,南京,郑州,重庆 |
| 2 | 青岛,六安 |
SQL
select id,name from ts1
lateral view explode(split(names,',')) lateral_name as name
输出结果
| id | name |
|---|---|
| 3 | 三亚 |
| 3 | 常州 |
| 3 | 武汉 |
| 1 | 杭州 |
| 1 | 合肥 |
| 1 | 南京 |
| 1 | 郑州 |
| 1 | 重庆 |
| 2 | 青岛 |
| 2 | 六安 |
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
这道题是thisquestion的逆题.给定一个散列,每个键都有一个数组,例如{[:a,:b,:c]=>1,[:a,:b,:d]=>2,[:a,:e]=>3,[:f]=>4,}将其转换为嵌套哈希的最佳方法是什么{:a=>{:b=>{:c=>1,:d=>2},:e=>3,},:f=>4,} 最佳答案 这是一个迭代的解决方案,递归的解决方案留给读者作为练习:defconvert(h={})ret={}h.eachdo|k,v|node=retk[0..-2].each{|x|node[x]||={};node=node[x]}node[
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我需要一个通过输入字符串进行计算的方法,像这样function="(a/b)*100"a=25b=50function.something>>50有什么方法吗? 最佳答案 您可以使用instance_eval:function="(a/b)*100"a=25.0b=50instance_evalfunction#=>50.0请注意,使用eval本质上是不安全的,尤其是当您使用外部输入时,因为它可能包含注入(inject)的恶意代码。另请注意,a设置为25.0而不是25,因为如果它是整数a/b将导致0(整数)。
我是ruby的新手,我正在尝试制作一个程序来自动格式化给定的字符串和数组。我试图弄清楚的一种自动格式化功能是一种用于数组的功能。假设我有一个如下例所示的数组myArray=["a","b","c"]我想把它变成一个列化的字符串,这样putsmyString就会给出`1)a``2)b``3)c`我该怎么做呢?我能找到的最接近的东西是使用.each这不是我想要的,我不能让每一行都有一个单独的条目。这一切都必须是一个带有换行符的字符串。任何帮助将不胜感激,提前致谢 最佳答案 您可以使用.map与.with_index:myArray=