上篇文章介绍了编写 Yarn Application 的整体框架流程,本篇文章将详细介绍其中 Client 部分的编写方式。
本篇代码已上传 Github:
Github - MyYarnClient
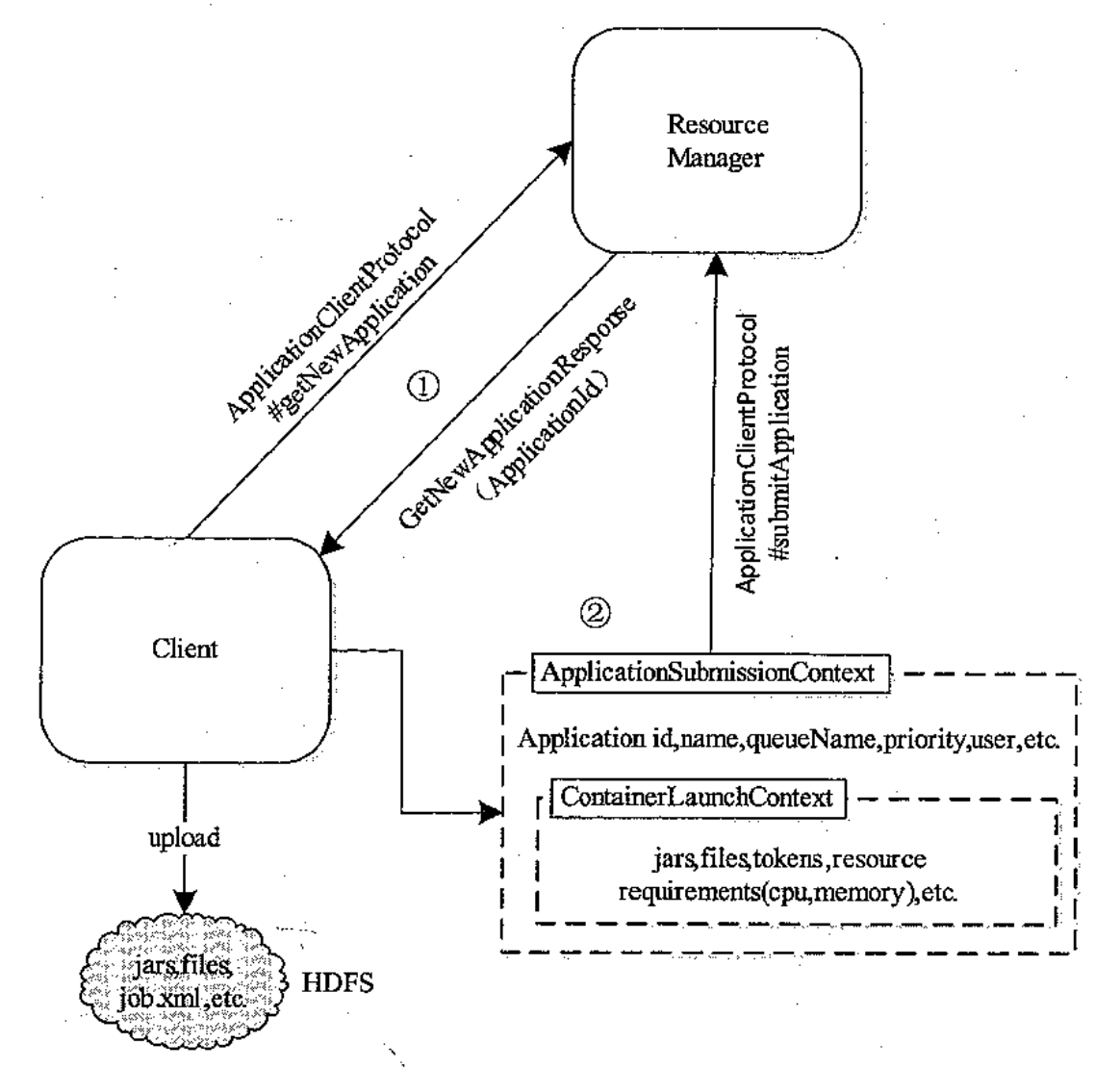
YarnClient 内容通过 ApplicationClientProtocol 与 ResourceManager 通信,向 RM 的ApplicationsManager 申请 Application。
跟踪进去可以在 YarnClientImpl 找到 rpc:
this.rmClient = (ApplicationClientProtocol)ClientRMProxy.createRMProxy(this.getConfig(), ApplicationClientProtocol.class);
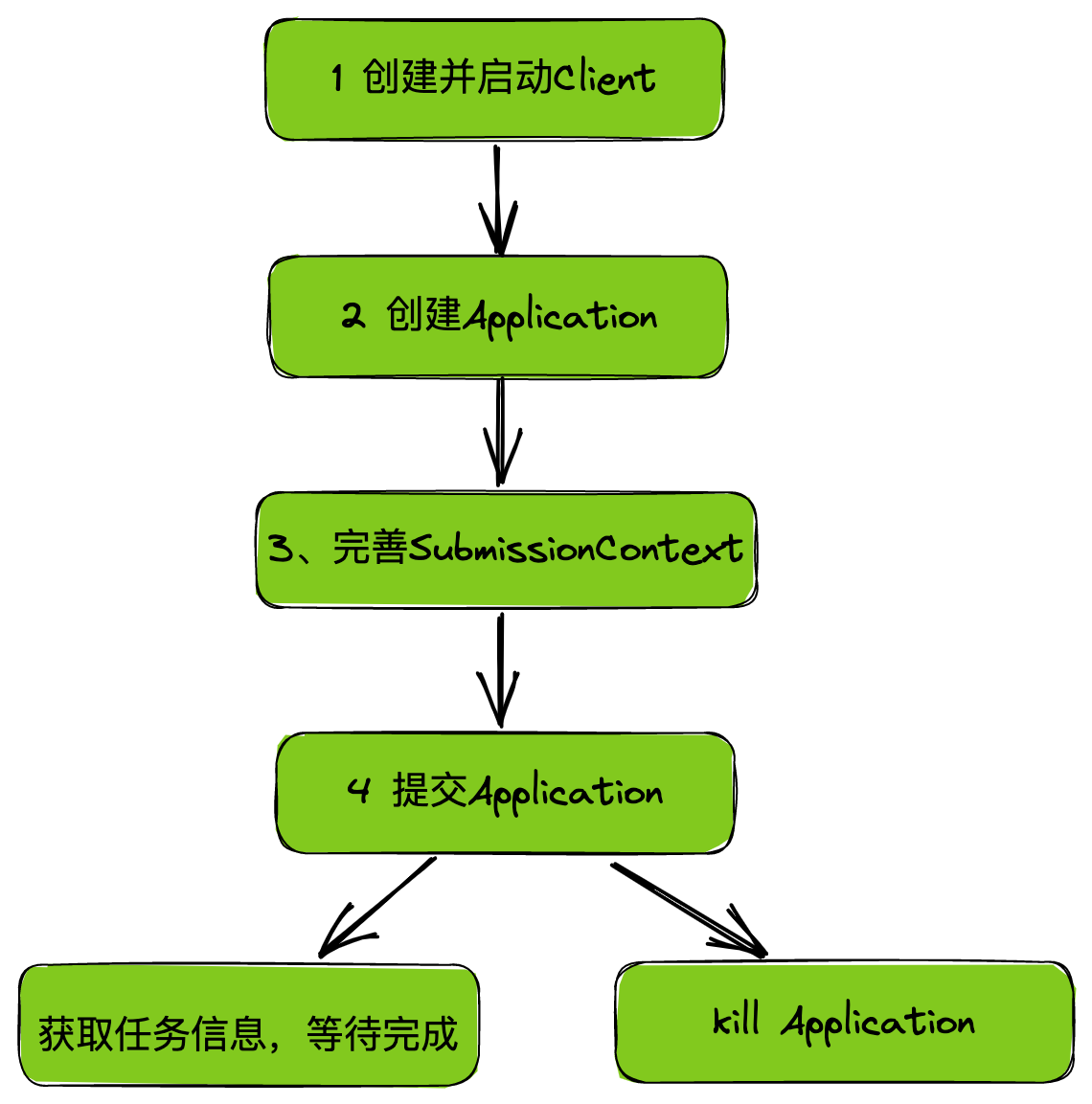
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
GetNewApplicationResponse 中除了包含 ApplicationId,还包括集群最大/最小资源,给任务启动设置的资源作参考。
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
需要在 ApplicationSubmissionContext 中定义 RM 启动 AM 时所需的全部信息,主要包括:
// 3 完善 ApplicationSubmissionContext 所需内容
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId applicationId = appContext.getApplicationId();
// 3.1 设置application name
appContext.setApplicationName("my-test-app");
// 3.2 设置ContainerLaunchContext
// localResources, env, commands 等
// application master 的 jar 放到 localResources 中
// 这部分较长省略,请到代码中查看
ContainerLaunchContext amContainerCtx = createAMContainerLaunchContext(
conf, app.getApplicationSubmissionContext().getApplicationId());
appContext.setAMContainerSpec(amContainerCtx);
// 3.3 设置优先级
Priority pri = Priority.newInstance(0);
appContext.setPriority(pri);
// 3.4 设置队列
appContext.setQueue("default");
// 3.5 设置 am 资源
int amMemory = 2048;
int amVCores = 2;
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
提交后,RM 接收到 Application,根据资源请求分配容器,最终将 AM 启动在容器中。
这里交给 YarnClientImpl 执行 rmClient.submitApplication(request),通过 RPC ApplicationClientProtocol 提交到 RM
ApplicationId appId = yarnClient.submitApplication(appContext);
ApplicationReport report = yarnClient.getApplicationReport(appId);
log.info("Got application report " +
", clientToAMToken=" + report.getClientToAMToken()
+ ", appDiagnostics=" + report.getDiagnostics()
+ ", appMasterHost=" + report.getHost()
+ ", appQueue=" + report.getQueue()
+ ", appMasterRpcPort=" + report.getRpcPort()
+ ", appStartTime=" + report.getStartTime()
+ ", yarnAppState=" + report.getYarnApplicationState().toString()
+ ", distributedFinalState=" + report.getFinalApplicationStatus().toString()
+ ", appTrackingUrl=" + report.getTrackingUrl()
+ ", appUser=" + report.getUser());
当 Application 运行了过长的时间或者其他的原因,client 可以 kill application。
流程是:client 像 RM 发送 kill 信号,再传递给 AM
yarnClient.killApplication(appId);
参考文章:
Hadoop: Writing YARN Applications - Writing a simple Client
《Hadoop 技术内幕 - 深入解析 Yarn 结构设计与实现原理》第四章
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
我使用rails3.1+rspec和factorygirl。我对必填字段(validates_presence_of)的验证工作正常。我如何让测试将该事实用作“成功”而不是“失败”规范是:describe"Addanindustrywithnoname"docontext"Unabletocreatearecordwhenthenameisblank"dosubjectdoind=Factory.create(:industry_name_blank)endit{shouldbe_invalid}endend但是我失败了:Failures:1)Addanindustrywithnona