上一篇文章我们已经学习了Bean的自动装配,是在xml文件中配置autowire来实现的,现在我们来学习一下通过注解来实现自动装配。
一、使用注解需要的准备工作
使用注解在xml配置文件中导入约束并配置对注解的支持:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<context:annotation-config/>
</beans>二、注解的使用
仍然是上一篇文章的三个类,People、Cat、Dog。
xml文件配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<context:annotation-config/>
<bean class="com.jms.pojo.Dog"/>
<bean class="com.jms.pojo.Cat"/>
<bean id="people" class="com.jms.pojo.People">
<property name="name" value="jms"/>
</bean>
</beans>1.@Autowired
@Autowired注解
@Autowired注解是spring的一个注解,这个注解可以在属性、构造函数、set方法等地方使用,能够实现Bean的自动装配。
(1)在属性上使用
public class People {
private String name;
@Autowired
private Dog dog;
@Autowired
private Cat cat;
}(2)在构造函数上使用
public class People {
private String name;
private Dog dog;
private Cat cat;
@Autowired
public People(Dog dog, Cat cat) {
this.dog = dog;
this.cat = cat;
}(3)在set方法上使用
public class People {
private String name;
private Dog dog;
private Cat cat;
@Autowired
public void setDog(Dog dog) {
this.dog = dog;
}
@Autowired
public void setCat(Cat cat) {
this.cat = cat;
}
}这三种方法进行测试得到的都可以获得最后的结果,测试如下:
@Test
public void test1() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("beans.xml");
People people = applicationContext.getBean("people", People.class);
System.out.println(people.getName());
people.getDog().bark();
people.getCat().bark();
}测试结果:

除此之外@Autowired还有一个属性required默认为true,我们可以设置它为false,当我们设置了false时,被注解的值就可以为null,否则不行。

public class People {
private String name;
@Autowired
private Dog dog;
@Autowired(required = false)
private Cat cat;
}删掉xml文件中cat的bean:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<context:annotation-config/>
<bean class="com.jms.pojo.Dog"/>
<bean id="people" class="com.jms.pojo.People">
<property name="name" value="jms"/>
</bean>
</beans>测试:
@Test
public void test1() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("beans.xml");
People people = applicationContext.getBean("people", People.class);
System.out.println(people.getName());
people.getDog().bark();
System.out.println(people.getCat());
}测试结果:

从测试结果可以看到,cat变成了null。
此时,我们了解了@Autowired的基本用法,我们来思考一个问题,如果有多个同类型的bean会发生什么呢?此时我们修改Cat类型的bean为两个:
<bean id="cat2" class="com.jms.pojo.Cat"/>
<bean id="cat1" class="com.jms.pojo.Cat"/>
结果报错了,它会让我们去选择bean。上面很明显两个bean的id都和属性名不同,如果让其中一个id与属性名相同能否找到呢?
<bean id="cat" class="com.jms.pojo.Cat"/>
<bean id="cat1" class="com.jms.pojo.Cat"/>不再报错。
如果属性名与字段名不同,能否将上面的问题解决呢?答案是可以的,我们需要用到@Qualifier(value = ""),我们只需要让value等于bean的id即可。
如下面的示例:
<bean id="cat" class="com.jms.pojo.Cat"/>
<bean id="cat1" class="com.jms.pojo.Cat"/> @Autowired
@Qualifier(value = "cat1")
private Cat cat;总结一下:
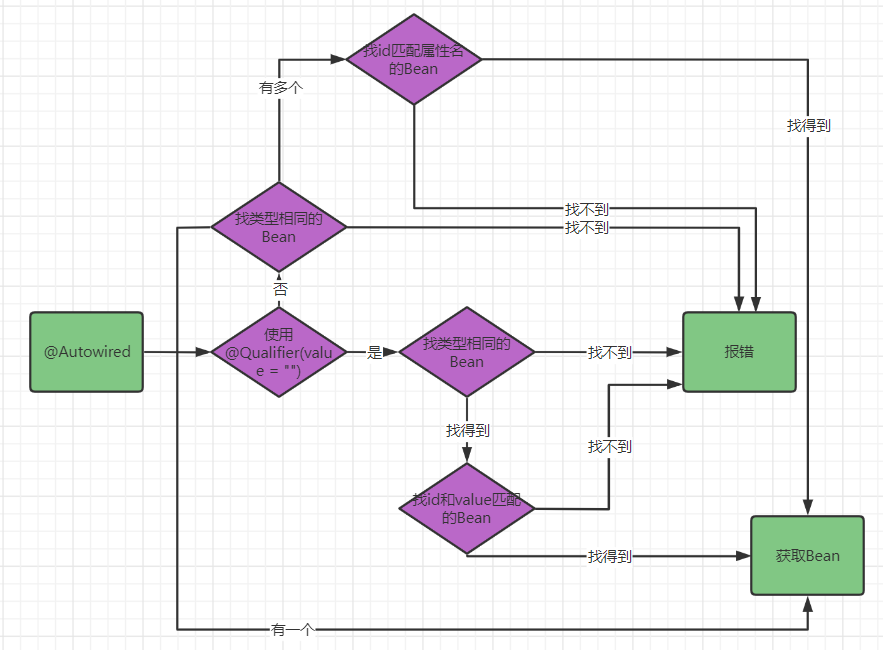
@Autowired注解是先去IOC容器中查到对应类型的Bean,如果有多个对应类型的Bean,然后根据Bean的id进行匹配。
@Autowired有一个属性required默认为true,我们可以设置它为false。true意味着我们必须找到Bean,false意味着可以找不到Bean(null)。
@Autowired可以@Qualifier(value = "")配合使用,这样就会去容器中找id与value值匹配的Bean。并且此时即便只有一个相同类型的Bean,如果id不匹配也会报错。
2.@Resource注解
@Resource注解是java中的一个注解,使用它同样可以实现Bean的自动装配。
@Resource有一个name属性,当使用name属性时,会根据name的值匹配Bean的id。
下面是使用的几个例子:
(1)不使用name属性,唯一Bean没有id
@Resource
private Dog dog;<bean class="com.jms.pojo.Dog"/>没有问题。即使有id且id随意,也是能够找到Bean的,因为类型匹配且唯一。
(2)不使用name属性,Bean不唯一但有能够匹配属性名的id
<bean id="dog" class="com.jms.pojo.Dog"/>
<bean id="dog1" class="com.jms.pojo.Dog"/>这种情况也没有问题,因为id能够与属性名匹配。
(3)使用name属性,Bean不唯一但有能匹配name的id
@Resource(name = "dog1")
private Dog dog; <bean id="dog" class="com.jms.pojo.Dog"/>
<bean id="dog1" class="com.jms.pojo.Dog"/>没有问题,因为name能与Bean的id匹配。
总而言之,@Resource与@Autowried用法基本相同,都是先去容器中匹配类型,如过有多个相同类型则将属性名与id进行匹配;当使用了name或者@Qualifier(value = "")时,会直接去对应类型的Bean中找id能与name或value值相匹配的,如果找不到,即便类型匹配且唯一也会报错。
我们用一个图来更加明了的看一下整个流程(以@Autowried为例):
(本文仅作个人学习记录用,如有纰漏敬请指正)
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev