遇到一个问题,就是上传的图片,在手机上可以下载了,但在电脑上怎么下载到电脑 里,包括上传的文件
点击查看页面就可以吧,在企业工作台里
我做了查看页面,小程序可以,但H5和电脑页面不行
你创建一个模型应用发布到企业工作台呢
还没有试过
移动端我们的历史教程里已经讲解了如何上传和下载文件,上传呢是依赖于表单的文件上传组件,而下载呢是依赖的小程序的文件下载API
但是附件上传到微搭里,如果是搭建PC端的应用,以上的方法就不行了。要想解决问题,我们先需要梳理几个概念。
第一个就是我回复的自定义应用和模型应用的区别。自定义应用呢可以理解为可以公开访问的应用,比如我们的H5、小程序、PC网站。
而模型应用呢可以理解为我们经常使用的网页管理后台,通常需要输入用户名和密码,登录之后有的是搭配了门户,比如可以显示待办、消息通知、常用应用和需要展示的一些通知公告信息。
如果没有复杂需求的,可能也就是简单的一个管理后台,通常左边是模块列表,右边是表格。
概念理清楚之后,要结合你自己的应用场景来进行选择。因为模型应用占用了内部账号,每个账号都需要按月支付费用,通常如果需要多人使用的,我们不建议选择搭建模型应用。而搭建自定义应用就需要考虑组件的选择问题。
微搭的组件是分为移动端的组件和PC端的组件,移动端我们因为屏幕比较小,通常是使用块状结构从上到下展示信息。而PC端应用我们通常需要使用表格组件,结合分页的功能来展示数据。
为了解决上述的问题,我们实际还原一下现实的场景。
初学者可能有个疑问,我的附件要存放到哪里呢?这里就要梳理几个思路,第一个是附件存在哪里,第二个就是附件如何访问。
微搭的底层是使用的云开发,云开发由几个基本要素组成,云函数、云数据库、云存储。我们的附件其实是存放在云存储里。对外访问的时候要换取临时链接,这个临时链接其实就是通过域名访问的一个互联网路径。
为啥要有临时路径这个概念呢?因为你使用公有云,尤其是按量付费这种模式,很容易被攻击。对方如果猜到你的附件的存放路径,可以使用脚本批量刷量,你的套餐很容易被刷爆。为了防范这个问题,你每次访问附件的时候,给你一个临时路径,有一定的有效期,过期就失效了,这样就可以保护你的资源。
那我怎么知道我的附件在哪存放的呢?通常我们附件上传到云存储后,会给你返回一个fileid,这个fileid就表示你附件的存放路径,我们需要把这个路径存放到数据库里,这样下次就知道去哪取了。
总结一下,附件真实存放在云存储里,而附件的存放路径存放在数据库里。
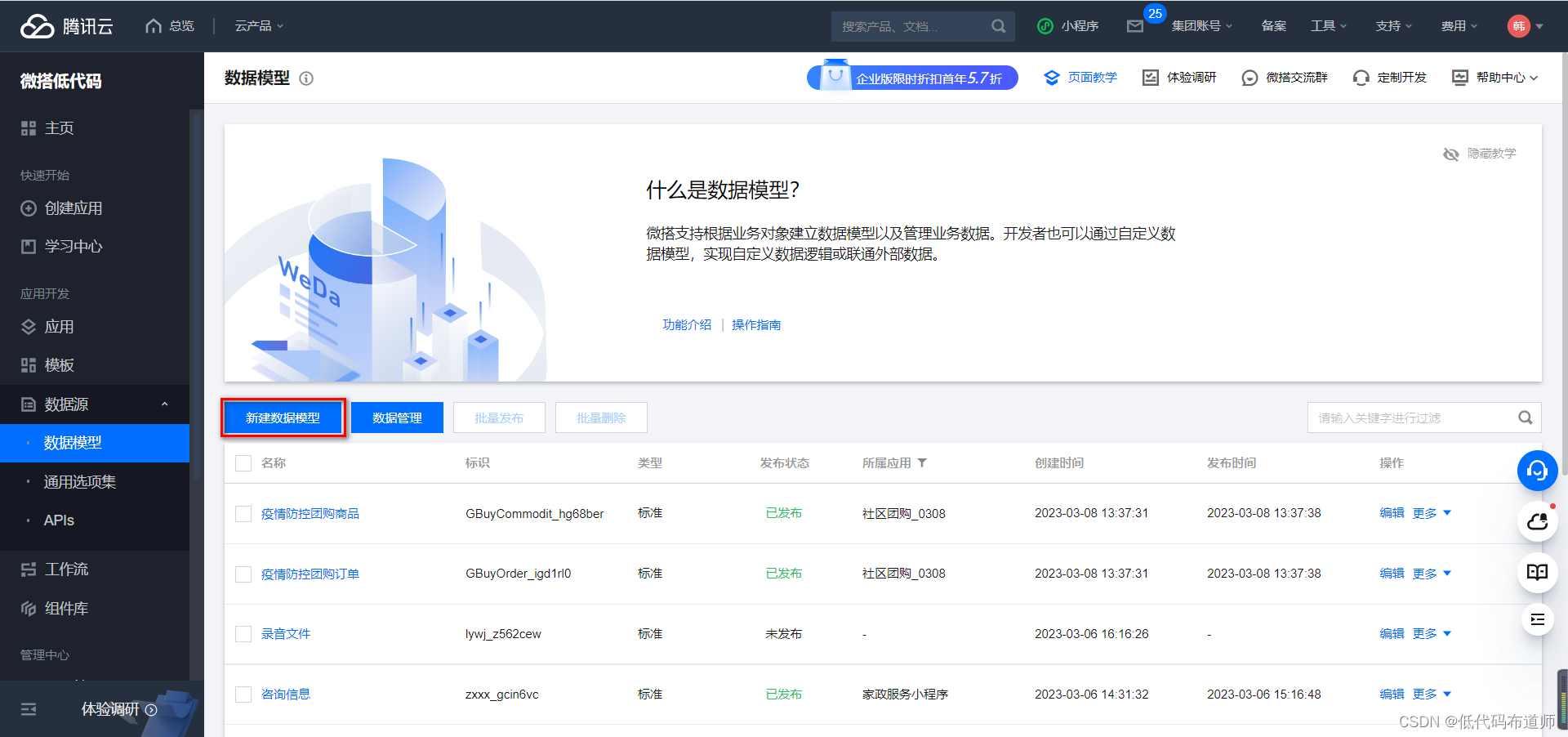
概念清楚了之后,微搭是通过字段来存放路径的,登录微搭的控制台,点击新建数据模型,输入模型的名称,系统自动生成标识
