聚合查询函数是对一组值执行计算,并返回单个值。
Django 使用聚合查询前要先从 django.db.models 引入 Avg、Max、Min、Count、Sum(首字母大写)。
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数
聚合查询返回值的数据类型是字典。
聚合函数 aggregate() 是 QuerySet 的一个终止子句, 生成的一个汇总值,相当于 count()。
使用 aggregate() 后,数据类型就变为字典,不能再使用 QuerySet 数据类型的一些 API 了。
日期数据类型(DateField)可以用 Max 和 Min。
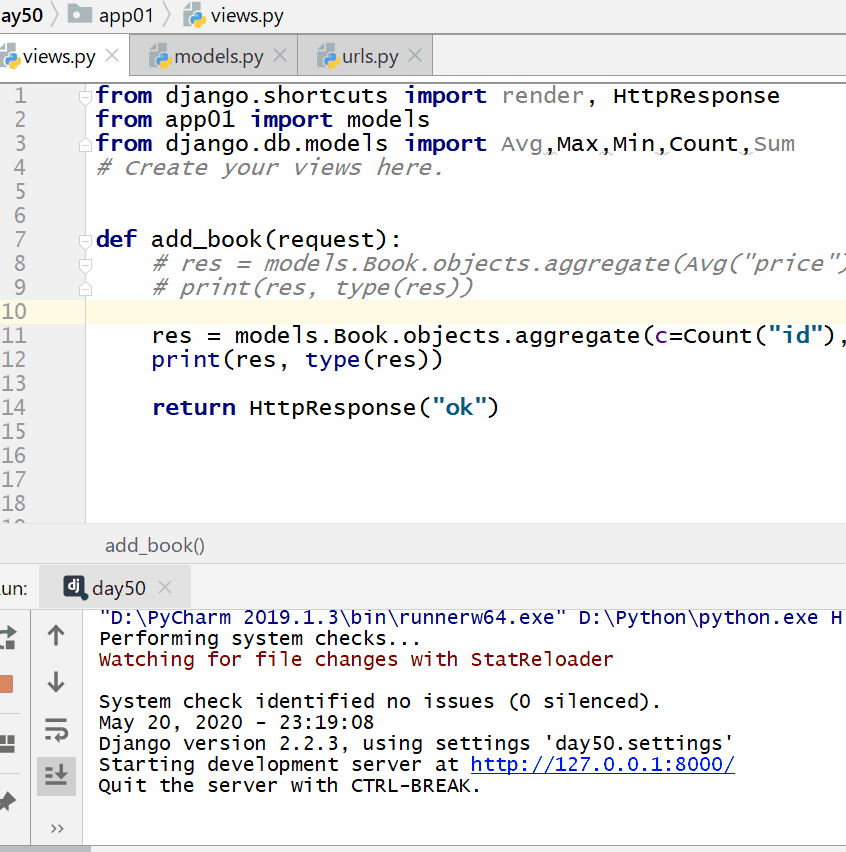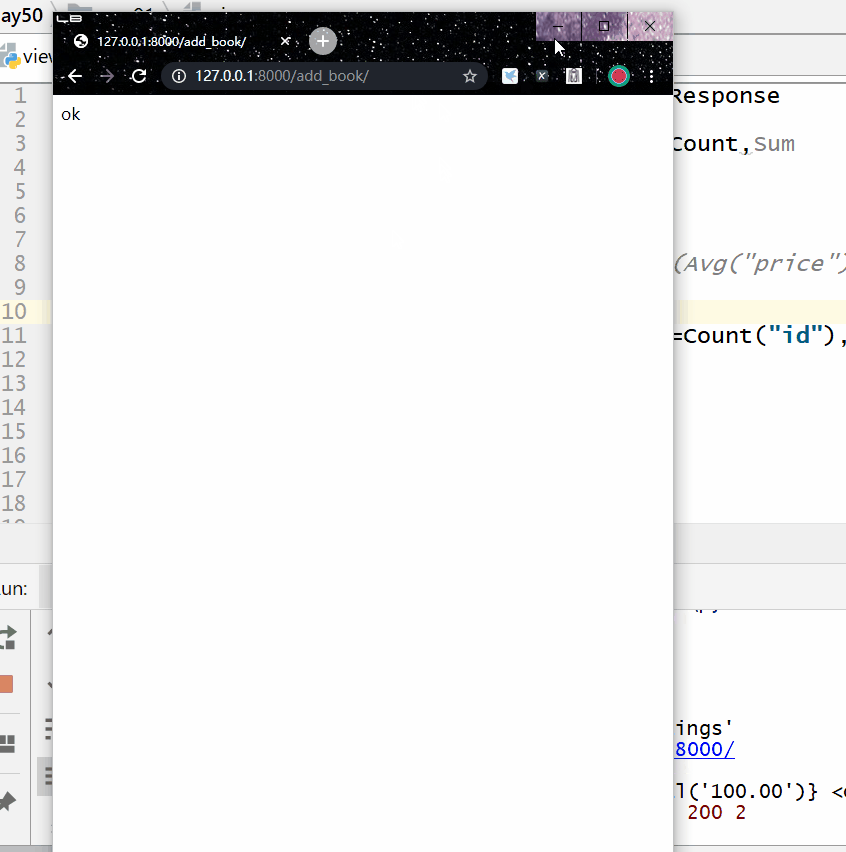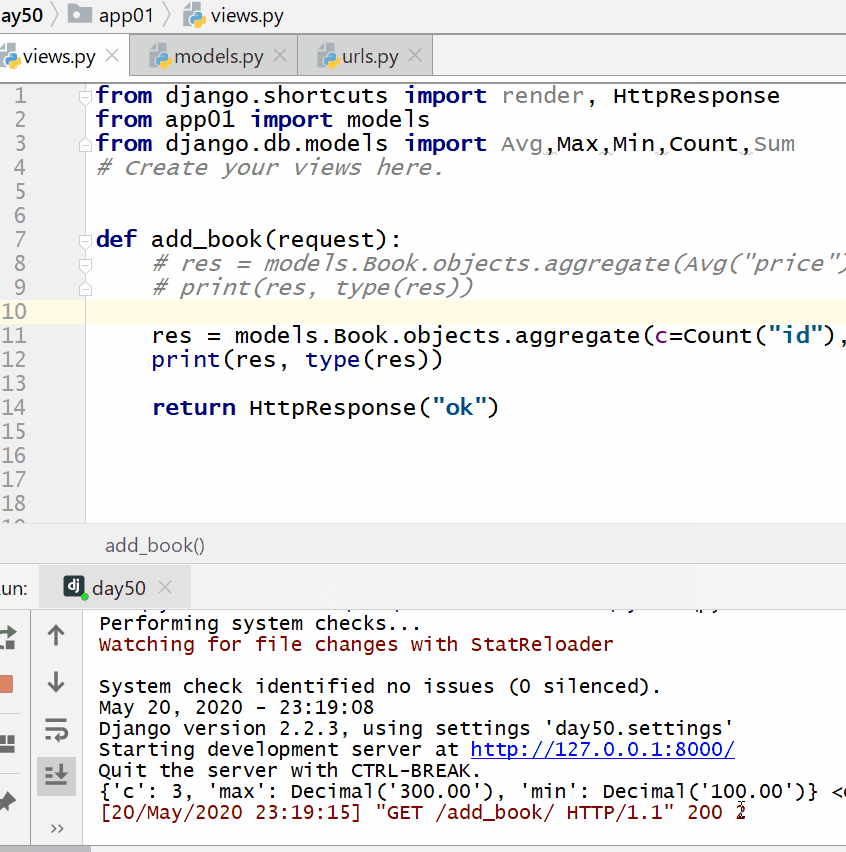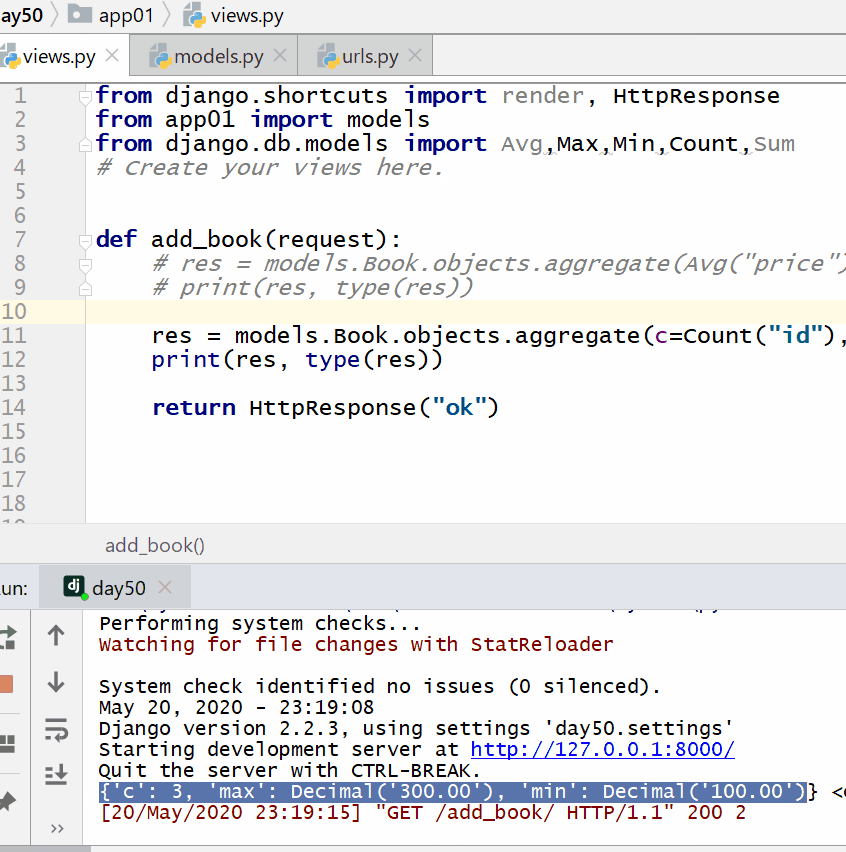
返回的字典中:键的名称默认是(属性名称加上__聚合函数名),值是计算出来的聚合值。
如果要自定义返回字典的键的名称,可以起别名:
