在官方文档上面就有结束搭建nacos是介绍
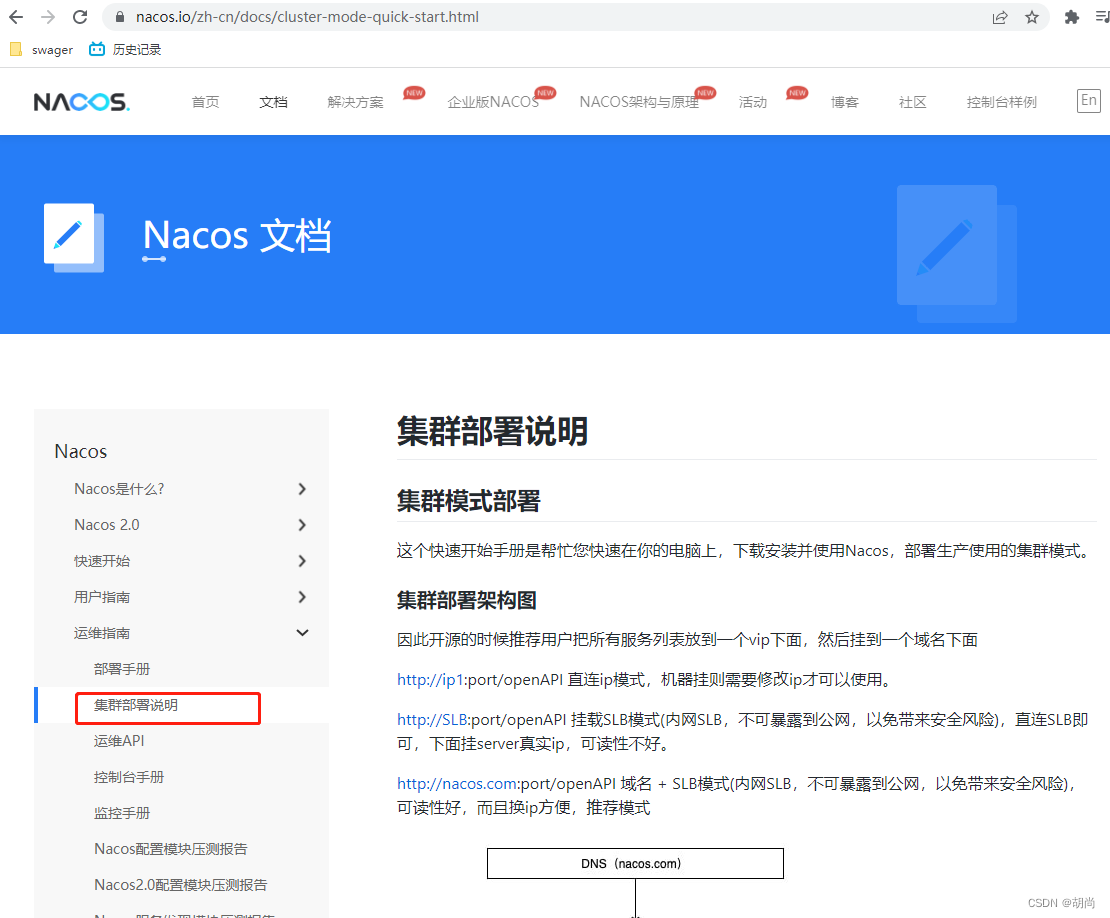
官方文档提供了一个Nacos集群的架构图,当我们访问Nacos时,首先会经过SLB,也就是负载均衡,通常是一个nginx,通过nginx来进行分发到具体的Nacos服务器上面。我们需要给不同的服务器进行部署Nacos,我们这里演示的是一个伪的集群,在一台服务器上面搭建三个Nacos。
1. 环境准备
请确保是在环境中安装使用:
2. Nocas下载:https://github.com/alibaba/nacos/releases
将下载好的安装包上传到linux服务器上并进行解压
[root@VM-8-14-centos nacos]# tar -zxvf nacos-server-1.4.1.tar.gz
[root@VM-8-14-centos nacos]# ll
drwxr-xr-x 5 root root 4096 Jun 7 20:39 nacos
