 简单来说,USM模型在涵盖1200万小时语音、280亿个句子和300种不同语言的无标注数据集中进行了预训练,并在较小的标注训练集中进行了微调。谷歌的研究人员表示,虽然用于微调的标注训练集仅有Whisper的1/7,但USM却有着与其相当甚至更好的性能,并且还能够有效地适应新的语言和数据。
简单来说,USM模型在涵盖1200万小时语音、280亿个句子和300种不同语言的无标注数据集中进行了预训练,并在较小的标注训练集中进行了微调。谷歌的研究人员表示,虽然用于微调的标注训练集仅有Whisper的1/7,但USM却有着与其相当甚至更好的性能,并且还能够有效地适应新的语言和数据。 论文地址:https://arxiv.org/abs/2303.01037结果显示,USM不仅在多语种自动语音识别和语音-文本翻译任务评测中实现了SOTA,而且还可以实际用在YouTube的字幕生成上。目前,支持自动检测和翻译的语种包括,主流的英语、汉语,以及阿萨姆语这类的小语种。最重要的是,还能用于谷歌在去年IO大会展示的未来AR眼镜的实时翻译。
论文地址:https://arxiv.org/abs/2303.01037结果显示,USM不仅在多语种自动语音识别和语音-文本翻译任务评测中实现了SOTA,而且还可以实际用在YouTube的字幕生成上。目前,支持自动检测和翻译的语种包括,主流的英语、汉语,以及阿萨姆语这类的小语种。最重要的是,还能用于谷歌在去年IO大会展示的未来AR眼镜的实时翻译。
 USM使用标准的编码器-解码器结构,其中解码器可以是CTC、RNN-T或LAS。对于编码器,USM使用了Conformor,或卷积增强Transformer。训练过程共分为三个阶段。在初始阶段,使用BEST-RQ(基于BERT的随机投影量化器的语音预训练)进行无监督的预训练。目标是为了优化RQ。在下一阶段,进一步训练语音表征学习模型。使用MOST(多目标监督预训练)来整合来自其他文本数据的信息。该模型引入了一个额外的编码器模块,以文本作为输入,并引入了额外的层来组合语音编码器和文本编码器的输出,并在未标记的语音、标记的语音和文本数据上联合训练模型。最后一步便是,对ASR(自动语音识别)和AST(自动语音翻译)任务进行微调,经过预训练的USM模型只需少量监督数据就可以取得很好的性能。
USM使用标准的编码器-解码器结构,其中解码器可以是CTC、RNN-T或LAS。对于编码器,USM使用了Conformor,或卷积增强Transformer。训练过程共分为三个阶段。在初始阶段,使用BEST-RQ(基于BERT的随机投影量化器的语音预训练)进行无监督的预训练。目标是为了优化RQ。在下一阶段,进一步训练语音表征学习模型。使用MOST(多目标监督预训练)来整合来自其他文本数据的信息。该模型引入了一个额外的编码器模块,以文本作为输入,并引入了额外的层来组合语音编码器和文本编码器的输出,并在未标记的语音、标记的语音和文本数据上联合训练模型。最后一步便是,对ASR(自动语音识别)和AST(自动语音翻译)任务进行微调,经过预训练的USM模型只需少量监督数据就可以取得很好的性能。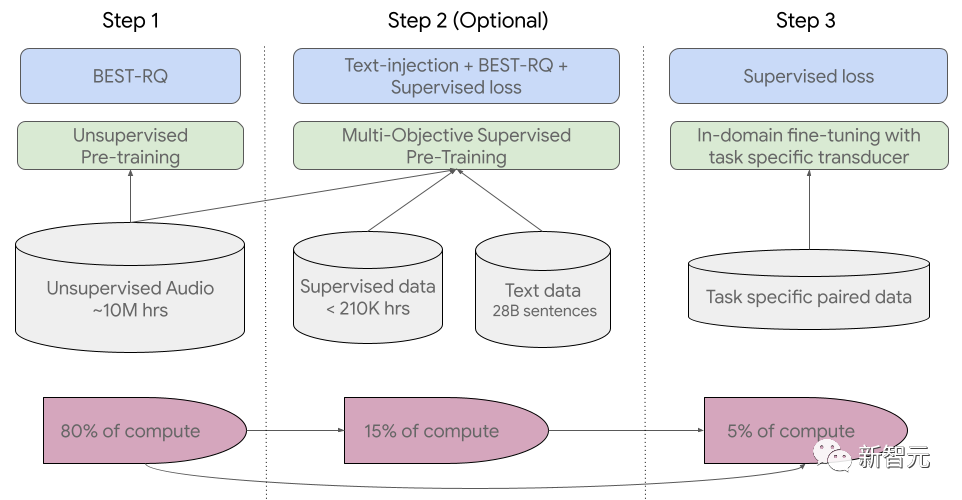 USM整体训练流程USM的性能如何,谷歌对其在YouTube字幕、下游ASR任务的推广、以及自动语音翻译上进行了测试。YouTube多语言字幕上的表现受监督的YouTube数据包括73种语言,每种语言的数据时长平均不到3000个小时。尽管监督数据有限,但模型在73种语言中实现了平均不到30%的单词错误率(WER),这比美国内部最先进的模型相比还要低。此外,谷歌与超40万小时标注数据训练出的Whisper模型 (big-v2) 进行了比较。在Whisper能解码的18种语言中,其解码错误率低于40%,而USM平均错误率仅为32.7%。
USM整体训练流程USM的性能如何,谷歌对其在YouTube字幕、下游ASR任务的推广、以及自动语音翻译上进行了测试。YouTube多语言字幕上的表现受监督的YouTube数据包括73种语言,每种语言的数据时长平均不到3000个小时。尽管监督数据有限,但模型在73种语言中实现了平均不到30%的单词错误率(WER),这比美国内部最先进的模型相比还要低。此外,谷歌与超40万小时标注数据训练出的Whisper模型 (big-v2) 进行了比较。在Whisper能解码的18种语言中,其解码错误率低于40%,而USM平均错误率仅为32.7%。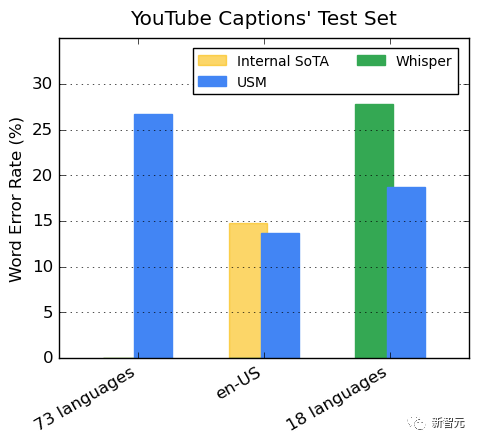 对下游ASR任务的推广在公开的数据集上,与Whisper相比,USM在CORAAL(非裔美国人的方言英语)、SpeechStew(英文-美国)和FLEURS(102种语言)上显示出更低的WER,不论是否有域内训练数据。两种模型在FLEURS上的差异尤为明显。
对下游ASR任务的推广在公开的数据集上,与Whisper相比,USM在CORAAL(非裔美国人的方言英语)、SpeechStew(英文-美国)和FLEURS(102种语言)上显示出更低的WER,不论是否有域内训练数据。两种模型在FLEURS上的差异尤为明显。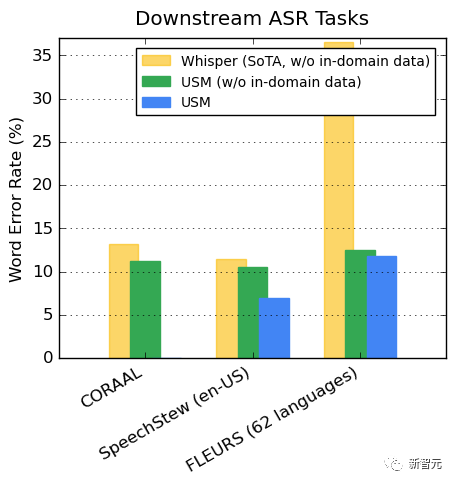 在AST任务上的表现在CoVoST数据集上对USM进行微调。将数据集中的语言按资源可用性分为高、中、低三类,在每一类上计算BLEU分数(越高越好),USM在每一类中的表现的优于Whisper。研究发现,BEST-RQ预训练是将语音表征学习扩展到大数据集的一种有效方法。当与MOST中的文本注入相结合时,它提高了下游语音任务的质量,在FLEURS和CoVoST 2基准上实现了最好的性能。通过训练轻量级剩余适配器模块,MOST表示能够快速适应新的域。而这些剩余适配器模块只增加2%的参数。
在AST任务上的表现在CoVoST数据集上对USM进行微调。将数据集中的语言按资源可用性分为高、中、低三类,在每一类上计算BLEU分数(越高越好),USM在每一类中的表现的优于Whisper。研究发现,BEST-RQ预训练是将语音表征学习扩展到大数据集的一种有效方法。当与MOST中的文本注入相结合时,它提高了下游语音任务的质量,在FLEURS和CoVoST 2基准上实现了最好的性能。通过训练轻量级剩余适配器模块,MOST表示能够快速适应新的域。而这些剩余适配器模块只增加2%的参数。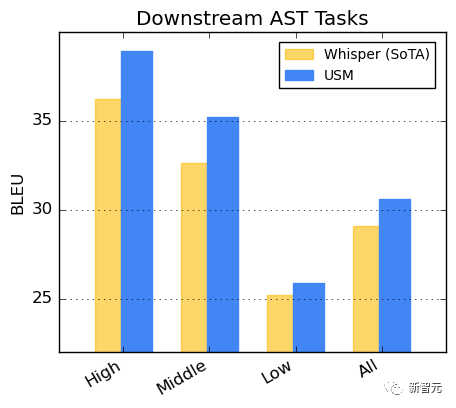 谷歌称,目前,USM支持100多种语言,到未来将扩展到1000多种语言。有了这项技术,或许对于每个人来讲走到世界各地稳妥了。甚至,未来实时翻译谷歌AR眼镜产品将会吸引众多粉丝。不过,现在这项技术的应用还是有很长的一段路要走。毕竟在面向世界的IO大会演讲中,谷歌还把阿拉伯文写反了,引来众多网友围观。
谷歌称,目前,USM支持100多种语言,到未来将扩展到1000多种语言。有了这项技术,或许对于每个人来讲走到世界各地稳妥了。甚至,未来实时翻译谷歌AR眼镜产品将会吸引众多粉丝。不过,现在这项技术的应用还是有很长的一段路要走。毕竟在面向世界的IO大会演讲中,谷歌还把阿拉伯文写反了,引来众多网友围观。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)