aggregate(别名 = 聚合函数名("属性名称"))
计算所有图书的平均价格:
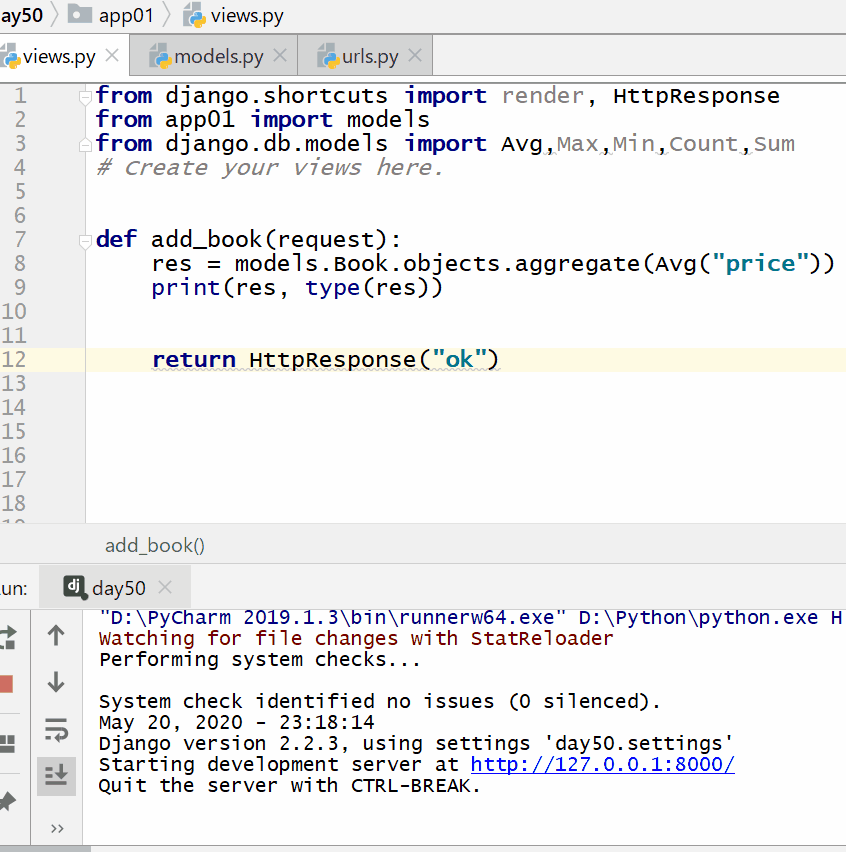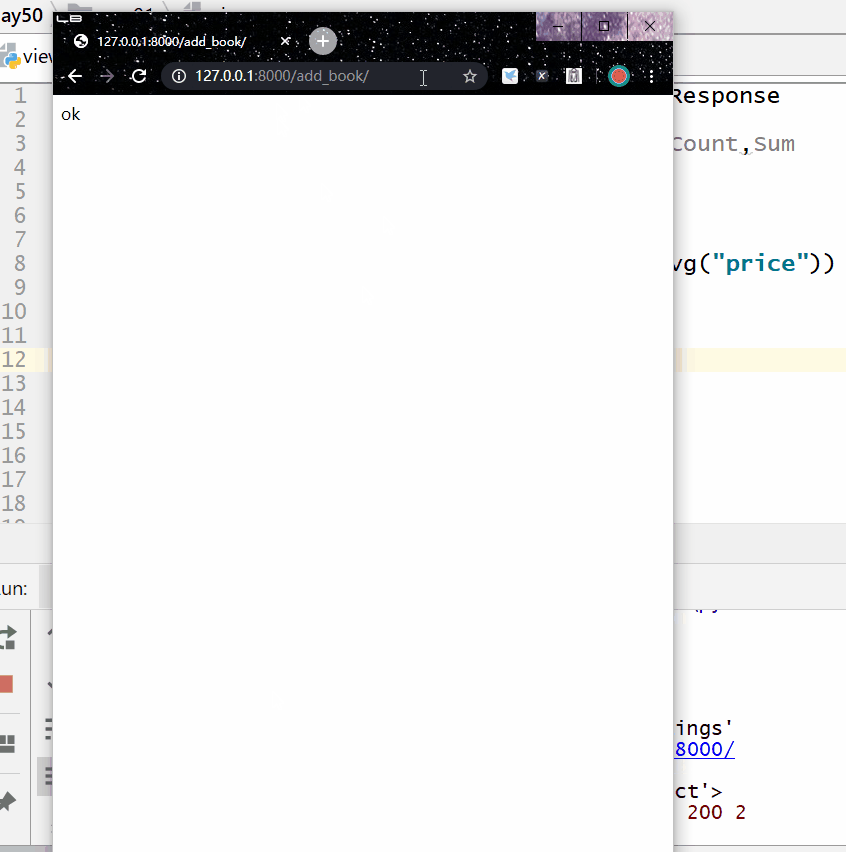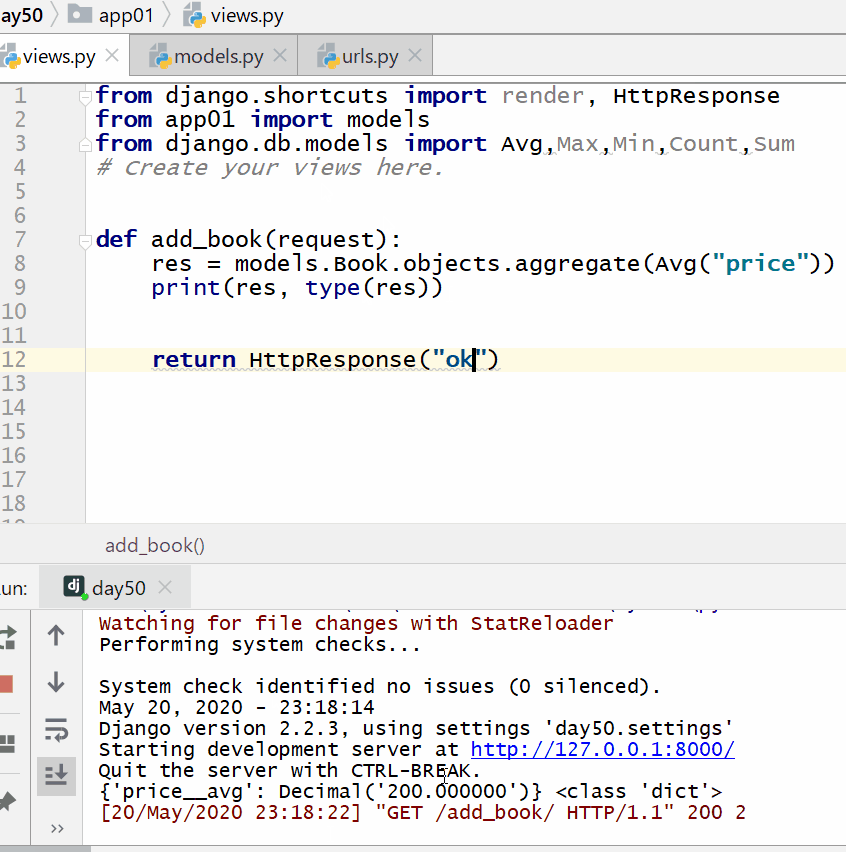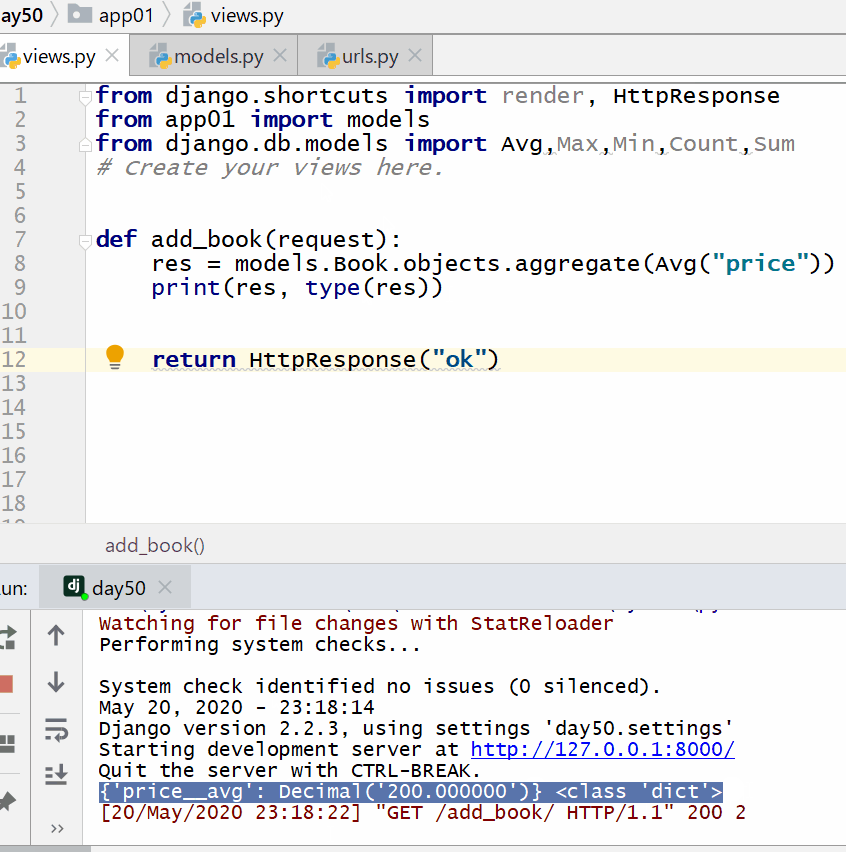
计算所有图书的数量、最贵价格和最便宜价格:
分组查询一般会用到聚合函数,所以使用前要先从 django.db.models 引入 Avg,Max,Min,Count,Sum(首字母大写)。
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数
返回值:
MySQL 中的 limit 相当于 ORM 中的 QuerySet 数据类型的切片。
注意:
annotate 里面放聚合函数。
values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
数据:
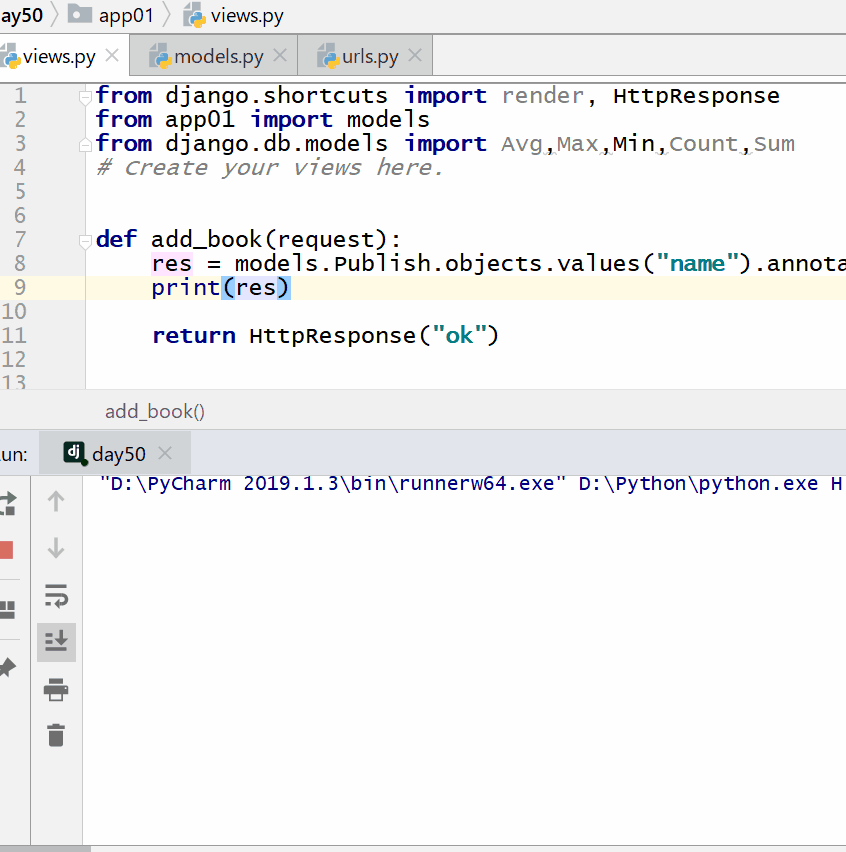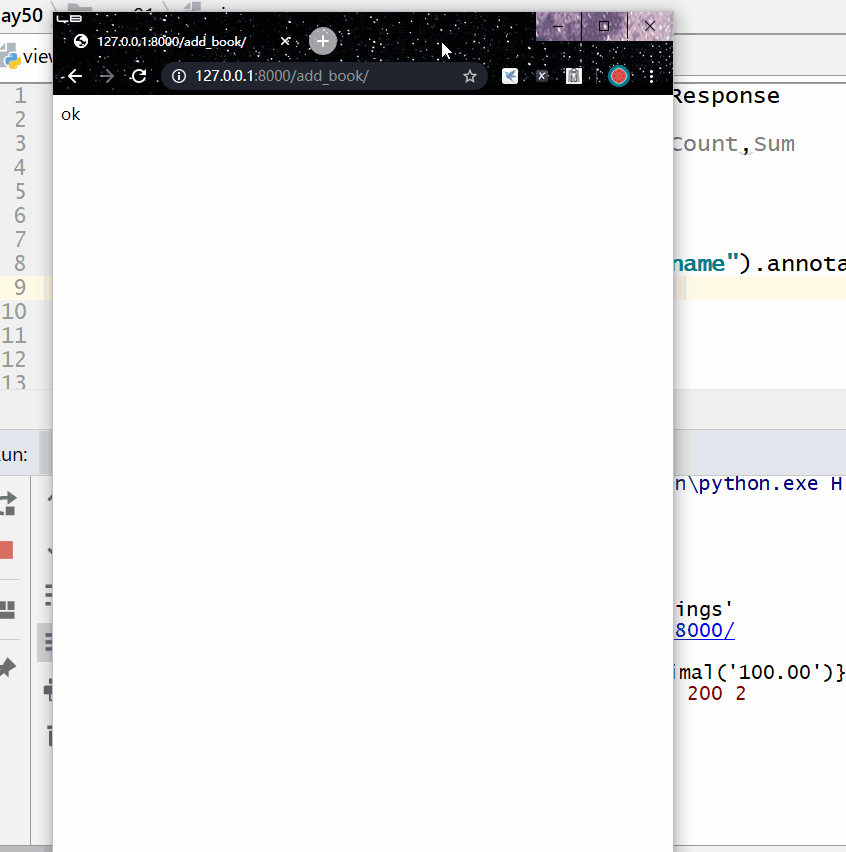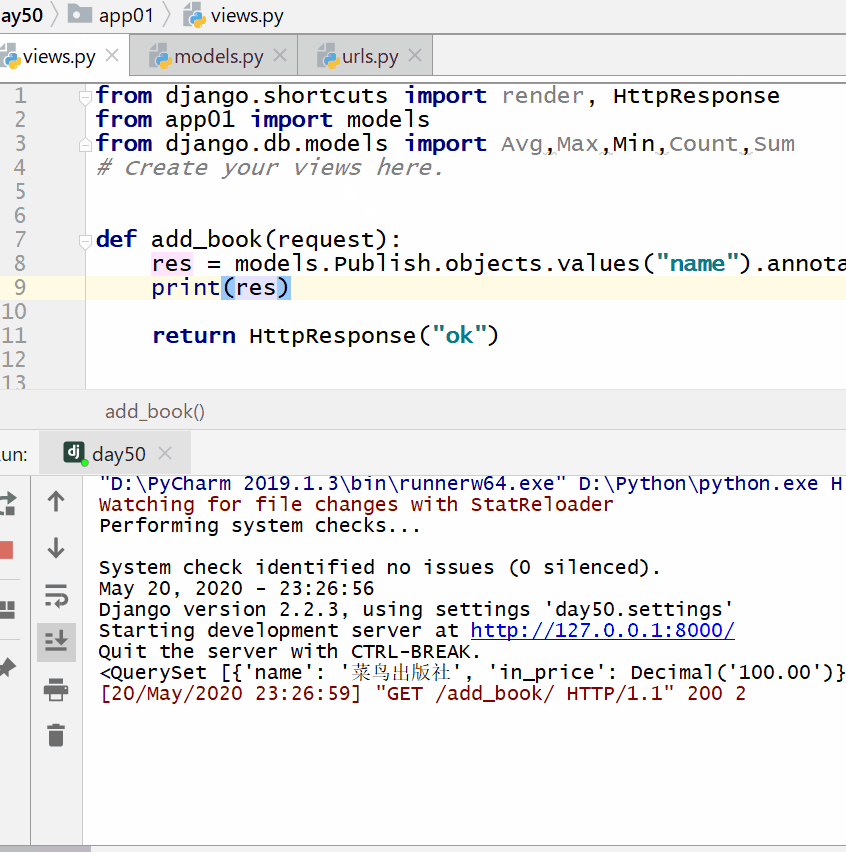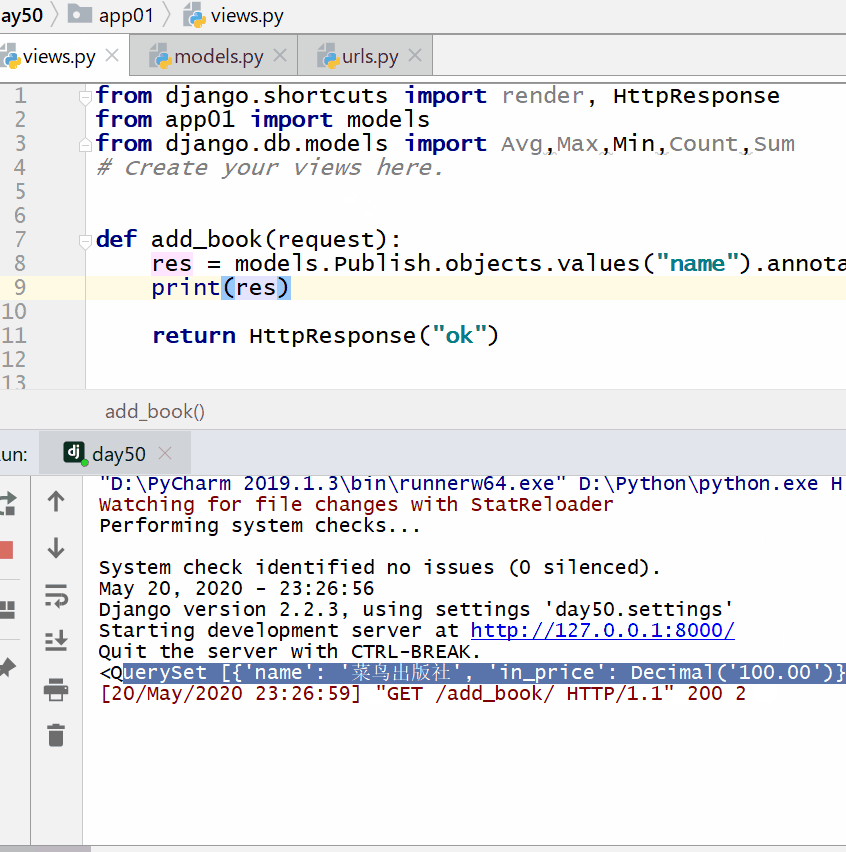
统计每一个出版社的最便宜的书的价格:
命令行中可以看到以下输出:
<QuerySet [{'name': '菜鸟出版社', 'in_price': Decimal('100.00')}, {'name': '明教出版社', 'in_price': Decimal('300.00')}]>
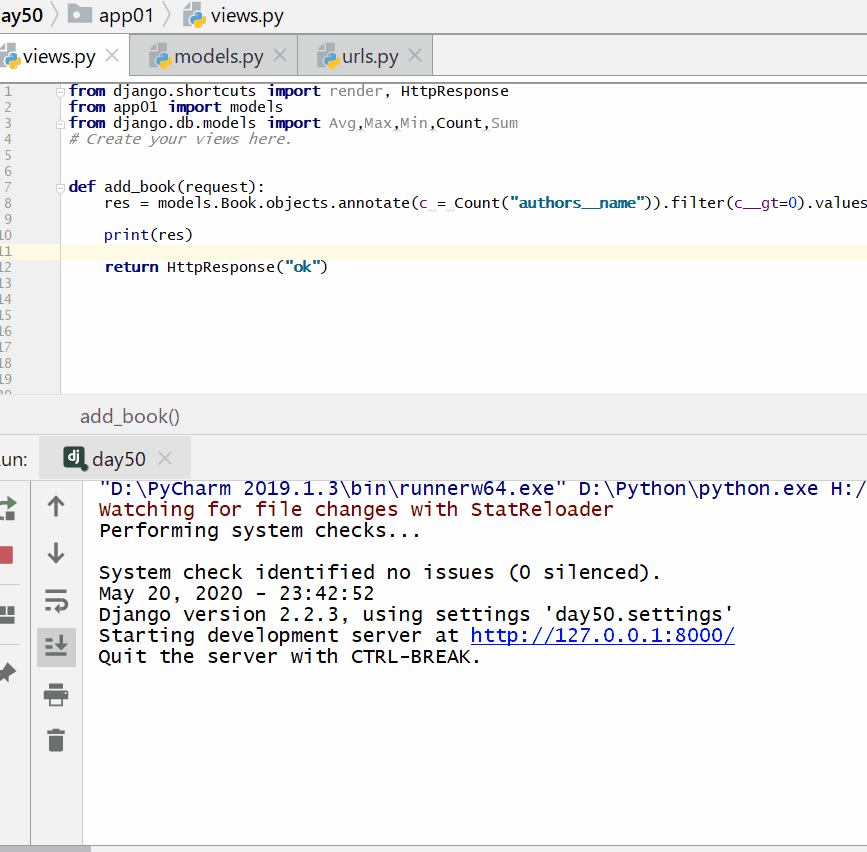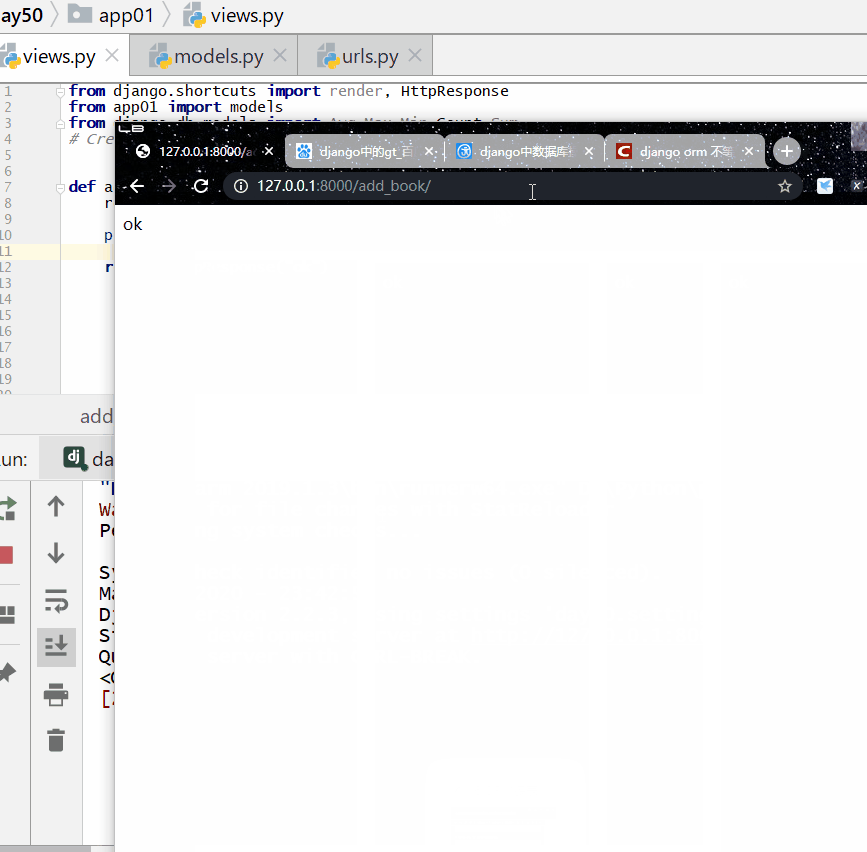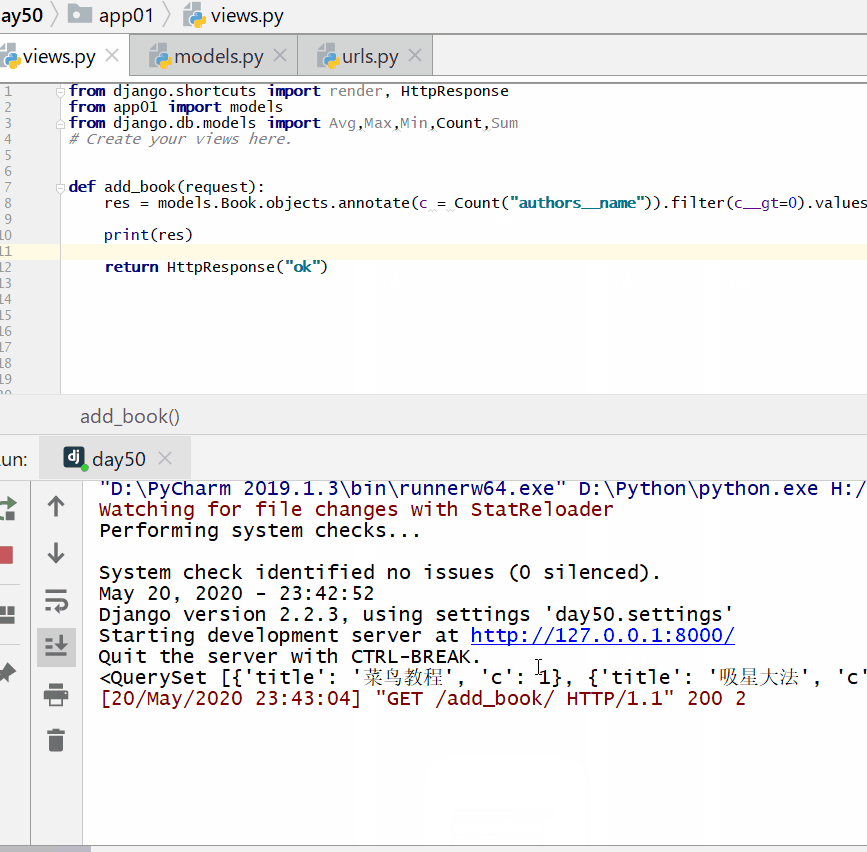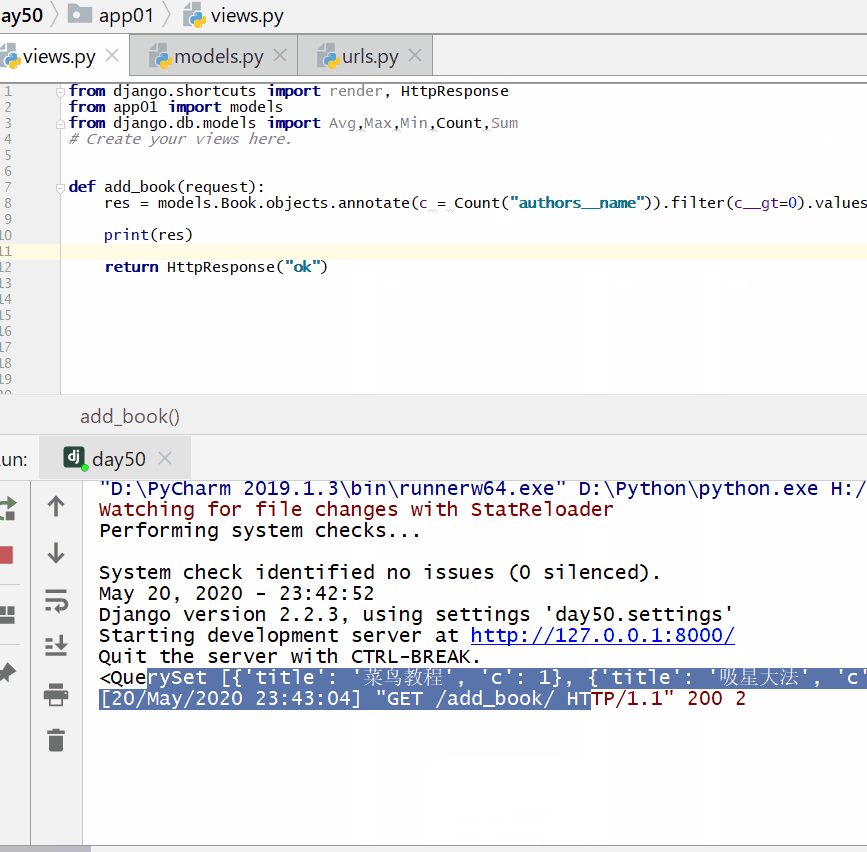
统计每一本书的作者个数:
<QuerySet [{'title': '菜鸟教程', 'c': 1}, {'title': '吸星大法', 'c': 1}, {'title': '冲灵剑法', 'c': 1}]>
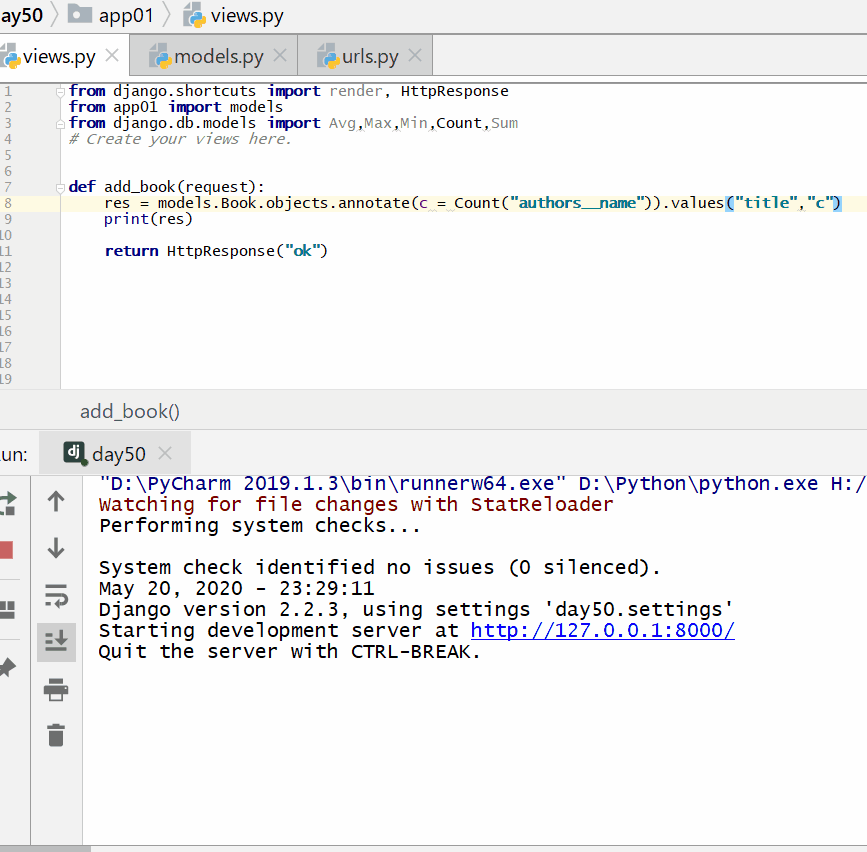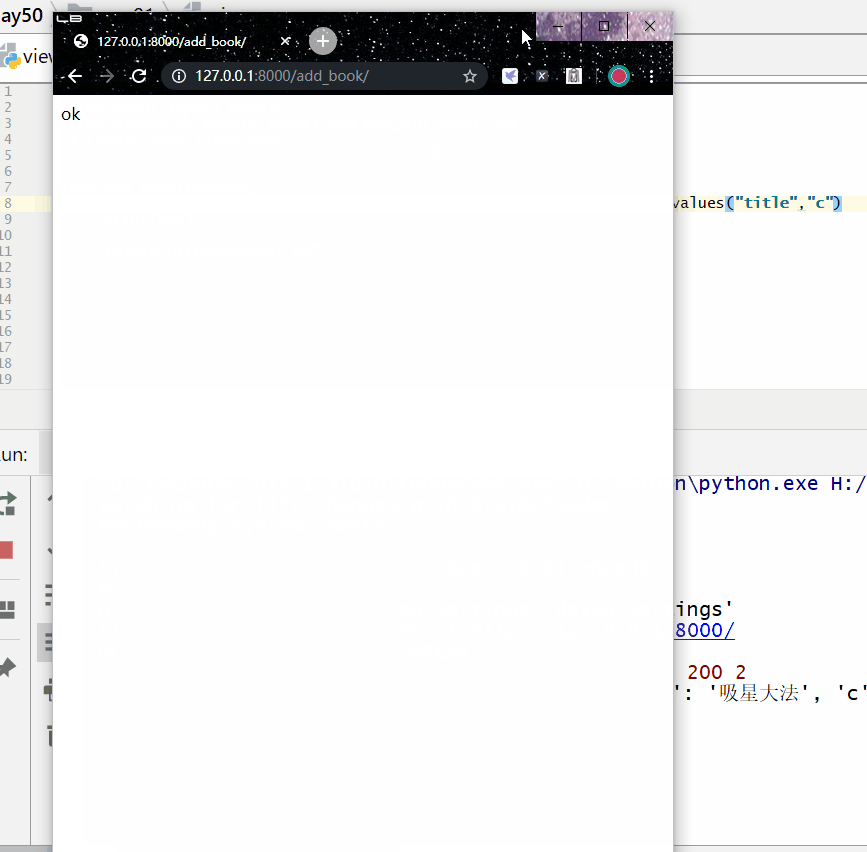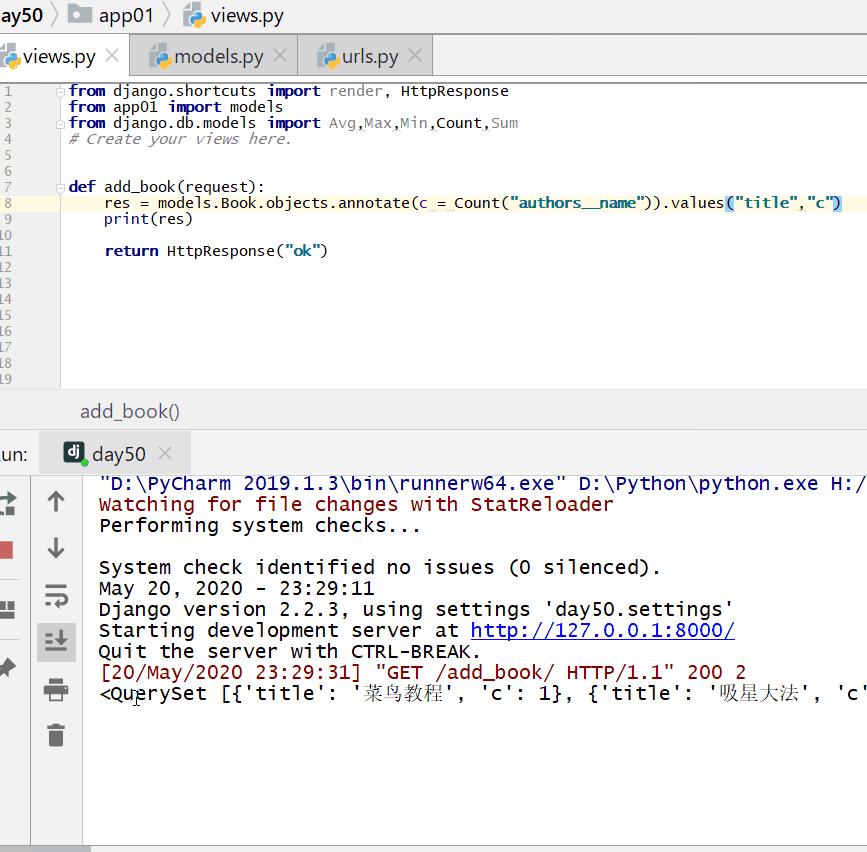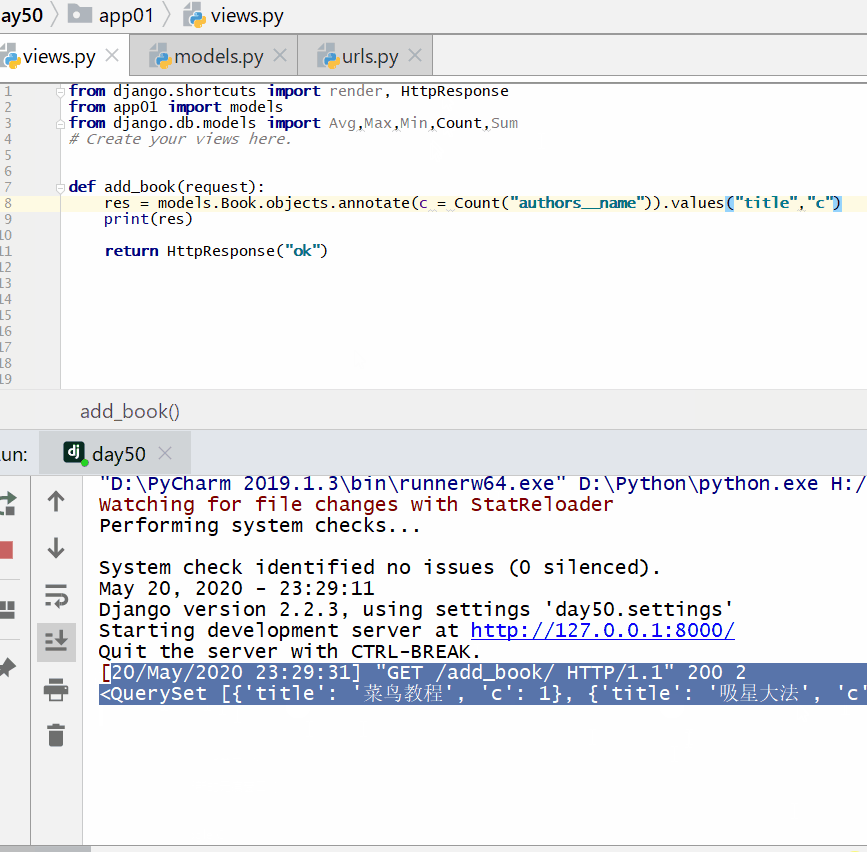
统计每一本以"菜"开头的书籍的作者个数:
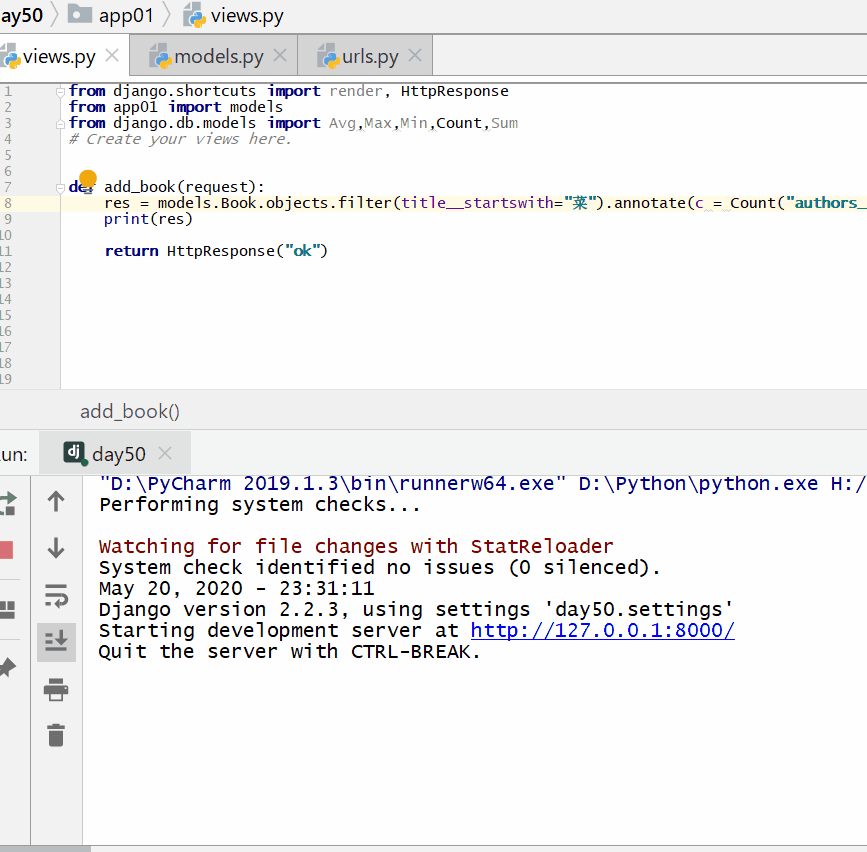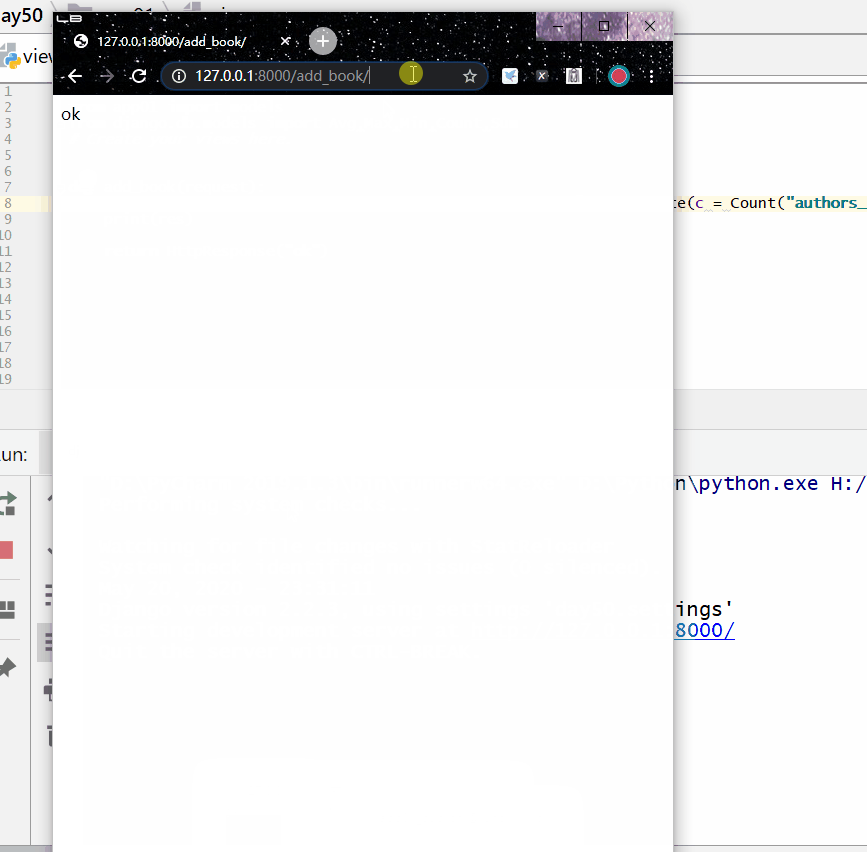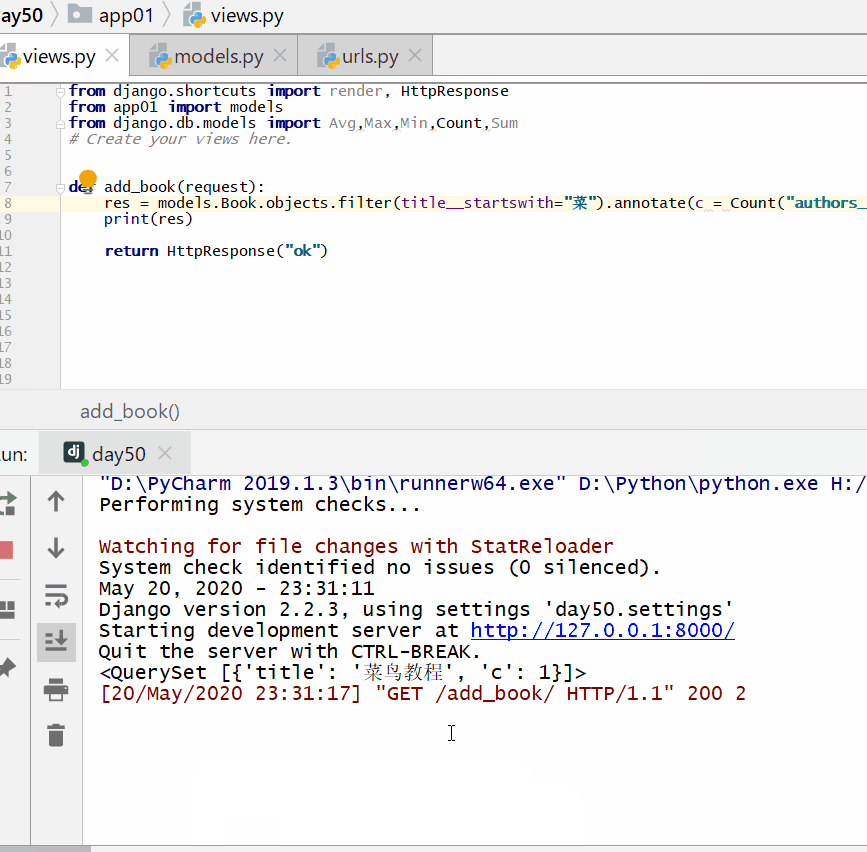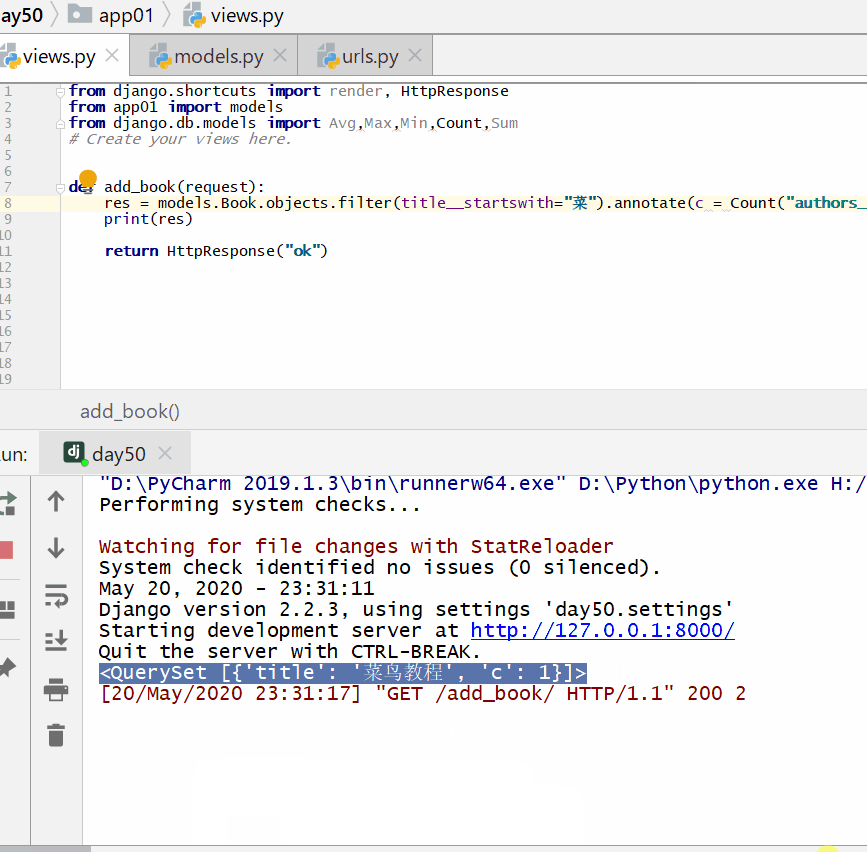
统计不止一个作者的图书名称:
<QuerySet [{'title': '菜鸟教程', 'c': 1}, {'title': '吸星大法', 'c': 1}, {'title': '冲灵剑法', 'c': 1}]>
根据一本图书作者数量的多少对查询集 QuerySet 进行降序排序:
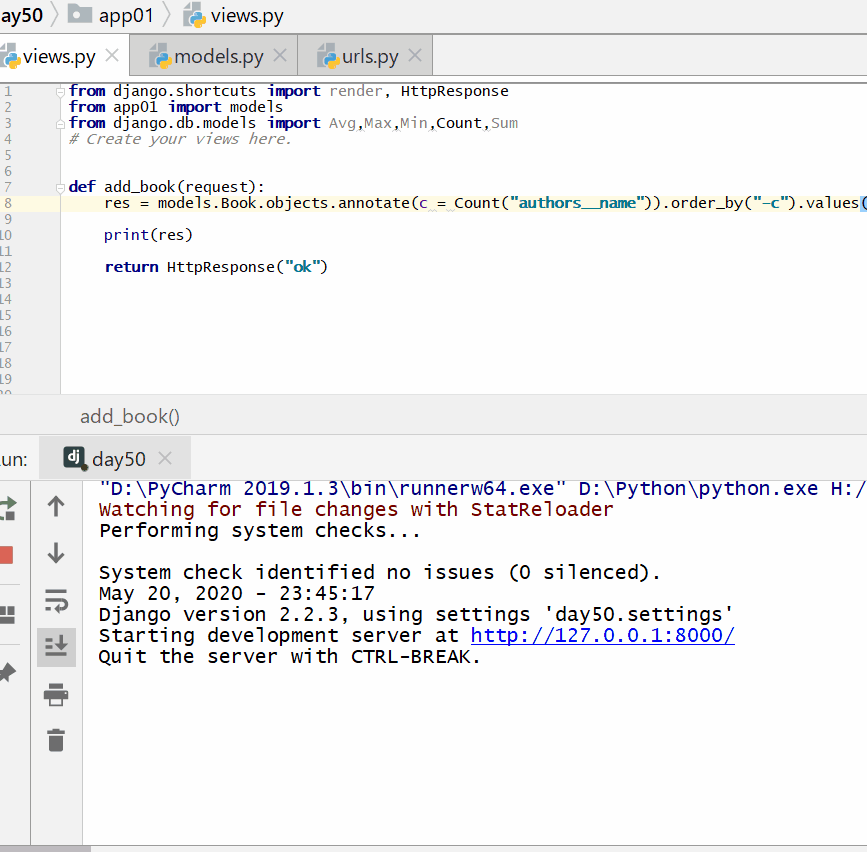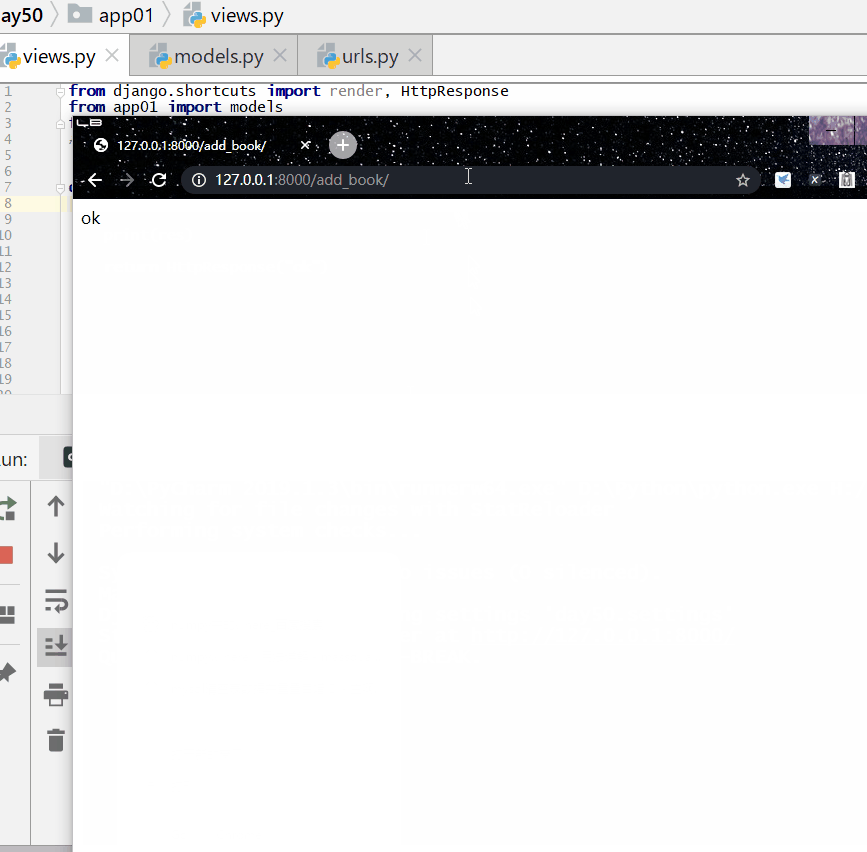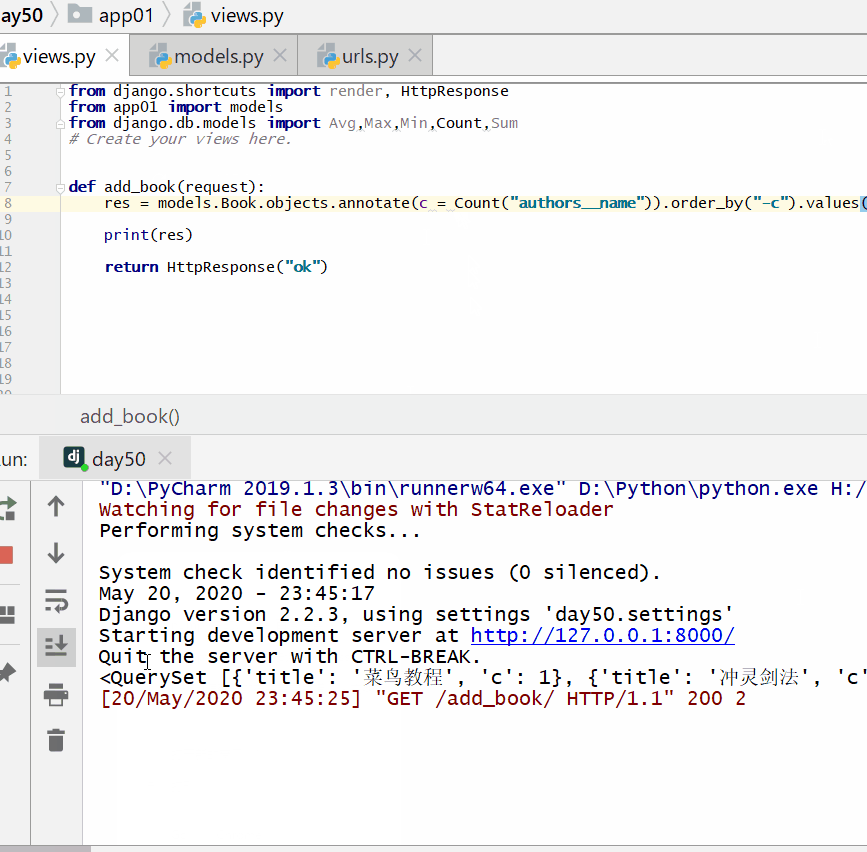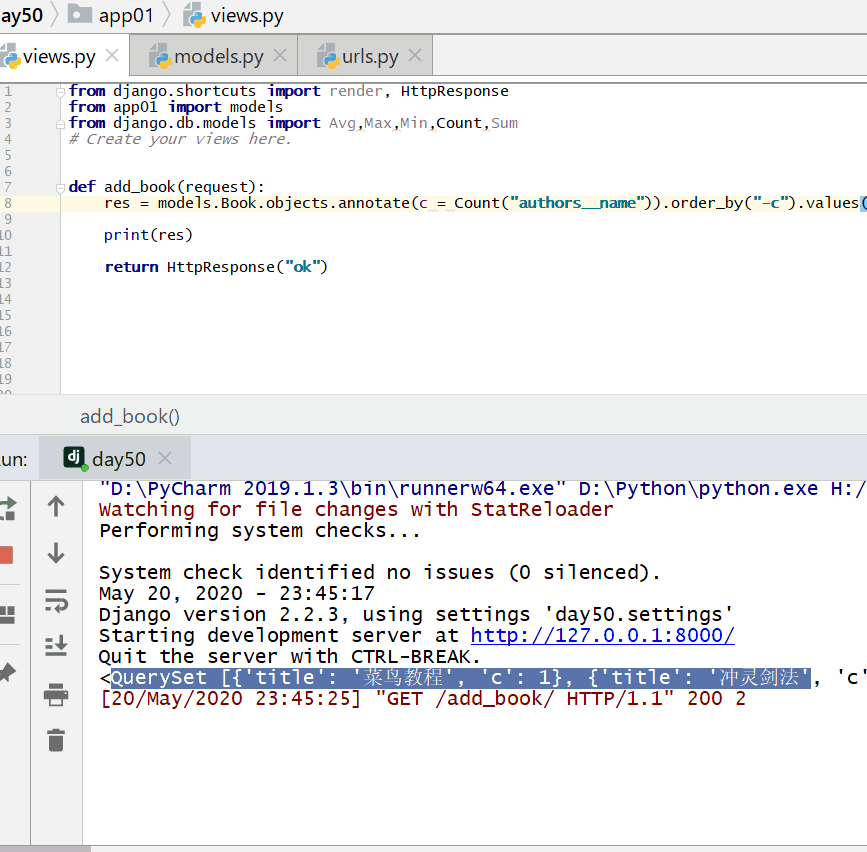
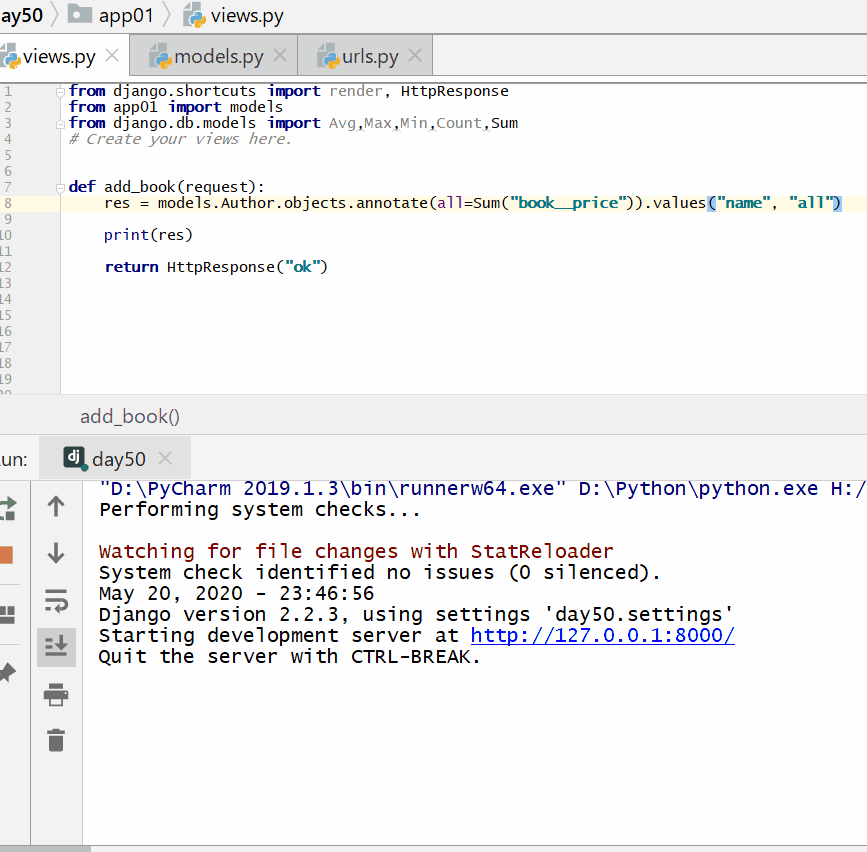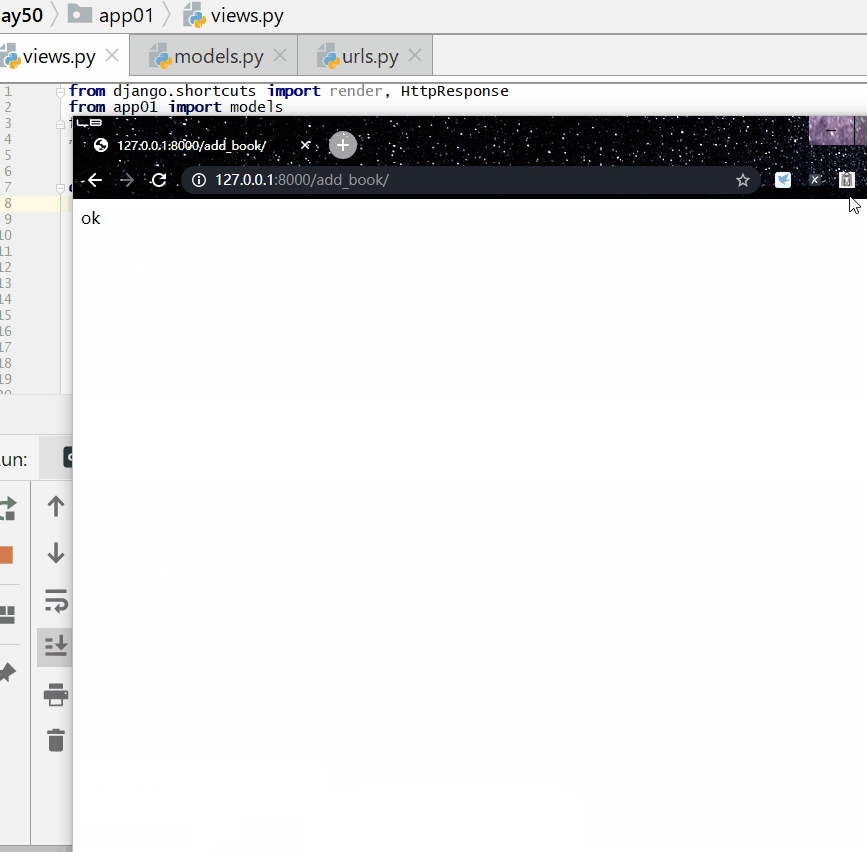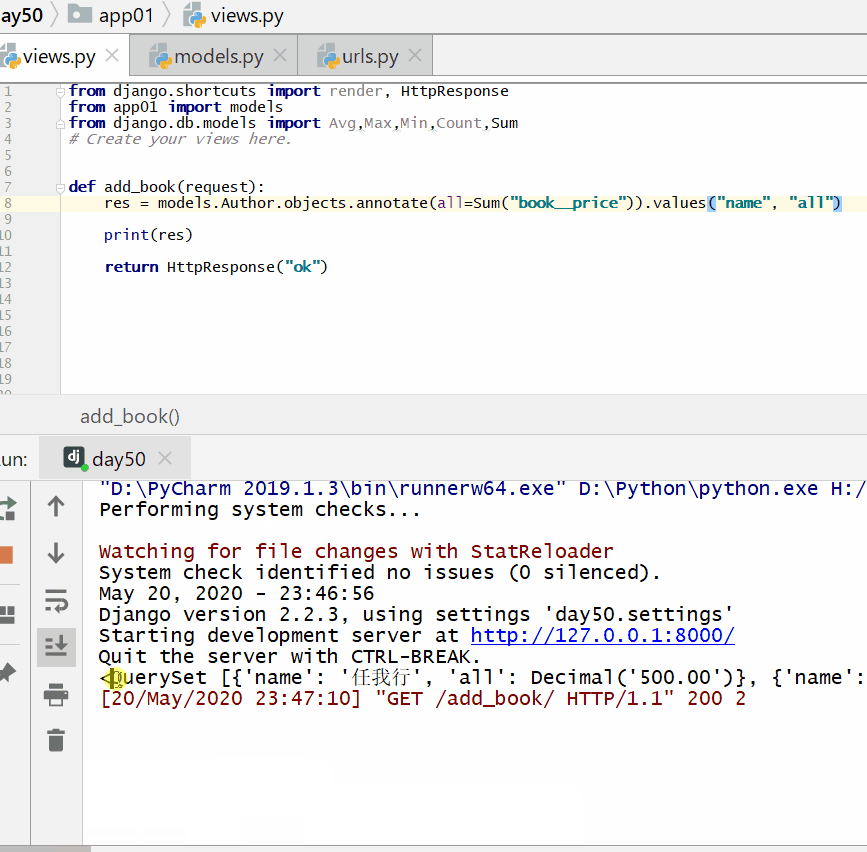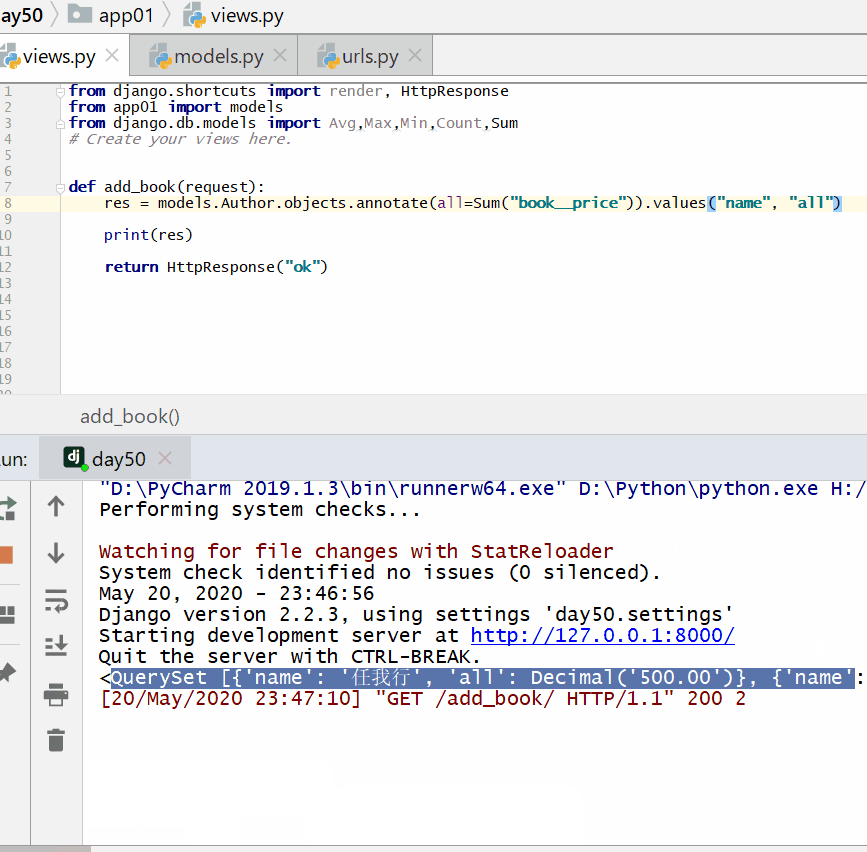
查询各个作者出的书的总价格:
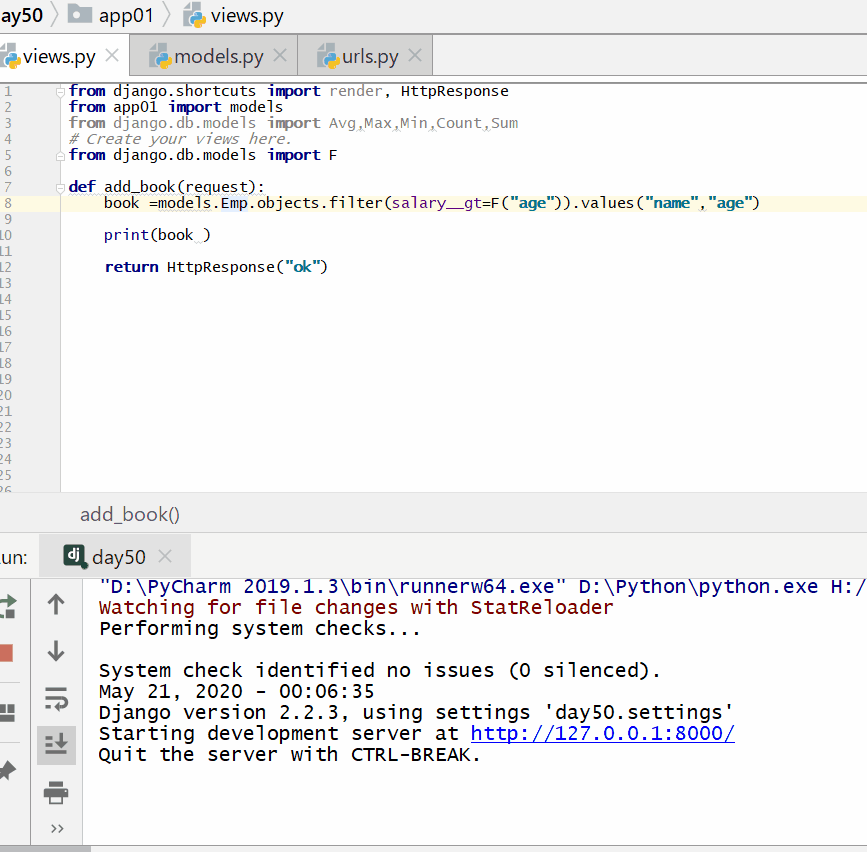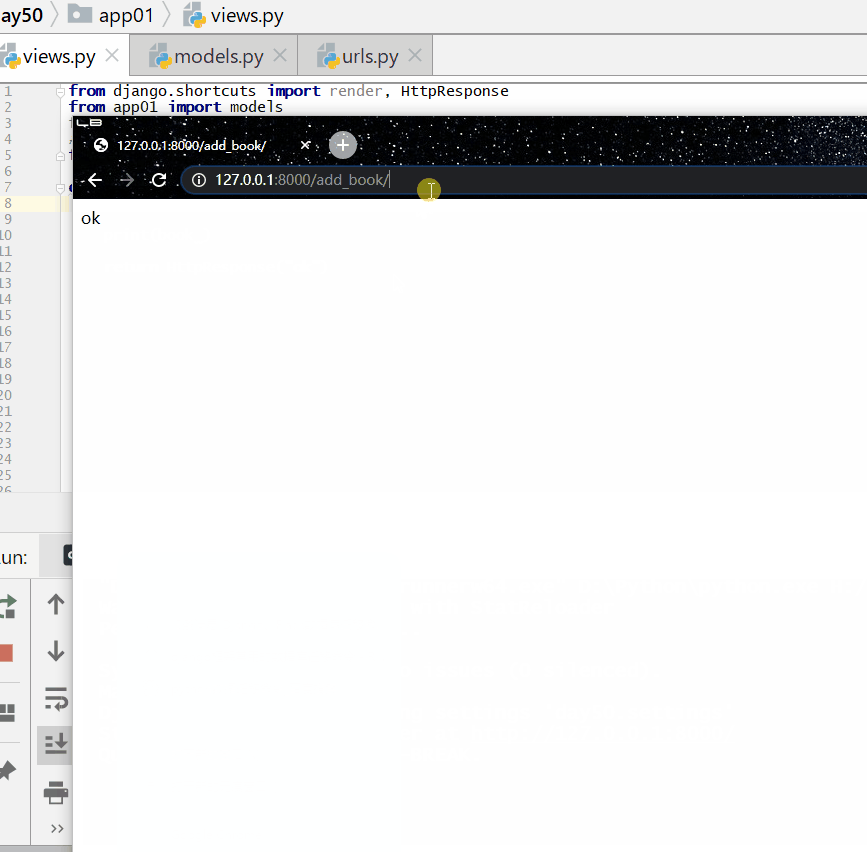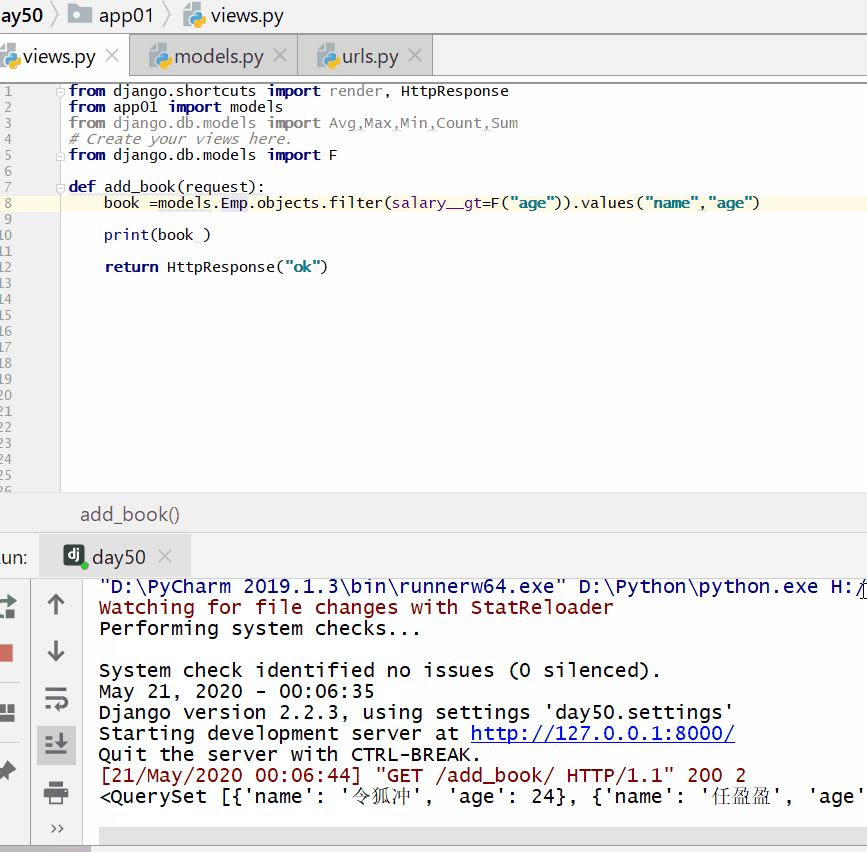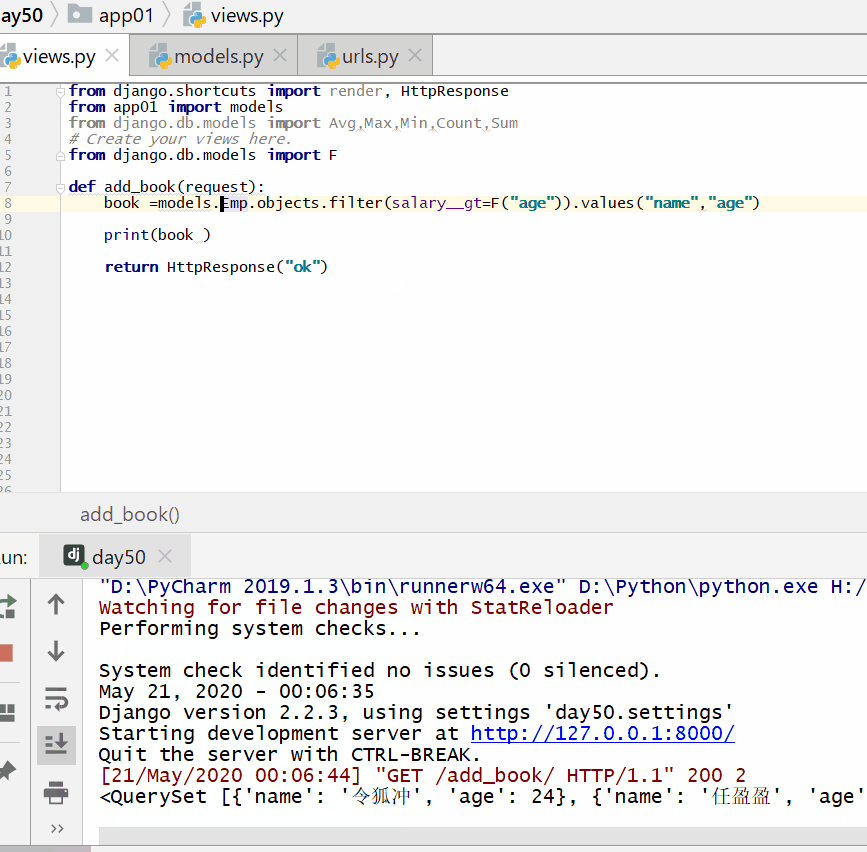
F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
之前构造的过滤器都只是将字段值与某个常量做比较,如果想要对两个字段的值做比较,就需要用到 F()。
使用前要先从 django.db.models 引入 F:
from django.db.models import F
用法:
F("字段名称")
F 动态获取对象字段的值,可以进行运算。
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取余的操作。
修改操作(update)也可以使用 F() 函数。
查询工资大于年龄的人:
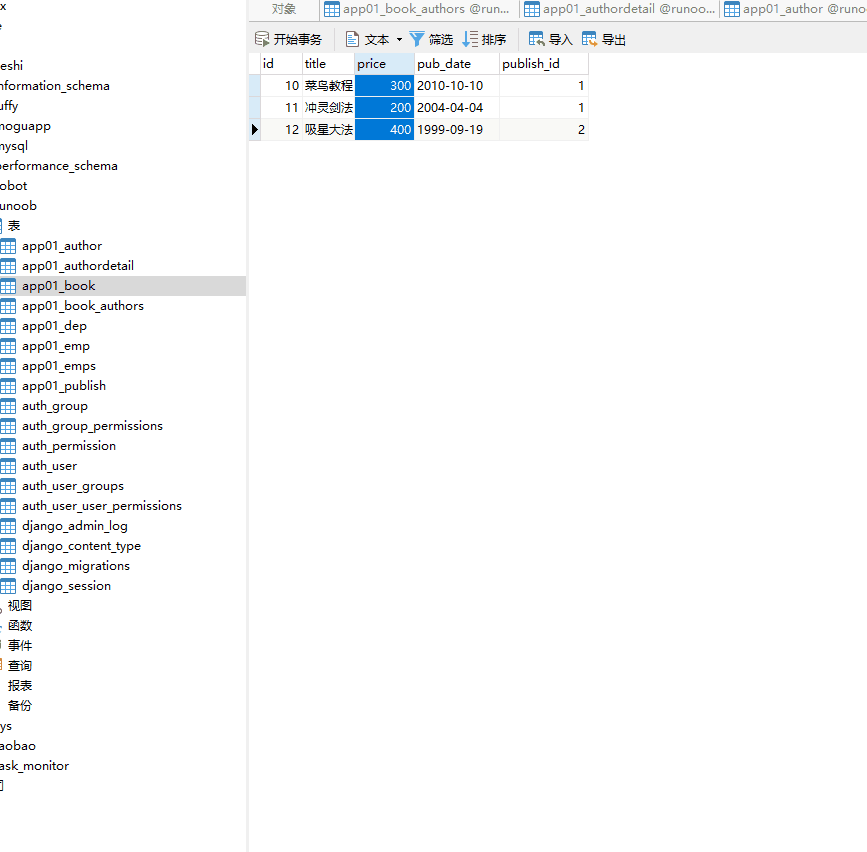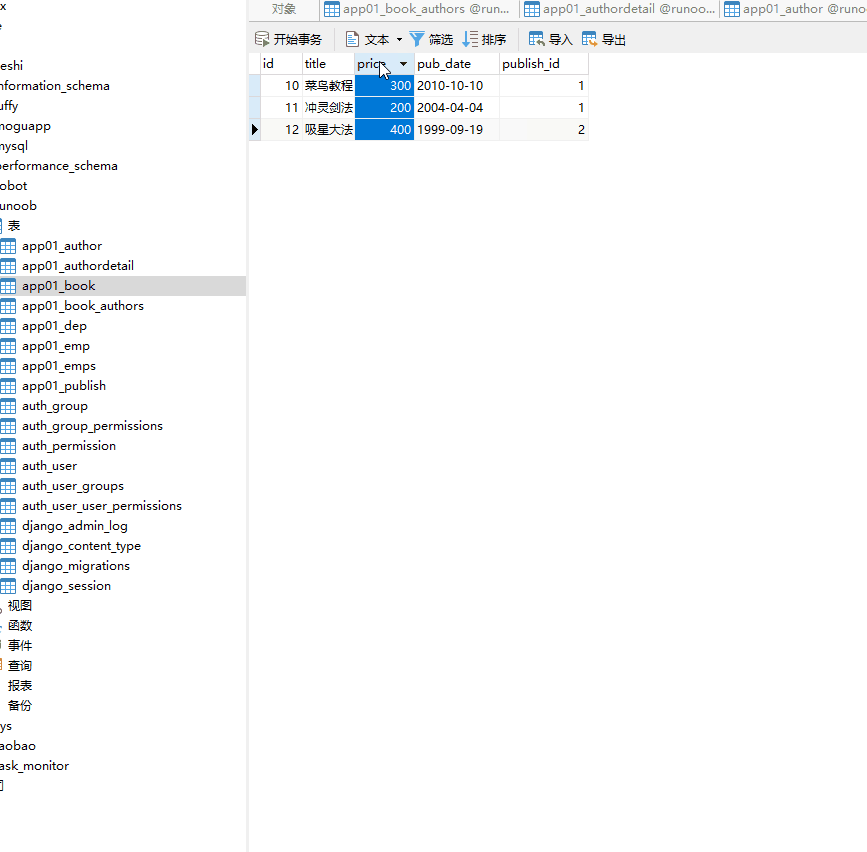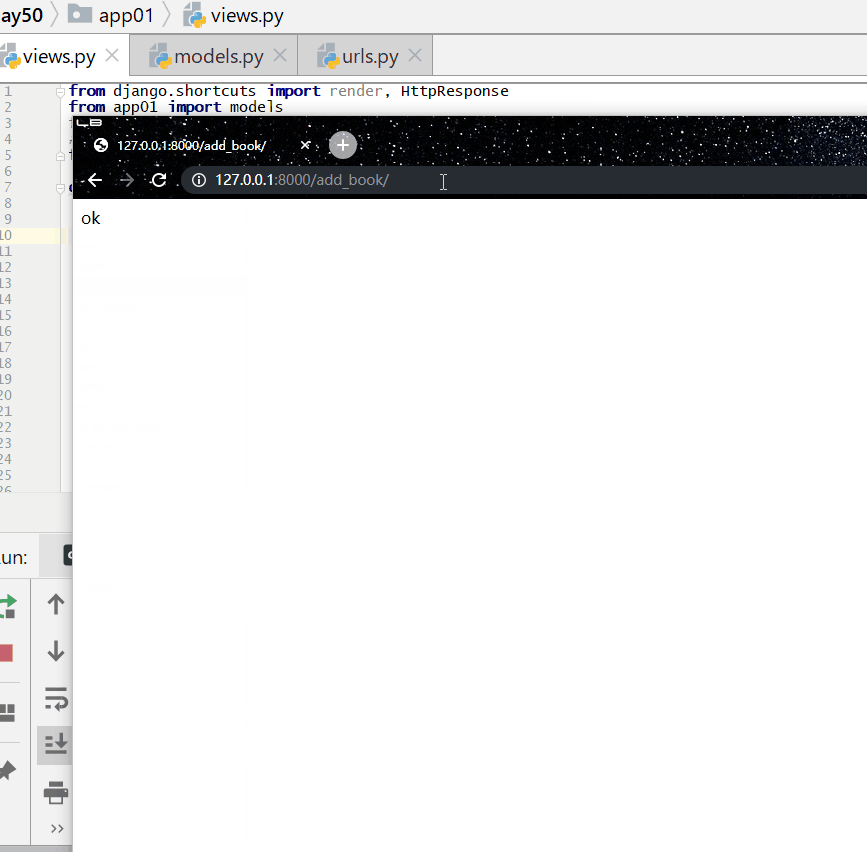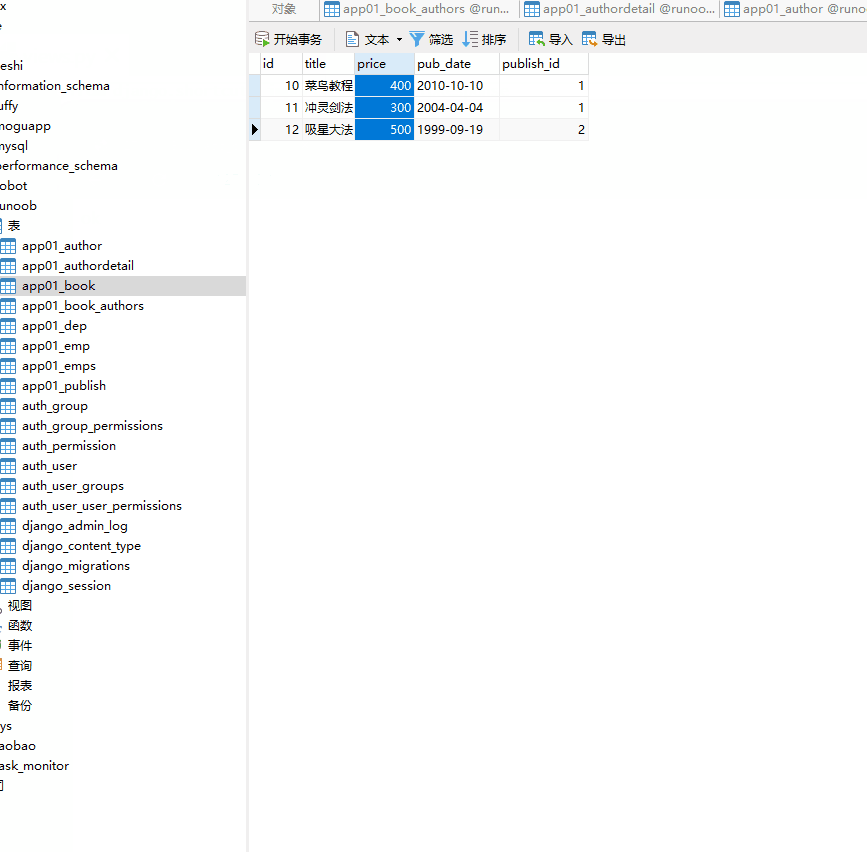
将每一本书的价格提高100元:
from django.db.models import Q
用法:
Q(条件判断)
例如:
Q(title__startswith="菜")
之前构造的过滤器里的多个条件的关系都是 and,如果需要执行更复杂的查询(例如 or 语句),就可以使用 Q 。
Q 对象可以使用 & | ~ (与 或 非)操作符进行组合。