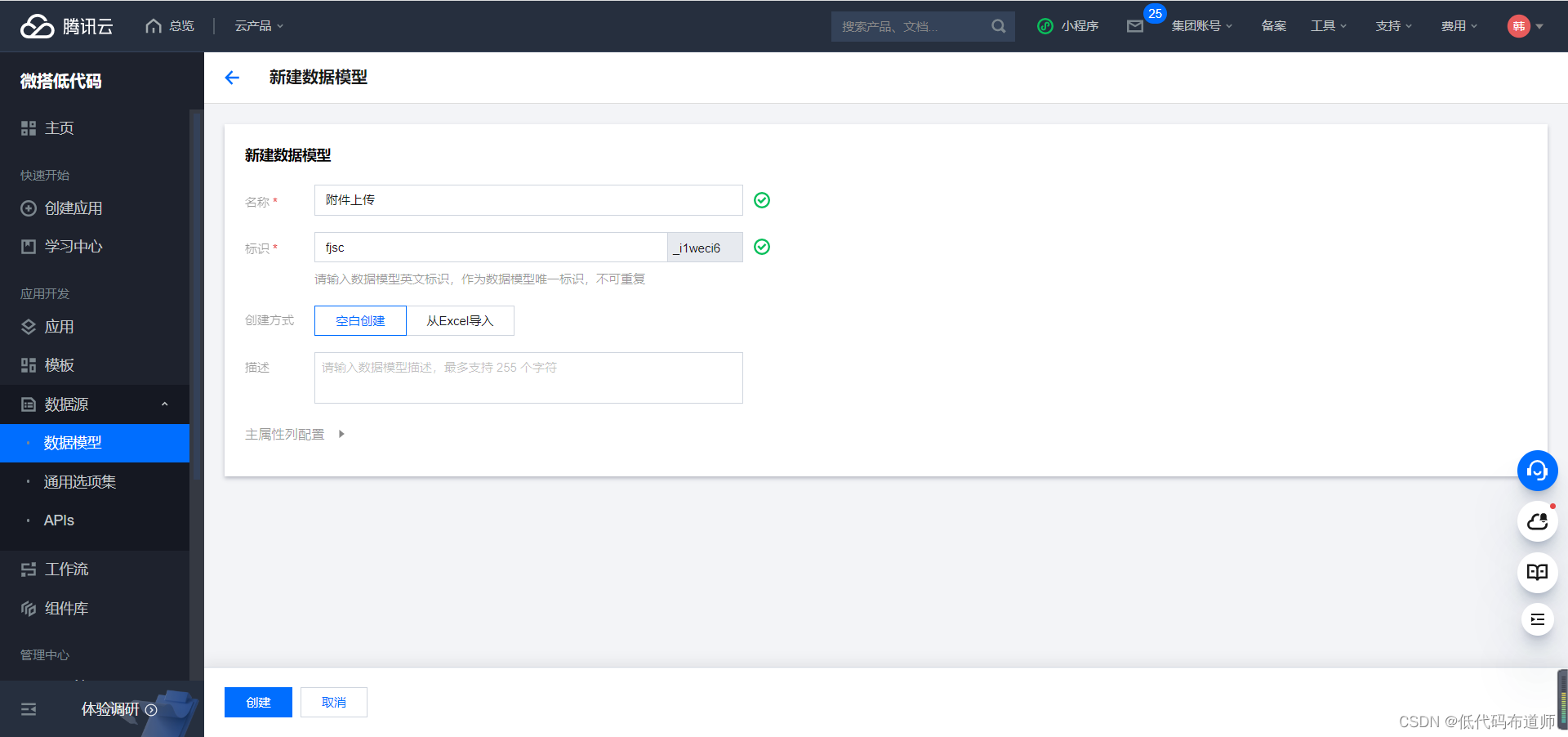
点击编辑按钮进入编辑模式,可以添加字段
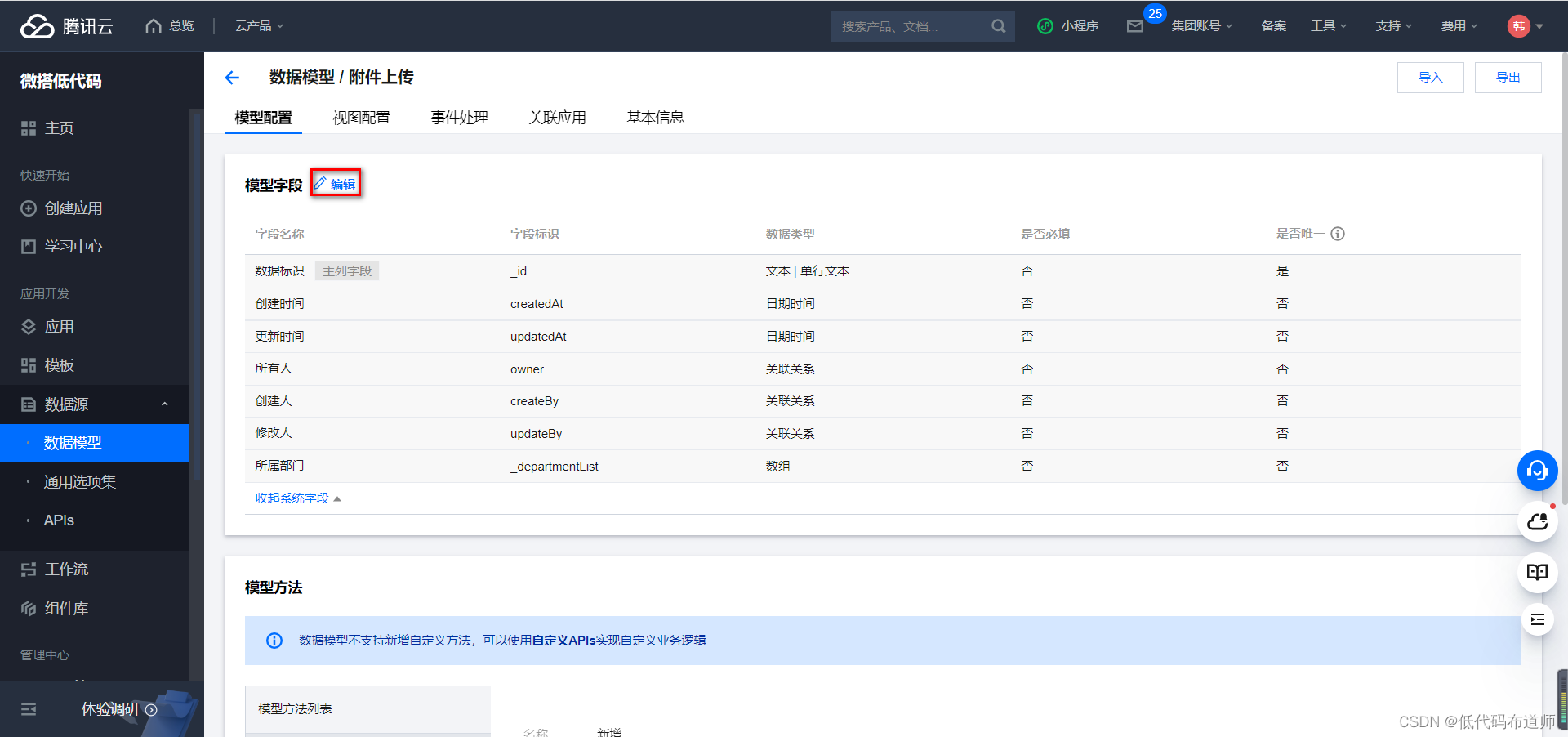
添加一个附件字段,字段类型选择文件
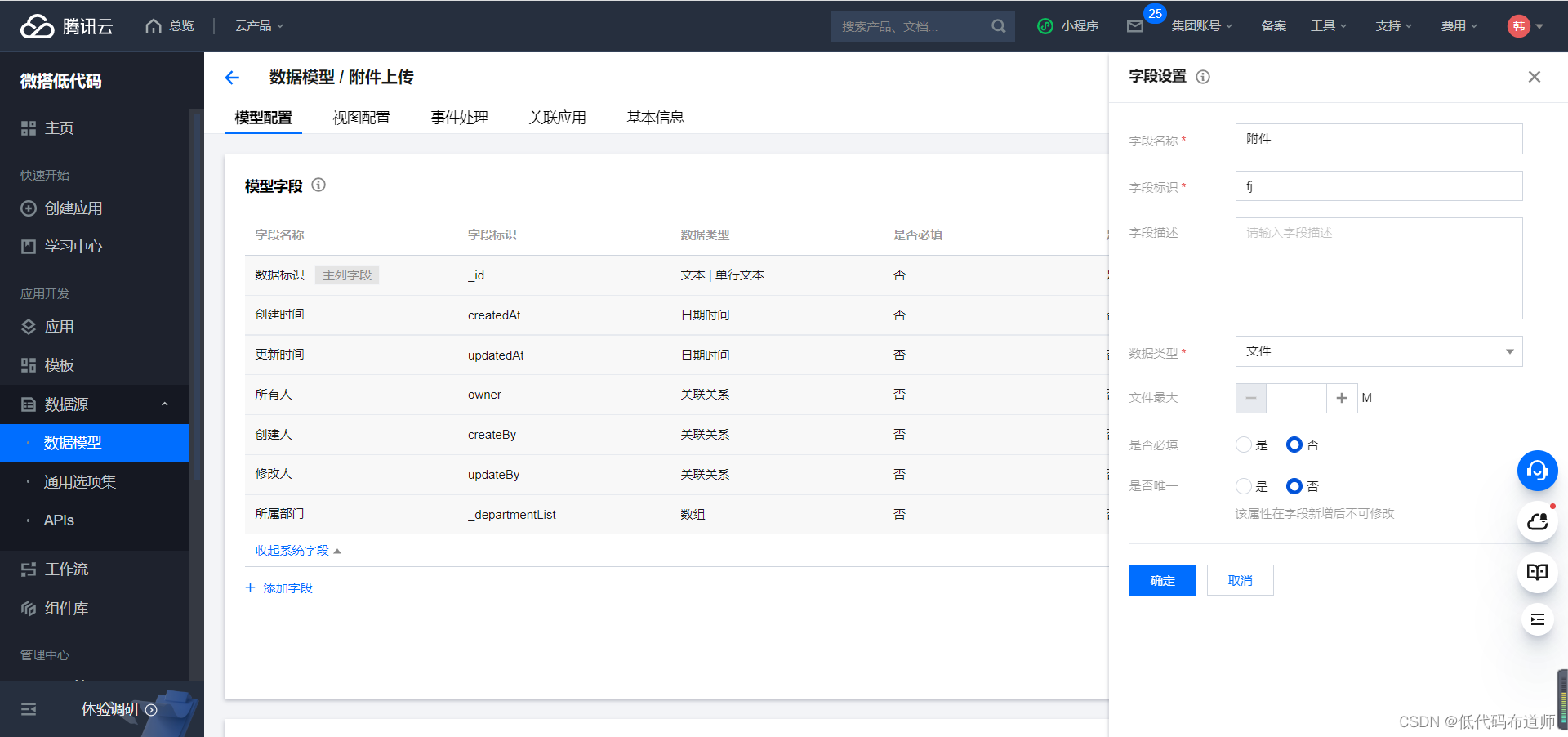
回到数据模型列表,点击更多,点击管理数据
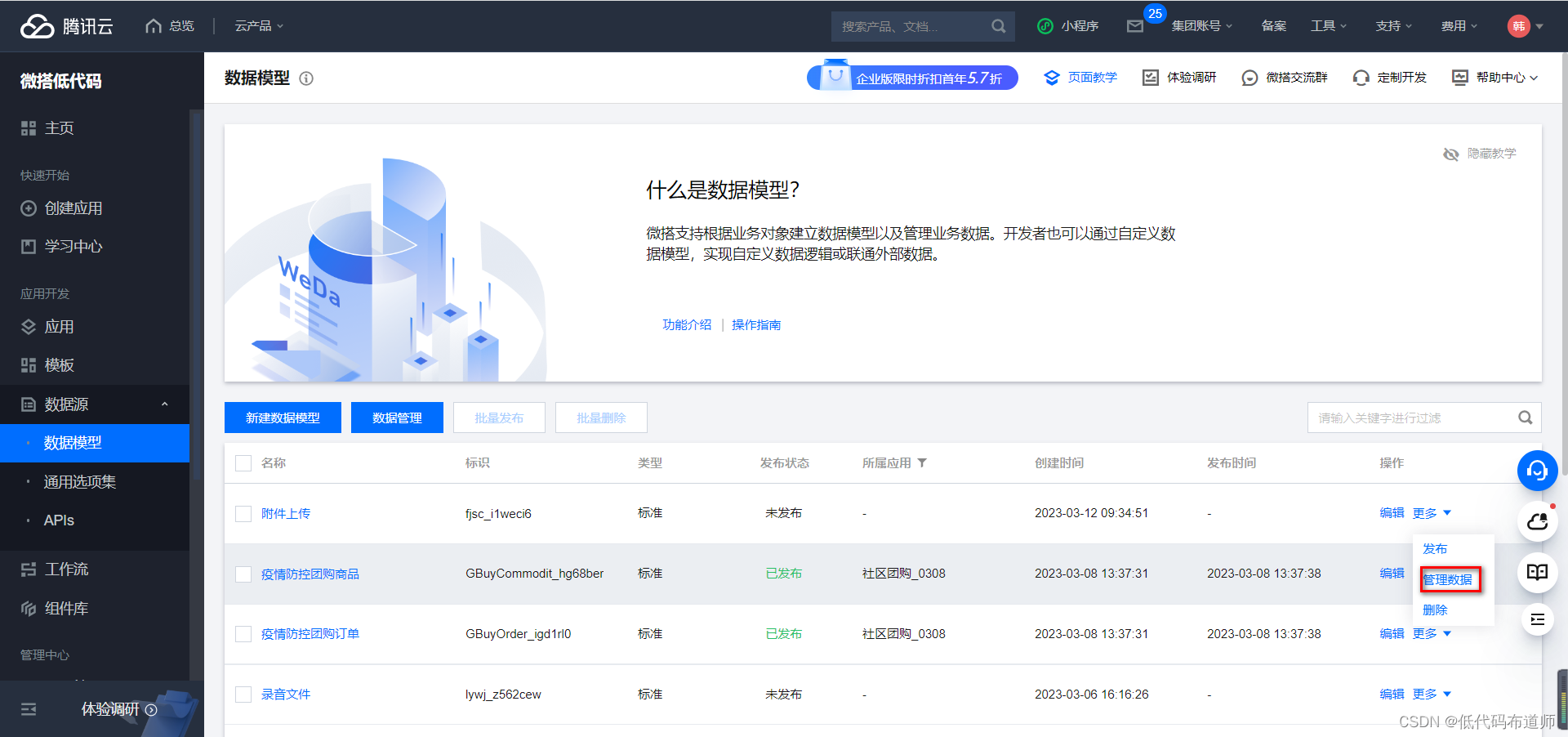
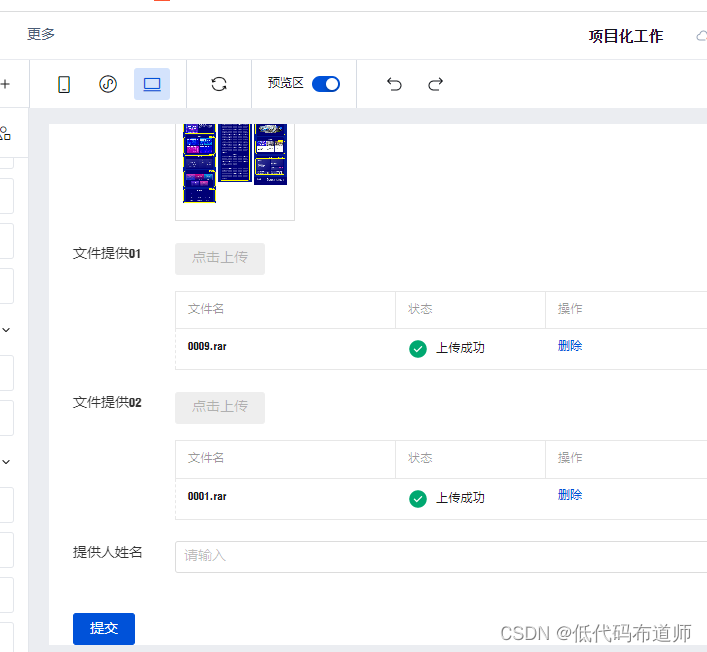
上传一个附件
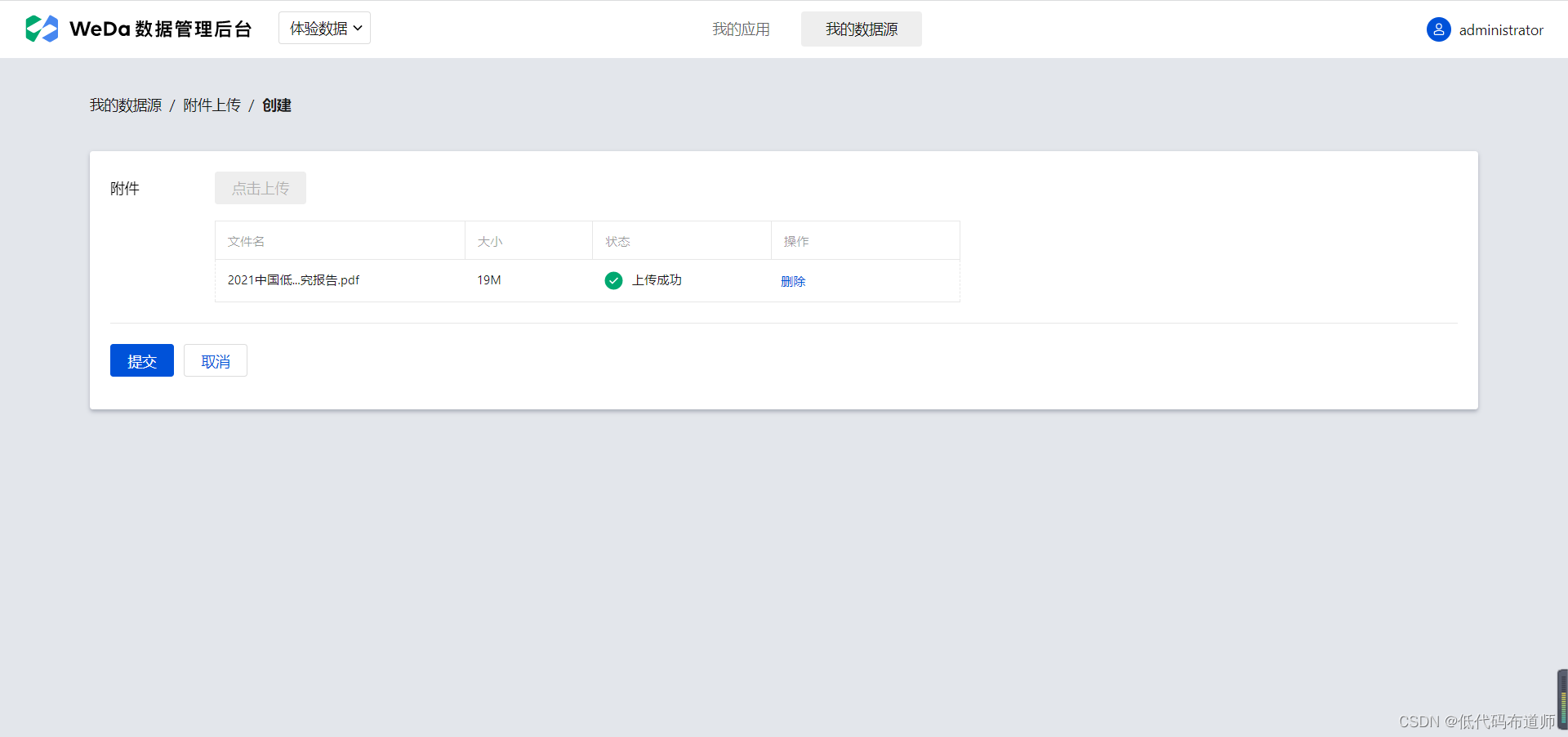
可以看到查看页面并不能下载附件
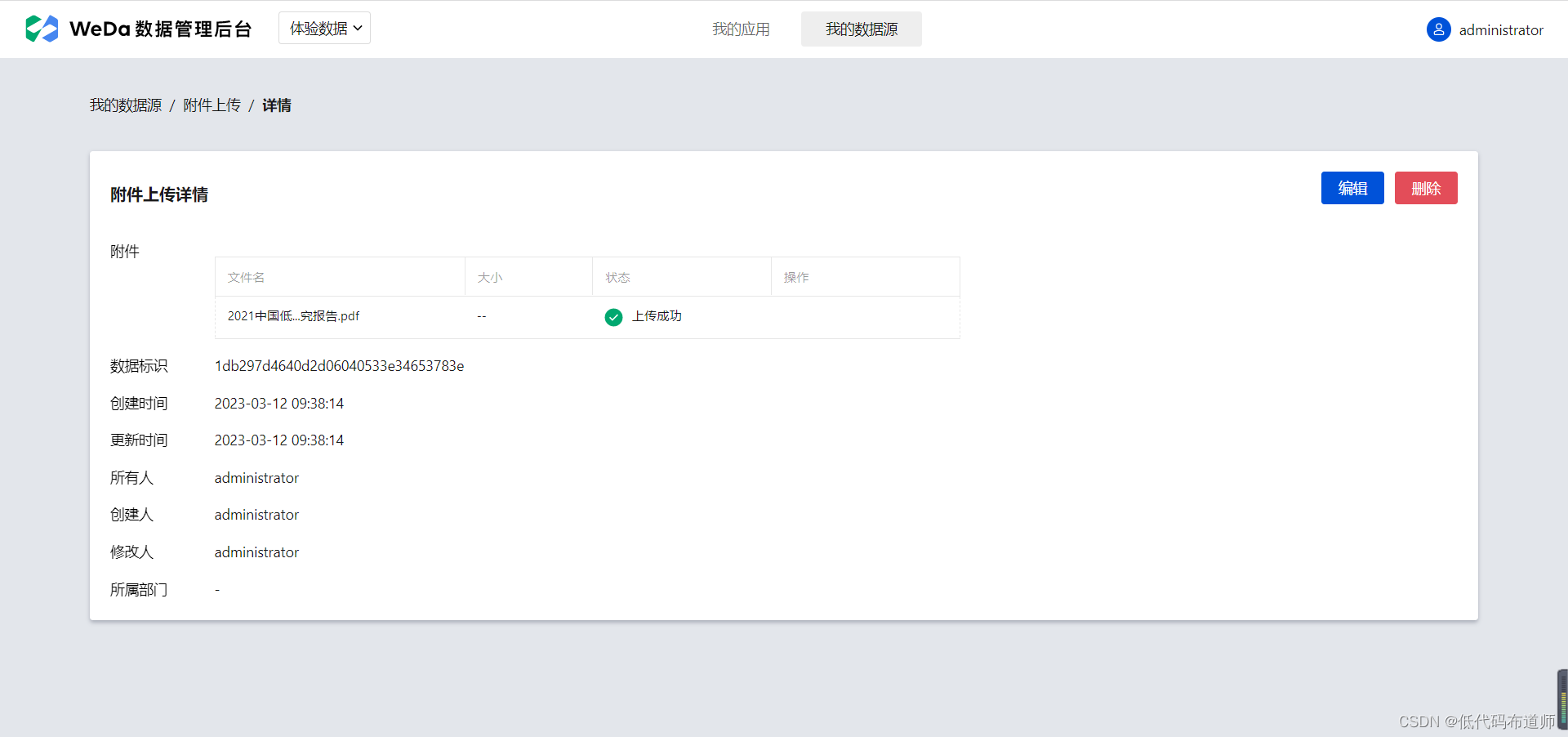
我们其实就需要修改一下查看页面,提供附件的下载功能
为了实现附件的下载功能,我们需要先创建一个自定义应用,应用类型的话选择支持web
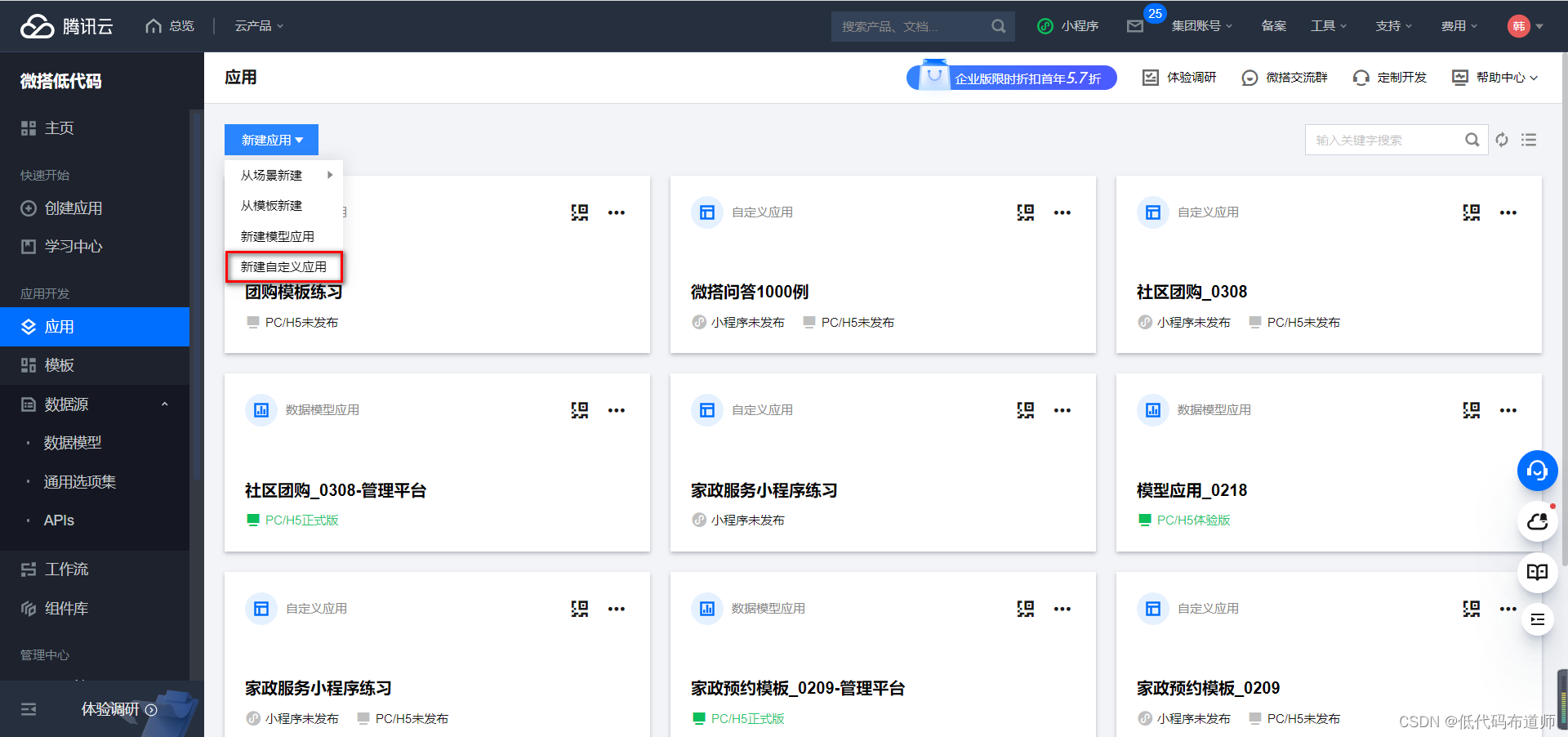
输入应用名称,选择支持的平台类型
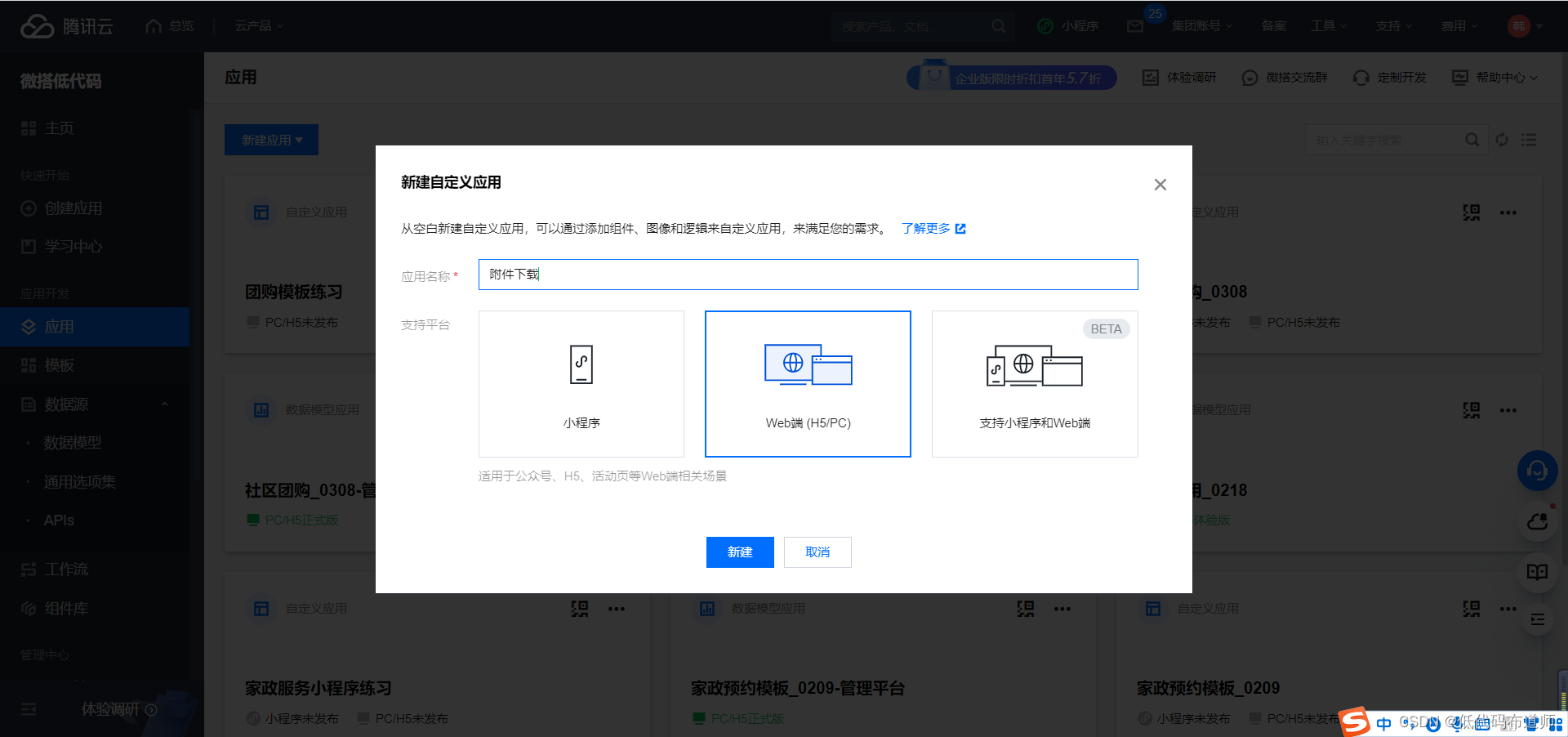
先将应用的模式切换成电脑模式
