概述
随着人工智能技术的不断发展,越来越多的ai产品被应用到各个领域,其中最具代表性的莫过于人工智能语言模型。语言模型是一种可以通过学习大量语言数据来预测文本或语音的技术,其应用范围十分广泛,如智能客服、机器翻译、语音助手等。
而chatgpt是其中最为优秀的语言模型之一。chatgpt是openai公司开发的一款基于自然语言处理技术的对话生成模型,其采用了gpt架构(generative pre-trained transformer),能够自动学习自然语言数据的特征,并生成高质量的语言文本。在近几年的发展中,chatgpt已经成为了ai时代的语言沟通利器,它的应用范围不断扩大,其产生的影响也日益显现。本篇博客,笔者将为大家来介绍一下chatgpt的api使用。
说的话
本篇主要是来讲一讲如何简单调用chatgpt,跟在国内不用科学的方法。众所周知直到目前chatgpt的api接口在国内部分运营商已经墙了。
那么无非就是那几种方法,一、通过海外服务器把程序架设在海外,二、通过数据流量代理的方法。目前用的最多的就是这两个,这两个方法各有各的缺点。
本次代给大家的是通过cloudflare里面的workers功能来实现在国内调用api接口的方法。
cloudflare实现教程
第一步:首先你需要有cloudflare的账号你可以到cloudflare官网注册账号Cloudflare | Web Performance & Security![]() https://dash.cloudflare.com/login
https://dash.cloudflare.com/login
第二步:需要把你的域名迁移到cloudflare上面具体迁移方法就不多讲了可以自己去网上找找。
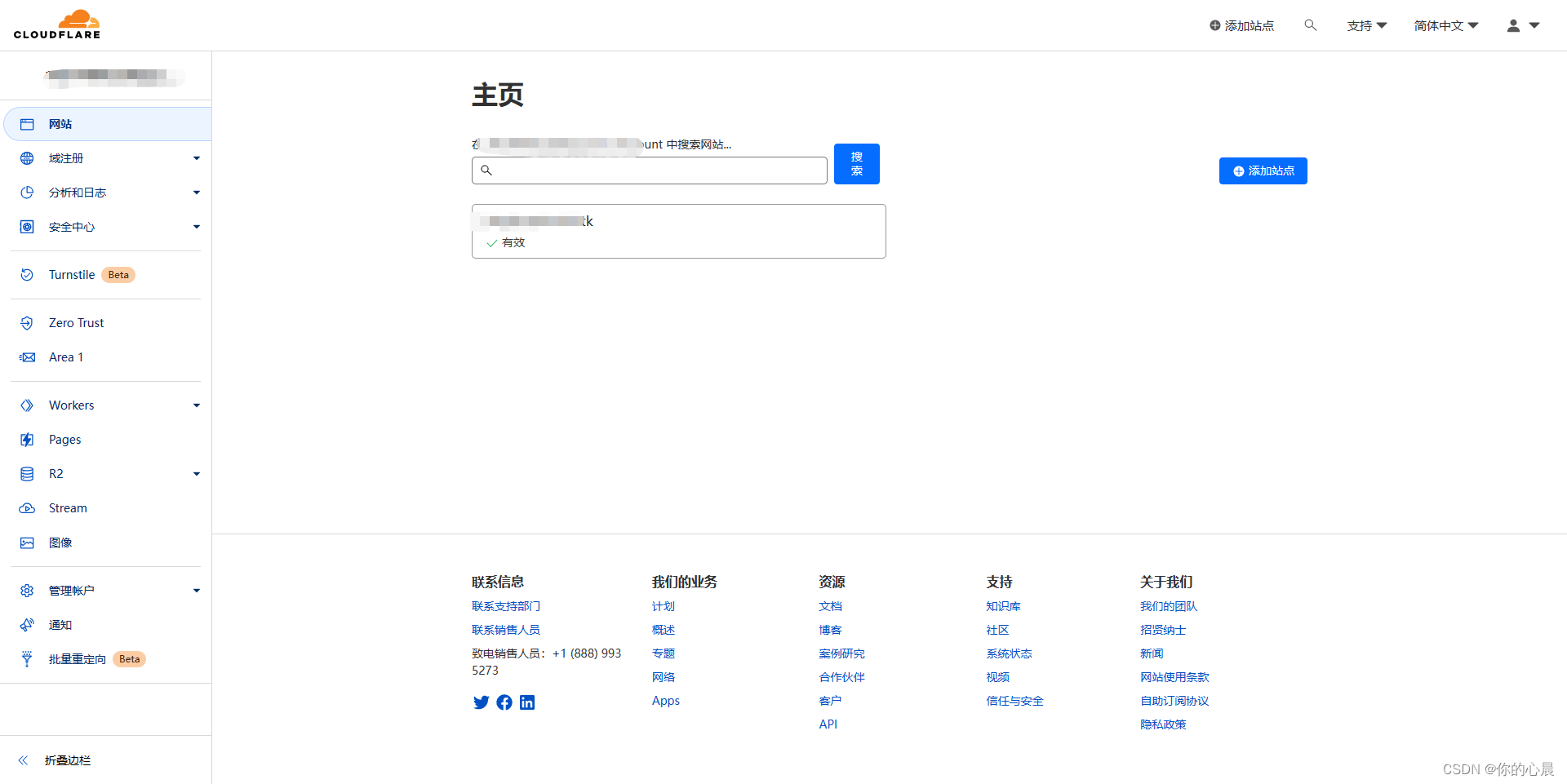
第三步:打开workers页面并创建一个新的服务,输入服务名称,启动器选择http处理程序
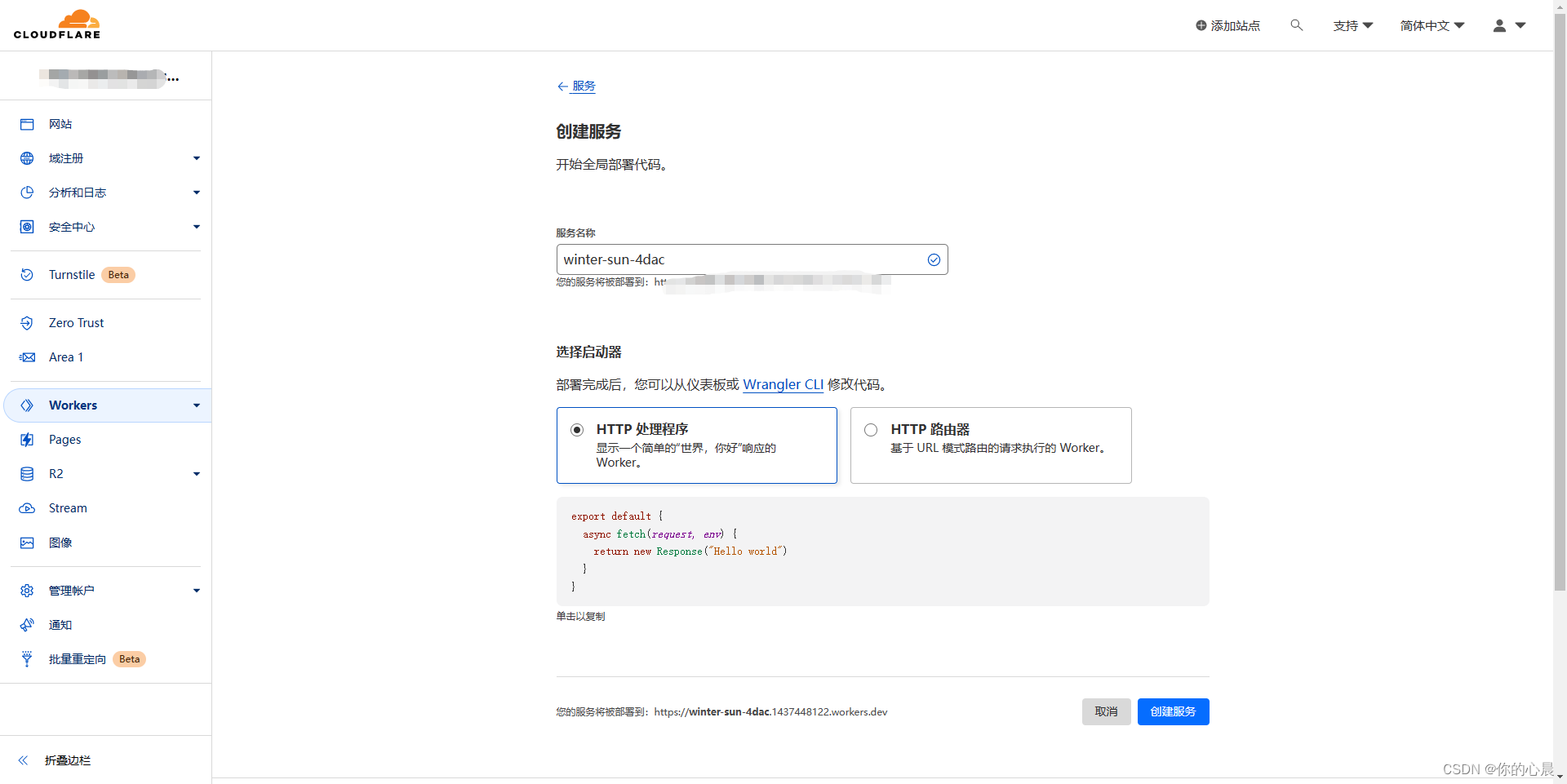
第四步:他给你分配的域名在国内一般是访问不了的所以需要你自定义一个新的域名,绑定好了之后点击快速编辑
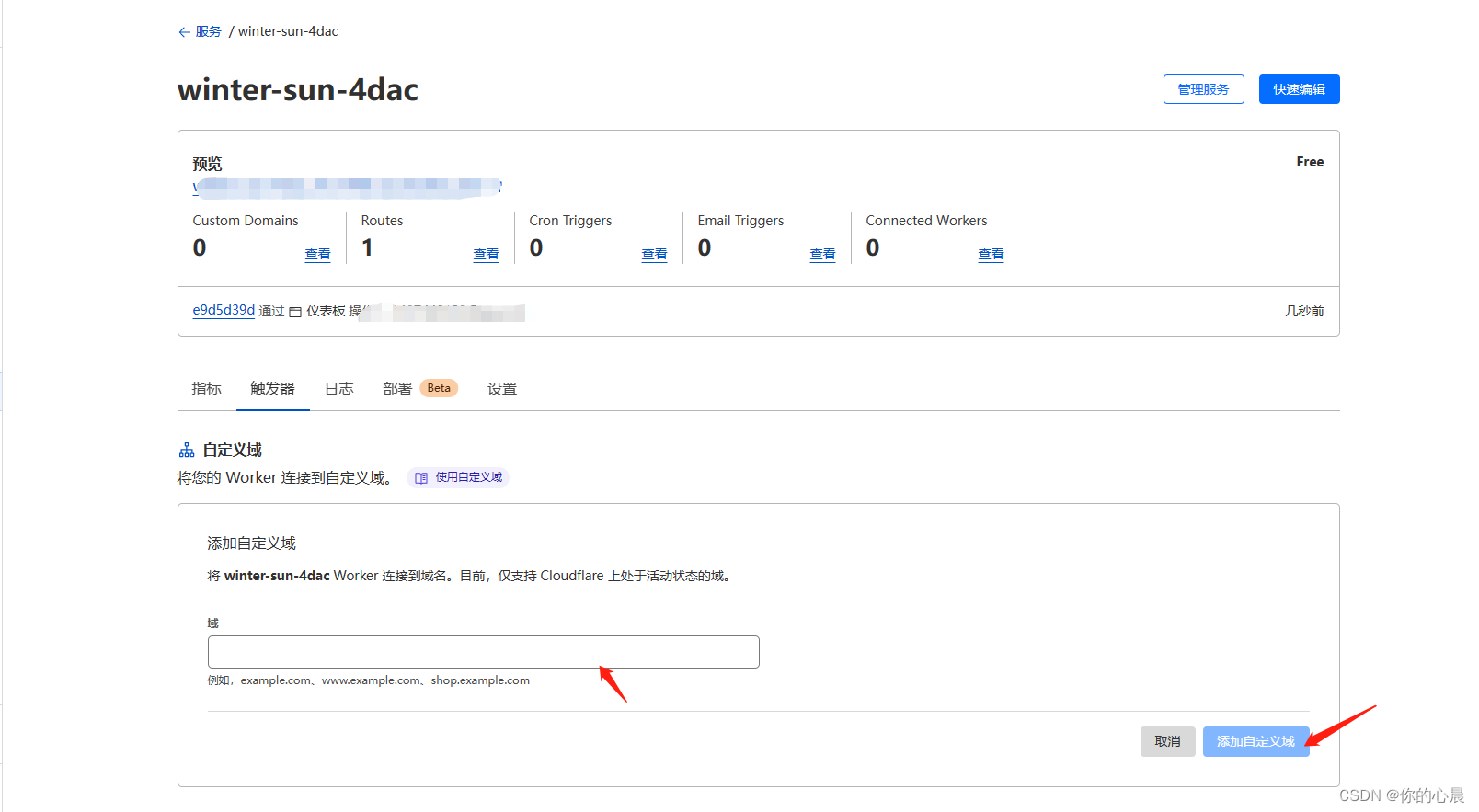
第五步:清空默认的程序代码填写入以下内容
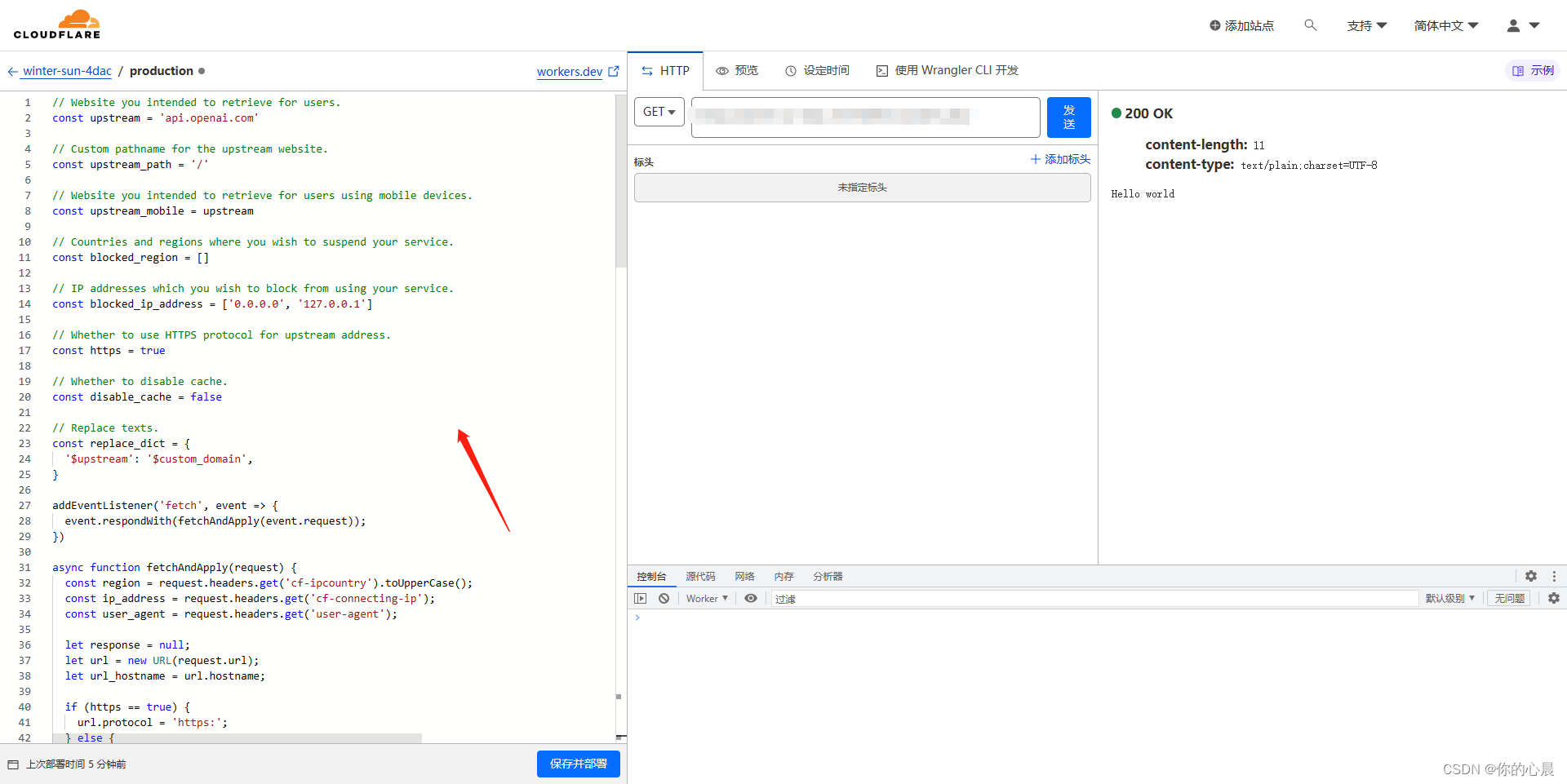
// Website you intended to retrieve for users.
const upstream = 'api.openai.com'
// Custom pathname for the upstream website.
const upstream_path = '/'
// Website you intended to retrieve for users using mobile devices.
const upstream_mobile = upstream
// Countries and regions where you wish to suspend your service.
const blocked_region = []
// IP addresses which you wish to block from using your service.
const blocked_ip_address = ['0.0.0.0', '127.0.0.1']
// Whether to use HTTPS protocol for upstream address.
const https = true
// Whether to disable cache.
const disable_cache = false
// Replace texts.
const replace_dict = {
'$upstream': '$custom_domain',
}
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request));
})
async function fetchAndApply(request) {
const region = request.headers.get('cf-ipcountry').toUpperCase();
const ip_address = request.headers.get('cf-connecting-ip');
const user_agent = request.headers.get('user-agent');
let response = null;
let url = new URL(request.url);
let url_hostname = url.hostname;
if (https == true) {
url.protocol = 'https:';
} else {
url.protocol = 'http:';
}
if (await device_status(user_agent)) {
var upstream_domain = upstream;
} else {
var upstream_domain = upstream_mobile;
}
url.host = upstream_domain;
if (url.pathname == '/') {
url.pathname = upstream_path;
} else {
url.pathname = upstream_path + url.pathname;
}
if (blocked_region.includes(region)) {
response = new Response('Access denied: WorkersProxy is not available in your region yet.', {
status: 403
});
} else if (blocked_ip_address.includes(ip_address)) {
response = new Response('Access denied: Your IP address is blocked by WorkersProxy.', {
status: 403
});
} else {
let method = request.method;
let request_headers = request.headers;
let new_request_headers = new Headers(request_headers);
new_request_headers.set('Host', upstream_domain);
new_request_headers.set('Referer', url.protocol + '//' + url_hostname);
let original_response = await fetch(url.href, {
method: method,
headers: new_request_headers,
body: request.body
})
connection_upgrade = new_request_headers.get("Upgrade");
if (connection_upgrade && connection_upgrade.toLowerCase() == "websocket") {
return original_response;
}
let original_response_clone = original_response.clone();
let original_text = null;
let response_headers = original_response.headers;
let new_response_headers = new Headers(response_headers);
let status = original_response.status;
if (disable_cache) {
new_response_headers.set('Cache-Control', 'no-store');
}
new_response_headers.set('access-control-allow-origin', '*');
new_response_headers.set('access-control-allow-credentials', true);
new_response_headers.delete('content-security-policy');
new_response_headers.delete('content-security-policy-report-only');
new_response_headers.delete('clear-site-data');
if (new_response_headers.get("x-pjax-url")) {
new_response_headers.set("x-pjax-url", response_headers.get("x-pjax-url").replace("//" + upstream_domain, "//" + url_hostname));
}
const content_type = new_response_headers.get('content-type');
if (content_type != null && content_type.includes('text/html') && content_type.includes('UTF-8')) {
original_text = await replace_response_text(original_response_clone, upstream_domain, url_hostname);
} else {
original_text = original_response_clone.body
}
response = new Response(original_text, {
status,
headers: new_response_headers
})
}
return response;
}
async function replace_response_text(response, upstream_domain, host_name) {
let text = await response.text()
var i, j;
for (i in replace_dict) {
j = replace_dict[i]
if (i == '$upstream') {
i = upstream_domain
} else if (i == '$custom_domain') {
i = host_name
}
if (j == '$upstream') {
j = upstream_domain
} else if (j == '$custom_domain') {
j = host_name
}
let re = new RegExp(i, 'g')
text = text.replace(re, j);
}
return text;
}
async function device_status(user_agent_info) {
var agents = ["Android", "iPhone", "SymbianOS", "Windows Phone", "iPad", "iPod"];
var flag = true;
for (var v = 0; v < agents.length; v++) {
if (user_agent_info.indexOf(agents[v]) > 0) {
flag = false;
break;
}
}
return flag;
}总结
最后把请求的openai的接口地址替换成你的域名就大功告成了
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t