目录

我们身边的人脸识别有车站检票,监控人脸,无人超市,支付宝人脸支付,上班打卡,人脸解锁手机。
人脸检测是人脸识别系统组成的关键部分之一,其目的是检测出任意给定图片中的包含的一个或多个人脸,是人脸识别、表情识别等下游任务的基础。人脸识别是通过采集包含人脸的图像或视频数据,通过对比和分析人脸特征信息从而实现身份识别的生物识别技术,是人脸识别系统的核心组件
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容,基于OpenCV的图片和视频人脸识别。介绍Haar的概念,以及如何对图片和视频中进行人脸检测,以及如何训练我们自己的模型,并在自己的模型下进行人脸识别。
- opencv
关于OpenCv
Opencv是一个开源的的跨平台计算机视觉库,内部实现了图像处理和计算机视觉方面的很多通用算法,对于python而言,在引用opencv库的时候需要写为import cv2。其中,cv2是opencv的C++命名空间名称,使用它来表示调用的是C++开发的opencv的接口。
目前人脸识别有很多较为成熟的方法,这里调用OpenCv库,而OpenCV又提供了三种人脸识别方法,分别是LBPH方法、EigenFishfaces方法、Fisherfaces方法。本文采用的是LBPH(Local Binary Patterns Histogram,局部二值模式直方图)方法。在OpenCV中,可以用函数cv2.face.LBPHFaceRecognizer_create()生成LBPH识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
CascadeClassifier,是Opencv中做人脸检测的时候的一个级联分类器。并且既可以使用Haar,也可以使用LBP特征。其中Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:https://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:https://pypi.hustunique.com/ 山东理工大学:https://pypi.sdutlinux.org/ 豆瓣:https://pypi.douban.com/simple/ 例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好,或者你pycharm里面python解释器没有设置好。
Haar级联是一种基于Haar特征的目标检测方法,它由多个级联分类器组成,每个级联分类器由多个弱分类器组成。在目标检测中,Haar级联通过逐级检测,将输入图像分成多个子区域,然后在每个子区域中应用Haar特征进行分类。这种级联的方式可以大大减少计算量,提高检测速度,同时保证较高的准确性。Haar级联在人脸识别、车辆识别等领域有着广泛的应用。
提取出图像的细节对产生稳定分类结果和跟踪结果很有用。这些提取的结果被称为特征,专业的表述为:从图像数据中提取特征。虽然任意像素都可以能影响多个特征,但特征应该比像素少得多。两个图像的相似程度可以通过它们对应特征的欧氏距离来度量。
Haar 特征是一种用于实现实时人脸跟踪的特征。每一个 Haar 特征都描述了相邻图像区域的对比模式。例如,边、顶点和细线都能生成具有判别性的特征。
首先我们要进入 OpenCV 官网:https://opencv.org 下载你需要的版本。点击 RELEASES
(发布)。如下图所示:
由于 OpenCV 支持好多平台,比如 Windows, Android, Maemo, FreeBSD, OpenBSD, iOS,
Linux 和 Mac OS,一般初学者都是用 windows,点击 Windows。
点击 Windows 后跳出下面界面,等待 5s 自动下载。
文件下载好后,然后双击下载的文件,进行安装,实质就是解压一下,解压完出来一个文件夹,其他什么也没发生。安装完后的目录结构如下。其中 build 是 OpenCV 使用时要用到的一些库文件,而 sources 中则是 OpenCV 官方为我们提供的一些 demo 示例源码。

在 sources 的一个文件夹 data/haarcascades。该文件夹包含了所有 OpenCV 的人脸检测的
XML 文件,这些可用于检测静止图像、视频和摄像头所得到图像中的人脸。
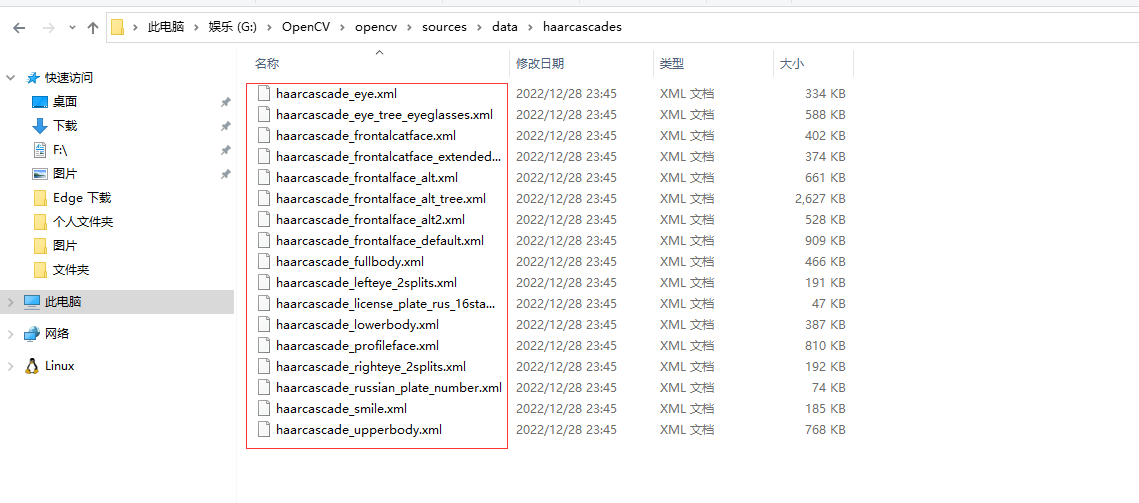
人脸检测器(默认):haarcascade_frontalface_default.xml
人脸检测器(快速 Harr):haarcascade_frontalface_alt2.xml
人脸检测器(侧视):haarcascade_profileface.xml
眼部检测器(左眼):haarcascade_lefteye_2splits.xml
眼部检测器(右眼):haarcascade_righteye_2splits.xml
嘴部检测器:haarcascade_mcs_mouth.xml
鼻子检测器:haarcascade_mcs_nose.xml
身体检测器:haarcascade_fullbody.xml
人脸检测器(快速 LBP):lbpcascade_frontalface.xml
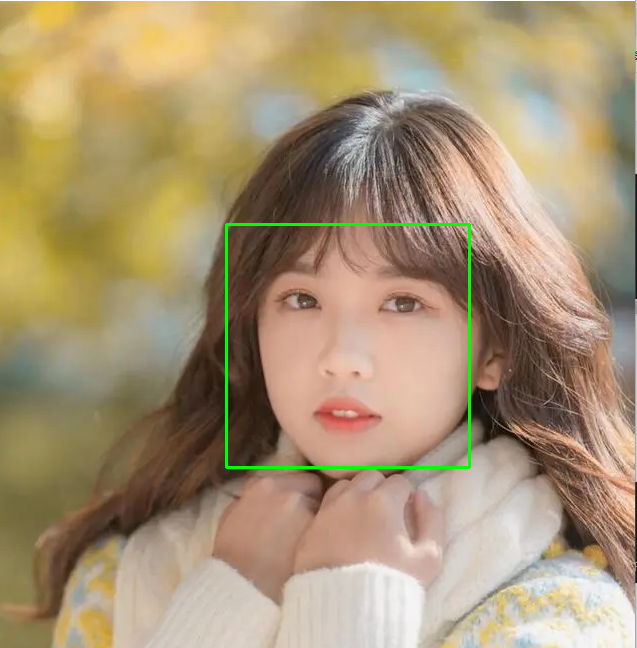
人脸检测首先是加载图像并检测人脸,这也是最基本的一步。为了使所得到的结果有意义,可在原始图像的人脸周围绘制矩形框。
我们首先来识别图片中的人脸,我们先识别图片中的一张人脸,假如,我们测试的照片有两张人脸的话,就会只显示一个人脸。
import cv2 as cv
def face_detect_demo():
#将图片转换为灰度图片
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
#加载特征数据
face_detector=cv.CascadeClassifier('E:\Program Files (x86)\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
faces=face_detector.detectMultiScale(gray)
for x,y,w,h in faces:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,255,0),thickness=2)
cv.imshow('result',img)
#加载图片
img=cv.imread('text1.jpg')
face_detect_demo()
cv.waitKey(0)
cv.destroyAllWindows()
我们前面识别了图片中的一张人脸,假如,我们想测试的照片有两张人脸的话,怎么办?前面的代码就实现不了了,我们来看看多张人脸是怎么实现的。
import cv2 as cv
def face_detect_demo():
#将图片灰度
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
#加载特征数据
face_detector = cv.CascadeClassifier(
'E:\Program Files (x86)\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
faces = face_detector.detectMultiScale(gray)
for x,y,w,h in faces:
print(x,y,w,h)
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=2)
#显示图片
cv.imshow('result',img)
#加载图片
img=cv.imread('text2.jpg')
#调用人脸检测方法
face_detect_demo()
cv.waitKey(0)
cv.destroyAllWindows()我们找了一个多张人脸的照片,相信大家对这张图片并不陌生,我们可以清晰的看到,我们准确无误的识别到了每一张人脸。

视频是一张一张图片组成的,在视频的帧上重复这个过程就能完成视频中的人脸检测。
视频中的人脸检测可以通过以下步骤实现:
- 图像预处理:对输入的视频帧进行预处理,包括图像增强、图像滤波、图像二值化等操作,以增强图像的对比度和亮度,减少噪声的影响,提高图像的质量。
- 特征提取:使用图像处理算法,如SIFT、SURF、ORB等,提取视频帧中的特征,如人脸的位置、大小、形状、姿态等信息,作为人脸检测的基础。
- 人脸检测:使用人脸检测算法,如Haar Cascade、LBPH、LBPH-SIFT等,对视频帧中的图像进行人脸检测,得到检测到的人脸的位置、大小、形状等信息。
- 人脸跟踪:使用人脸跟踪算法,如OpenCV中的人脸跟踪算法,对检测到的人脸进行跟踪,得到人脸的位置、大小、形状等信息。
- 人脸识别:使用人脸识别算法,如支持向量机、深度学习等,对人脸跟踪得到的人脸进行识别,得到人脸的身份信息。
视频是一张一张图片组成的,在视频的帧上重复这个过程就能完成视频中的人脸检测。我们看看代码是如何实现的。
import cv2 as cv
def face_detect_demo(img):
#将图片灰度
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
#加载特征数据
face_detector = cv.CascadeClassifier(
'E:\Program Files (x86)\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
faces = face_detector.detectMultiScale(gray)
for x,y,w,h in faces:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.circle(img,center=(x+w//2,y+h//2),radius=(w//2),color=(0,255,0),thickness=2)
cv.imshow('result',img)
#读取视频
cap=cv.VideoCapture('video.mp4')
while True:
flag,frame=cap.read()
print('flag:',flag,'frame.shape:',frame.shape)
if not flag:
break
face_detect_demo(frame)
if ord('q') == cv.waitKey(10):
break
cv.destroyAllWindows()
cap.release()这里我就不放视频了,我放一张视频的截图,我们可以清楚的看到,可以清晰的识别到我们的人脸。

人脸检测是 OpenCV 的一个很不错的功能,它是人脸识别的基础。什么是人脸识别呢?
其实就是一个程序能识别给定图像或视频中的人脸。实现这一目标的方法之一是用一系列分好类的图像来“训练”程序,并基于这些图像来进行识别。
这就是 OpenCV 及其人脸识别模块进行人脸识别的过程。
人脸识别模块的另外一个重要特征是:每个识别都具有转置信(confidence)评分,因此可在实际应用中通过对其设置阈值来进行筛选。
人脸识别所需要的人脸可以通过两种方式来得到:自己获得图像或从人脸数据库免费获得可用的人脸图像。互联网上有许多人脸数据库。
为了对这些样本进行人脸识别,必须要在包含人脸的样本图像上进行人脸识别。这是一个学习的过程,但并不像自己提供的图像那样令人满意。
有了数据,需要将这些样本图像加载到人脸识别算法中。所有的人脸识别算法在它们的train()函数中都有两个参数:图像数组和标签数组。这些标签表示进行识别时候某人人脸的ID,因此根据 ID 可以知道被识别的人是谁。要做到这一点,将在「trainer/trainer」目录中保存为.yml文件。
import os
import cv2
import sys
from PIL import Image
import numpy as np
def getImageAndLabels(path):
facesSamples = []
ids = []
imagePaths = [os.path.join(path, f) for f in os.listdir(path)]
# 检测人脸
face_detector = cv2.CascadeClassifier(
'E:\Program Files (x86)\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
# 遍历列表中的图片
for imagePath in imagePaths:
# 打开图片
PIL_img = Image.open(imagePath).convert('L')
# 将图像转换为数组
img_numpy = np.array(PIL_img, 'uint8')
faces = face_detector.detectMultiScale(img_numpy)
# 获取每张图片的id
id = int(os.path.split(imagePath)[1].split('.')[0])
for x, y, w, h in faces:
facesSamples.append(img_numpy[y:y + h, x:x + w])
ids.append(id)
return facesSamples, ids
if __name__ == '__main__':
# 图片路径
path = './data/jm/'
# 获取图像数组和id标签数组
faces, ids = getImageAndLabels(path)
# 获取训练对象
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.train(faces, np.array(ids))
# 保存文件
recognizer.write('trainer/trainer.yml')
🍖基于 LBPH 的人脸识别
LBPH(Local Binary Pattern Histogram)将检测到的人脸分为小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。由于这种方法的灵活性,LBPH是唯一允许模型样本人脸和检测到的人脸在形状、大小上可以不同的人脸识别算法。
调整后的区域中调用 predict()函数,该函数返回两个元素的数组:第一个元素是所识别个体的标签,第二个是置信度评分。所有的算法都有一个置信度评分阈值,置信度评分用来衡量所识别人脸与原模型的差距,0 表示完全匹配。可能有时不想保留所有的识别结果,则需要进一步处理,因此可用自己的算法来估算识别的置信度评分。LBPH 一个好的识别参考值要低于 50 ,任何高于 80 的参考值都会被认为是低的置信度评分。
import cv2
import numpy as np
import os
#加载训练数据集文件
recogizer=cv2.face.LBPHFaceRecognizer_create()
recogizer.read('trainer/trainer.yml')
#准备识别的图片
img=cv2.imread('19.pgm')
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
face_detector = cv2.CascadeClassifier(
'E:\Program Files (x86)\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
faces = face_detector.detectMultiScale(gray)
for x,y,w,h in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
#人脸识别
id,confidence=recogizer.predict(gray[y:y+h,x:x+w])
print('标签id:',id,'置信评分:',confidence)
cv2.imshow('result',img)
cv2.waitKey(0)
cv2.destroyAllWindows()标签id: 15 置信评分: 84.05495321482604
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。介绍Haar的概念,以及如何对图片和视频中进行人脸检测,以及如何训练我们自己的模型,并在自己的模型下进行人脸识别。

我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p