然后添加数据表格组件
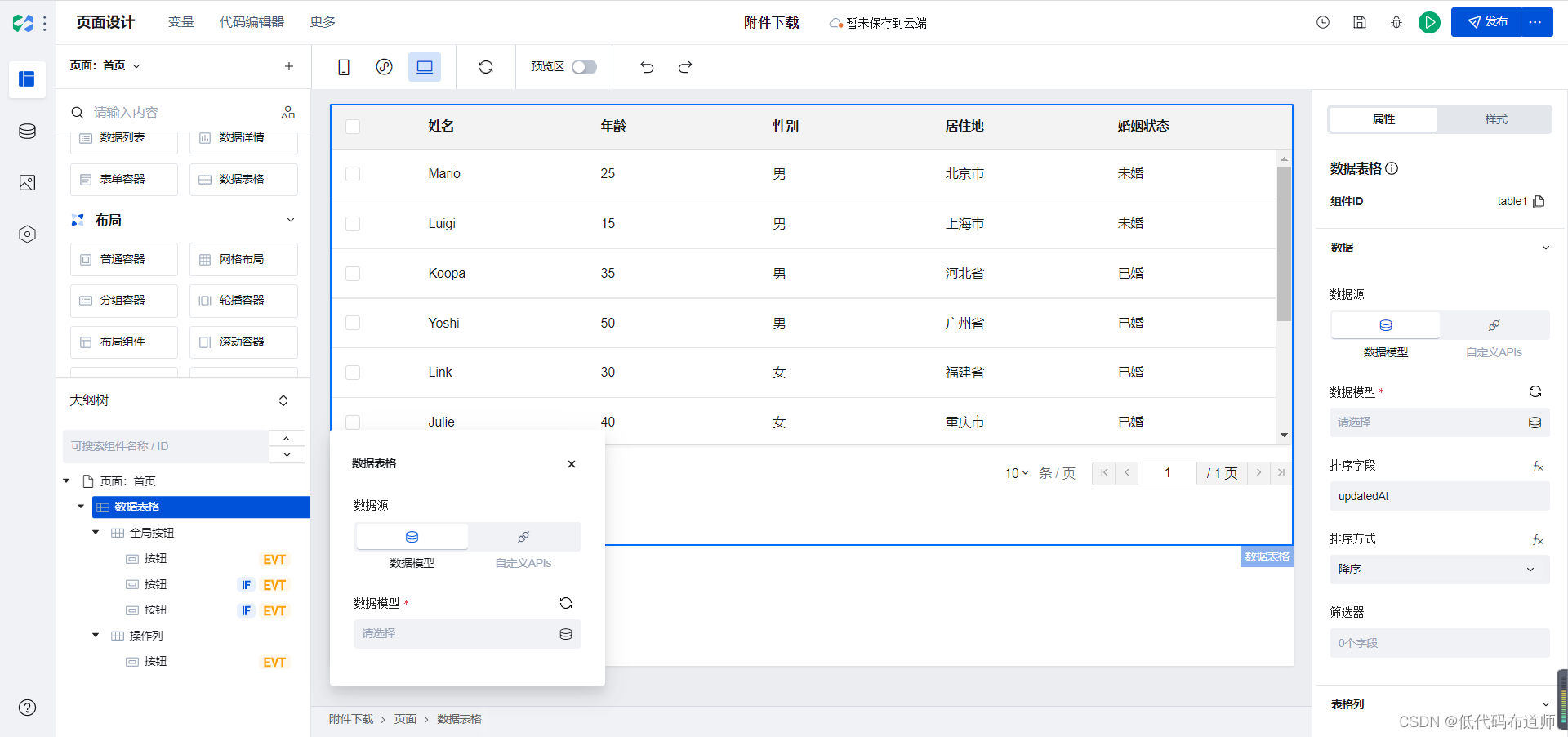
数据模型选择我们创建的数据源
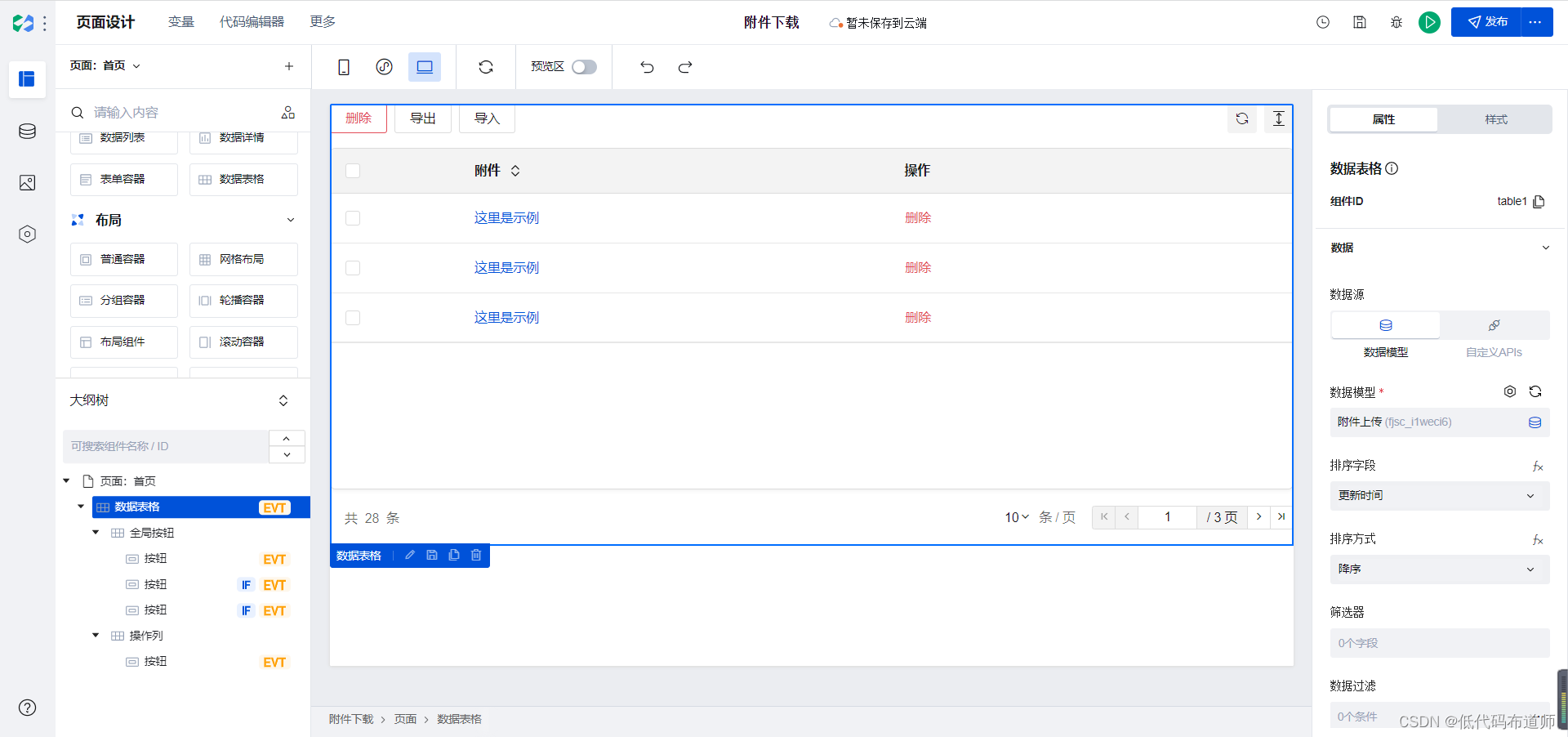
操作列默认只有删除按钮,我们选中操作列,添加一个查看按钮
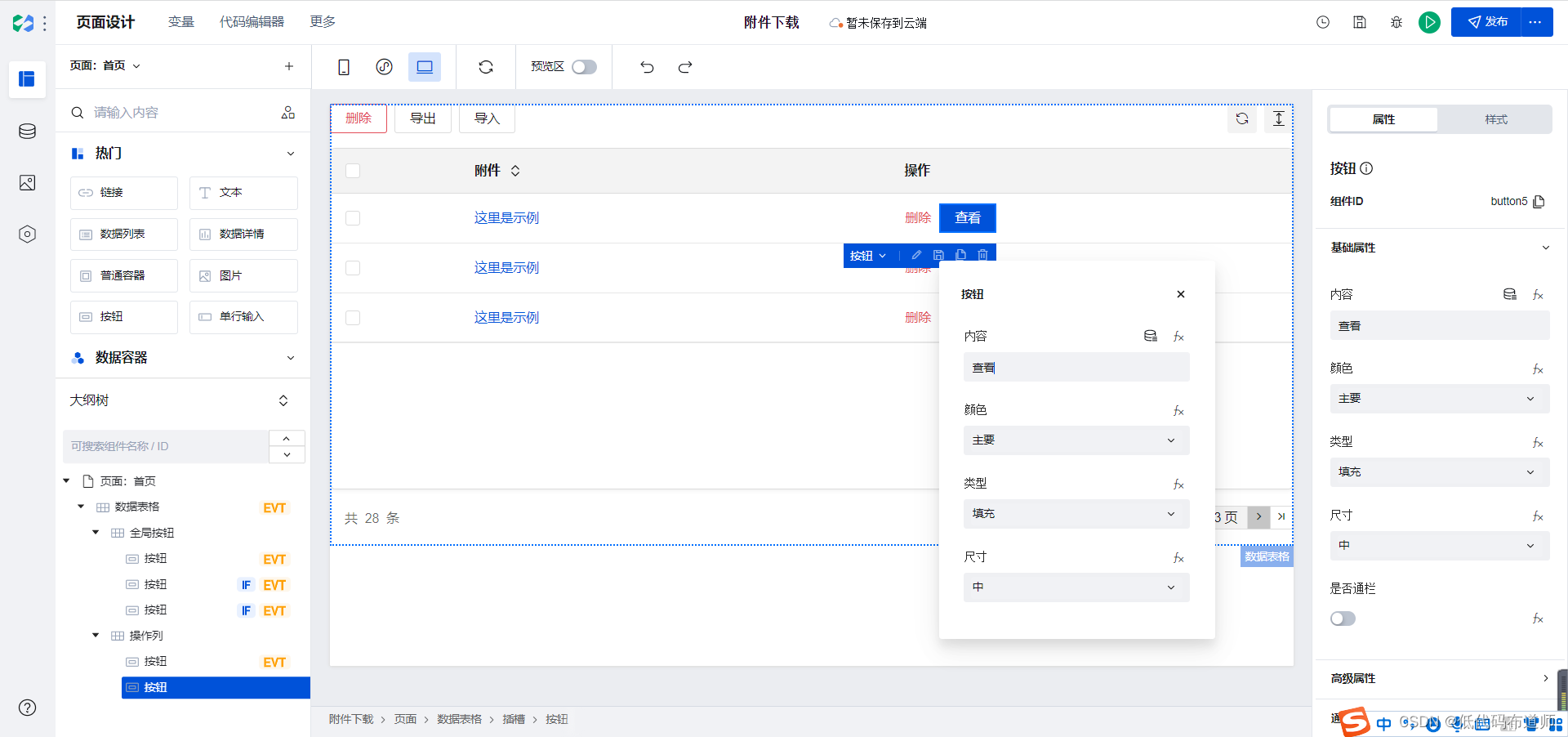
类型选择链接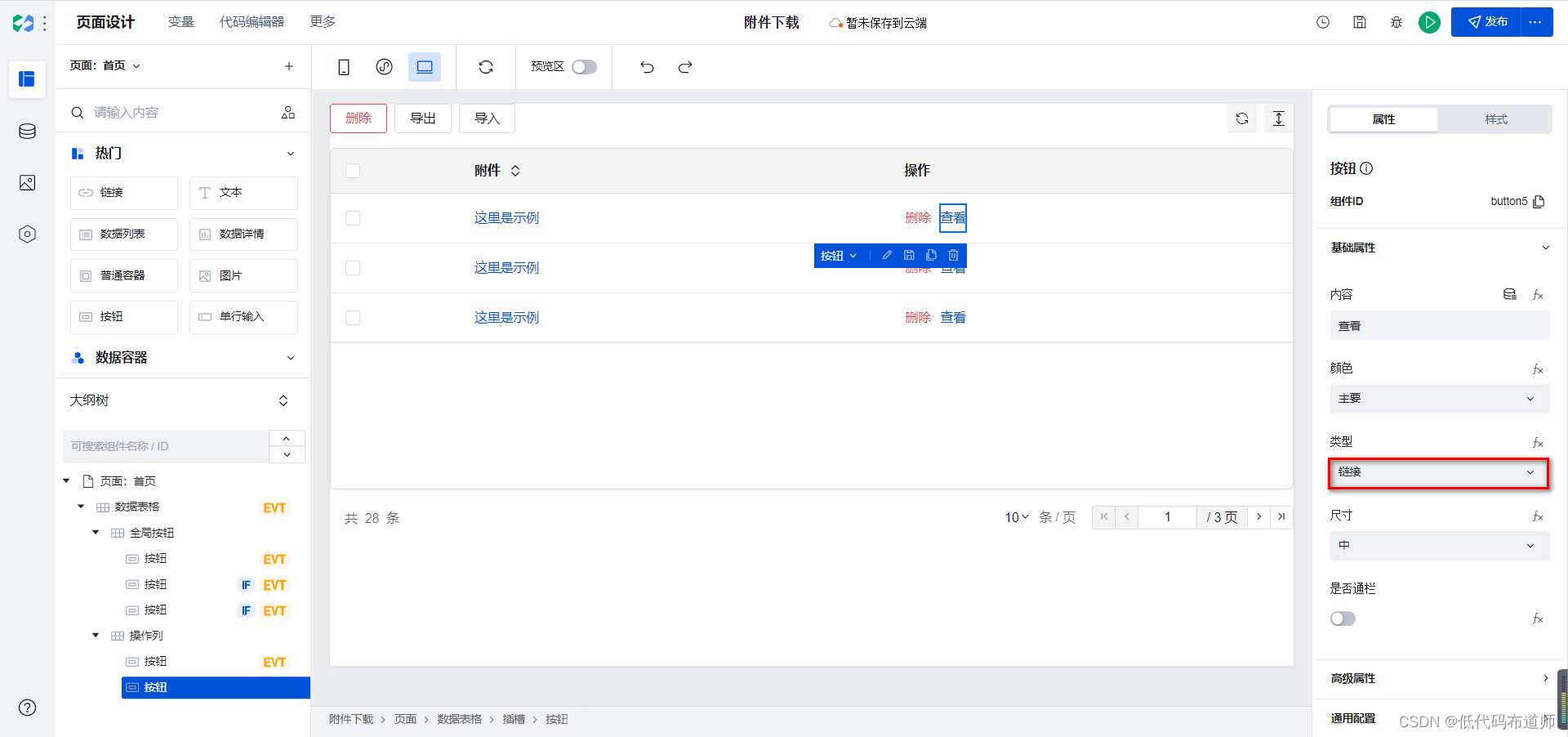
给按钮增加一个点击事件,打开页面,跳转到查看页面。我们需要先新建一个查看页面,点击页面组件区的+号
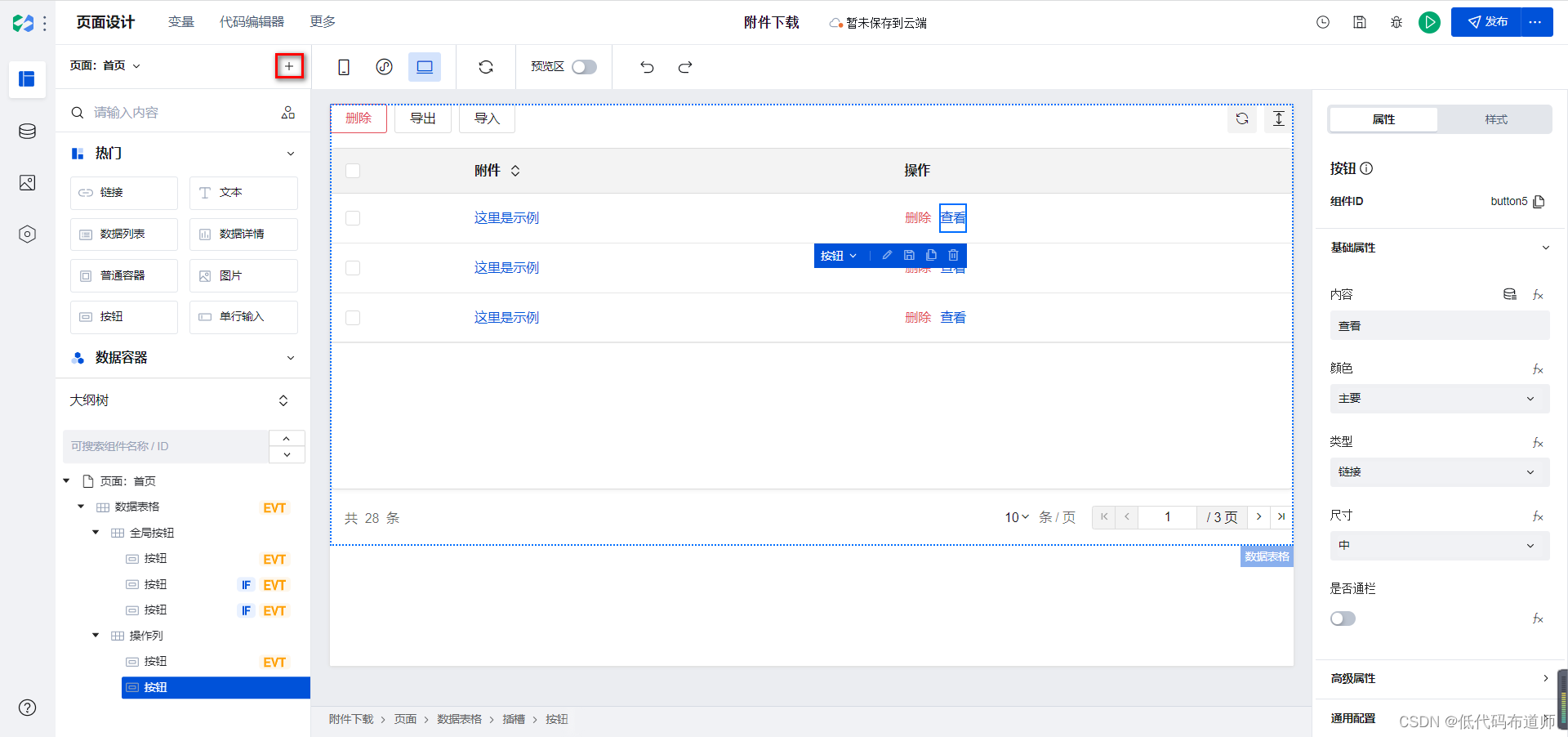
输入页面的名称
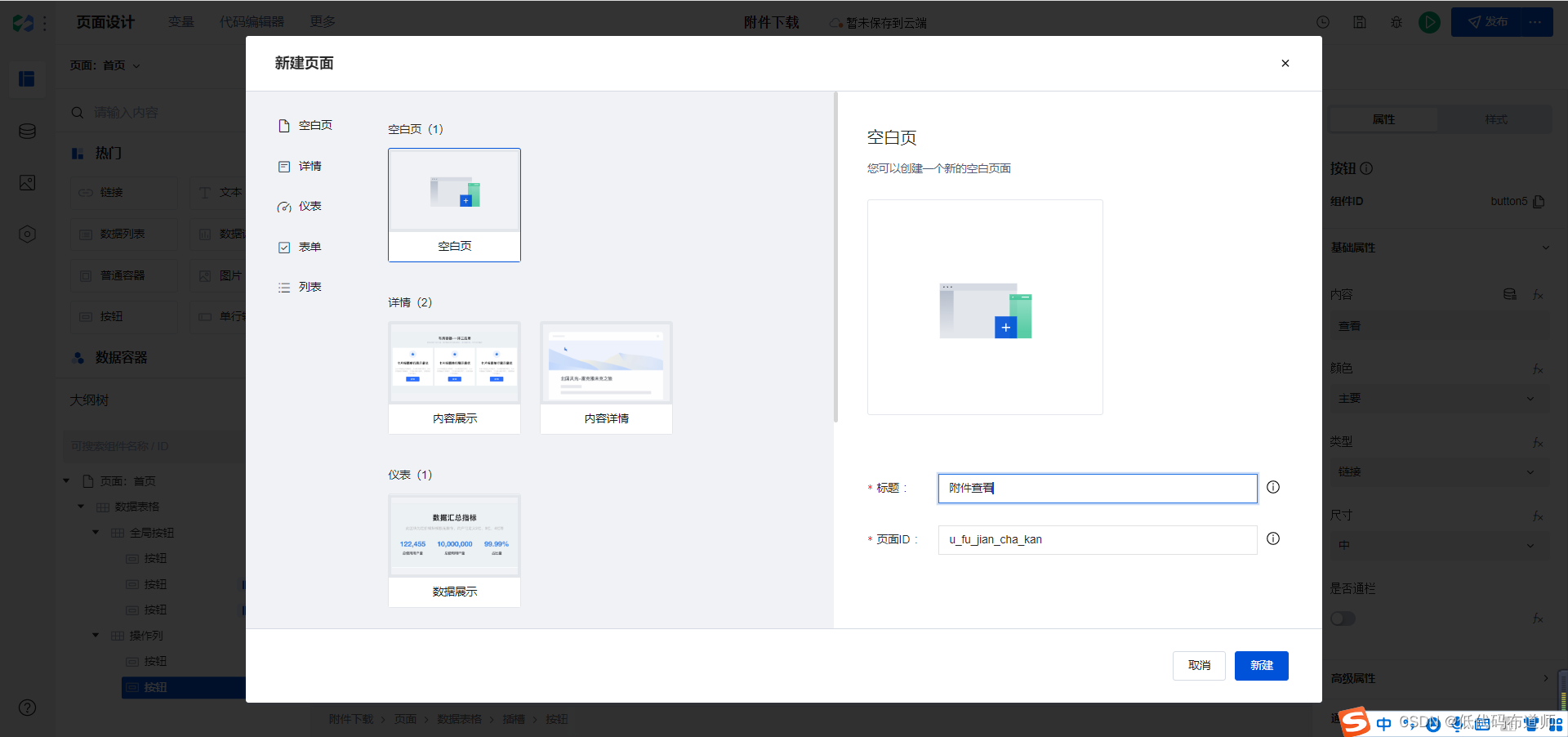
回到首页,选中我们的按钮,增加点击事件

选中打开页面
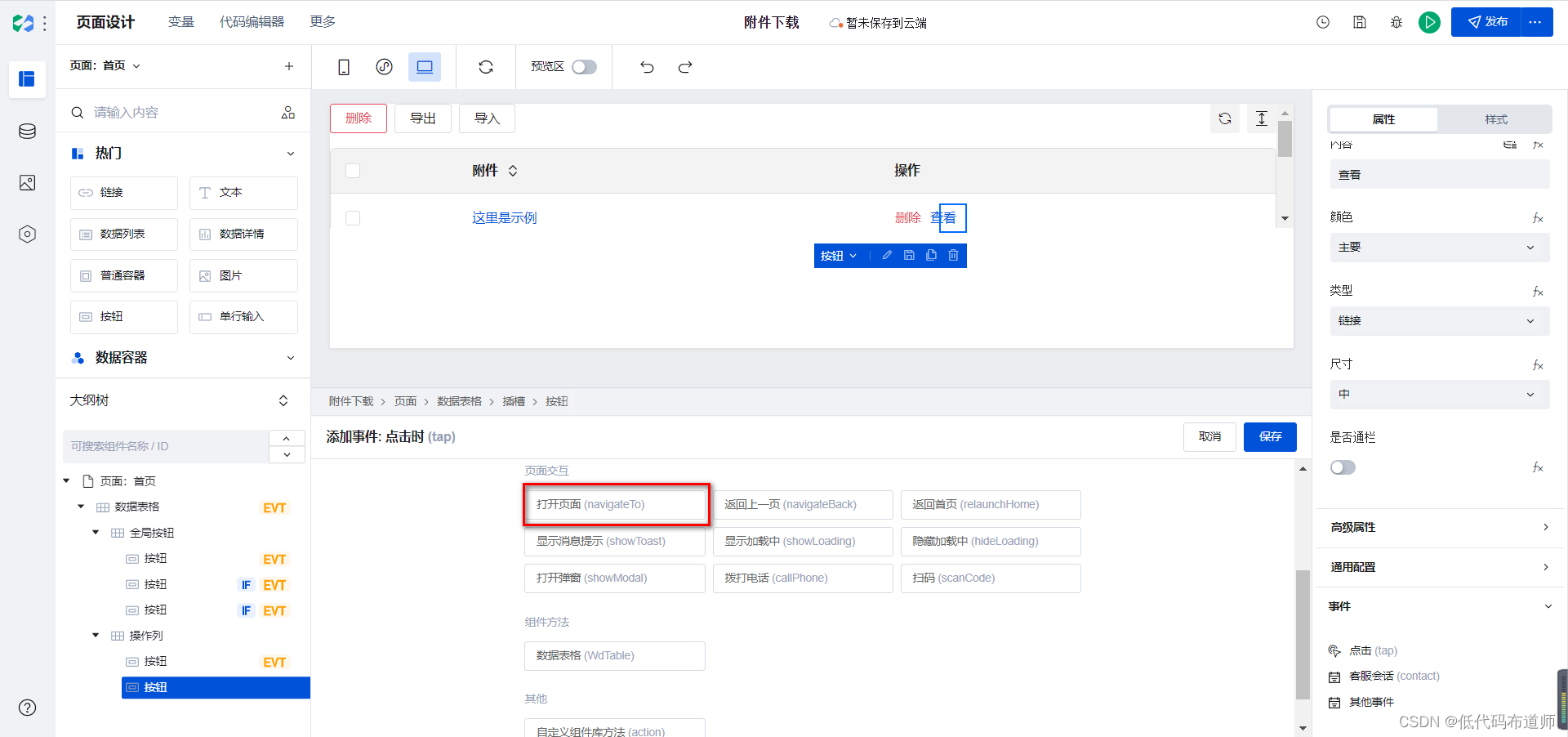
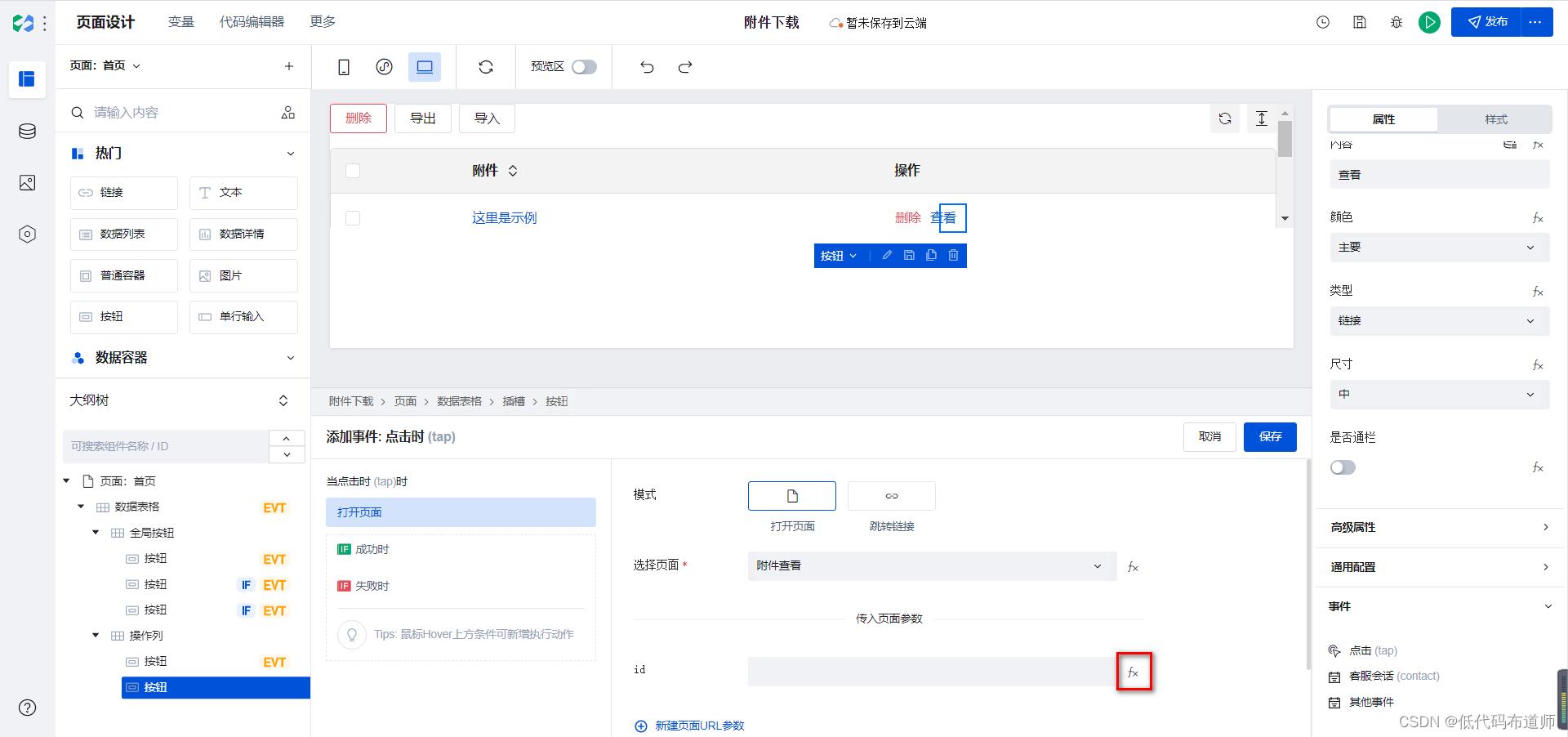
选择我们刚刚创建的附件查看页面,点击新建URL参数
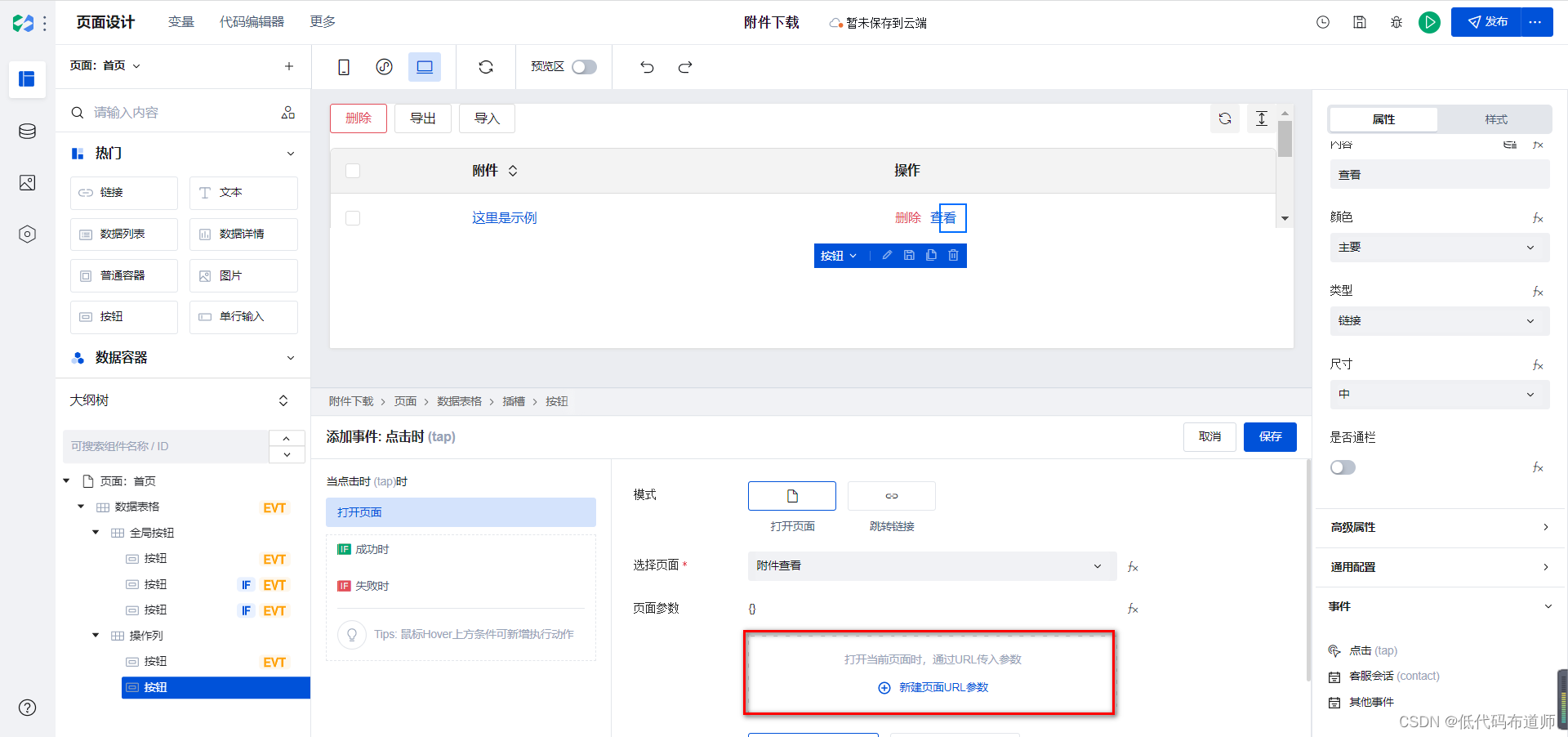
输入变量标识id
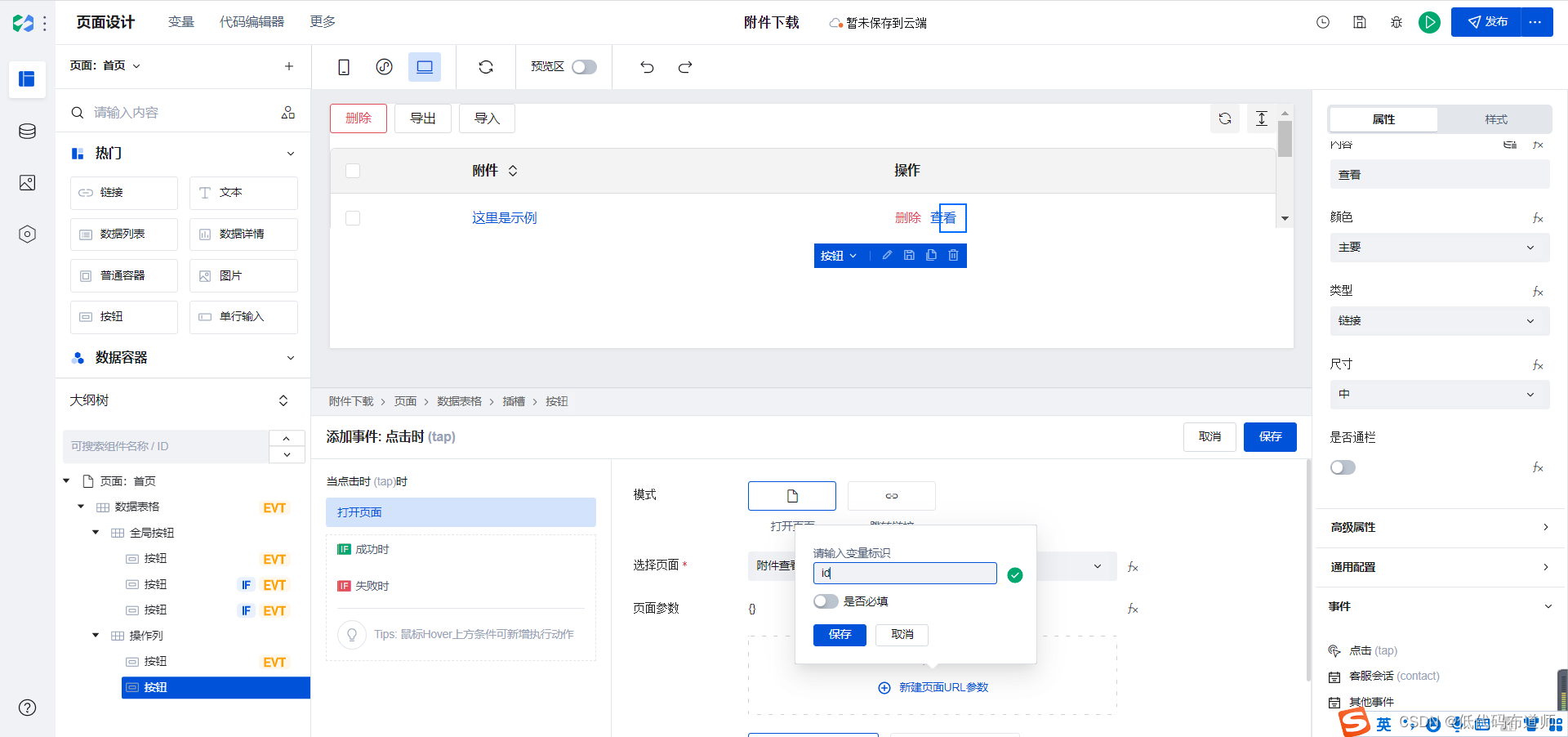
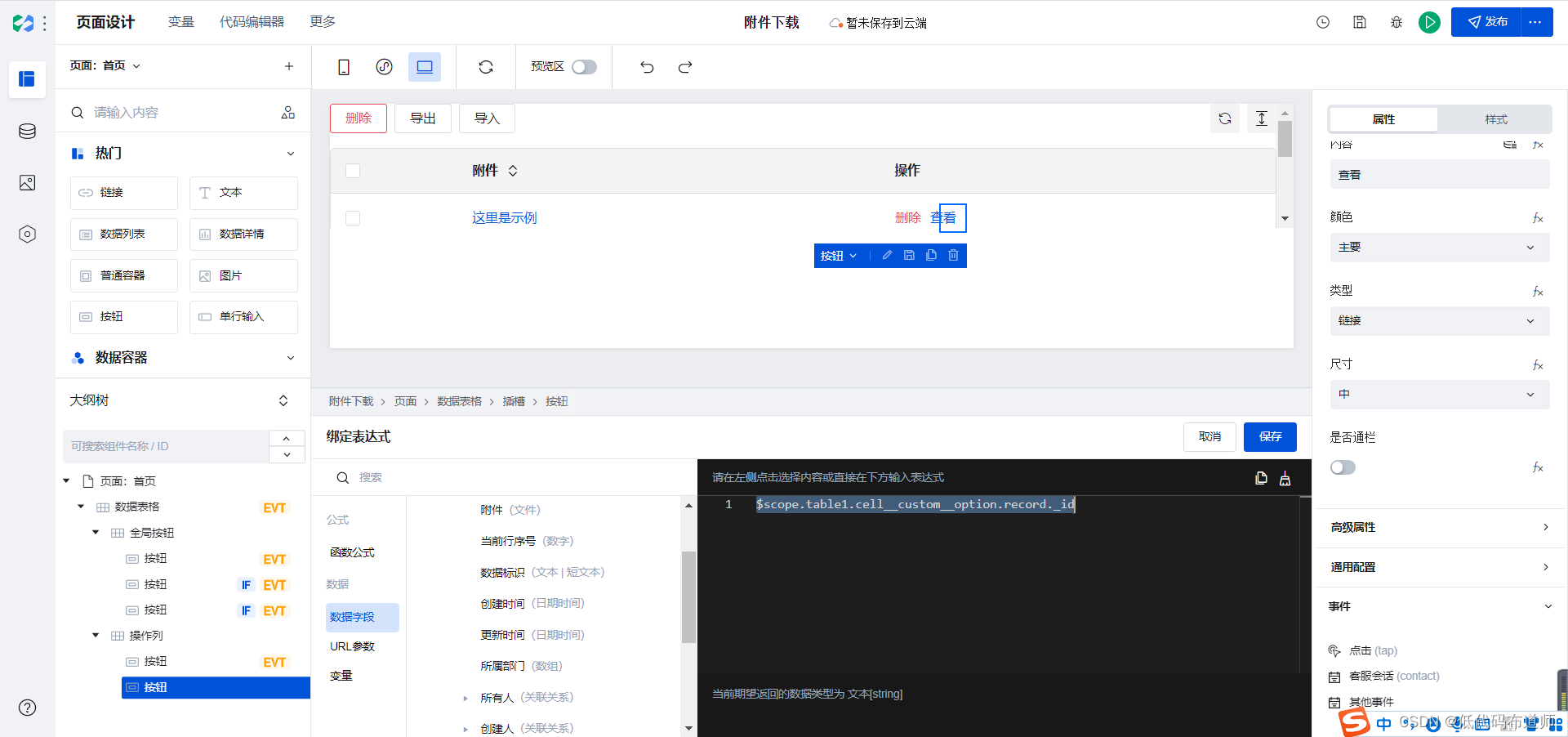
选择id旁边的fx进行数据绑定,从记录列表里选择数据标识
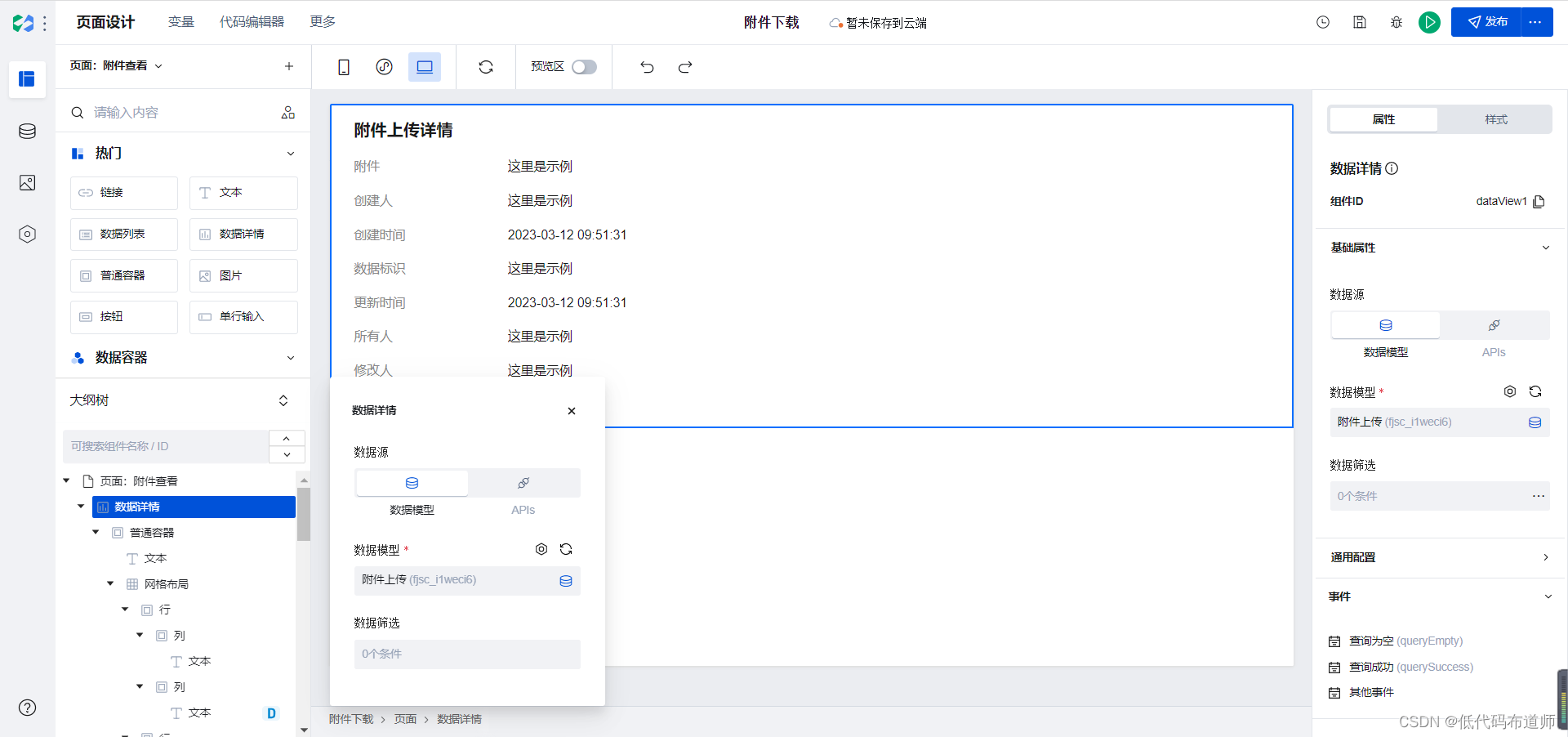
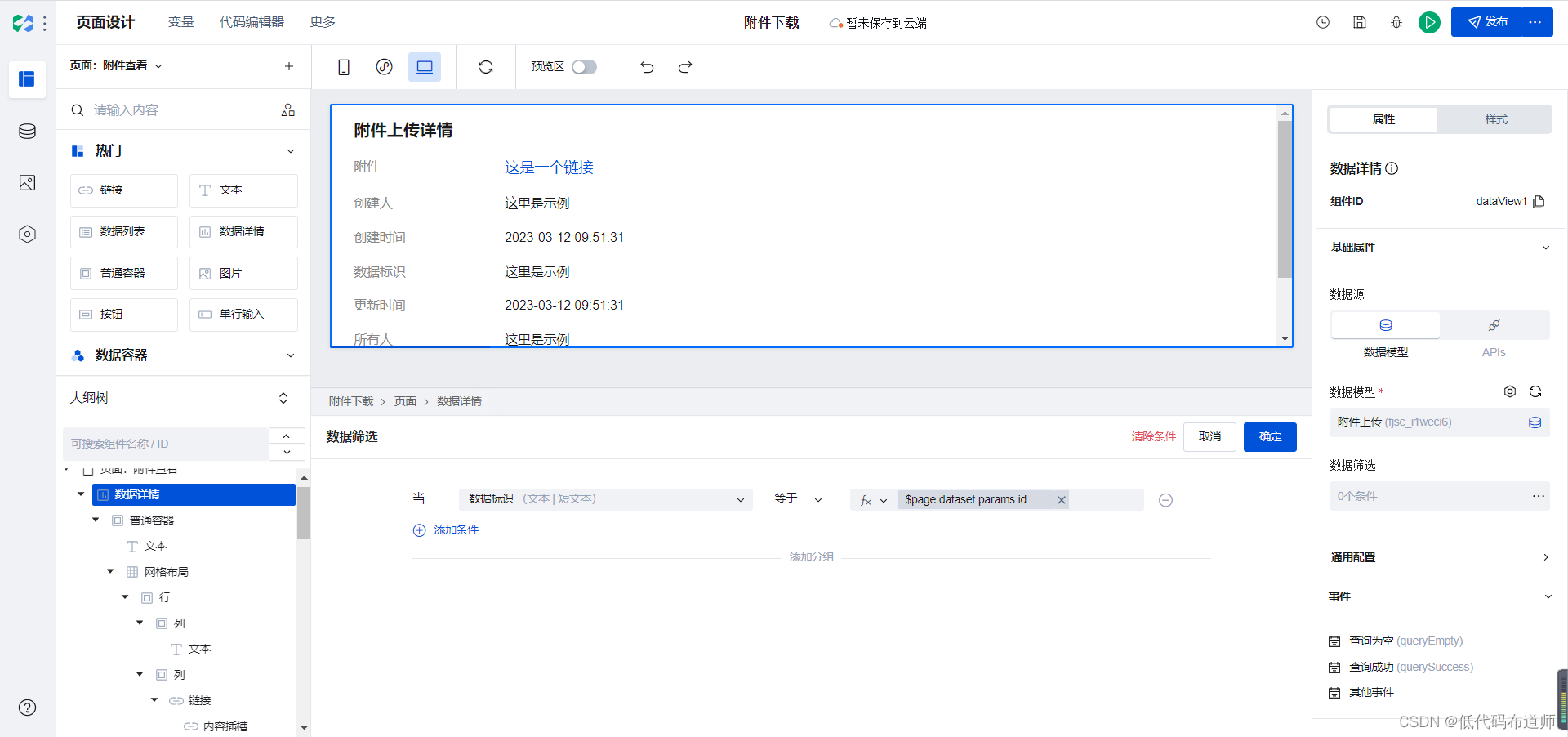
切换到附件查看页面,添加数据详情组件,数据模型选择附件上传
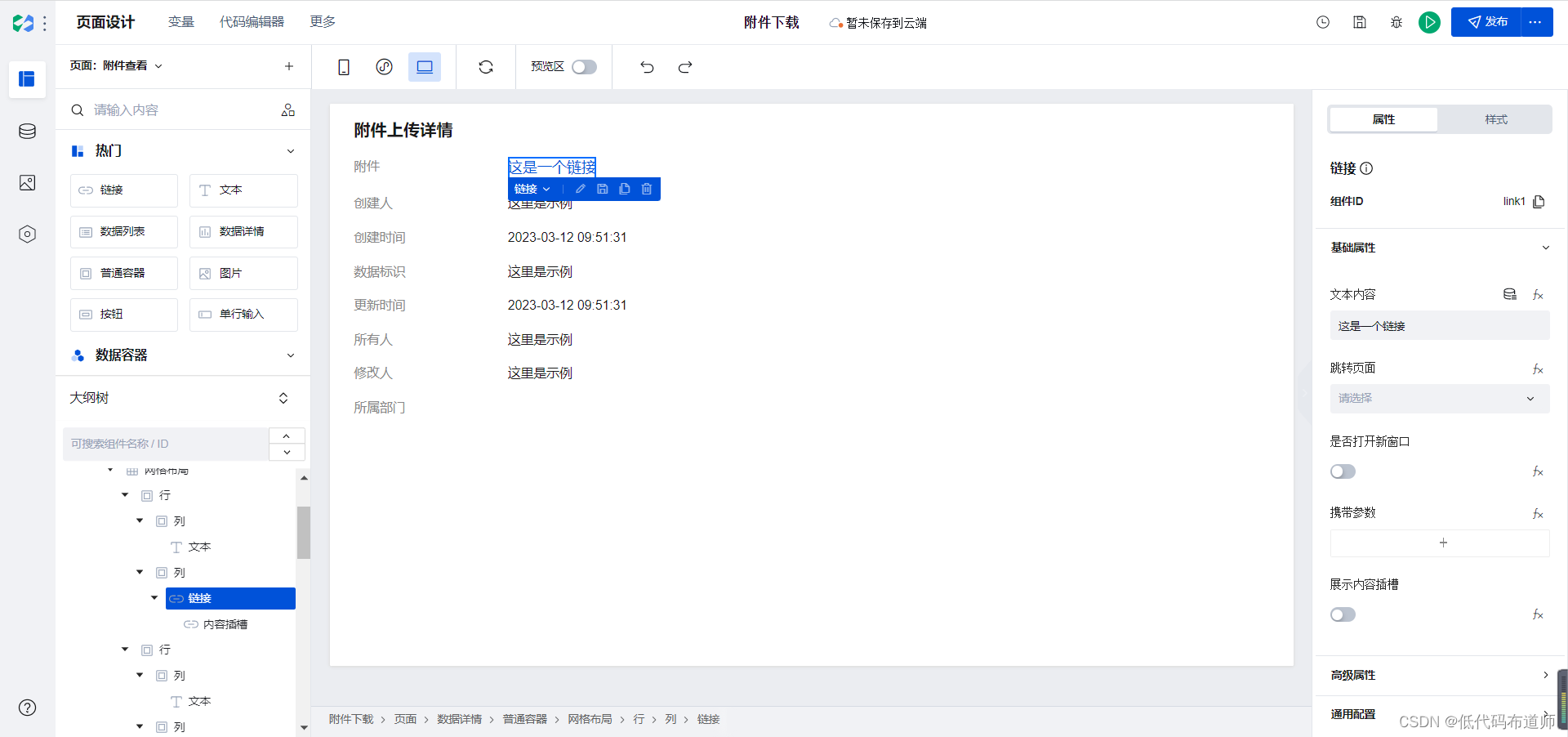
默认的附件字段因为是存储的路径,所以体现的是文本形式,我们要修改一下,将文本组件替换成链接组件
我们的数据详情组件需要设置筛选条件,通过传入的Id来过滤数据
这样页面就搭建好了,现在的问题是如何将附件的路径替换成临时路径的问题,我们可以通过编写API来解决
点击控制台的APIs,点击新建APIs
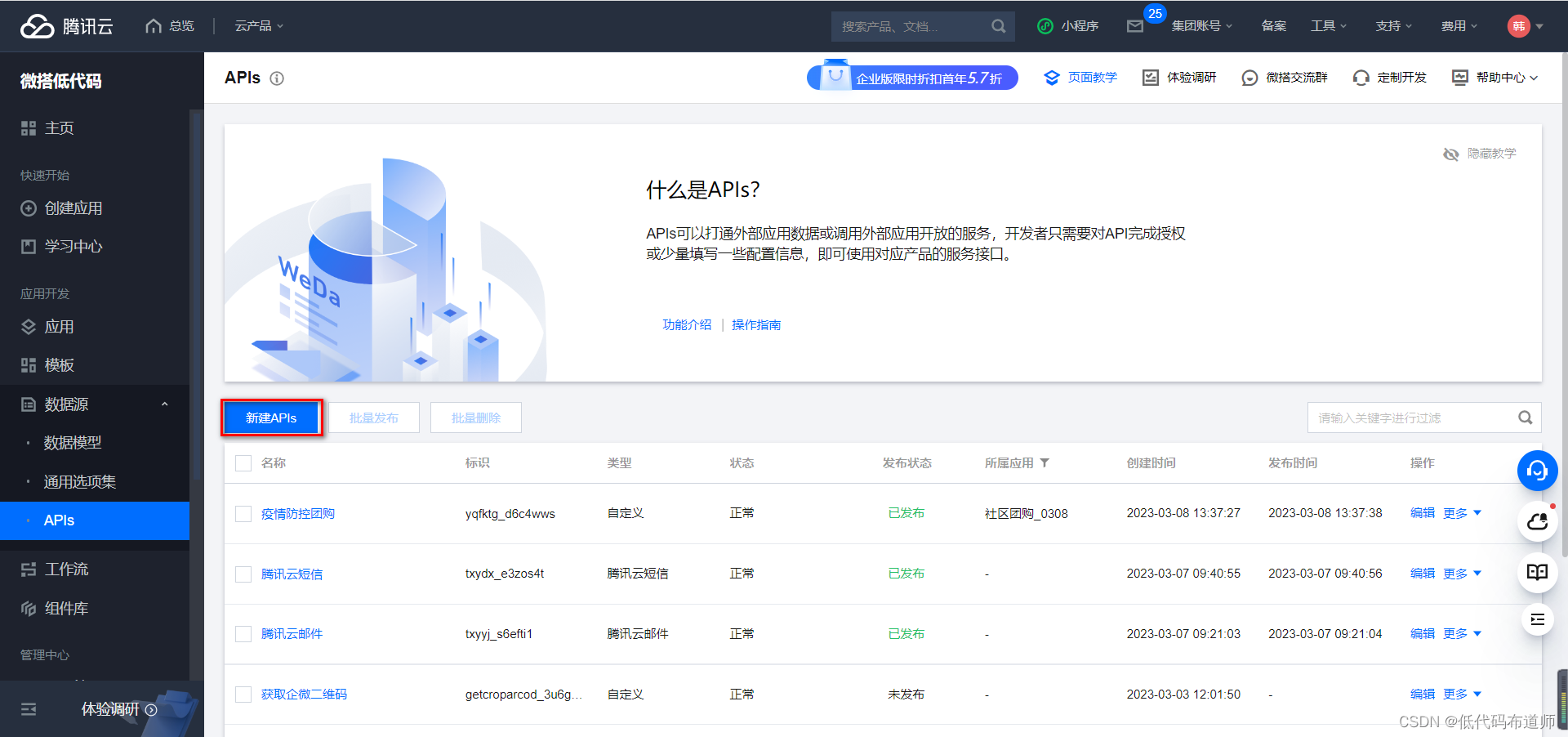
选择自定义代码
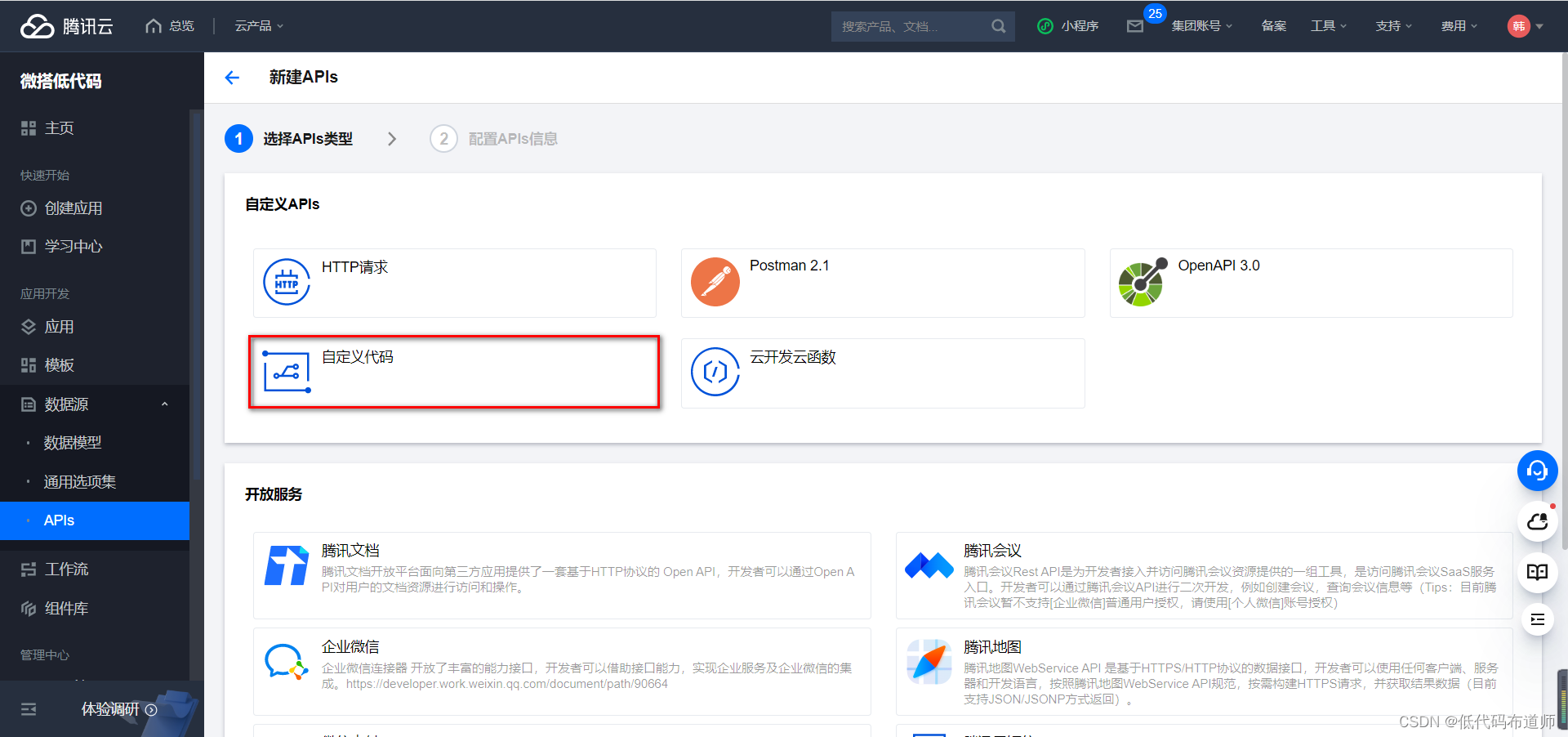
输入名称和标识
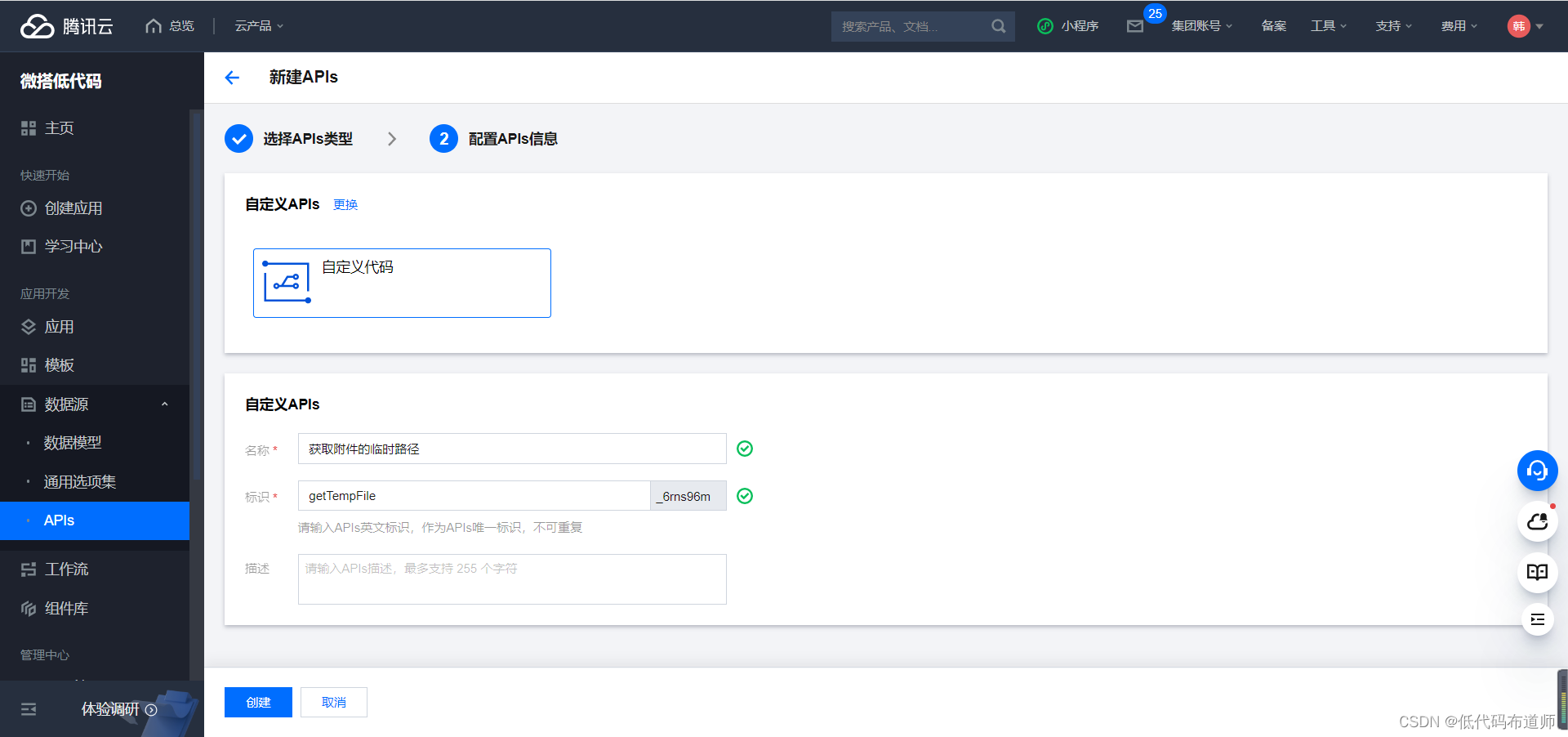
输入方法名称和标识
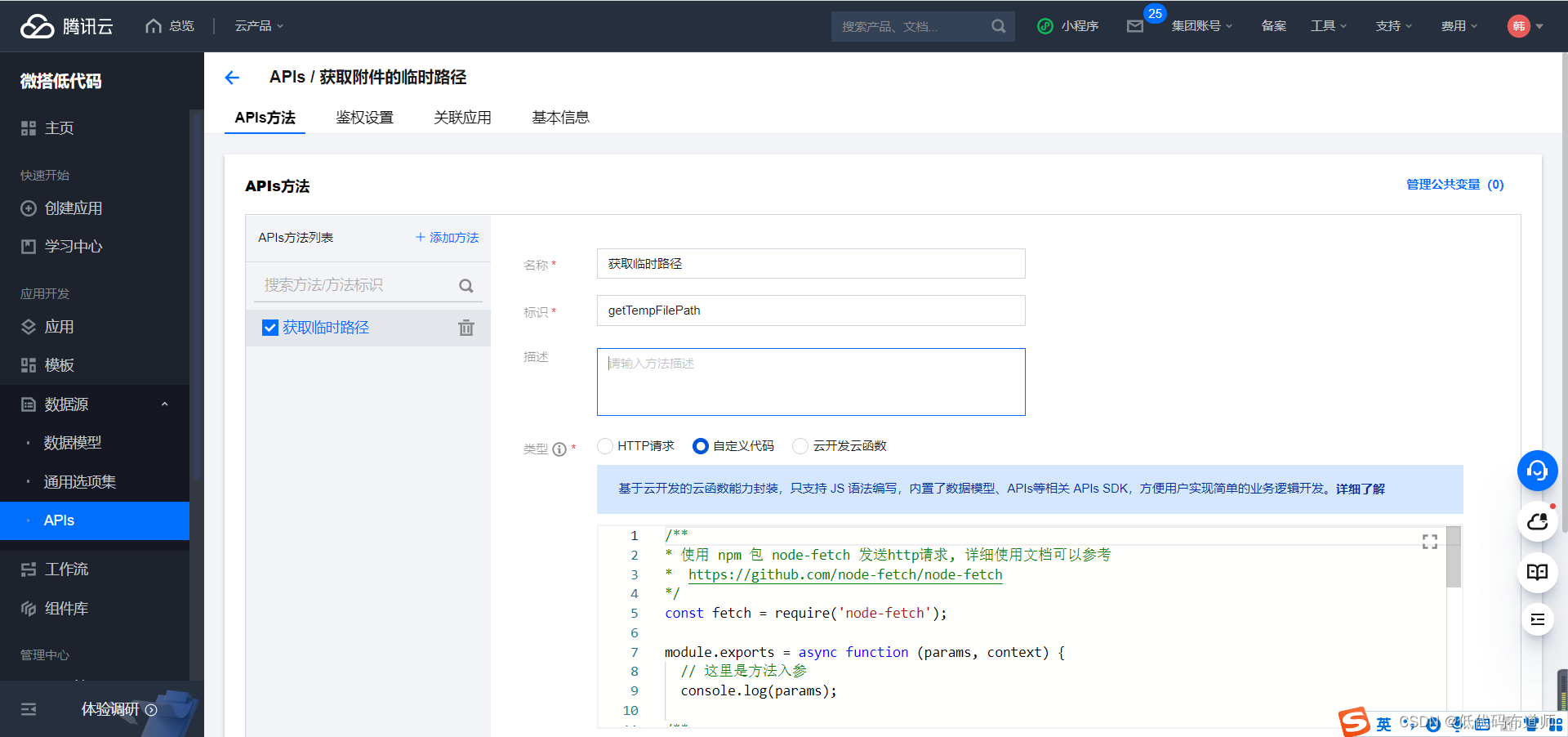
