目录
场景:适用于需求稳定、明确的项目。
过程:需求分析、总体设计、详细设计、编码和调试、集成测试和系统测试。
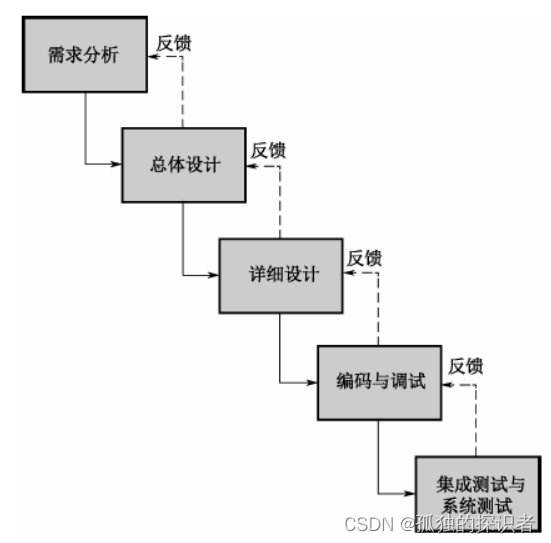
特点:是一种严格遵循软件生命周期各个阶段的固定顺序的模型,每个阶段划分明确,都有固定文档或源程序流入下一个阶段。需求分析是一切活动的基础。
缺点:
1. 由于需求不可能精确、完整的描述整个系统,造成后期维护工作繁重,这些维护工作大多都是在修正需求分析阶段引入的缺陷。
2. 难以适应变化,如果软件在后期出现需求变化,整个系统需要从头开始。
3. 交付时间长,需要等到所有阶段都结束才能交付产品,导致客户无法尽快确定需求是否满足。
4. 产生大量对客户无用的文档,确花费了大量人力,是一种重载过程。
场景:适用于用户需求不明确,且软件完善周期较长的项目。
特点:从初始的模型中逐渐演化为最终软件产品,是一种“渐变式”原型法。可以看作是若干次瀑布模型的迭代,在迭代的过程中得以演化和完善。
缺点:
1. 需要对需求进行明确的拆分,能清晰识别需求边界。
2. 所有的产品需求一开始并不完全弄清楚,会给总体设计带来困难及削弱产品的完整性。
场景:项目规模庞大,复杂且高风险。
特点:是瀑布模型和演化模型的结合,并增加了风险分析(引入非常严格的风险识别、风险分析、风险控制),支持用户需求动态变化。
过程:需求定义、风险分析、工程实现、评审。
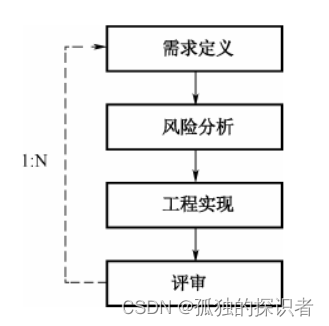
缺点:1. 需要具有相当丰富的风险评估经验和专业知识。
2. 过多的迭代次数会增加开发成本,延迟提交时间。
场景:在系统的技术架构成熟、风险较低的时候采用。
特点:提前进行集成测试和系统测试,缩短初始版本的发布周期,提高用户对系统的可见度
策略:
- 增量发布
特点:将系统划分为若干个不同的版本,每个版本都是一个完整的系统,后一版本以前一版本为基础进行开发,扩充功能,版本间的增量必须是均匀的。
- 原型法
特点:当用户需求不明确或技术架构中存在很多不可认知因素的时候,采用原型法。主要目的是获得精确的用户需求或验证架构的可用性,一般情况会在后期的开发中抛弃这个原型,重新实现完整的系统。
缺点:如何组织一个开放的结构使得该模型不会退化到建造修补模型。
特点:独立的、自包容的,构件之前通过接口相互协作。
过程:设计构件组装、建立构件库、构建应用软件、测试与发布。

优点:
1. 构件的自包容性让系统更容易扩展
2. 更容易被重用,降低开发成本
3. 粒度更小,因此安排开发任务更加灵活。
缺点:
场景:一个通用的过程框架,适合于各种应用领域、组织水平、项目规模的项目。
过程:初始、细化、构建、交付。
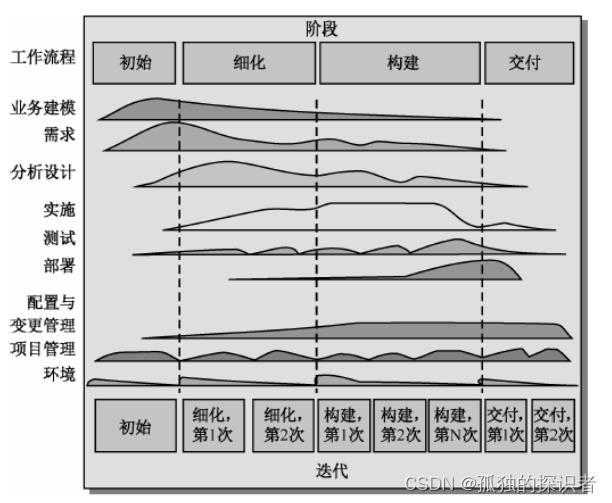
优点:
缺点:虽然UP是一个迭代的开发模型,但是本身并不属于敏捷开发,未经裁剪的up是一个重载过程。
场景:适用于小规模软件或者小团队开发。
特点:是一种以人为核心、迭代、循序渐进的开发方法。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案