
Java知识点--IO流(下)

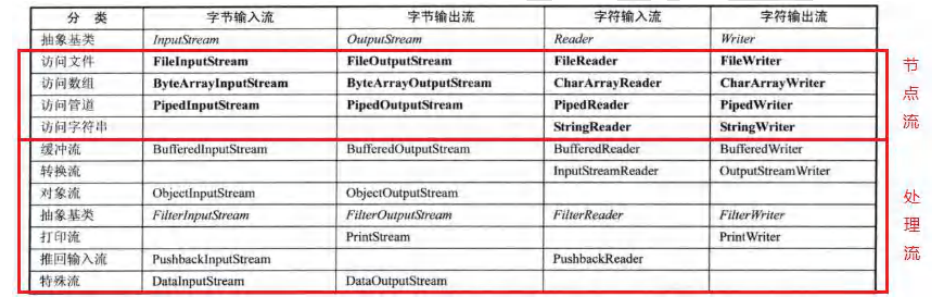
节点流:只能从特定的数据源读写数据,例如:访问文件用FileReader,访问数组用CharArrayReader,访问管道用PipedReader,访问字符串用StringReader。
处理流:也叫包装流,为程序提供更为强大的读写功能,也更加灵活,如BufferedReader,BufferedWriter,将节点流封装起来,可以访问文件,数组,管道,字符串等。
1.节点流是底层流/低级流,直接跟数据源相接。
2.处理流(包装流)包装节点流,既可以消除不同节点流的实现差异,也可以提供更方便的方法来完成输入输出。
3.处理流(也叫包装流)对节点流进行包装,使用了修饰器设计模式,不会直接与数据源相连。
1.性能的提高:主要以增加缓冲的方式来提高输入输出的效率。
2.操作的便捷:处理流可能提供了一系列便捷的方法来一次输入输出大批量的数据,使用更加灵活方便。
BufferedReader 和 BufferedWriter属于字符流,是按照字符来读写数据的,关闭处理流时,只需关闭外层流即可。
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class Exercise08 {
public static void main(String[] args) throws IOException {
//1.确定文件路径
String filePath = "e:\\story1.txt";
//2.引入BufferedReader
BufferedReader bufferedReader = new BufferedReader(new FileReader(filePath));
//3.定义读取行数
String readLen = null;
//4.按行读取,当返回 null 时,表示文件读取完毕
while ((readLen = bufferedReader.readLine()) != null){
System.out.println(readLen);
}
//5.关闭外层流,只需要关闭 BufferedReader,因为底层会自动的去关闭节点流
bufferedReader.close();
}
}
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Exercise09 {
public static void main(String[] args) throws IOException {
//1.确定文件路径
String filePath = "e:\\a9.txt";
//2.引入BufferedWriter
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(filePath));
//3. 写入"hello"
bufferedWriter.write("hello");
//4.关闭外层流
bufferedWriter.close();
}
}
import java.io.*;
public class Exercise10 {
public static void main(String[] args) throws IOException {
//1. BufferedReader 和 BufferedWriter 是按照字符操作
//2. 不要去操作 二进制文件[声音,视频,doc, pdf], 可能造成文件损坏
String filePath = "e:\\a9.txt";
String newFilePath = "e:\\a10.txt";
BufferedReader bufferedReader = new BufferedReader(new FileReader(filePath));
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(newFilePath));
String s;
//说明: readLine 读取一行内容,但是没有换行
while ((s = bufferedReader.readLine()) != null){
//每读取一行,就写入
bufferedWriter.write(s);
//插入一个换行
bufferedWriter.newLine();
}
//关闭流
bufferedReader.close();
bufferedWriter.close();
}
}
BufferedInputStream 和 BufferedOutputStream属于字节流,是按照字节来读写数据的,关闭处理流时,只需关闭外层流即可。
import java.io.*;
//字节流可以操作二进制文件,也可以操作文本文件
public class Exercise11 {
public static void main(String[] args) throws IOException {
String filePath = "e:\\3.jpg";
String newFilePath = "e:\\4.jpg";
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(filePath));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(newFilePath));
byte[] arr = new byte[1024];
int readLen = 0;
//当返回 -1 时,就表示文件读取完毕
while ((readLen = bufferedInputStream.read(arr)) != -1) {
bufferedOutputStream.write(arr,0,readLen);
}
//关闭流 , 关闭外层的处理流即可,底层会去关闭节点流
bufferedInputStream.close();
bufferedOutputStream.close();
}
}
1.将int num=100这个 int数据保存到文件中,注意不是 100 数字,而是 int 100,并且,能够从文件中直接恢复 int 100
2. 将 Dog dog = new Dog(“小黄”,3)这个 dog对象 保存到 文件中,并且能够从文件恢复.
3.上面的要求,就是能够将 基本数据类型 或者 对象 进行 序列化 和 反序列化操作
1.序列化就是在保存数据时,保存数据的值和数据类型
2.反序列化就是在恢复数据时,恢复数据的值和数据类型
3.需要让某个对象支持序列化机制,则必须让其类是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一:
Serializable //这是一个标记接口,没有方法
Externalizable//该接口有方法需要实现,因此我们一般实现上面的 Serializable接口
功能:提供了对基本类型或对象类型的序列化和反序列化的方法
ObjectOutputStream 提供 序列化功能
ObjectInputStream 提供 反序列化功能
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Exercise12 {
public static void main(String[] args) throws IOException {
String filePath = "e:\\a12.txt";
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(filePath));
objectOutputStream.writeInt(100);
objectOutputStream.writeBoolean(true);
objectOutputStream.writeChar('a');
objectOutputStream.writeDouble(12.5);
objectOutputStream.writeUTF("hello");
objectOutputStream.writeObject(new Dog("tom", 3));
objectOutputStream.close();
}
}
public class Dog implements Serializable {
private String name;
private int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class Exercise13 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
String filePath = "e:\\a12.txt";
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(filePath));
System.out.println(objectInputStream.readInt());
System.out.println(objectInputStream.readBoolean());
System.out.println(objectInputStream.readChar());
System.out.println(objectInputStream.readDouble());
System.out.println(objectInputStream.readUTF());
System.out.println(objectInputStream.readObject());
objectInputStream.close();
}
}
1)读写顺序要一致
2)要求序列化或反序列化对象 ,需要 实现 Serializable
3)序列化的类中建议添加SerialVersionUID,为了提高版本的兼容性
4)序列化对象时,默认将里面所有属性都进行序列化,但除了static或transient修饰的成员
5)序列化对象时,要求里面属性的类型也需要实现序列化接口
6)序列化具备可继承性,也就是如果某类已经实现了序列化,则它的所有子类也已经默认实现了序列化
| \ | 类型 | 默认设备 |
|---|---|---|
| System.in 标准输入 | InputStream | 键盘 |
| System.out 标准输出 | PrintStream | 显示器 |
1、IDEA中默认以UTF-8编码续取文件。
2、如果文件是以gbk编码保存的,以UTF-8读取可能会出现乱码,因此需要转换流。
3、转换流可以将字节流转换成字符流。
4、在处理纯文本数据时,使用字符流效率更高,也可以解决中文问题,所以建议将字节流转换成字符流。
5、可以在使用时指定编码格式。
1. InputStreamReader:Reader的子类,可以将InputStream(字节流)包装成(转换)Reader(字符流)
2.OutputStreamWriter:Writer的子类,实现将OutputStream(字节流)包装成Writer(字符流)
import java.io.*;
public class Exercise14 {
public static void main(String[] args) throws IOException {
String filePath = "e:\\a10.txt";
//1. 把 FileInputStream 转成 InputStreamReader
//2. 指定编码 gbk
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream(filePath), "gbk");
//3. 把 InputStreamReader 传入 BufferedReader
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String s;
//4. 读取
while ((s = bufferedReader.readLine()) != null){
System.out.println(s);
}
//5. 关闭外层流
bufferedReader.close();
}
}
import java.io.*;
public class Exercise15 {
public static void main(String[] args) throws IOException {
String filePath = "e:\\a15.txt";
OutputStreamWriter gbk = new OutputStreamWriter(new FileOutputStream(filePath), "gbk");
gbk.write("hello,world");
gbk.close();
}
}
打印流只有输出流,PrintStream是字节流,PrintWriter是字符流。
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class PrintStream_ {
public static void main(String[] args) throws FileNotFoundException {
String filePath = "e:\\m1.txt";
PrintStream printStream = new PrintStream(new FileOutputStream(filePath));
printStream.println("hello");
printStream.close();
}
}
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
public class PrintWriter_ {
public static void main(String[] args) throws IOException {
String filePath = "e:\\t2.txt";
PrintWriter printWriter = new PrintWriter(new FileWriter(filePath));
printWriter.println("肌肤光滑");
printWriter.close();
}
}
1、XX·properties表示配置文件,可以存放用户名,密码等
2、如果用户名,密码写在源程序中,用户改密码就需要改源码,很不方便,因此需要配置文件我们可以通过程序读取和写入配置文件
3、在src目录下定义 mysql.properties 配置文件
ip=192.168.100.100
user=root
pwd=12345
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
public class Exercise16 {
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
properties.load(new FileReader("src\\mysql.properties"));
properties.list(System.out);
String user = properties.getProperty("user");
System.out.println(user);
}
}
import java.io.FileWriter;
import java.io.IOException;
import java.util.Properties;
public class Exercise17 {
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
properties.setProperty("name","tom");
properties.setProperty("sex","male");
properties.setProperty("age","30");
properties.store(new FileWriter("src\\1.properties"), null);
}
}
1.properties
sex=male
name=tom
age=30
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg