博学之,审问之,慎思之,明辨之,笃行之🏂
hive on spark搭建好后,任务提交会有问题,因为通过hive会话提交的任务一直存在且不会结束(除非关掉这个hive会话),根本原因是这些任务提交到了Yarn的同一个队列中,前面的任务没有执行完毕后面的任务不会执行,所以解决办法是增加一个Yarn队列,指定任务提交的队列,这样就不会出现任务的阻塞。
1. 情景复现:
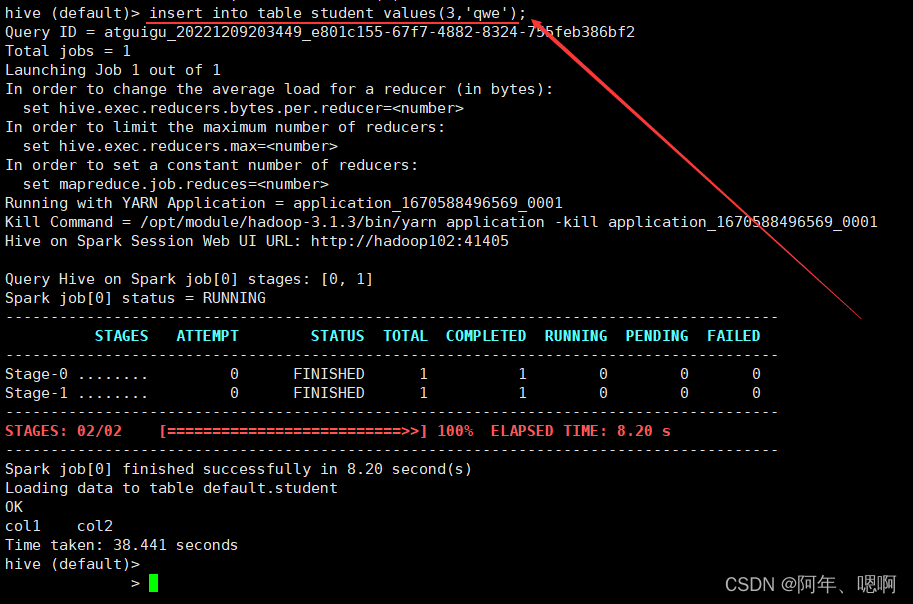
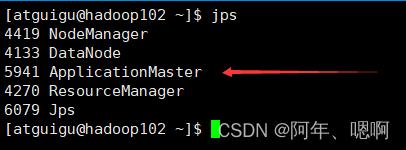
搭建好hive on spark 后,在命令行直接进入hive会话,提交任务后,在ResourceManager上jps查看进程可以看到有个进程ApplicationMaster一直存在,打开ResourceManager的8088端口可以看到刚才提交的任务一直在default队列中而且状态是RUNNING运行状态,尽管刚才的SQL已经跑完了,但是任务还是处于运行状态,这是因为hive的会话一直开着,而且只要这个会话不关闭,他这个任务就不会结束。

查看任务:
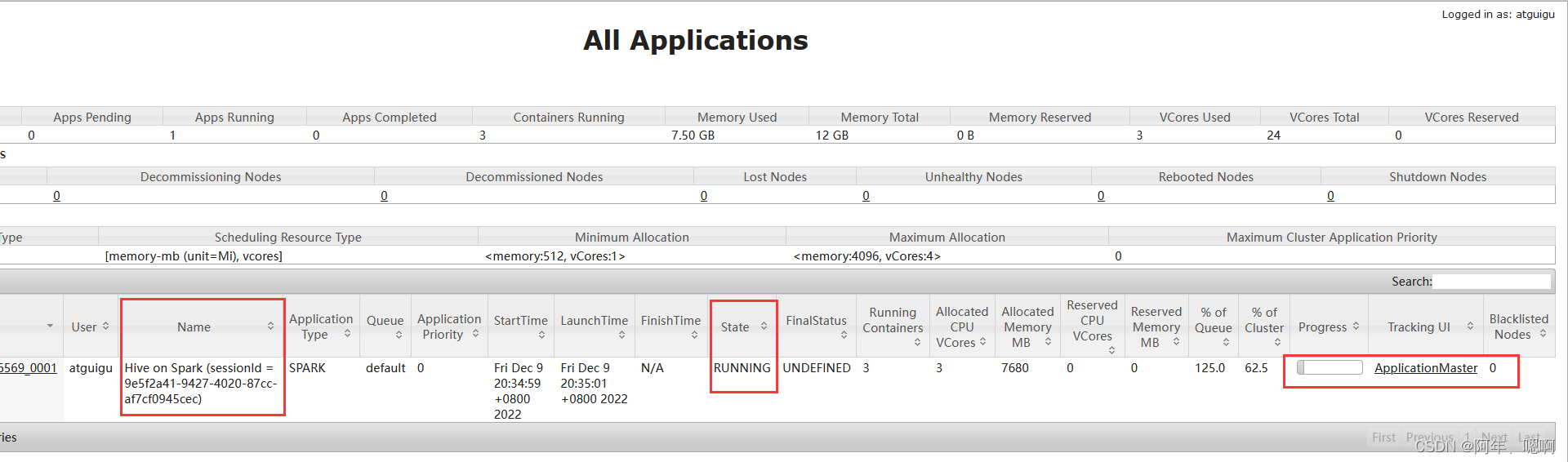
我们再尝试着向Yarn提交一个任务,发现他一直卡在Runing job那里不动
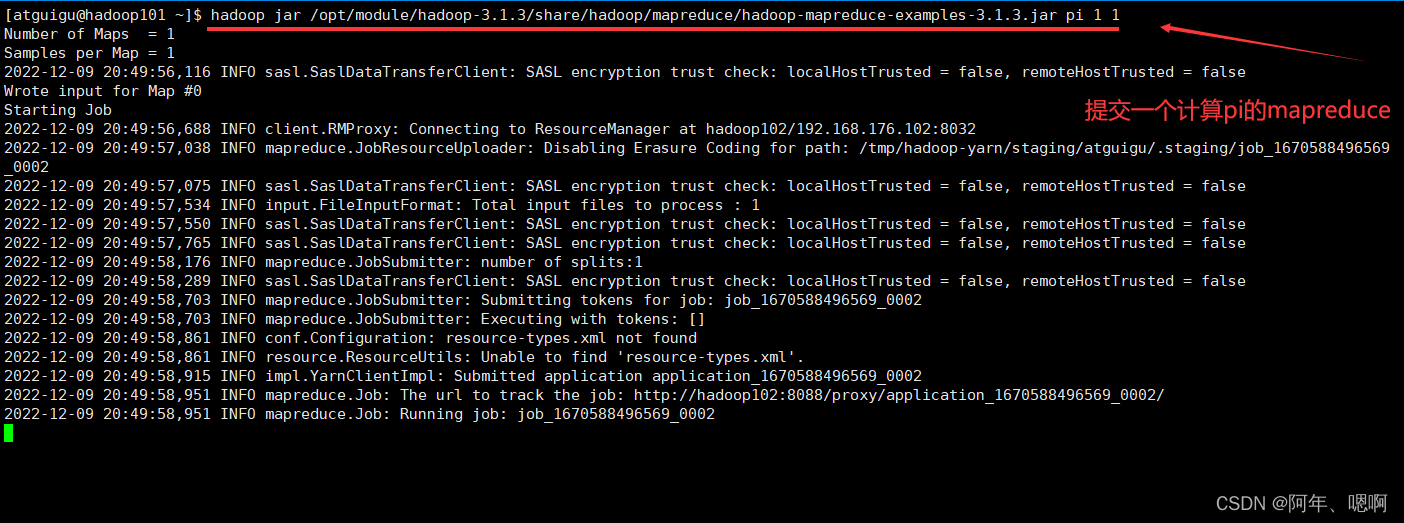
再次查看web页面,发现任务已经提交上来
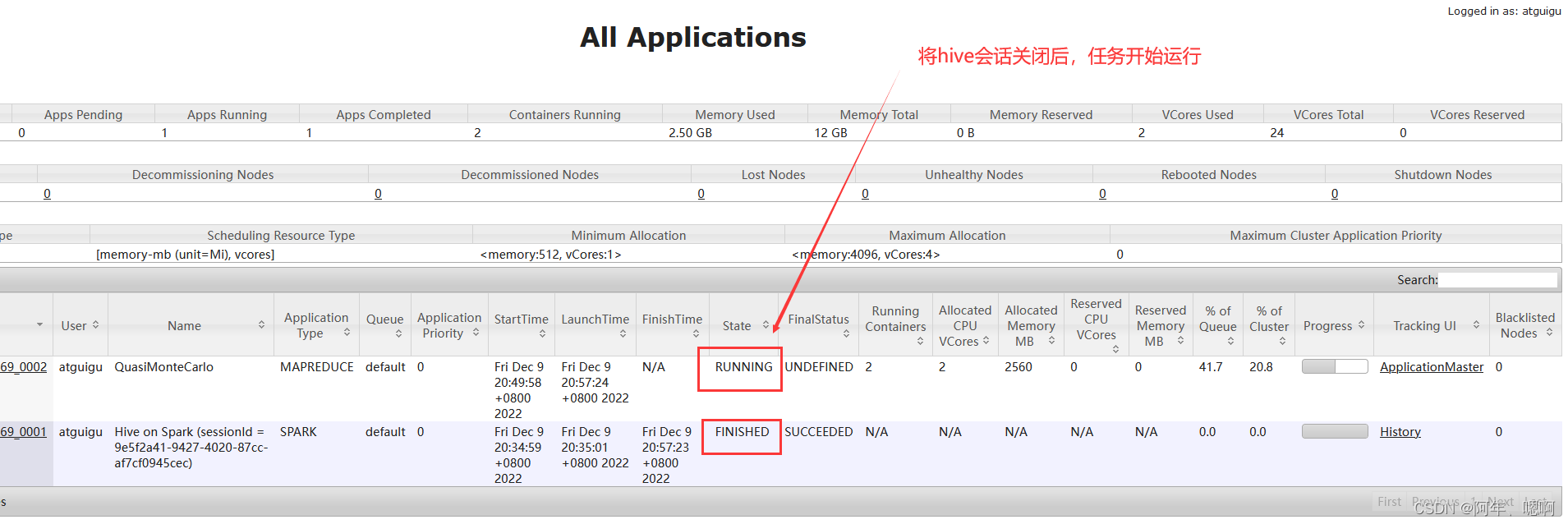
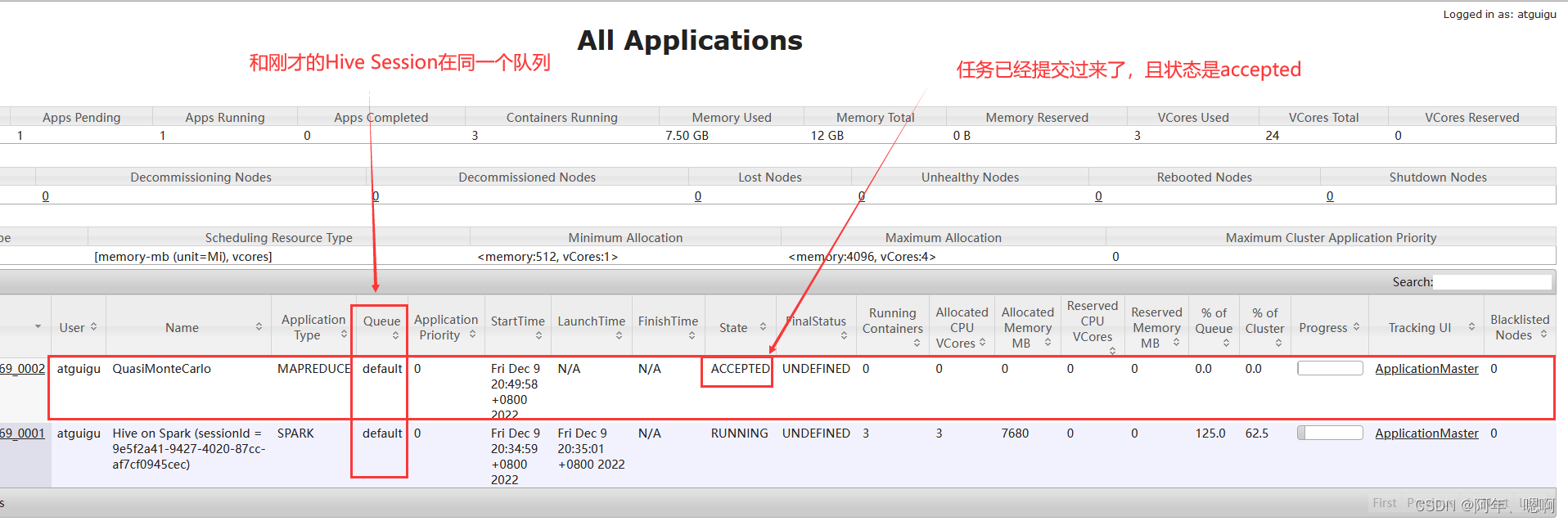 退出hive会话,再次查看,发现任务开始运行…
退出hive会话,再次查看,发现任务开始运行…
2. 原因:
梳理:原因是同一个队列中它前面的任务没有执行完,还没有轮到它执行。
分析:因为Yarn调度器默认是容量调度器,容量调度器中的多个队列可以并发执行,但是刚才的两个任务他们都提交到了同一个队列(default)中,而同一个队列中,又遵循先进先出(FIFO调度器)的原则,当前面的任务还没有执行完毕时,后面的任务不会执行,所以就出现了上面的现象。
优化:增加一个队列,将任务提交到不同的队列中。
3. Yarn队列配置—增加队列
增加一个名字叫hive的队列
修改hadoop配置文件目录下的capacity-scheduler.xml配置文件
1.修改如下配置。增加hive队列,将默认队列的的资源容量设置为50%
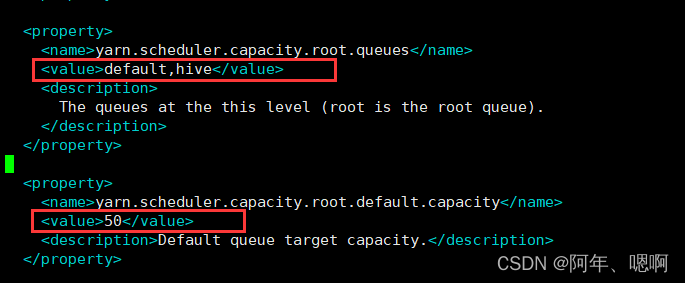
2.增加如下配置
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>50</value>
<description>
hive队列的容量为50%
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
<description>
一个用户最多能够获取该队列资源容量的比例
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
<description>
hive队列的最大容量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
<description>
访问控制,控制谁可以将任务提交到该队列
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
<description>
访问控制,控制谁可以管理(包括提交和取消)该队列的任务
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
<description>
访问控制,控制用户可以提交到该队列的任务的最大优先级
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
<description>
hive队列中任务的最大生命时长,-1表示时间无限长
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
<description>
default队列中任务的最大生命时长
</description>
</property>
3.将配置文件分发给各个机器
4.重启Hadoop集群
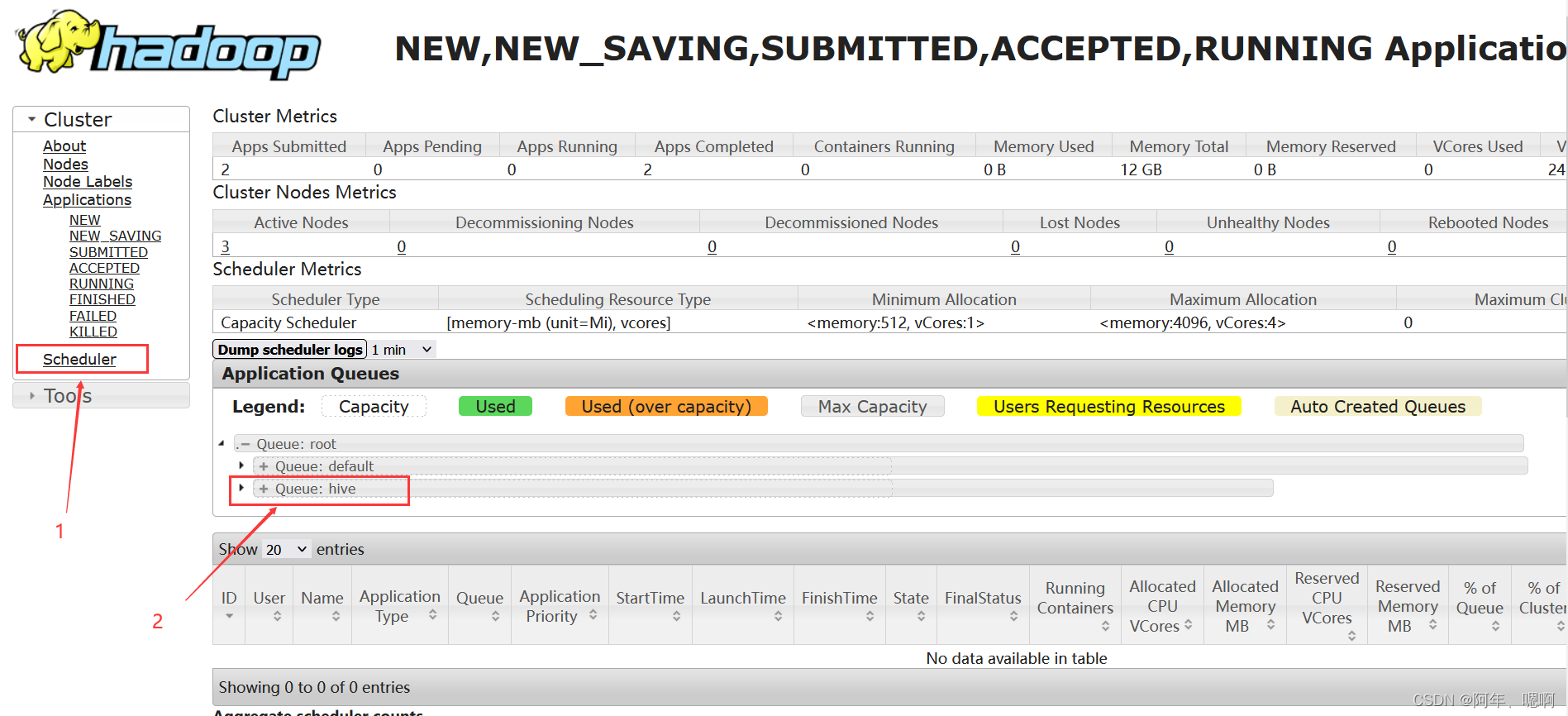
5.访问ResourceManager的8088端口,查看队列是否添加成功。
可以看到hive队列已经添加成功。
6.要向此队列提交任务的话,可以在hive客户端执行以下命令:
hive (default)> set mapreduce.job.queuename=hive;
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我以前没有使用过cron,所以我不能确定我这样做是对的。我想要自动化的任务似乎没有运行。我在终端中执行了这些步骤:sudogeminstall每当切换到应用程序目录无论何时。(这创建了文件schedule.rb)我将此代码添加到schedule.rb:every10.minutesdorunner"User.vote",environment=>"development"endevery:hourdorunner"Digest.rss",:environment=>"development"end我将此代码添加到deploy.rb:after"deploy:symlink","depl
如何在Rake任务中运行Capybara功能?例如:访问('http://google.com')谢谢! 最佳答案 在任务中尝试这样的事情:require'capybara'require'capybara/dsl'Capybara.current_driver=:seleniumBrowser=Class.new{includeCapybara::DSL}page=Browser.new.pagepage.visit("http://www.google.com")puts(page.html)