输入如下代码
// 初始化
const tcb = require('@cloudbase/node-sdk')
const app = tcb.init({
env:'***'
})
module.exports = async function (params, context) {
const result = await app.getTempFileURL({
fileList: [params.fileid]
})
// 在这里返回这个方法的结果,需要与出参定义的结构映射
return {
tempfileurl: result.fileList[0].tempFileURL
};
};
这里的env要替换成你自己的,登录控制台,在资源管理可以查看环境Id
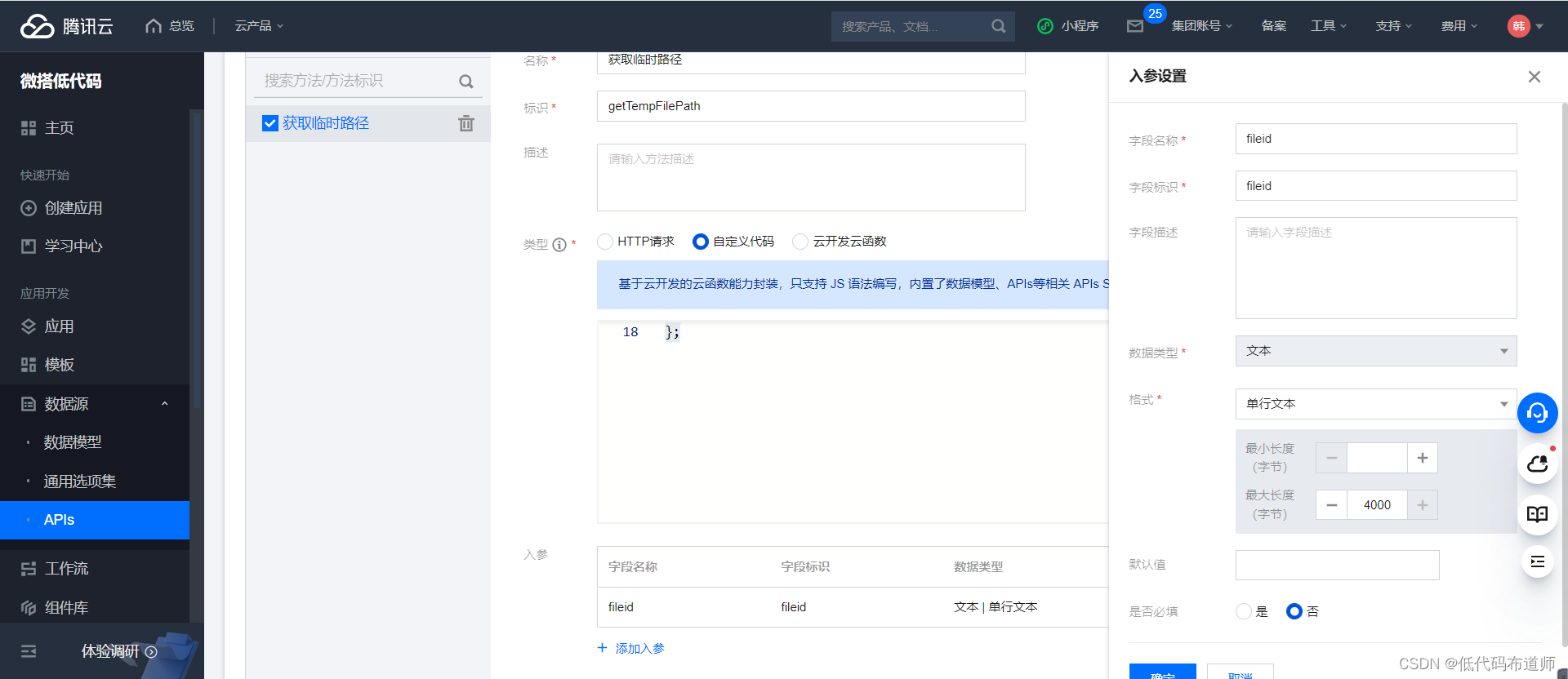
因为我们需要传入fileid,因此需要创建一个入参
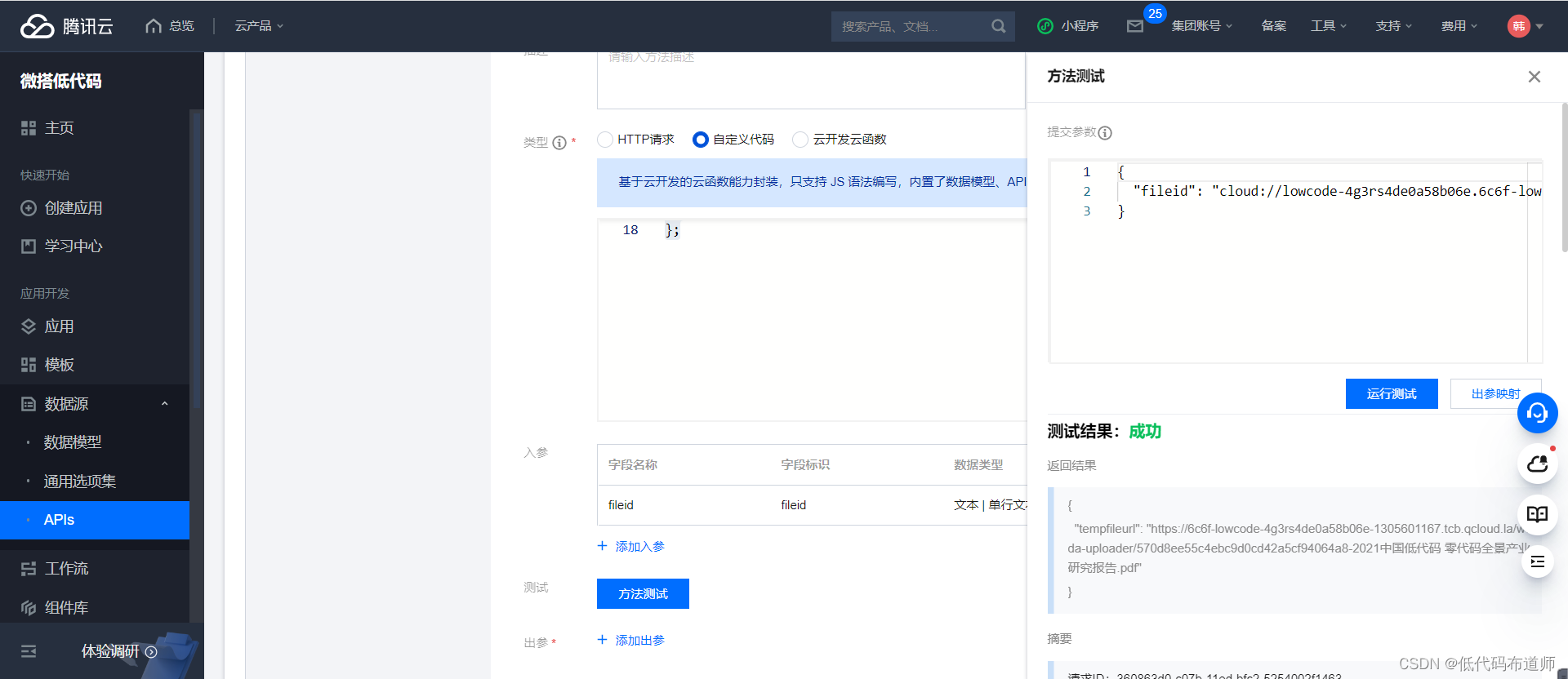
代码搭建好之后,点击方法测试,我们传入fileid可以看到返回的临时路径
测试成功之后点击出参映射
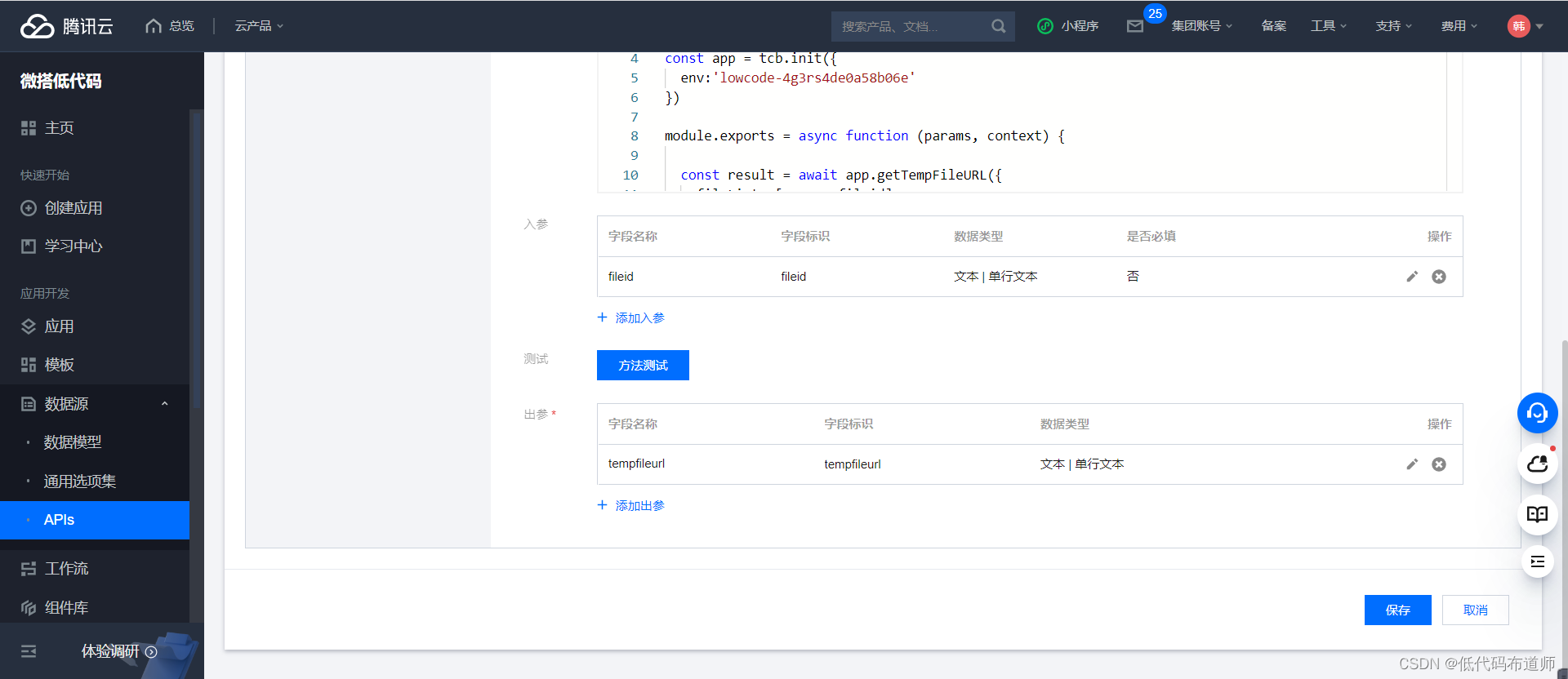
就完成了API的创建