-rw-r--r-- 1 root root 79052411 Jun 7 20:39 nacos-server-1.4.1.tar.gz
# 将解压后的nacos目录改一个名字,并复制三份,目录名结尾加一个端口
[root@VM-8-14-centos nacos]# mv nacos nacos8849
[root@VM-8-14-centos nacos]# cp -r nacos8849/ nacos8850
[root@VM-8-14-centos nacos]# cp -r nacos8849/ nacos8851
[root@VM-8-14-centos nacos]# ll
drwxr-xr-x 5 root root 4096 Jun 7 20:39 nacos8849
drwxr-xr-x 5 root root 4096 Jun 7 20:50 nacos8850
drwxr-xr-x 5 root root 4096 Jun 7 20:50 nacos8851
-rw-r--r-- 1 root root 79052411 Jun 7 20:39 nacos-server-1.4.1.tar.gz
配置集群配置文件
在nacos的解压目录nacos/的conf目录下,有配置文件cluster.conf,请每行配置成ip:port。
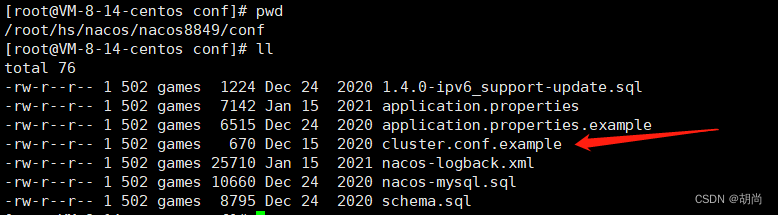
# 创建cluster.conf文件
[root@VM-8-14-centos conf]# vim cluster.conf
# 输入以下内容,如果是真实的生产环境就配置各个服务器的ip和端口
114.132.75.63:8849
114.132.75.63:8850
114.132.75.63:8851
确定数据源
为什么需要将数据源配置成mysql数据库嘞?
这是因为nacos默认的数据源是使用的内置数据源,是存在内存中的,那么我们启动nacos集群的时候内存中的数据肯定就不能共享了,到时候我们的数据进行注册的话就会注册到各自的Nacos服务器中,这也就会造成数据不一致。为了保证数据一致性就需要将数据源改为数据库。
我们首先需要安装好数据库,然后创建一个数据库,然后执行安装包中提供的sql脚本,这个sql脚本只是一些建表语句,所以需要我们先创建一个数据库,需要注意mysql需要使用5.7+以上的版本,如果用低版本的mysql在执行sql脚本的时候可能会报错
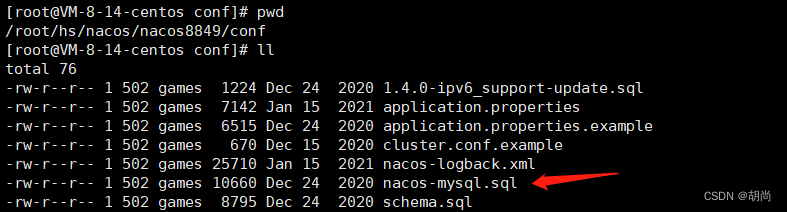
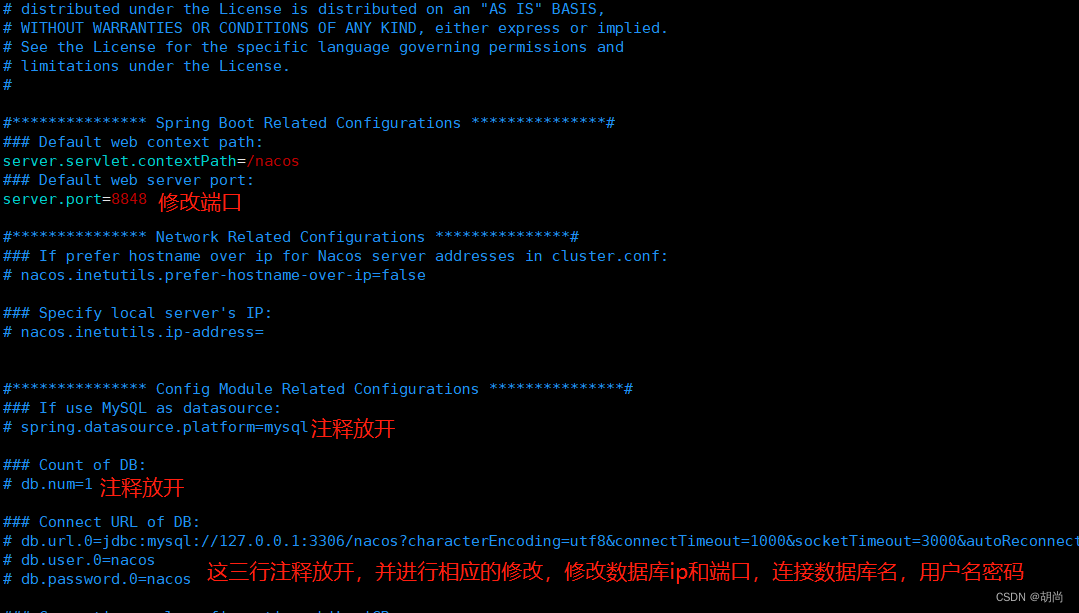
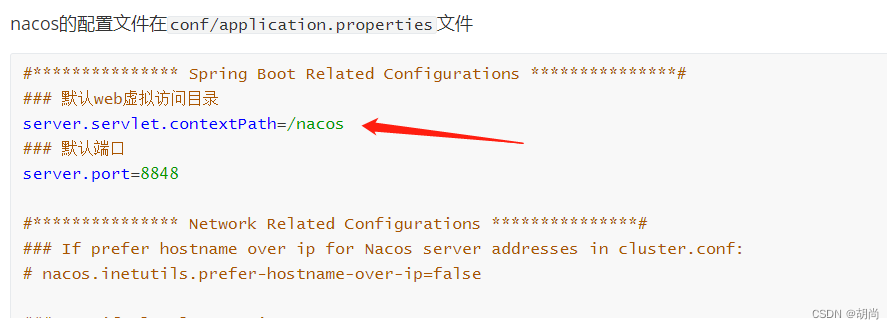
执行完sql脚本之后,编辑conf/application.properties文件,修改的内容如下图所示
修改启动脚本
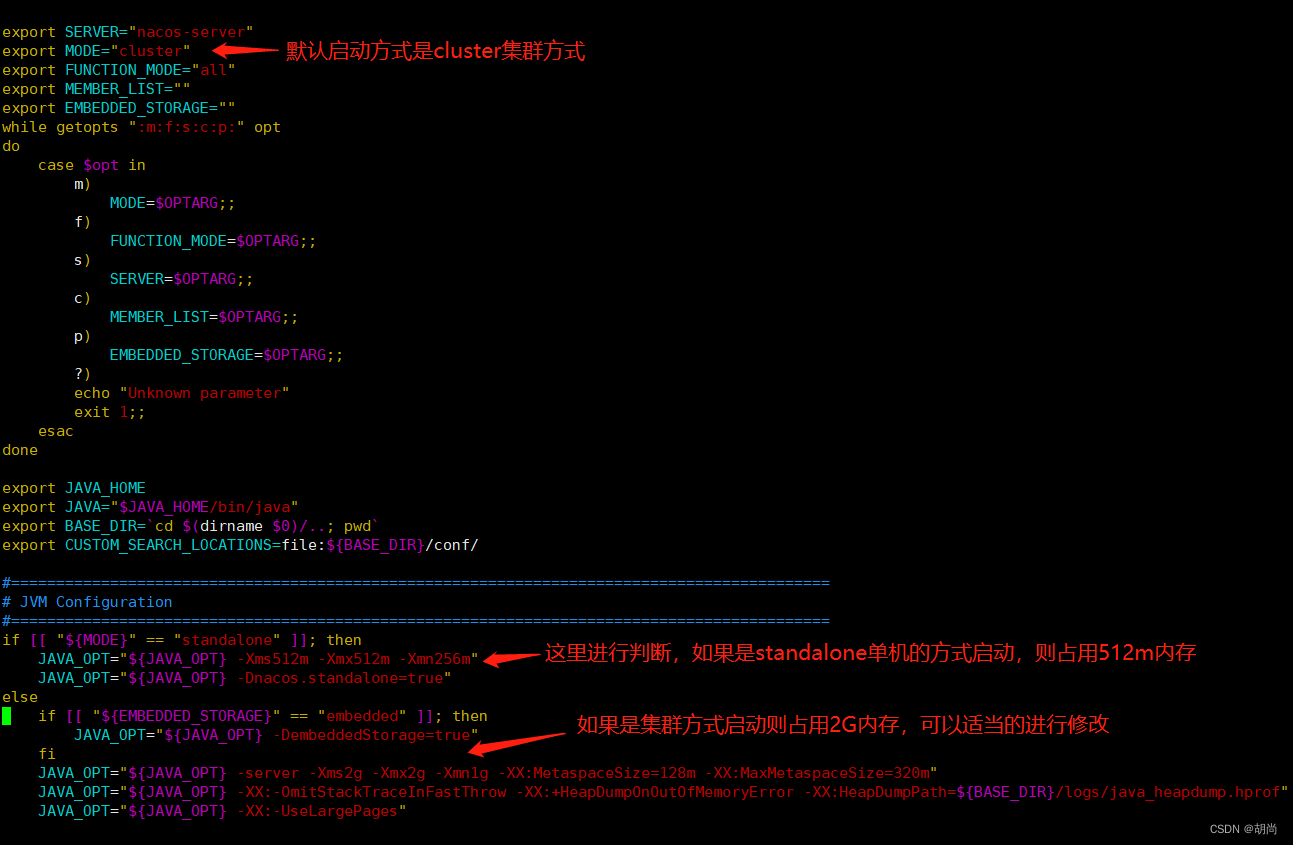
我们还需要修改bin/startup.sh 启动脚本,因为如果是以集群的方式启动,Nacos默认占用的内存是2G,如果服务器的内存足够大可以不进行修改。