优先级从高到低:~ & |。
可以混合使用 Q 对象和关键字参数,Q 对象和关键字参数是用"and"拼在一起的(即将逗号看成 and ),但是 Q 对象必须位于所有关键字参数的前面。
查询价格大于 350 或者名称以菜开头的书籍的名称和价格。
from django.db.models import Q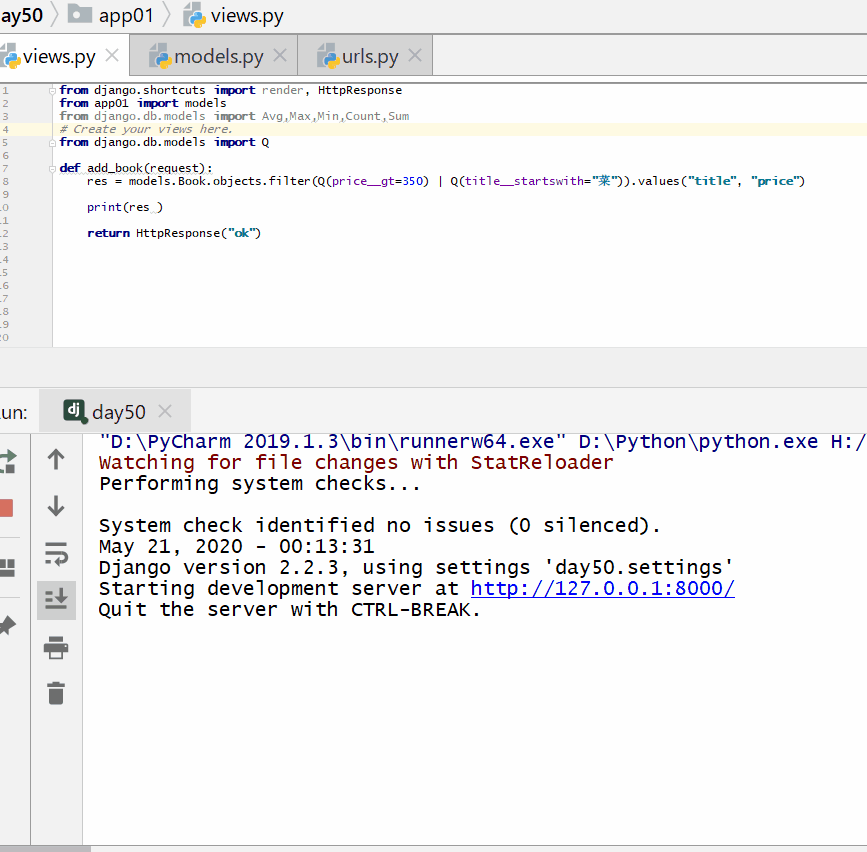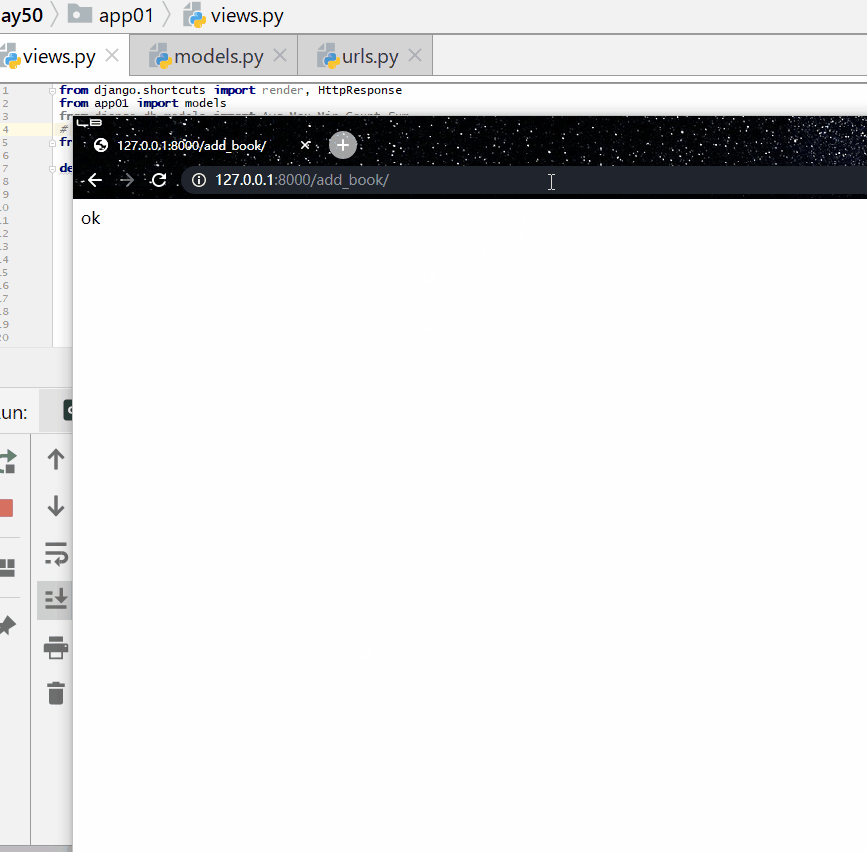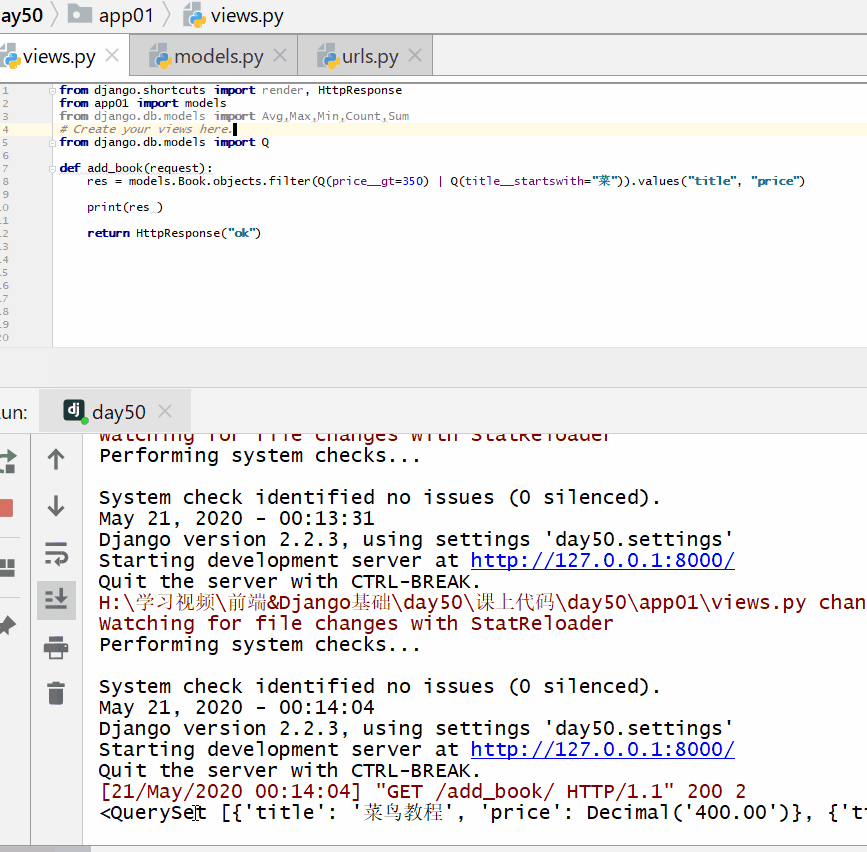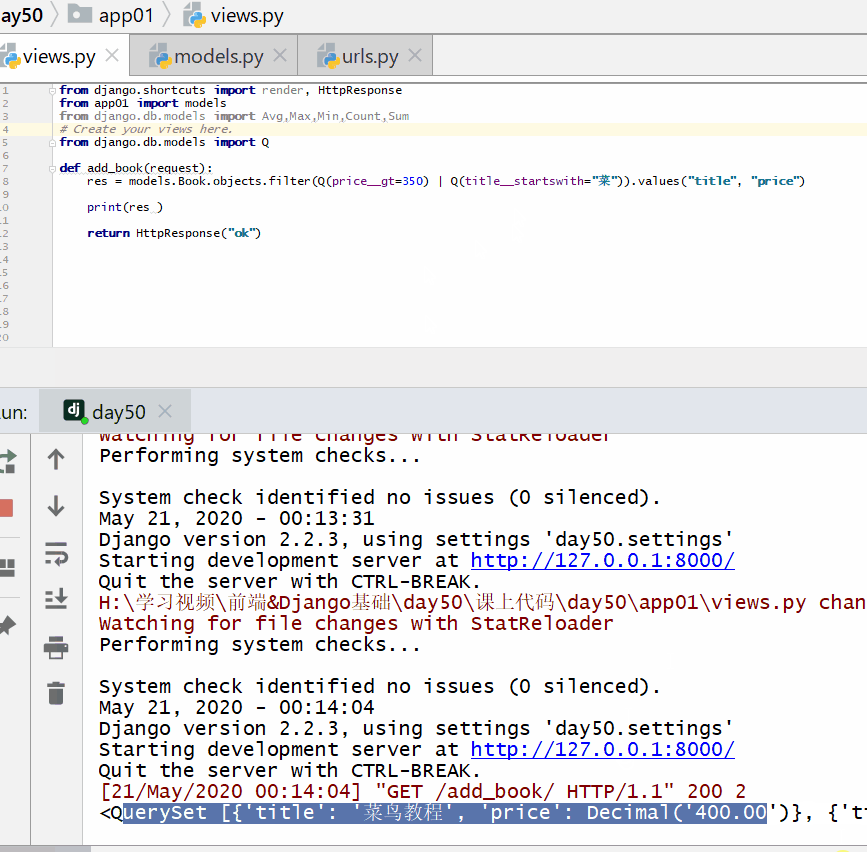
查询以"菜"结尾或者不是 2010 年 10 月份的书籍:
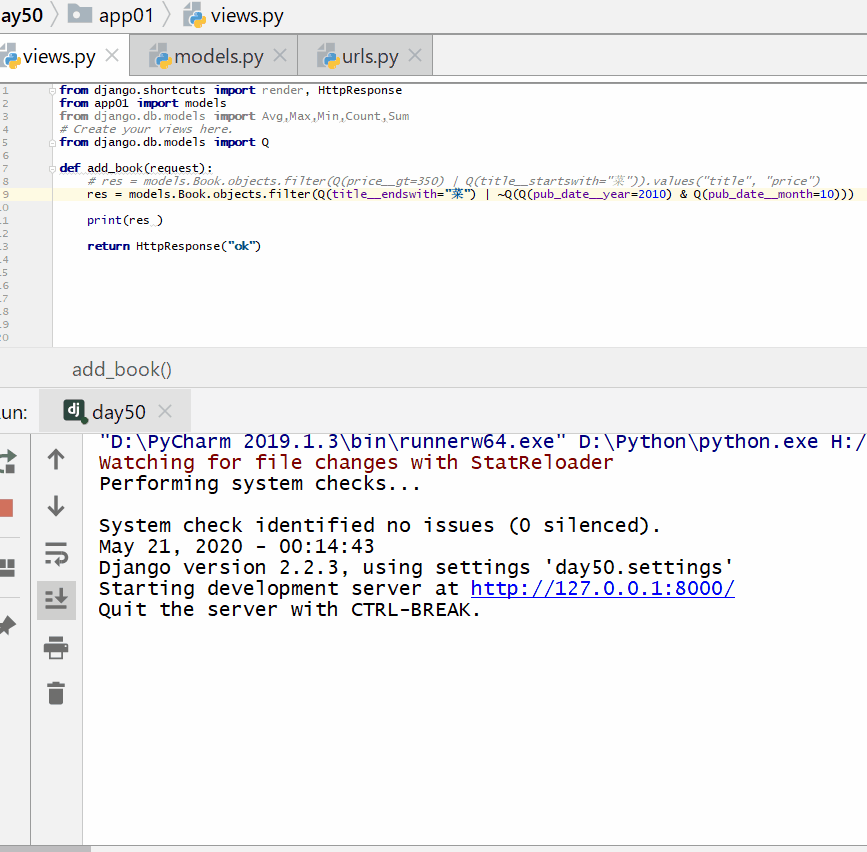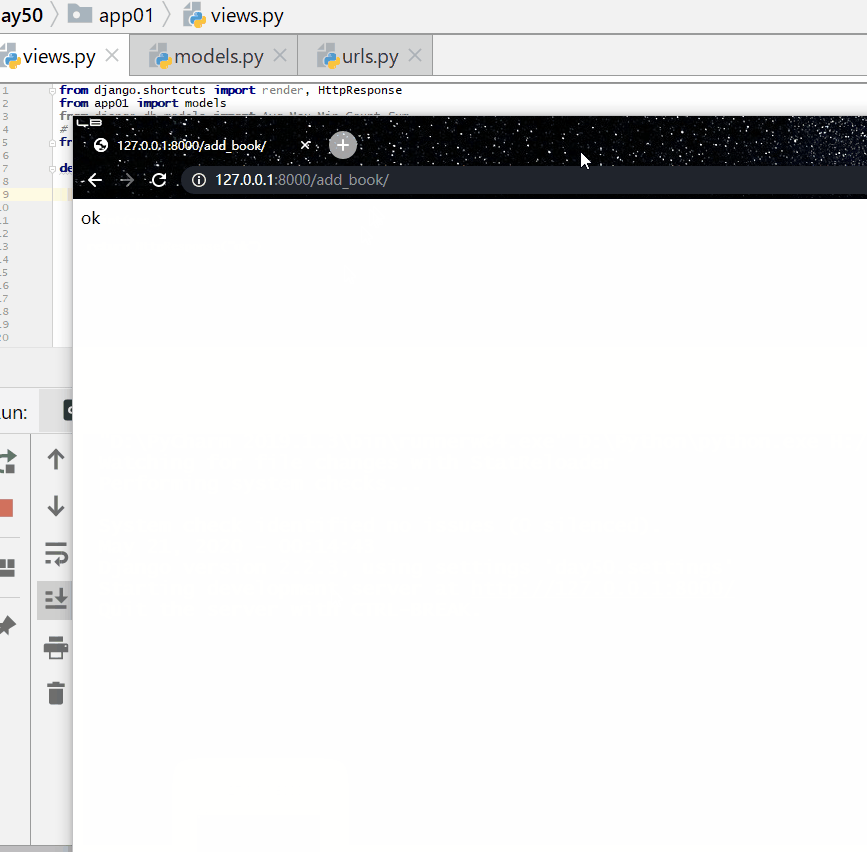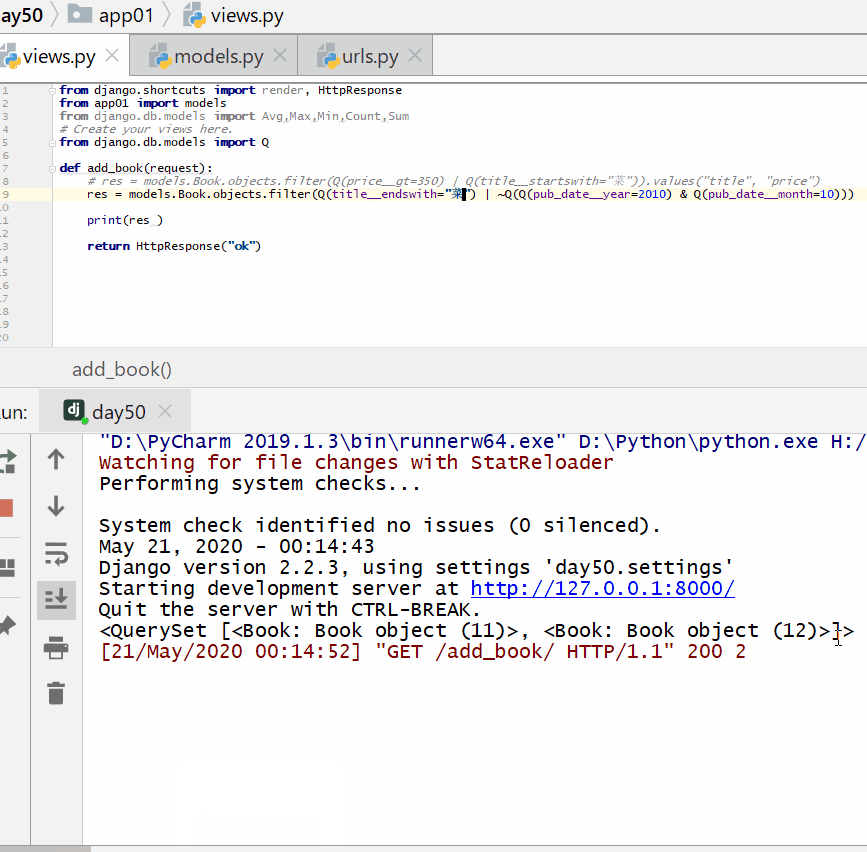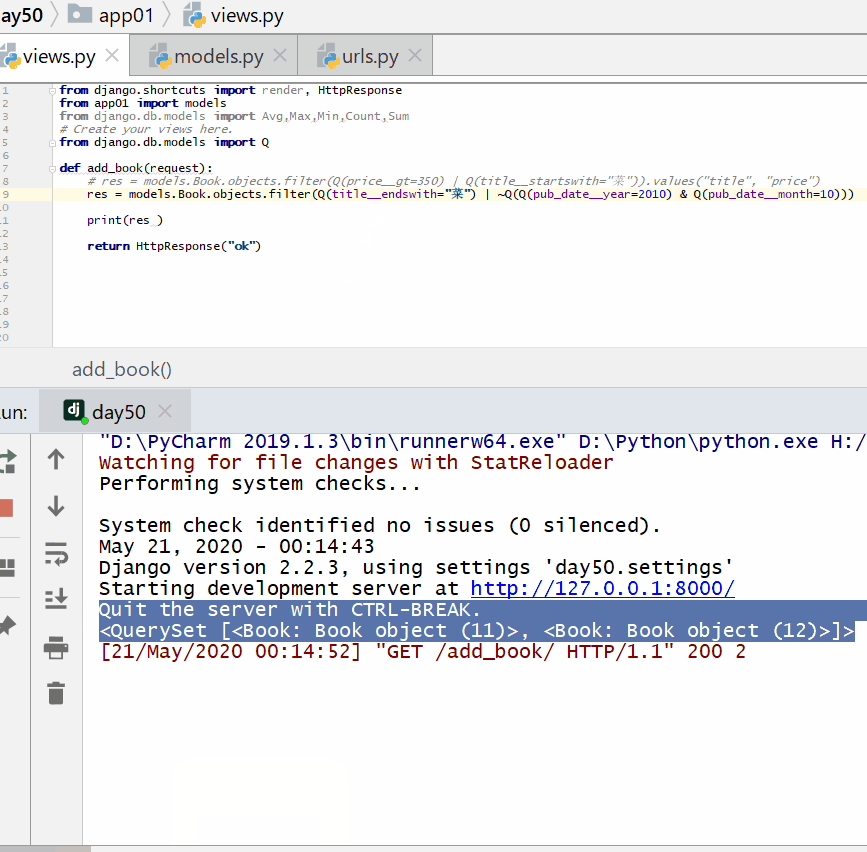
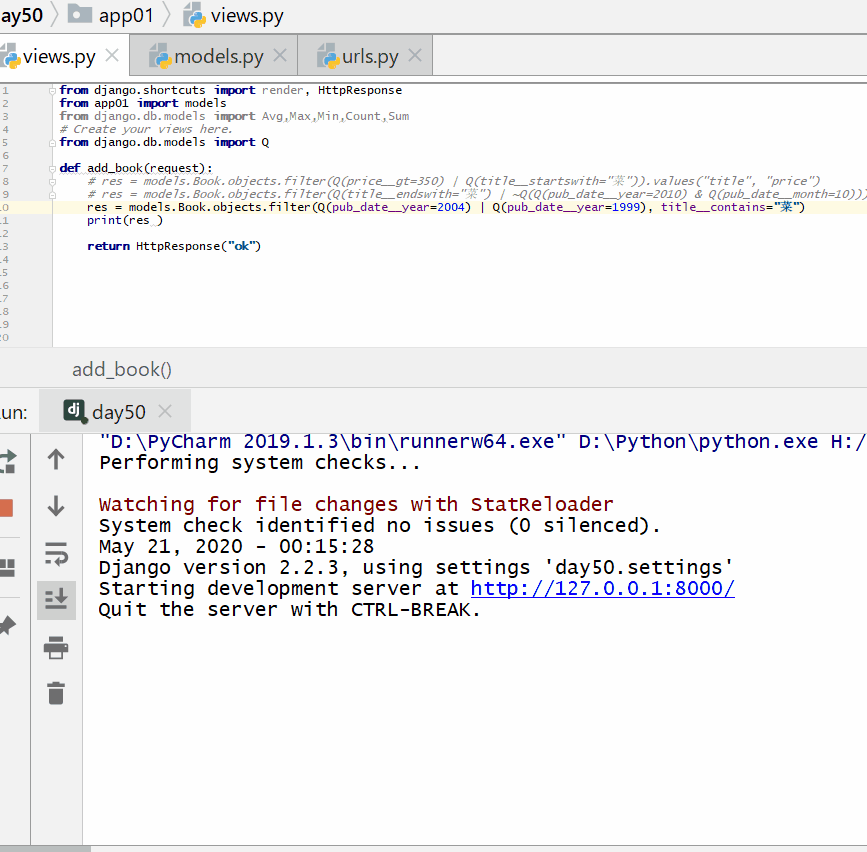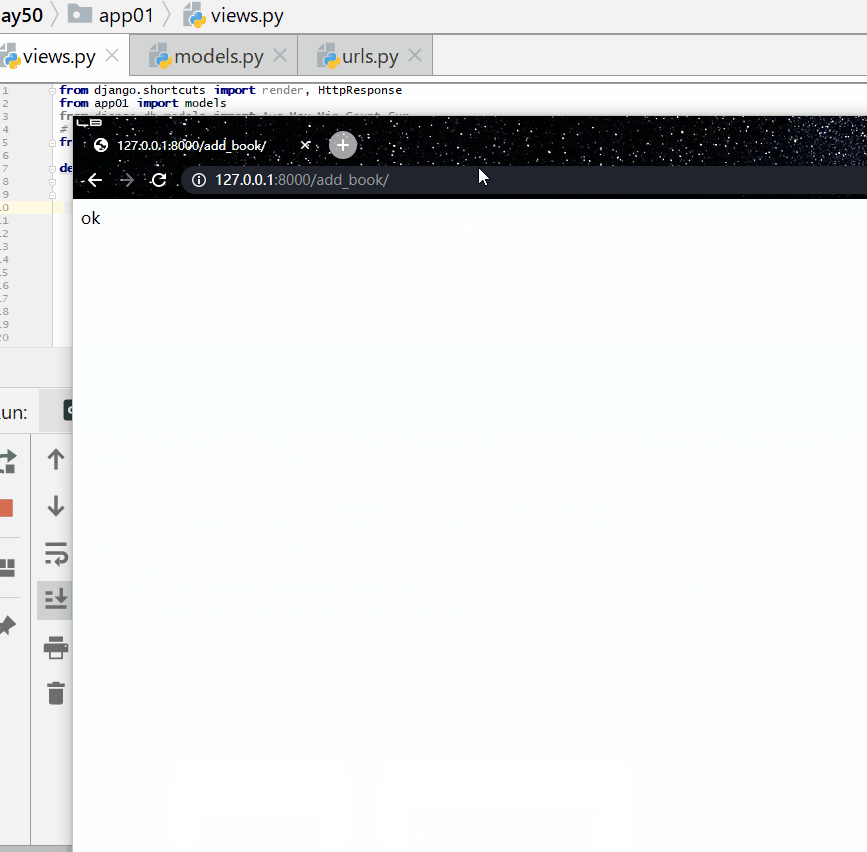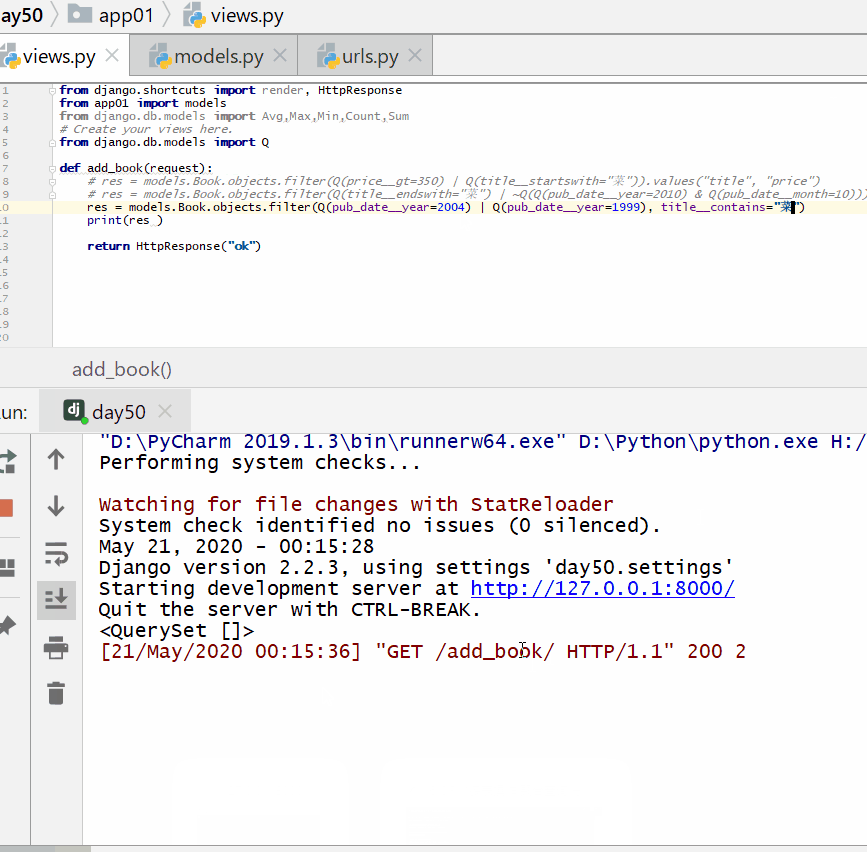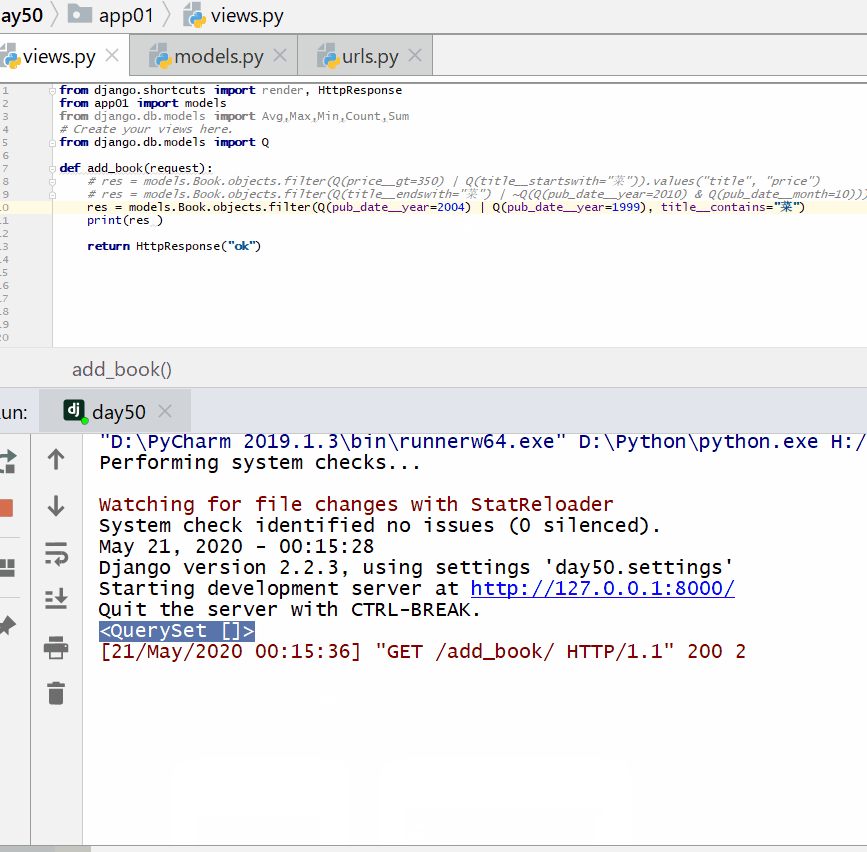
查询出版日期是 2004 或者 1999 年,并且书名中包含有"菜"的书籍。
Q 对象和关键字混合使用,Q 对象要在所有关键字的前面:
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我已经有很多两个值数组,例如下面的例子ary=[[1,2],[2,3],[1,3],[4,5],[5,6],[4,7],[7,8],[4,8]]我想把它们分组到[1,2,3],[4,5],[5,6],[4,7,8]因为意思是1和2有关系,2和3有关系,1和3有关系,所以1,2,3都有关系我如何通过ruby库或任何算法来做到这一点? 最佳答案 这是基本Bron–Kerboschalgorithm的Ruby实现:classGraphdefinitialize(edges)@edges=edgesenddeffind_maximum_