在java中我们可以使用数组来保存多个对象,但是数组的长度不可变。如果需要保存数量变化的数据,数据就不太合适了。为了保存数量不确定的数据,以及保存具有映射关系的数据(也被称为关联数组),Java 提供了集合类。**集合类主要负责保存、盛装其他数据,因此集合类也被称为容器类**
java集合类型分为Collection和Map,它们是 Java 集合的根接口,这两个接口又包含了一些子接口或实现类.
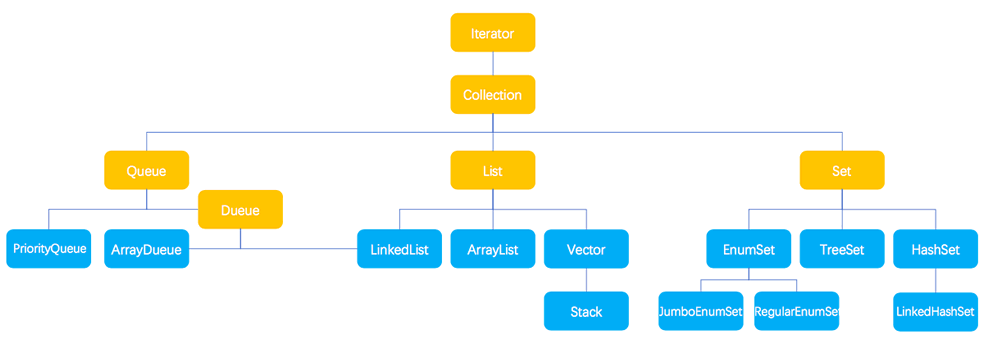
下图为collection接口基本结构
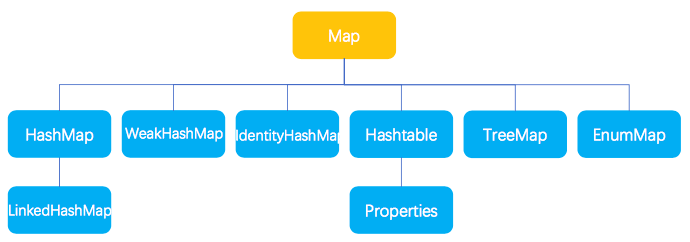
下图为Map接口基本结构
1.修改操作
| 方法名 | 作用 |
|---|---|
| add() | 添加单个数据,结果返回布尔值 |
| remove() | 删除单个数据,结果返回布尔值 |
2.查询操作
| 方法名 | 作用 |
|---|---|
| size() | 返回此集合中的元素数。 |
| isEmpty() | 如果集合中不包含元素,则返回 true 。 |
| contains() | 如果此集合包含指定的元素,则返回true。 |
| iterator() | 以正确的顺序返回该列表中的元素的迭代器。 |
| toArray() | 正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。 |
| toArray(T[]) | 正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。 否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。 |
3.批量操作
| 方法名 | 作用 |
|---|---|
| containsAll(Collection<?>) | 如果此集合包含指定 集合中的所有元素,则返回true。 |
| addALl(Collection<? extends E>) | 批量添加 |
| removeALL(Collection<?>) | 批量删除 |
| removeIF(Predicate<? super E>) | 条件删除 |
| retainAll(Collection<?>) | 保留删除 |
| clear() | 清空集合 |
| stream() | 返回一个顺序Stream与此集合作为其来源。 |
| parallelStream() | 返回可能并行的Stream与此集合作为其来源。 该方法允许返回顺序流。 |
定义一个Fruit类,一个Apple类,以及一个Banana类
public class Fruit {
private String name;
public Fruit(String name) {
this.name = name;
}
@Override
public String toString() {
return name;
}
}
public class Apple extends Fruit{
public Apple(String name) {
super(name);
}
}
public class Banana extends Fruit{
public Banana(String name) {
super(name);
}
}
然后在主方法中写一个集合,并向这个集合中国添加数据
public class Demo01 {
//首先看一下添加操作boolean add(),添加成功返回True,失败返回False
public static void main(String[] args) {
List<Fruit> fruits = new ArrayList<>();
System.out.println(fruits.add(new Apple("红富士苹果")));
System.out.println(fruits.add(new Apple("青苹果")));
System.out.println(fruits.add(new Fruit("蛇果")));
for (Fruit fruit : fruits) {
System.out.println(fruit);
}
}
}
输出:
true
true
true
红富士苹果
青苹果
蛇果
List
因为集合中定义的是Fruit,说明该集合只能存储Fruit对象或者Fruit的子类对象
再看一下addall()方法,添加成功返回true,否则返回false
首先定义两个集合,分别为苹果集合和香蕉集合,并向集合中添加数据
public class Demo01 {
//首先看一下添加操作boolean add(),添加成功返回True,失败返回False
public static void main(String[] args) {
List<Apple> apples = new ArrayList<>();
apples.add(new Apple("红富士"));
apples.add(new Apple("青苹果"));
apples.add(new Apple("蛇果"));
List<Banana> bananas = new ArrayList<>();
bananas.add(new Banana("帝皇蕉"));
apples.add(new Apple("海南香蕉"));
List<Fruit> fruits = new ArrayList<>();
System.out.println(fruits.addAll(apples));
System.out.println(fruits.addAll(bananas));
for (Fruit fruit : fruits) {
System.out.println(fruit);
}
}
}
remove()删除单个数据,删除批量数据removeAll,删除符合添加条件的数据,removeIF,删除所有数据clear,即清空数据!
首先先看单个删除操作如何操作的
public class Demo02 {
public static void main(String[] args) {
//定义一个数字集合
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
for (Integer number : numbers) {
System.out.print(number+" ");
}
System.out.println();
System.out.println("====分===割===线=====");
numbers.remove(2);
numbers.remove(3);
for (Integer number : numbers) {
System.out.print(number+" ");
}
}
}
输出:
1 2 3 4 5
====分===割===线=====
1 2 4
可以看到,删除我们打印输出的是1,2,4,可以看到他是先删除的下标为2的数字,然后,后面的数字往前进一个,集合中现在的长度为4,我们再取下标3的数,也就是最后一个数5,打印剩下的数就是1.2.4.
1.removeAll()方法
删除要删除数据中的集合,只要有符合的就执行删除操作
代码示例:
public class Demo03 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
List<Integer> num=new ArrayList<>();
num.add(2);
num.add(3);
num.add(5);
num.add(6);
numbers.removeAll(num);
for (Integer number : numbers) {
System.out.print(number+" ");
}
}
}
输出:
1 4
2.retainAll()方法,指定要保留的数据集合
public class Demo04 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
List<Integer> nums = new ArrayList<>();
nums.add(2);
nums.add(4);
nums.add(6);
numbers.retainAll(nums);
System.out.println(numbers);
}
}
输出:
[2, 4]
可以看到,我们把要保留的数放在第二个集合中,当在需要操作的集合中能找到相应的数据,就将其保留!
3.removeIf()方法
public class Demo05 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
//指定规则删除集合中的数据
//Predicate接口主要用来判断一个参数是否符合要求
boolean result=numbers.removeIf(new Predicate<Integer>() {
@Override
public boolean test(Integer integer) {
//删除所有偶数
return integer%2==0;
}
});
//看是否删除成功
System.out.println(result);
//遍历集合
for (Integer number : numbers) {
System.out.print(number+" ");
}
}
}
输出:
true
1 3 5
4.clear()方法,清空集合
public class Demo06 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
System.out.println(numbers);
numbers.clear();
System.out.println(numbers);
}
}
输出:
[1, 2, 3, 4, 5]
[]
一些常见的其他方法
public class Demo07 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
//集合的元素数
System.out.println(numbers.size());
//集合是否为空
System.out.println(numbers.isEmpty());
//集合中是否有元素2
System.out.println(numbers.contains(2));
}
}
输出:
5
false
true
更多方法,具体的可以查看一下jdk的帮助文档
ArrayLisy不但拥有Collection中的方法,还拥有List中的所有方法
特点:
优点:查询快
缺点:增删慢
1.ArrayList中的构造方法
ArrayList中有三种构造方法
public ArrayList() 构造一个初始容量为十的空列表。
public ArrayList(Collection<? extends E> c) 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
public ArrayList(int initialCapacity) 构造具有指定初始容量的空列表。
2.ArrayList中的常用方法
| 方法 | 作用 |
|---|---|
| add(E) | 添加元素 |
| set(int index,E element) | 覆盖指定位置的元素 |
| remove(int index) | 删除指定位置的元素 |
| get(int index) | 获取指定位置的元素 |
| indexOf(Object o) | 获取指定位置的索引 |
| iterator() | 获取迭代器 |
| size() | 获取集合大小 |
| isEmpty() | 判断集合是否为空 |
| clear() | 清空集合 |
| stream() | 为集合创建流 |
拥有Collection里面的所有方法,List中的所有方法,Queue中的所有方法,Deque中的所有方法
1.LinkedList中的构造方法
LinkedList() 构造一个空列表。
LinkedList(Collection<? extends E> c) 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
特点:
优点:增删块
缺点:查询慢
2.LinkedList的常用方法:
| 方法 | 作用 |
|---|---|
| getFirst | 返回此列表中的第一个元素。 |
| getLast | 返回此列表中的最后一个元素。 |
| removeFirst | 从此列表中删除并返回第一个元素。 |
| removeLast | 从此列表中删除并返回最后一个元素。 |
| add | 将指定的元素追加到此列表的末尾。 |
| addFirst | 在该列表开头插入指定的元素。 |
| size | 返回此列表中的元素数。 |
| clear | 从列表中删除所有元素。 此呼叫返回后,列表将为空。 |
| contains | 如果此列表包含指定的元素,则返回true` |
| listIterator | 从列表中的指定位置开始,返回此列表中元素的列表迭代器(按适当的顺序)。 |
| straem | 为集合创建流 |
| ArrayLIst | LinkedList | |
|---|---|---|
| 数据结构 | 数组 | 链表 |
| 查询速度 | 快 | 慢 |
| 增删速度 | 慢 | 快 |
| 内存空间 | 小 | 大 |
| 应用场景 | 查询较多 | 增删较多 |
特点:
1.无序
2.key可以为null,哈希值为0
3.key不可以重复,重复的key,新值会覆盖旧值
优点:增删改查快
缺点:无序
1.HashMap的构造方法:
| 方法 | 作用 |
|---|---|
| HashMap() | 构造一个空的 HashMap ,默认初始容量(16)和默认负载系数(0.75)。 |
| HashMap(int initialCapacity) | 构造一个空的 HashMap具有指定的初始容量和默认负载因子(0.75) |
| HashMap(int initialCapacity, float loadFactor) | 构造一个空的HashMap具有指定的初始容量和负载因子。 |
| HashMap(Map<? extends K,? extends V> m) | HashMap(int initialCapacity, float loadFactor)构造一个新的 HashMap与指定的相同的映射 Map` |
2.HashMap中常用的方法:
| 方法名 | 作用 |
|---|---|
| size | 返回此地图中键值映射的数量。 |
| isEmpty | 如果此地图不包含键值映射,则返回 true 。 |
| get | 返回到指定键所映射的值,或null如果此映射包含该键的映射。 |
| put | 将指定的值与此映射中的指定键相关联。 如果地图先前包含了该键的映射,则替换旧值。 |
| remove | 从该地图中删除指定键的映射(如果存在)。 |
| clear | 从这张地图中删除所有的映射。 此呼叫返回后,地图将为空。 |
| containsKey | 如果此映射包含指定键的映射,则返回 true 。 |
| keySet | 返回此地图中包含的键的Set视图。 该集合由地图支持,因此对地图的更改将反映在集合中,反之亦然。 如果在集合中的迭代正在进行中修改映射(除了通过迭代器自己的remov操作),迭代的结果是未定义的。 该组支持元件移除,即从映射中相应的映射,经由Iterator.remove,Set.remove,removeAll,retainAll和clear操作。 它不支持add或addAll操作。 |
其中put与get方法在hashmap中用的最为频繁,在实际开发中,hashmap多用于缓存数据
特点:
优点:有序
LInkedHashMap中常用的方法:
| 方法 | 作用 |
|---|---|
| put(K,V) | 添加元素 |
| get(Object) | 获取指定键的元素 |
| containsKey(Object) | 查询集合中是否包含指定键 |
| remove(Object) | 删除指定键的元素 |
| keyset() | 以set集合的形式返回所有值 |
| size() | 获取集合大小 |
| isEmpty() | 判断集合是否为空 |
| clear() | 清空集合 |
特点:
优点:对key有序
缺点:无序
keymap的常用方法:
| 方法 | 作用 |
|---|---|
| put(K,V) | 添加元素 |
| get(Object) | 获取指定键的元素 |
| containsKey(Object) | 查询集合中是否包含指定键 |
| remove(Object) | 删除指定键的元素 |
| keyset() | 以set集合的形式返回所有值 |
| size() | 获取集合大小 |
| isEmpty() | 判断集合是否为空 |
| clear() | 清空集合 |
| descendingMap | 倒序遍历 |
特点:
优点:增删改查快
缺点:无序
1.HashSet的构造方法:
| 构造方法 | 说明 |
|---|---|
| HashSet() | 构造一个新的空集合; 背景HashMap实例具有默认初始容量(16)和负载因子 |
| HashSet(Collection<? extends E> c) | 构造一个包含指定集合中的元素的新集合。 |
| HashSet(int initialCapacity) | 构造一个新的空集合; 背景HashMap实例具有指定的初始容量和默认负载因子(0.75) |
| HashSet(int initialCapacity, float loadFactor) | 构造一个新的空集合; 背景HashMap实例具有指定的初始容量和指定的负载因子。 |
2.HashSet的常用方法
| 方法 | 作用 |
|---|---|
| add | 添加元素 |
| containsKey(Object) | 查询集合中是否包含指定键 |
| remove(Object) | 删除指定键 |
| iteartor | 迭代器 |
| size() | 获取集合大小 |
| isEmpty() | 判断集合是否为空 |
| clear() | 清空集合 |
3.HashSet与HashMap的区别
| Hashmap | Hashset |
|---|---|
| key是key,value是value | 把key当成value使用,value再用统一的值填充 |
特点:
优点:有序,增删快
缺点:查询慢
1.LinkedHashSet的常用方法
| 方法 | 作用 |
|---|---|
| add | 添加元素 |
| containsKey(Object) | 查询集合中是否包含指定键 |
| remove(Object) | 删除指定键 |
| iteartor | 迭代器 |
| size() | 获取集合大小 |
| isEmpty() | 判断集合是否为空 |
| clear() | 清空集合 |
2.LinkedHahsSet与LinkedHashMap的区别
| LinkedHashSet | LinkedhashMap | |
|---|---|---|
| 存储方式 | key是key,value是value | 把key当成value使用,value再用统一的值填充 |
| 排序方式 | 添加顺序 访问顺序 | 添加顺序 |
特点:
优点:对值排序
缺点:无序
1.TreeSet的常用方法:
| 方法 | 作用 |
|---|---|
| add | 添加元素 |
| containsKey(Object) | 查询集合中是否包含指定键 |
| remove(Object) | 删除指定键 |
| iteartor | 迭代器 |
| size() | 获取集合大小 |
| isEmpty() | 判断集合是否为空 |
| clear() | 清空集合 |
| descendingIterator | 倒叙遍历 |
2.HashSet与TreeSet的对比
| HashSet | LInkEdHashSet | Treeset |
|---|---|---|
| 添加、查询快 | 添加、修改、删除快;有序 | 只有需要对元素进行排序时使用 |
一种容器保护机制,防止多个线程并发修改同一个容器的内容,如果发生了并发修改的情况就会触发快速失败机制,也就是抛出ConcurrentModificationException(并发修改异常)
eg:
当你在迭代遍历某个容器的过程中国,另一个线程介入其中,并且插入或删除此容器中的某个元素,那么就会出现问题,单线程和多线程同理!
我们看一下代码:
可以看出,我们在下面迭代遍历的同时,进行插入操作
import java.util.ArrayList;
import java.util.Iterator;
public class FailFast {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Iterator<String> iterator = list.iterator();
list.add("1");
list.add("2");
while (iterator.hasNext()){
System.out.println(iterator.next());}
}
}
输出:
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:911)
at java.util.ArrayList$Itr.next(ArrayList.java:861)
at com.gather.map.FailFast.main(FailFast.java:14)
那么为了防止这类问题出现,java容器类采用了快速失败机制,主要用与监视容器的变化
那么如何避免上述问题:我们只需要采用线程安全的容器即可
| 线程不安全 | 线程安全 |
|---|---|
| ArrayLIst | CopyOnWriteArrayList |
| LinkedList | |
| HashMap | ConcurrentHashMap |
| LinkedHashMap | |
| TreeMap | |
| HashSet | CopyOnWriteArraySet |
| LinkedHashSet | |
| TreeSet |
代码示例:
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;
public class FailFast2 {
public static void main(String[] args) {
//创建一个支持并发的集合
CopyOnWriteArrayList list=new CopyOnWriteArrayList();
//另一个线程修改器
new Thread(new Runnable() {
@Override
public void run() {
list.add("一个简单的多线程");
list.add("lingstar");
}
}).start();
//获取迭代器
Iterator<String> iterator = list.iterator();
//遍历集合
while (iterator.hasNext()){
//获取元素
System.out.println(iterator.next());
}
}
}
输出:
一个简单的多线程
lingstar
特点:
优点:增删改查快
缺点:无序
1.ConcurrentHashMap的常用方法
| 方法 | 作用 |
|---|---|
| put | 添加元素 |
| get(Object) | 获取指定键的元素 |
| containsKey(Object) | 查询集合中是否包含指定键 |
| remove(Object) | 删除指定键 |
| keySet() | 以set集合的形式返回所有键 |
| size() | 获取集合大小 |
| isEmpty() | 判断集合是否为空 |
| clear() | 清空集合 |
2.ConcurrentHashMap与HashMap的区别
| hashMap | ConcurrentHahsmap | |
|---|---|---|
| 线程是否安全 | 不安全 | 安全 |
| 扩容 | 单线程扩容 | 多线程协同扩容 |
| 统计元素个数 | size | baseCount+CounterCell() |
| key,value能否为null | 能 | 不能 |
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/