 关于数字化转型的两点思考:
关于数字化转型的两点思考: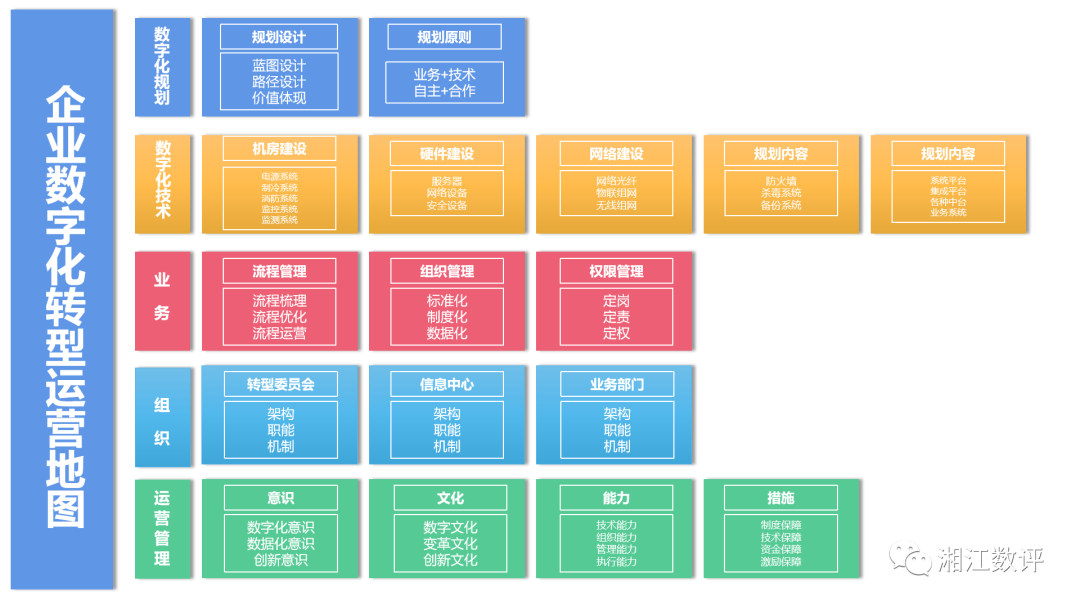 企业数字化转型是一项复杂的系统工程,表面上看涉及技术,其实在技术的背后是管理的博弈,涉及企业的规划能力、业务能力、组织能力、运营管理能力,今天老杨根据多年经验设计了这套企业数字化转型运营地图,从规划到落地层面进行详解,让各位对数字化转型建设思路更清晰、明确。
企业数字化转型是一项复杂的系统工程,表面上看涉及技术,其实在技术的背后是管理的博弈,涉及企业的规划能力、业务能力、组织能力、运营管理能力,今天老杨根据多年经验设计了这套企业数字化转型运营地图,从规划到落地层面进行详解,让各位对数字化转型建设思路更清晰、明确。当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Rubysyntaxquestion:Rational(a,b)andRational.new!(a,b)我正在阅读ruby镐书,我对创建有理数的语法感到困惑。Rational(3,4)*Rational(1,2)产生=>3/8为什么Rational不需要new方法(我还注意到例如我可以在没有new方法的情况下创建字符串)?
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我花了几天时间尝试安装ruby1.9.2并让它与gems一起工作:-/我最终放弃了我的MacOSX10.6机器,下面是我的Ubuntu机器上的当前状态。任何建议将不胜感激!#rubytest.rb:29:in`require':nosuchfiletoload--mongo(LoadError)from:29:in`require'fromtest.rb:1:in`'#cattest.rbrequire'mongo'db=Mongo::Connection.new.db("mydb")#gemwhichmongo/usr/local/rvm/gems/ruby-1.9.2-p0/g
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c