后端方法写好之后,我们需要在前端进行调用。先创建一个变量用来接收结果
在生命周期函数里我们调用后端代码并赋值给变量
export default {
async onPageLoad(query) {
//console.log('---------> LifeCycle onPageLoad', query)
const result = await app.cloud.callConnector({
name:'getTempFile_6rns96m',
methodName:'getTempFilePath',
params:{
fileid:$page.dataset.params.tempfileid
}
})
console.log($page.dataset.params.tempfileid,result)
$page.dataset.state.tempfile = result.tempfileurl
},
onPageShow() {
//console.log('---------> LifeCycle onPageShow')
},
onPageReady() {
//console.log('---------> LifeCycle onPageReady')
},
onPageHide() {
//console.log('---------> LifeCycle onPageHide')
},
onPageUnload() {
//console.log('---------> LifeCycle onPageUnload')
},
}
最后做数据绑定整体的功能就实现了
我们本篇介绍了微搭PC端功能整体搭建的流程,PC端的流程一般会涉及到后端开发,这里就要会使用云开发的后端语法,前后端都熟悉之后你的应用开发就得心应手了。
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我的代码目前看起来像这样numbers=[1,2,3,4,5]defpop_threepop=[]3.times{pop有没有办法在一行中完成pop_three方法中的内容?我基本上想做类似numbers.slice(0,3)的事情,但要删除切片中的数组项。嗯...嗯,我想我刚刚意识到我可以试试slice! 最佳答案 是numbers.pop(3)或者numbers.shift(3)如果你想要另一边。 关于ruby-多次弹出/移动ruby数组,我们在StackOverflow上找到一
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的