[root@VM-8-14-centos nacos8849]# vim bin/startup.sh
修改完成之后就可以启动了
[root@VM-8-14-centos nacos8849]# bin/startup.sh
启动完成后,最后一行日志提示可以让我们去查看日志文件

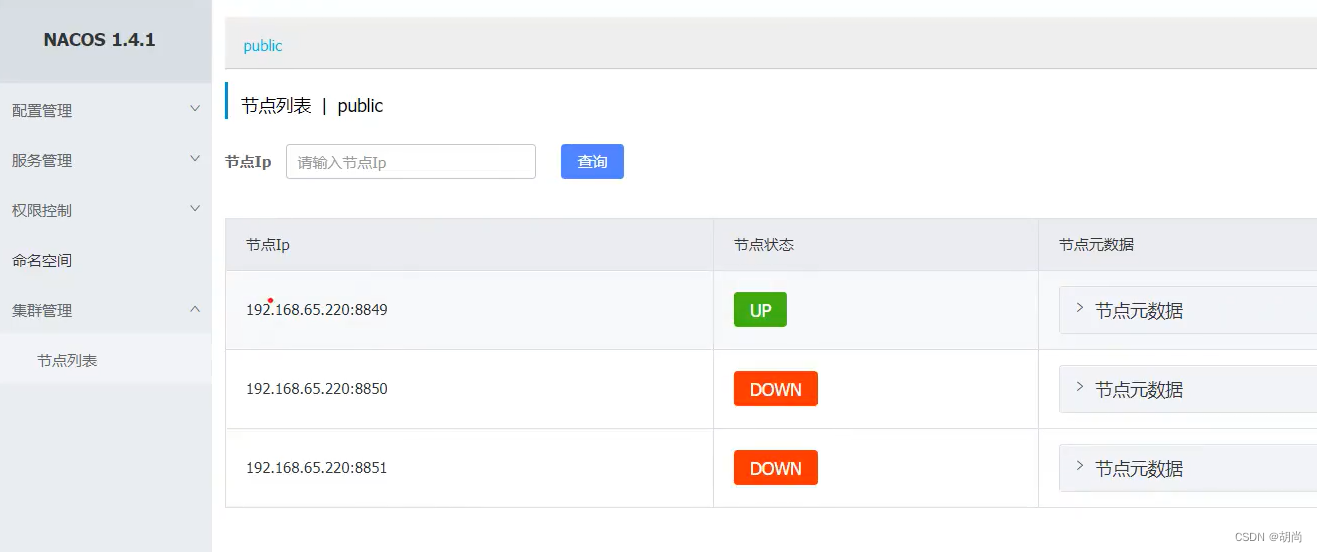
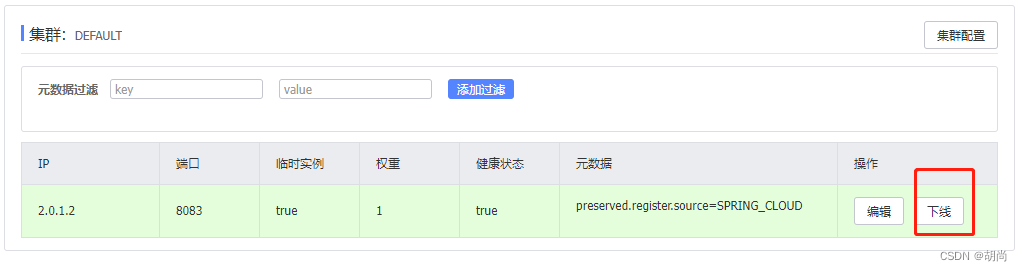
现在就可以在Nacos管理界面进行查看集群管理了,因为我现在只是启动了一台Nacos,所以其他两台是down
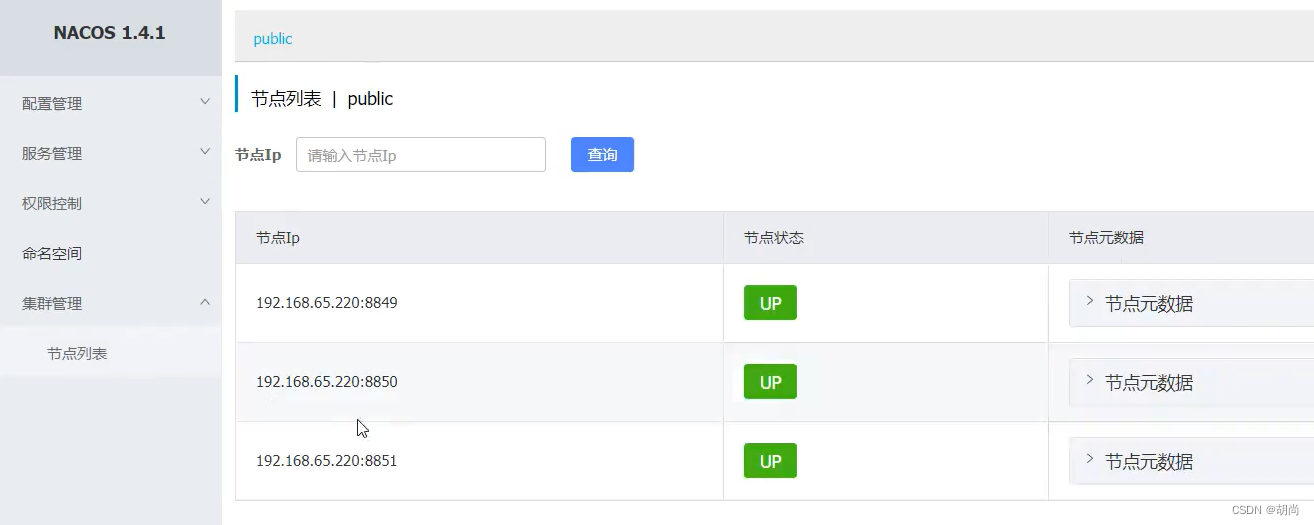
然后再将刚刚修改的三个地方在另外两个nacos目录中也进行相应的修改。并启动这三个nacos。现在随便访问一个nacos的管理界面都可以看到
启动完成之后有一个问题,我们的服务应该如何写,Nacos Client到底写这三个Nacos服务中的哪一个嘞?
其实我们写任何一个都不行,因为这样就又像是单机了,其实我还需要安装一个nginx,用nginx来进行负载均衡,我们使用nginx代理的一个地址。
在nginx的配置文件nginx.conf进行如下的修改
# 定义一个upstream,然后定义别名,再定义要进行负载均衡的ip
upstream nacoscluster {
server 127.0.0.1:8849;
server 127.0.0.1:8850;
server 127.0.0.1:8851;
}
server {
listen 8847;
server_name localhost;
# 这里判断的uri是因为nacos服务启动的conf/application.peoperties配置文件中指定的一个默认访问前缀,如下图所示
location /nacos/ {
proxy_pass http://nacoscluster/nacos/;
}
}
然后在nacos client中的配置文件写nginx的代理地址
server:
port: 8084
spring:
application:
name: stock-service
cloud:
nacos:
# 指定Nacos服务的地址
server-addr: 114.132.75.63:8847
discovery:
username: nacos
password: nacos
namespace: public
nacos是支持多数据中心的,我们是多集群,我们可以如下所示的参数来进行设置,如果是单集群就没必要设置了

这里的集群对应的是服务实例详情页面中最下方的集群。
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。
(1)为什么写这个话题(Why)读万卷书不如行千里路。这次搭建MQTT服务,遇到了一些误解,特此记录备忘。主要包括:(1)服务(Broker)的账户管理与网页管理平台的账户(2)与web应用的集成(Spring系)(2)ActiveMQ版本选择因为JAVA环境是JDK8,所以按兼容性考虑选择了ActiveMQ5.15的最后版本5.15.15。如果你是JDK11则可考虑ActiveMQ的最新版本5.17或5.18。ActiveMQ支持MQTTv3.1.1andv3.1。(3)ActiveMQ与web应用的集成主要介绍与Spring系的webapp集成(SpringBoot和SpringMVC)。
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我目前正在尝试搭建一个学习Ruby的开发环境。环境主要是为了掌握这门语言,但我很可能会在很长一段时间后转向使用Rails进行开发。以Web开发为目标,我想了解首选的Web服务器和数据库。我打算在虚拟机上设置环境,所以我不担心把它弄坏。因此,我愿意使用Linux发行版、OSX或Windows作为操作系统。我正从C#转向,所以我想在一定程度上被迫采用Ruby的
以太坊概论考察课更具课堂教学讲解,参考开放资料。使用所学的知识,创建项目并完成要求的内容。包含的功能和要求具体如下:一:安装并运行geth客户端1、下载安装geth首先下载geth:https://geth.ethereum.org/downloads/选择路径↓2、配置环境变量3、运行geth如下命令所示:查看geth命令。使用gethversion查看geth版本号,判断geth是否成功安装。如下命令所示:`gethversion`可以通过geth--help查看geth工具所支持的命令和相关参数,方便后期关于geth的操作。如下命令所示:geth--help运行结果如下:二:搭建get
目录一、下载Elasticsearch1.选择你要下载的Elasticsearch版本二、采用通用搭建集群的方法三、配置三台es1.上传压缩包到任意一台虚拟机中2.解压并修改配置文件(配置单台es)3.配置三台es集群4.设置后台启动和开机自启(可选)一、下载Elasticsearch1.选择你要下载的Elasticsearch版本es下载地址这里我下载的是二、采用通用搭建集群的方法集群搭建方法三、配置三台es1.上传压缩包到任意一台虚拟机中上传方式有两种第一种:使用xftp上传直接拖动过去就可以了。第二种:使用lrzsz先安装yum-yinstalllrzsz切换到要上传的位置cd/opt/