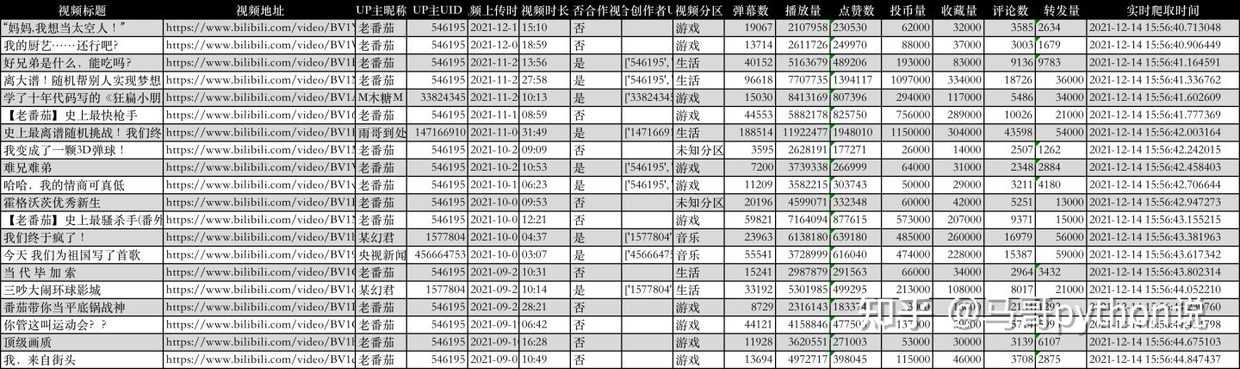
前几天开发了一个python爬虫脚本,成功爬取了B站李子柒的视频数据,共142个视频,17个字段,含:
视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕数,播放量,点赞数,投币量,收藏量,评论数,转发量,实时爬取时间
基于这个Python爬虫程序,我更换了up主的UID,把李子柒的uid换成了老番茄的uid,便成功爬取了老番茄的B站数据。共393个视频,17个字段,字段同上。
这里展示下爬取到的前20个视频数据:
基于爬取的老番茄B站数据,用python做了以下基础数据分析的开发。
import pandas as pd
df = pd.read_excel('B站视频数据_老番茄.xlsx', parse_dates=['视频上传时间', '实时爬取时间']) # 读取excel数据
df.head(3) # 查看前三行数据
df.shape # 查看形状,几行几列
df.info() # 查看列信息
df.describe() # 数据分析
df['是否合作视频'].value_counts() # 统计:是否合作视频
df['视频分区'].value_counts() # 统计:视频分区
df2 = df[['视频标题', '视频地址', '弹幕数', '播放量',
'点赞数', '投币量', '收藏量', '评论数', '转发量', '视频上传时间']] # 去掉不关心的列
df2.loc[df.评论数 == 0] # 评论数是0的数据
df2.isnull().any() # 空值
df2.duplicated().any() # 重复值
df2.loc[df.播放量 == df['播放量'].max()] # 播放量最高的视频
df2.loc[df.弹幕数 == df['弹幕数'].max()] # 弹幕数最高的视频
df2.loc[df.投币量 == df['投币量'].min()] # 投币量最小的视频
df2.loc[df.收藏量 == df['收藏量'].min()] # 收藏量最小的视频
df2.nlargest(n=3, columns='播放量') # 播放量TOP3的视频
df2.nlargest(n=3, columns='投币量') # 投币量TOP3的视频
df2.nsmallest(n=3, columns='评论数') # 评论数倒数3的视频
df2.nsmallest(n=3, columns='转发量') # 转发量倒数3的视频
# 查看spearman相关性(得出结论:收藏量&投币量,相关性最大,0.98)
df2.corr(method='spearman')

import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 可视化效果不好
df2.plot(x='视频上传时间', y=['弹幕数', '播放量', '点赞数', '投币量', '收藏量', '评论数', '转发量'])
from pyecharts.charts import Line # 折线图所导入的包
from pyecharts import options as opts # 全局设置所导入的包
time_list = df2['视频上传时间'].astype(str).values.tolist()
line = (
Line() # 实例化Line
# 加入X轴数据
.add_xaxis(time_list)
# 加入Y轴数据
.add_yaxis("弹幕数", df2['弹幕数'].values.tolist())
.add_yaxis("播放量", df2['播放量'].values.tolist())
.add_yaxis("点赞数", df2['点赞数'].values.tolist())
.add_yaxis("投币量", df2['投币量'].values.tolist())
.add_yaxis("收藏量", df2['收藏量'].values.tolist())
.add_yaxis("评论数", df2['评论数'].values.tolist())
.add_yaxis("转发量", df2['转发量'].values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="老番茄B站数据分析"),
legend_opts=opts.LegendOpts(is_show=True),
)
# 全局设置项
)

至此,基础数据分析工作完成了。
逐行代码视频讲解:
https://www.zhihu.com/zvideo/1455460990275567616
附完整源码:点击这里完整源码
更多案例源码 -> 马哥python说
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur