docker安装配置elasticsearch,kibana和IK分词器
elasticsearch安装教程大全
elasticsearch学习笔记(一)
elasticsearch学习笔记(二)
elasticsearch学习笔记(三)
可参考:Debian安装docker
Centos安装docker
(docker-compose可以直接互连)
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
Elasticsearch和kibana版本要一致
#版本要一致
docker pull elasticsearch:7.12.1
docker pull kibana:7.12.1
# 宿主机挂载目录
mkdir -p /docker/elasticsearch/data
mkdir -p /docker/elasticsearch/plugins
这里默认内存是1g,最好不要少于512m
#运行es7
docker run -d \
--name es7 \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/docker/elasticsearch/data \
-v es-plugins:/docker/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
检查是否成功 http://ip:9200/
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/docker/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/docker/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/docker/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net :加入一个名为es-net的网络中-p 9200:9200:端口映射配置kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
#运行kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es7:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
#检验
http://ip:5601/
左侧Devtools中可以快速编写DSL
--network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:

此时,在浏览器输入地址访问:http://ip:5601,即可看到结果
kibana中提供了一个DevTools界面:

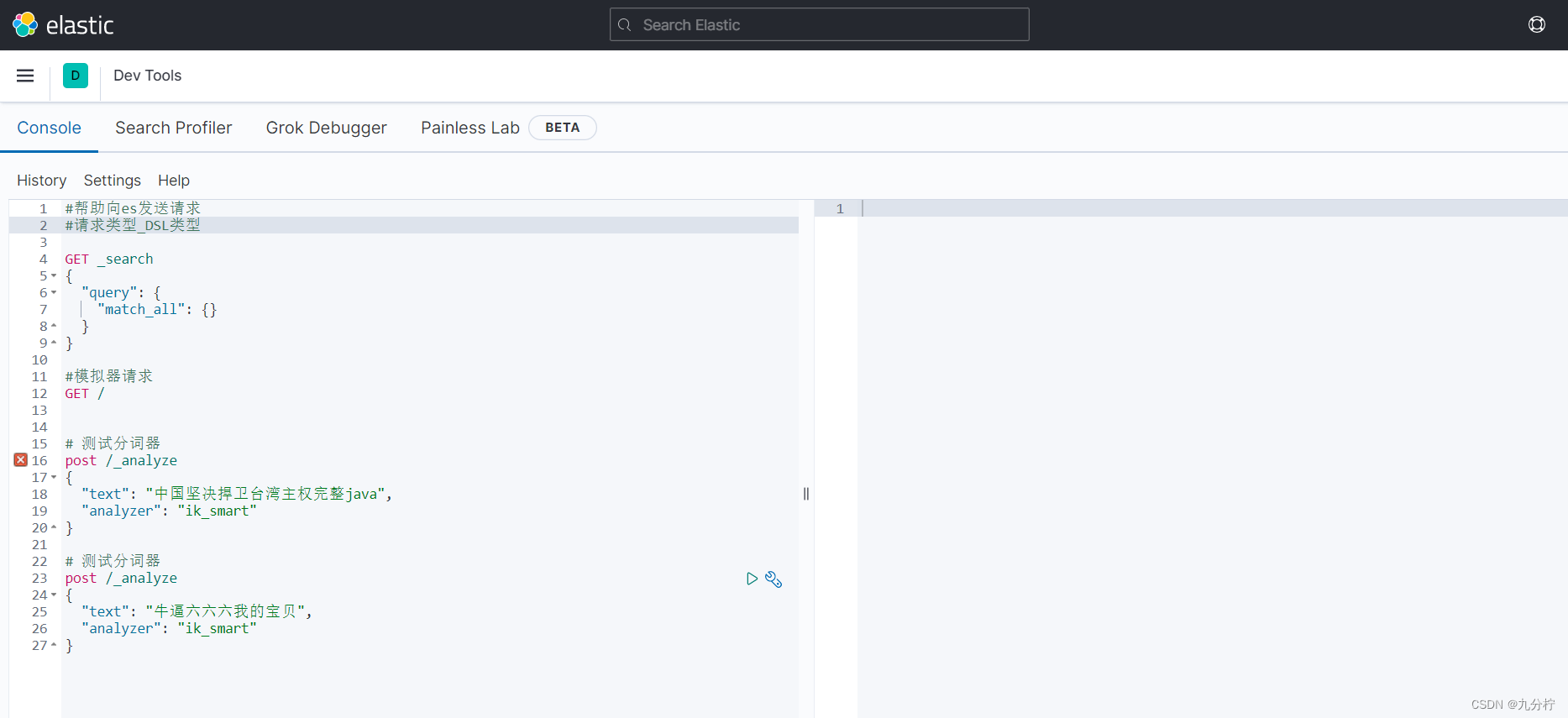
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
原有默认的分词器对中文分词并不友好
可以使用IK分词器
#### 安装IK分词器插件
# 进入容器内部
docker exec -it es7 /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
# 等待下载安装完成
#退出
exit
#重启容器
docker restart es7
IK分词器包含两种模式:
ik_smart:最少切分
ik_max_word:最细切分
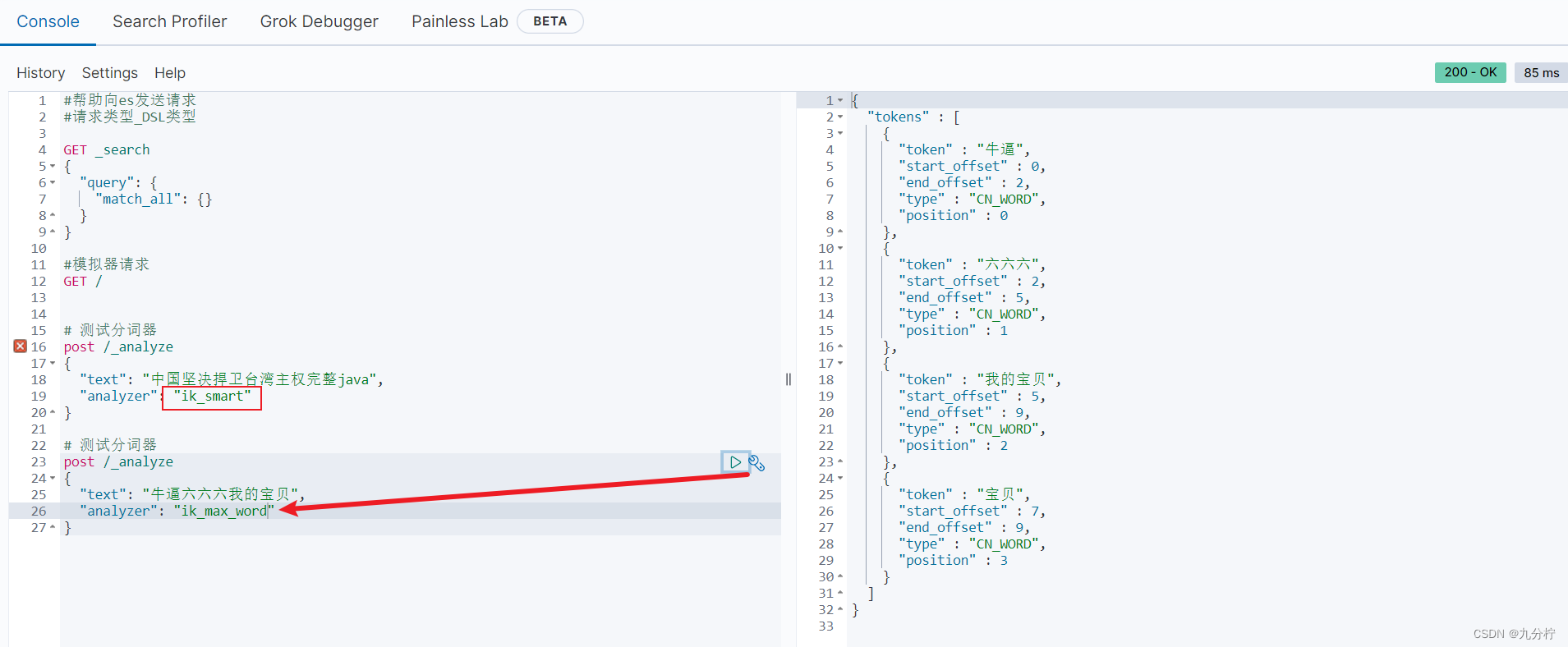
es使用通过词来分,但终究别人定义的词,我们可以自定义一些词典
# 可以进入修改字典
docker exec -it es7 /bin/bash
# 字典目录
cd /usr/share/elasticsearch/config/analysis-ik
# 修改配置文件
vi IKAnalyzer.cfg.xml
# :wq
# 退回到宿主机
exit
# 重启es和kibana
docker restart es7
docker restart kibana
IKAnalyzer.cfg.xml中可以配置
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://113.131.57.206:7090/remote.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
上面两个是本地的额外字典和额外禁止词位置,可以自己添加xml文件同目录的文件如,xxx.dic
下面两个是远程的
每次都要进入容器内部修改很麻烦, 而且vi编写也麻烦, 可以通过远程字典来热更新词典
先在宿主机的目录创建字典文件
## 宿主机的目录
cd /docker/elasticsearch/IK/
## 创建字典文件
touch remote.txt
创建完后, 可以通过MobaXterm等远程连接工具, 然后用VSCode打开编辑
remote.txt

安装nginx可以参考这里的unbuntu安装nginx部分(Debian也可以用)
通过apt-get安装的nginx的目录
#安装好的nginx相关文件位置:
/usr/sbin/nginx:主程序
/etc/nginx:存放配置文件
/usr/share/nginx:存放静态文件
/var/log/nginx:存放日志
修改nginx配置
cd /etc/nginx
# 修改conf.d目录下的,没有可以自己创建一个
# 主配置已经默认引入这目录下所有配置文件
cd /conf.d
# 创建
touch http.conf
http.conf加入以下内容:
# 根据约定,URL 尾部的 / 表示目录,没有 / 表示文件。所以访问 /some-dir/ 时,服务器会自动去该目录下找对应的默认文件。
# 如果访问 /some-dir 的话,服务器会先去找 some-dir 文件,找不到的话会将 some-dir 当成目录,重定向到 /some-dir/
# 每次更改后重启nginx
# cd /usr/sbin
# ./nginx -s reload
server {
listen 7090;
server_name localhost;
server_name 113.131.57.206; #你的ip
charset 'utf-8';
default_type 'text/html';
# 端口直接指向那个目录
location / {
root /docker/elasticsearch/IK;
}
}
修改后重启nginx
# 每次更改后重启nginx
cd /usr/sbin
./nginx -s reload
检验访问输入
http://113.131.57.206:7090/remote.txt
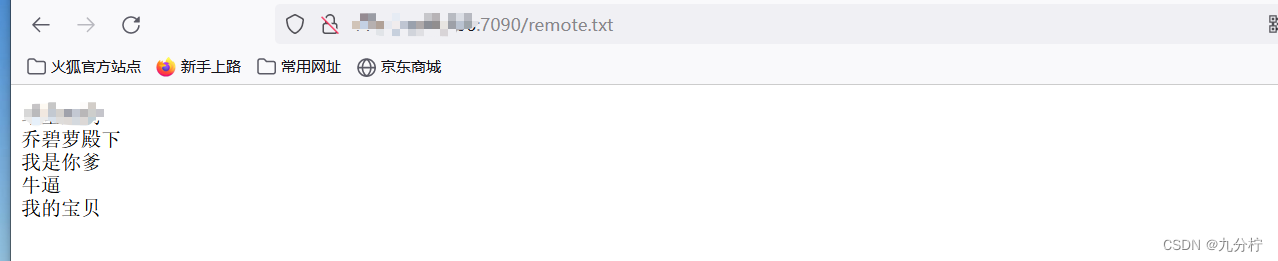
然后再去kibana的devtols就会按照我们自定义的词汇分词

#进入容器
docker exec -it es7 /bin/bash
#查看安装了哪些插件
./bin/elasticsearch-plugin list
#3、卸载x-pack插件
#a. 卸载x-pack插件
./bin/elasticsearch-plugin remove x-pack
#exit
#重启容器
#进入容器
docker exec -it es7 /bin/bash
#安装拼音分词器插件
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.12.1/elasticsearch-analysis-pinyin-7.12.1.zip
#exit
#重启容器
github地址:https://github.com/medcl/elasticsearch-analysis-pinyin
也可以先下载好https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.12.1/elasticsearch-analysis-pinyin-7.12.1.zip这个包,然后上传到对应的挂载目录,例如/var/lib/docker/volumes/es-plugins/_data
然后重启容器就可以。
可以通过docker inspect es7 查看挂载位置
例如
"Source": "/var/lib/docker/volumes/es-plugins/_data",
"Destination": "/docker/elasticsearch/plugins",
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
ES集群相关概念:
集群(cluster):一组拥有共同的 cluster name 的 节点。
节点(node) :集群中的一个 Elasticearch 实例
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
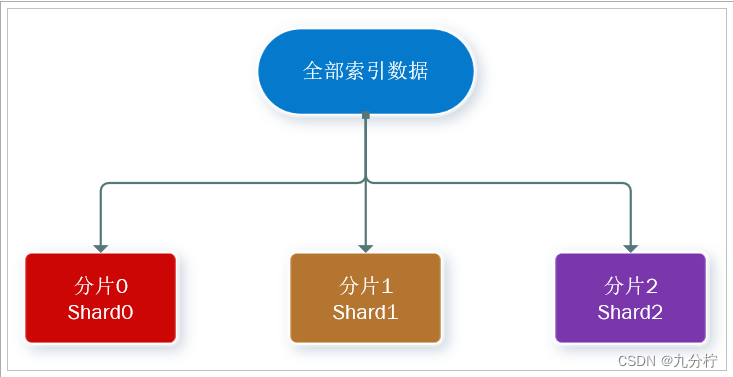
此处,我们把数据分成3片:shard0、shard1、shard2
主分片(Primary shard):相对于副本分片的定义。
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
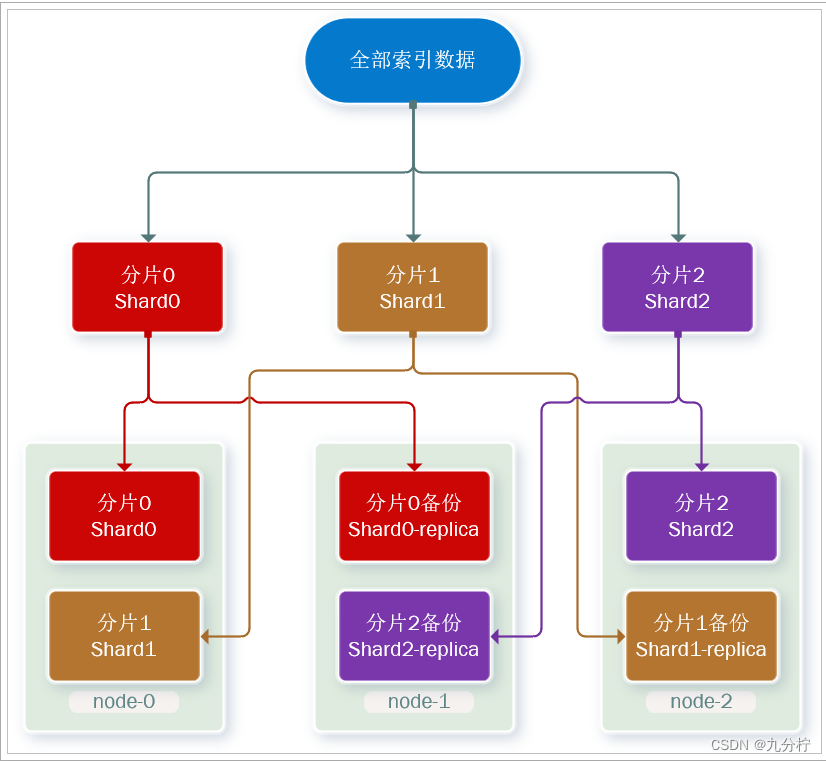
现在,每个分片都有1个备份,存储在3个节点:
我们会在单机上利用docker容器运行多个es实例来模拟es集群。不过生产环境推荐大家每一台服务节点仅部署一个es的实例。
部署es集群可以直接使用docker-compose来完成,但这要求你的Linux虚拟机至少有4G的内存空间
可以参考:docker-compose的安装
首先编写一个docker-compose.yml文件,内容如下:
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
es运行需要修改一些linux系统权限,修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
添加下面的内容:
vm.max_map_count=262144
#:wq
#保存
然后执行命令,让配置生效:
sysctl -p
通过docker-compose启动集群:
上传docker-compose.yml
# 去到docker-compose.yml所在的目录
docker-compose up -d
部署后,如果docker和docker-compose同时部署导致所有docker容器都访问不了,也可以看里面的解决方案docker-compose部署
kibana可以监控es集群,不过新版本需要依赖es的x-pack 功能,配置比较复杂。
这里推荐使用cerebro来监控es集群状态,官方网址:https://github.com/lmenezes/cerebro

解压后的目录如下

进入bin目录点击cerebro.bat即可启动

访问http://localhost:9000 即可进入管理界面:
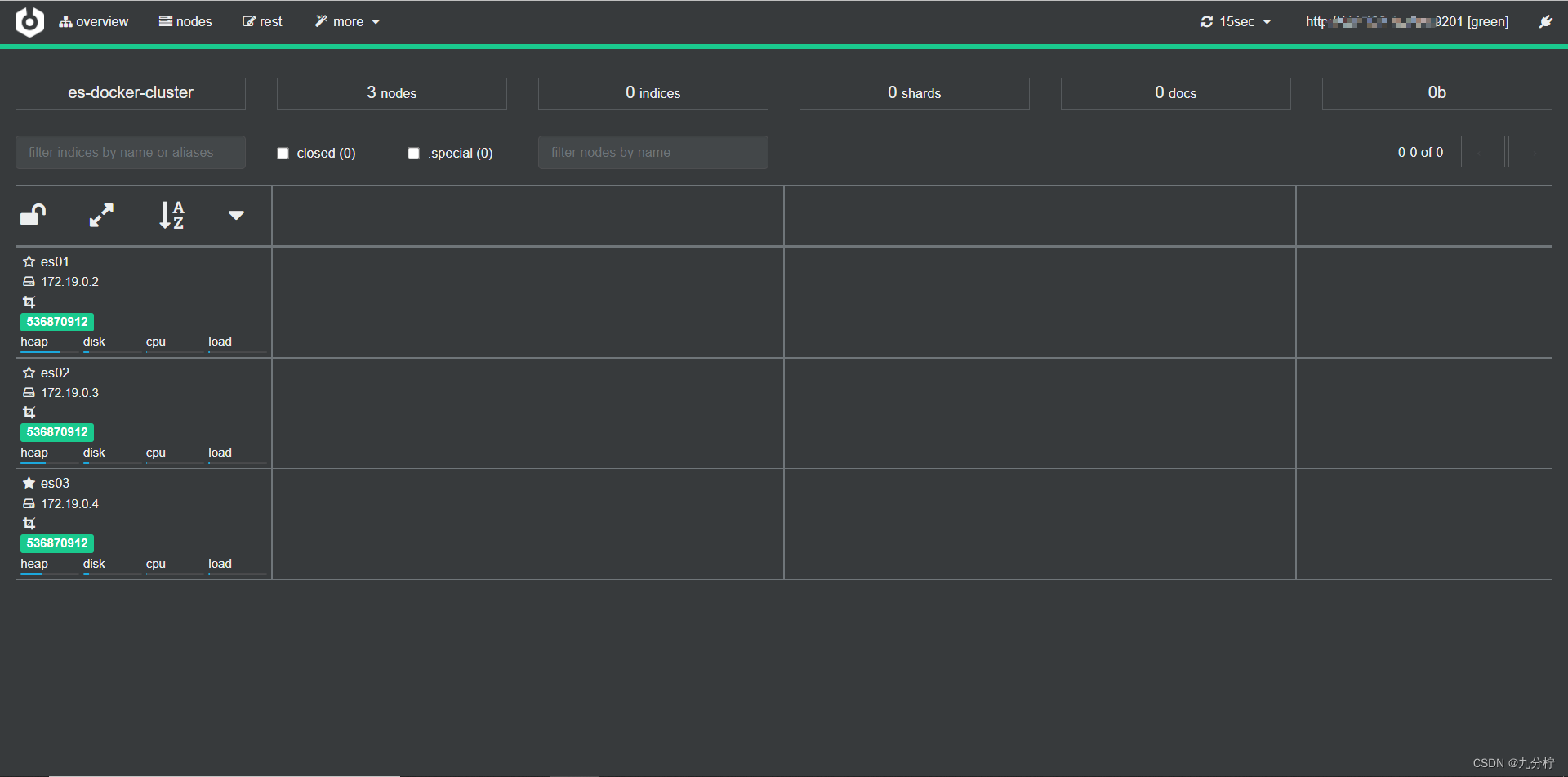
输入你的elasticsearch的任意节点的地址和端口,点击connect即可:
至此, 安装完成, 也是博主踩坑慢慢安装过来的, 有任何问题也可以留言与博主交流, 希望对你有帮助!
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=