文章目录
左值是一个表示数据的表达式,比如:变量名、解引用的指针变量。一般地,我们可以获取它的地址和对它赋值,但被 const 修饰后的左值,不能给它赋值,但是仍然可以取它的地址。
总体而言,可以取地址的对象就是左值。
// 以下的a、p、*p、b都是左值
int a = 3;
int* p = &a;
*p;
const int b = 2;
右值也是一个表示数据的表达式,比如:字面常量、表达式返回值,传值返回函数的返回值(是传值返回,而非传引用返回),右值不能出现在赋值符号的左边且不能取地址。
总体而言,不可以取地址的对象就是右值。
double x = 1.3, y = 3.8;
// 以下几个都是常见的右值
10; // 字面常量
x + y; // 表达式返回值
fmin(x, y); // 传值返回函数的返回值
以下写法均不能通过编译:
10 = 4;、x + y = 4;、fmin(x, y) = 4;,VS2015 编译报错:error C2106: “=”: 左操作数必须为左值。原因:右值不能出现在赋值符号的左边。&10;、&(x + y);、&fmin(x, y);,VS2015 编译报错:error C2102: “&” 要求左值。原因:右值不能取地址。
区分左值和右值,终究还是要看能否取地址。
传统的 C++ 语法中就存在引用语法,而 C++11标准中新增了右值引用的语法特性,因此为了区分两者,将C++11标准出现之前的引用称为左值引用。
无论左值引用还是右值引用,都是给对象取别名。
左值引用就是对左值的引用,给左值取别名。
// 以下几个是对上面左值的左值引用
int& ra = a;
int*& rp = p;
int& r = *p;
const int& rb = b;
右值引用就是对右值的引用,给右值取别名。
右值引用的表示是在具体的变量类型名称后加两个 &,比如:
int&& rr = 4;。
// 以下几个是对上面右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
注意:
右值引用引用右值,会使右值被存储到特定的位置。
也就是说,右值引用变量其实是左值,可以对它取地址和赋值(const右值引用变量可以取地址但不可以赋值,因为 const 在起作用)。
当然,取地址是指取变量空间的地址(右值是不能取地址的)。比如:
double&& rr2 = x + y;
&rr2;
rr2 = 9.4;
右值引用 rr2 引用右值 x + y 后,该表达式的返回值被存储到特定的位置,不能取表达式返回值 x + y 的地址,但是可以取 rr2 的地址,也可以修改 rr2 。const double&& rr4 = x + y;
&rr4;
可以对 rr4 取地址,但不能修改 rr4,即写成rr4 = 5.3;会编译报错。
现在我们知道左值引用可以引用左值,右值引用可以引用右值。
那么左值引用是否可以引用右值?右值引用是否可以引用左值呢?
下面的对比与总结给出了答案。
左值引用总结:
const左值引用既可以引用左值,也可以引用右值。// 1.左值引用只能引用左值
int t = 8;
int& rt1 = t;
//int& rt2 = 8; // 编译报错,因为10是右值,不能直接引用右值
// 2.但是const左值引用既可以引用左值
const int& rt3 = t;
const int& rt4 = 8; // 也可以引用右值
const double& r1 = x + y;
const double& r2 = fmin(x, y);
问:为什么
const左值引用也可以引用右值?
答:在 C++11标准产生之前,是没有右值引用这个概念的,当时如果想要一个类型既能接收左值也能接收右值的话,需要用const左值引用,比如标准容器的 push_back 接口:void push_back (const T& val)。
也就是说,如果const左值引用不能引用右值的话,有些接口就不好支持了。
下面就是 C++98标准中相关接口const左值引用引用右值的例子:
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
右值引用总结:
move的左值。
move,本文指std::move(C++11),作用是将一个左值强制转化为右值,以实现移动语义。
左值被 move 后变为右值,于是右值引用可以引用。
// 1.右值引用只能引用右值
int&& rr1 = 10;
double&& rr2 = x + y;
const double&& rr3 = x + y;
int t = 10;
//int&& rrt = t; // 编译报错,不能直接引用左值
// 2.但是右值引用可以引用被move的左值
int&& rrt = std::move(t);
int*&& rr4 = std::move(p);
int&& rr5 = std::move(*p);
const int&& rr6 = std::move(b);
// 1.左值引用做参数
void func1(string s)
{...}
void func2(const string& s)
{...}
int main()
{
string s1("Hello World!");
func1(s1); // 由于是传值传参且做的是深拷贝,代价较大
func2(s1); // 左值引用做参数减少了拷贝,提高了效率
return 0;
}
// 2.左值引用做返回值(仅限于对象出了函数作用域以后还存在的情况)
string s2("hello");
// string operator+=(char ch) 传值返回存在拷贝且是深拷贝
// string& operator+=(char ch) 左值引用做返回值没有拷贝,提高了效率
s2 += '!';
传值传参和传值返回都会产生拷贝,有的甚至是深拷贝,代价很大。而左值引用的实际意义在于做参数和做返回值都可以减少拷贝,从而提高效率。
左值引用虽然较完美地解决了大部分问题,但对于有些问题仍然不能很好地解决。
当对象出了函数作用域以后仍然存在时,可以使用左值引用返回,这是没问题的。
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
但当对象(对象是函数内的局部对象)出了函数作用域以后不存在时,就不可以使用左值引用返回了。
string operator+(const string& s, char ch)
{
string ret(s);
ret.push_back(ch);
return ret;
}
// 拿现在这个函数来举例:ret是函数内的局部对象,出了函数作用域后会被析构,即被销毁了
// 若此时再返回它的别名(左值引用),也就是再拿这个对象来用,就会出问题
于是,对于第二种情形,左值引用也无能为力,只能传值返回。
于是,为了解决上述传值返回的拷贝问题,C++11标准就增加了右值引用和移动语义。
将一个对象中的资源移动到另一个对象(资源控制权的转移)。
转移参数右值的资源来构造自己。
// 这是一个模拟string类的实现的移动构造
string(string&& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
swap(s);
}
拷贝构造函数和移动构造函数都是构造函数的重载函数,所不同的是:
注:当传来的参数是右值时,虽然拷贝构造函数可以接收,但是编译器会认为移动构造函数更加匹配,就会调用移动构造函数。
总的来说,如果这两个函数都有在类内定义的话,在构造对象时:
- 若是左值做参数,那么就会调用拷贝构造函数,做一次拷贝(如果是像 string 这样的在堆空间上存在资源的类,那么每调用一次拷贝构造就会做一次深拷贝)。
- 若是右值做参数,那么就会调用移动构造,而调用移动构造就会减少拷贝(如果是像 string 这样的在堆空间上存在资源的类,那么每调用一次移动构造就会少做一次深拷贝)。
比如执行下面这几行代码:
string s("Hello World11111111111111111");
string s1 = s; // s是左值,所以调用拷贝构造函数
string s2 = move(s); // s被move后变为右值,所以调用移动构造函数,s的资源会被转移用来构造s2
// 要注意的是,move一般是不这样用的,因为s的资源被转走了
执行
string s1 = s;前:
执行string s1 = s;后(也是执行string s2 = move(s);前):
执行string s2 = move(s);后:
比如执行语句cout << MyLib::to_string(1234) << endl;
只有拷贝构造没有移动构造:
在 to_string 函数栈帧销毁前,用局部对象 str 拷贝构造出临时对象返回到函数调用处。
既有拷贝构造也有移动构造:
在 to_string 函数栈帧销毁前,用局部对象 str (反正 str 要销毁,将 str 视为右值,直接转移 str 的资源 )移动构造出临时对象返回到函数调用处。
比如执行语句MyLib::string ret = MyLib::to_string(1234);
只有拷贝构造没有移动构造:
在 to_string 函数栈帧销毁前,先用局部对象 str 拷贝构造出临时对象返回到函数调用处,to_string 函数栈帧销毁后,再用临时对象拷贝构造出 ret 。
但现在的编译器一般都会进行优化:因为临时对象有 ret 来接收,这样的话临时对象的创建和销毁就显得多余了,不如省略掉这一步,直接用 str 拷贝构造出 ret 。
既有拷贝构造也有移动构造:
在 to_string 函数栈帧销毁前,由于局部对象 str 是左值(可以对它取地址),所以用 str 拷贝构造出临时对象返回到函数调用处,to_string 函数栈帧销毁后,由于临时对象是右值,所以用临时对象移动构造出 ret 。
但现在的编译器一般都会进行优化:因为临时对象有 ret 来接收,先拷贝构造出临时对象再用它移动构造出 ret ,临时对象好像没必要产生一样,不如省略掉。既然 str 是 to_string 函数栈帧的局部对象,最后还是要销毁,不如将 str 视为右值,直接转移 str 的资源用来构造 ret ,也就是直接用 str 移动构造出 ret 。
再比如执行下面的代码:
调用该函数后,需要传值返回这种占用很多资源的自定义类型,
在 C++98 中,没有移动构造,拷贝构造做深拷贝,花费的代价很大;
在 C++11 中,直接移动构造,转移 m 的资源给 ret ,提高了效率。
转移参数右值的资源来赋给自己。
// 这是一个模拟string类的实现的移动赋值
string& operator=(string&& s)
{
swap(s);
return *this;
}
拷贝赋值函数和移动赋值函数都是赋值运算符重载函数的重载函数,所不同的是:
注:当传来的参数是右值时,虽然拷贝赋值函数可以接收,但是编译器会认为移动赋值函数更加匹配,就会调用移动赋值函数。
总的来说,如果这两个函数都有在类内定义的话,在进行对象的赋值时:
- 若是左值做参数,那么就会调用拷贝赋值,做一次拷贝(如果是像 string 这样的在堆空间上存在资源的类,那么每调用一次拷贝赋值就会做一次深拷贝)。
- 若是右值做参数,那么就会调用移动赋值,而调用移动赋值就会减少拷贝(如果是像 string 这样的在堆空间上存在资源的类,那么每调用一次移动赋值就会少做一次深拷贝)。
比如下面这几行代码:
string s("11111111111111111");
string s1("22222222222222222");
s1 = s; // s是左值,所以调用拷贝赋值函数
string s2("333333333333333333");
s2 = std::move(s); // s被move后变为右值,所以调用移动赋值函数,s的资源会被转移用来赋给s2
// 要注意的是,move一般是不这样用的,因为s的资源被转走了
比如执行下面的语句:
MyLib::string ret("111111111111111111111111");
ret = MyLib::to_string(12345);
没有移动赋值(有移动构造和拷贝赋值):
用 str(编译器视 str 为右值)移动构造出临时对象作为返回值,再用临时对象拷贝赋值给 ret 。
有移动赋值:
用 str(编译器视 str 为右值)移动构造出临时对象作为返回值,由于临时对象是右值,再用临时对象移动赋值给 ret 。
除了上面的使用场景之外,C++11标准的STL 容器的相关接口函数也增加了右值引用版本。
比如:


在此之前我们需要知道什么是万能引用:
确定类型的 && 表示右值引用(比如:int&& ,string&&),
但函数模板中的 && 不表示右值引用,而是万能引用,模板类型必须通过推断才能确定,其接收左值后会被推导为左值引用,接收右值后会被推导为右值引用。
注意区分右值引用和万能引用:下面的函数的 T&& 并不是万能引用,因为 T 的类型在模板实例化时已经确定。
template<typename T>
class A
{
void func(T&& t); // 模板实例化时T的类型已经确定,调用函数时T是一个确定类型,所以这里是右值引用
};
让我们通过下面的程序来认识万能引用:
template<typename T>
void f(T&& t) // 万能引用
{
//...
}
int main()
{
int a = 5; // 左值
f(a); // 传参后万能引用被推导为左值引用
const string s("hello"); // const左值
f(s); // 传参后万能引用被推导为const左值引用
f(to_string(1234)); // to_string函数会返回一个string临时对象,是右值,传参后万能引用被推导为右值引用
const double d = 1.1;
f(std::move(d)); // const左值被move后变成const右值,传参后万能引用被推导为const右值引用
return 0;
}
在调试下开监视窗口可看到传参后参数 t 的类型:
于是我们会用万能引用去做一些有意义的事,比如下面的代码:
void Func(int& x) { cout << "左值引用" << endl; }
void Func(const int& x) { cout << "const左值引用" << endl; }
void Func(int&& x) { cout << "右值引用" << endl; }
void Func(const int&& x) { cout << "const右值引用" << endl; }
template<typename T>
void f(T&& t) // 万能引用
{
Func(t); // 根据参数t的类型去匹配合适的重载函数
}
int main()
{
int a = 4; // 左值
f(a);
const int b = 8; // const左值
f(b);
f(10); // 10是右值
const int c = 13;
f(std::move(c)); // const左值被move后变成const右值
return 0;
}
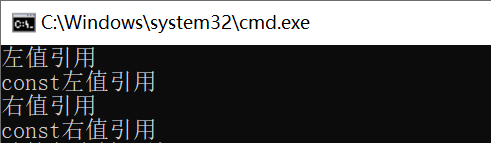
运行程序后,我们本以为打印的结果是:
左值引用
const左值引用
右值引用
const右值引用
但实际的结果却是:
后两行的运行结果跟我们预想的不一样。
那么这是怎么一回事呢?
其实在本文的前面已经讲过了,右值引用变量其实是左值,所以就有了上面的运行结果。
具体解释:
f(10);
10是右值,传参后万能引用被推导为右值引用,但该右值引用变量其实是左值,因此实际调用的函数是void Func(int& x)。f(std::move(c));
const左值被move后变成const右值,传参后万能引用被推导为const右值引用,但该const右值引用变量其实是const左值,因此实际调用的函数是void Func(const int& x)。
也就是说,右值引用失去了右值的属性。
但我们希望的是,在传递过程中能够保持住它的原有的左值或右值属性,于是 C++11标准提出完美转发。
完美转发是指在函数模板中,完全依照模板的参数类型,将参数传递给当前函数模板中的另外一个函数。
因此,为了实现完美转发,除了使用万能引用之外,我们还要用到std::forward(C++11),它在传参的过程中保留对象的原生类型属性。
这样右值引用在传递过程中就能够保持右值的属性。
void Func(int& x) { cout << "左值引用" << endl; }
void Func(const int& x) { cout << "const左值引用" << endl; }
void Func(int&& x) { cout << "右值引用" << endl; }
void Func(const int&& x) { cout << "const右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t) // 万能引用
{
Func(std::forward<T>(t)); // 根据参数t的类型去匹配合适的重载函数
}
int main()
{
int a = 4; // 左值
PerfectForward(a);
const int b = 8; // const左值
PerfectForward(b);
PerfectForward(10); // 10是右值
const int c = 13;
PerfectForward(std::move(c)); // const左值被move后变成const右值
return 0;
}
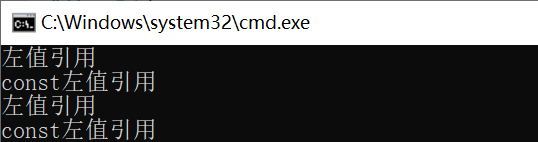
运行结果如下:
实现完美转发需要用到万能引用和 std::forward 。
除了上面的使用场景之外,C++11标准的 STL 容器的相关接口函数也实现了完美转发,这样就能够真正实现右值引用的价值。
比如 STL 库中的容器 list :

上面四个接口函数都调用 _Insert 函数,_Insert 函数模板实现了完美转发。
再比如自己模拟实现的 list(这里只写出主要部分):
template<class T>
struct ListNode
{
ListNode* _next = nullptr;
ListNode* _prev = nullptr;
T _data;
};
template<class T>
class List
{
typedef ListNode<T> Node;
public:
List()
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
void PushBack(const T& x) // 左值引用
{
Insert(_head, x);
}
void PushFront(const T& x) // 左值引用
{
Insert(_head->_next, x);
}
void PushBack(T&& x) // 右值引用
{
Insert(_head, std::forward<T>(x)); // 关键位置:保留对象的原生类型属性
}
void PushFront(T&& x) // 右值引用
{
Insert(_head->_next, std::forward<T>(x)); // 关键位置:保留对象的原生类型属性
}
template<class TPL> // 该函数模板实现了完美转发
void Insert(Node* pos, TPL&& x) // 万能引用
{
Node* prev = pos->_prev;
Node* newnode = new Node;
newnode->_data = std::forward<TPL>(x); // 关键位置:保留对象的原生类型属性
// prev newnode pos
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
private:
Node* _head;
};
只要是右值引用,由当前函数再传递给其它函数调用,要保持右值属性,必须实现完美转发。
右值引用(及其支持的移动语义和完美转发)是 C++11 中加入的最重要的新特性之一,它使得 C++ 程序的运行更加高效。
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我正在尝试将一个资源属性的默认值设置为另一个属性的值。我正在为我正在构建的tomcat说明书定义一个资源,其中包含以下定义。我想要可以独立设置的“名称”和“服务名称”属性。当未设置服务名称时,我希望它默认为为“名称”提供的任何内容。以下不符合我的预期:attribute:name,:kind_of=>String,:required=>true,:name_attribute=>trueattribute:service_name,:kind_of=>String,:default=>:name注意第二行末尾的“:default=>:name”。当我在Recipe的新block中引用我
如thisanswer中所述,Array.new(size,object)创建一个数组,其中size引用相同的object。hash=Hash.newa=Array.new(2,hash)a[0]['cat']='feline'a#=>[{"cat"=>"feline"},{"cat"=>"feline"}]a[1]['cat']='Felix'a#=>[{"cat"=>"Felix"},{"cat"=>"Felix"}]为什么Ruby会这样做,而不是对object进行dup或clone? 最佳答案 因为那是thedocumenta
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
我的ruby脚本从命令行参数获取某些输入。它检查是否缺少任何命令行参数,然后提示用户输入。但是我无法使用gets从用户那里获得输入。示例代码:test.rbname=""ARGV.eachdo|a|ifa.include?('-n')name=aputs"Argument:#{a}"endendifname==""puts"entername:"name=getsputsnameend运行脚本:rubytest.rbraghav-k错误结果:test.rb:6:in`gets':Nosuchfileordirectory-raghav-k(Errno::ENOENT)fromtes
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是