摘要:目前,鲲鹏亲和开发框架提供:场景化SDK、启发式编程、鲲鹏亲和分析、鲲鹏调试器、远程实验室等功能,降低开发应用难度,方便开发者使用鲲鹏架构提供的软硬协同能力,提升开发效率。
本文分享自华为云社区《掌握这5大功能,解锁鲲鹏开发新发现》,作者:华为云社区精选 。
本文主要介绍鲲鹏开发框架插件工具能力和使用方法,还会将鲲鹏编译调试的新特性和功能也和大家同步一下,内容主要包括三个方面:鲲鹏开发框架整体介绍和鲲鹏编译调试工具。

我们先看第一部分内容,目前鲲鹏应用开发面临的问题:
随着鲲鹏发展,越来越多的应用有诉求在鲲鹏进行原生开发,使用好鲲鹏算力。通过广泛的调研,我们了解到开发者开发鲲鹏架构应用主要痛点是:不了解鲲鹏架构的特点,不知道在应用中,怎么样可以使用出最大算力。
1. 开发阶段:缺乏鲲鹏亲和开发的实时引导、缺乏对鲲鹏特点检查工具、依赖库生态难以快速获取;
2. 编译调试阶段:难以充分利用微架构性能优势、无多样算力编译和调试能力;
3. 测试阶段:存在兼容性测试工作量大、应用的安全性、稳定性、性能及功耗等问题难以保障。
为了解决开发者的痛点,我们推出了鲲鹏亲和开发框架,帮助开发者降低学习成本和入门门槛,提高开发效率。

目前,鲲鹏亲和开发框架提供:场景化SDK、启发式编程、鲲鹏亲和分析、鲲鹏调试器、远程实验室等功能,降低开发应用难度,方便开发者使用鲲鹏架构提供的软硬协同能力,提升开发效率。
• 通过鲲鹏亲和开发框架,用户方便获取线上实验资源、编程指南、指导手册资料;通过快速学习,赋能开发者鲲鹏应用开发能力,开发者通过工程向导创建代码工程,并利用鲲鹏场景化SDK,快速学习鲲鹏架构特性,开发鲲鹏亲和代码。
• 开发过程中,通过启发式编程,可以智能提示近万条优化函数和百万级依赖文件。
• 通过静态检查工具,屏蔽底层的硬件差异,大大提高软件设计和开发效率。
• 提供多样化调试工具,通过鲲鹏调试器,用户可以针对不同的使用场景和应用类型,对通用应用程序进行调试,方便定位代码问题。
• 提供远程实验室,免费向开发者提供远程功能,可以随时随地体验鲲鹏多样算力。
接下来,会逐一详细介绍这5个功能:

鲲鹏开发框架主要是提供给开发者:开发体验好、架构自亲和、应用高性能、多算力兼容的框架,降低开发者学习和开发鲲鹏应用的难度。

场景化SDK包括:提供安全计算,高性能计算和通用计算三大类,以及二十余种应用场景的Demo工程的创建和管理支持对应SDK的下载、部署和检查,零成本学习鲲鹏开发框架,助力开发者快速进行工程构建。

随着操作系统复杂性提升,攻击窗口也在变大,如果没有安全加固,漏洞会被利用,有些应用被设置为可信应用,具有较高特权,但也存在固有安全漏洞,被黑客能够获取到用户数据。
而鲲鹏开发框架基于机密计算TrustZone套件,向开发者提供了安全计算SDK,从硬件架构上提供可信运营环境TEE,在应用被系统攻破后,黑客也无法获取用户环境,保护了应用和数据的安全性。
安全sdk提供了CA工程、TA工程、RSA工程、机密数据保存、匿名投票和证书签发6个参考实现,帮助开发者快速学习安全计算SDK的使用。
1、 CA工程主要是运行在业务环境下的应用程序工程,展示的是CA工程如何调用TA工程。
2、 TA工程主要是运行在可信执行环境下的TEE应用程序,主要是TEE环境工程接口调用。
3、 RSA工程包含了CA工程和TA工程,是基于RSA加解密、签名和验签的工程。
4、 机密数据保存工程使用TEE安全存储接口,保存机密数据,可以支持将敏感数据进行加密操作,不再需要从软件层进行加密工作。
5、 匿名投票系统可以在保证数据隐私安全的情况下,完成匿名投票,可在业务执行环境中,可以查看用户是否投票,但是无法获取其投票选项。
6、 证书签发工程主要是用户签发X509场景,主要功能是创建证书,对用户提交的证书请求文件进行签名,生成X509证书,使用TEE对证书的私钥加密保存,保证证书私钥不会泄露。

高性能SDK包含两个内容:
1、高性能通信库
高性能计算简称HPC,是一个计算机集群系统,通过互联技术将多个计算机系统连在一起,运用所有系统的综合算力来处理单个系统无法完成的数据密集型任务,包括:仿真、建模、渲染等。HPC整合多个单元计算能力,将大规模运算任务拆分在各个服务器上运行的能力,再将计算结果汇总,得到最终结果,从而实现强大计算功能。
鲲鹏亲和开发框架面向HPC场景提供Hyper MPI和数学加速库,助力开发者构建高性能应用。
2、数学库
提供基于鲲鹏平台优化的高性能数学库,包括:基础数学运算库、线性代数运算库、基础线性代数库、稀疏线性代数库、快速傅里叶变换库。

通用计算SDK包含三个内容:
1、硬件加速应用:基于鲲鹏硬件加速的压缩、国密加解密工程。
2、加速库应用:正则表达匹配、压缩、加解密、信息摘要、循环校验。
3、同构加速应用:注解形式实现JAVA程序远程卸载,从而实现代码的加速效果。
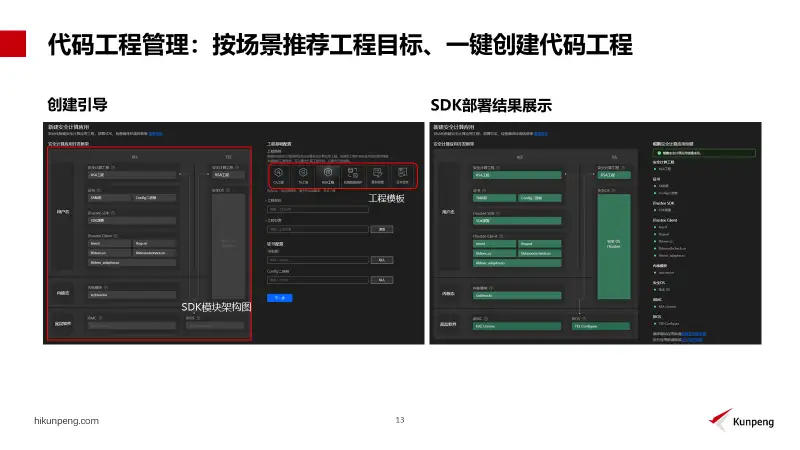
鲲鹏开发框架向开发者展示SDK模块架构图,可以清晰了解到所需要组件以及在系统中位置,选择自动部署或者下载后手动部署SDK到远程服务器,用户可以根据组件架构图的提示,查看部署是否完成。
工程创建完成后,鲲鹏开发框架会展示下载的模板工程、代码和目录数,用户通过阅读和调试样例代码,了解鲲鹏架构特性,学习和使用场景化SDK来提供鲲鹏软硬件能力,并基于这些代码可以进行二次开发,图示是RSA工程运行结果。

借助启发式编程搜索功能,提高应用开发效率和质量,用户可以获得相关函数在线说明文档和使用介绍。智能联想补全主要针对是开发代码编写过程,函数搜索主要是针对想提前了解一个函数的使用。
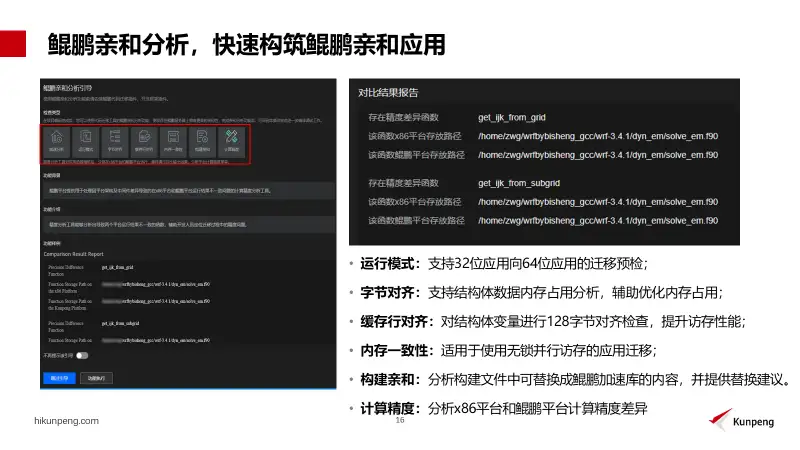
鲲鹏亲和开发框架提供鲲鹏亲和分析的功能,帮助开发阶段使用更高效鲲鹏加速库,检查应用软件的鲲鹏亲和性,更高效的使用鲲鹏算力。

之前介绍的是通用应用程序的编译调试功能,今年增加本地/远程调试、GPU程序调试、HPC并行调试的能力。

在实际开发场景中,开发者经常需要在服务器上进行开发、编译、调试和运行操作。由于绝大多数开发者更喜欢在本地windows环境上使用IDE编码,需要开发者编写好代码后,手动上传到远端服务,在服务器上进行编译调整等一系列操作,若编译调试报错,这还需要在本地修改代码再继续上传;若运行报错,则需要开发者在远端服务器进行跟踪定位,最后在本地修改代码再上传编译运行。
这个过程相对来说是比较低效,为解决因开发编译调试环境分离,造成的开发效率低下问题,鲲鹏亲和开发框架提供了鲲鹏编译调试功能,该功能可以简化程序开发流程,提高开发效率,可以在本地IDE中实现开发同步、代码远程编译和远程调试功能。
在编译之前,用户可以使用一键部署编译器功能,将选择的编译器一键部署到目标服务器,目前可选部署的编译器支持:毕昇编译器,毕昇JDK还有GCC for openEuler的部署,在部署完成后,可创建一个编译任务,通过一键同步代码功能,将我们的代码同步到远端节点,代码同步完成后,点击按钮执行远程编译操作。编译过程中的结果,可以在终端显示,整个过程无需我们频繁在IDE和远端服务器之间进行切换,实现了我们IDE一站式部署开发,远程编译和调试。
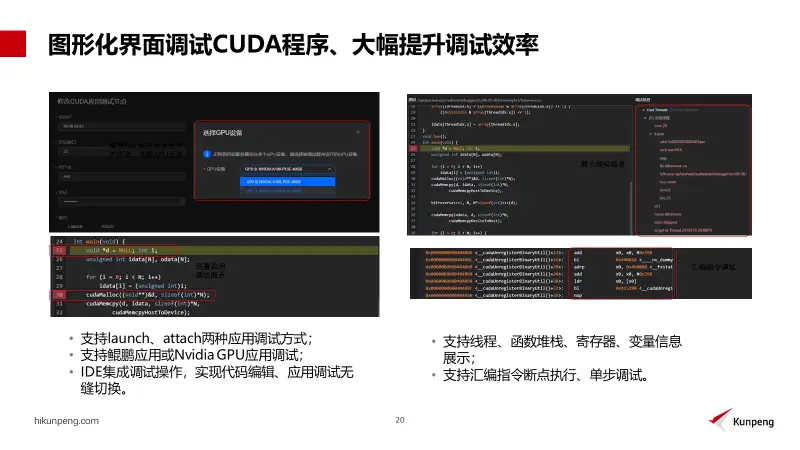
鲲鹏亲和开发框架提供的编译调试插件,在原有功能上增加了CUDA程序调试器。可以在本地ID上调试,远程服务器上的CUDA应用程序。通过图形化页面的方式向用户提供CUDA程序调试能力,功能更加贴近开发习惯,简单易用,降低了用户的使用门槛和学习成本,提升了代码调试效率。
CUDA调试器支持两种模式,一种是Launch,还有一种是attach,其中 launch模式支持选择GPU设备进行调试。CUDA支持多线程调试,在调试过程中可以进行线程切换,支持对应线程的堆栈变量等信息的一个展示。
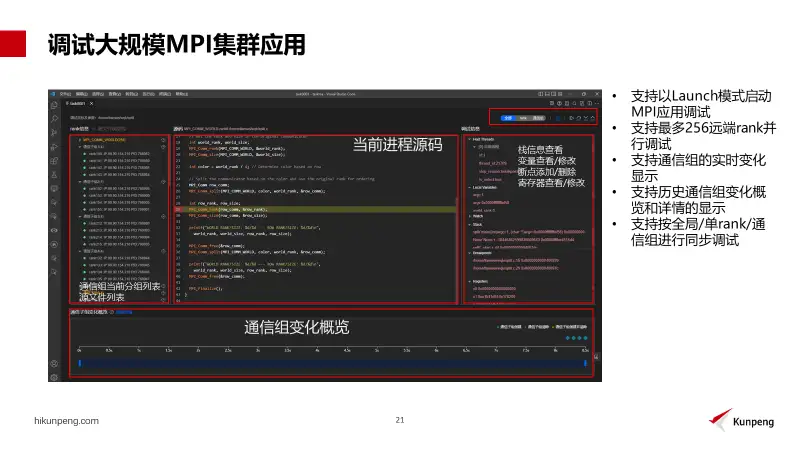
接下来介绍是一个重点功能。编译调试针对大规模MPI应用集群的调试能力,目前现状是:HPC并行程序具有复杂逻辑、并发量大、计算节点多、进程数多、状态切换迅速且复杂等特点,难以进行一个集群调试。针对这个问题,鲲鹏调试器提供HPC并行调试功能,支持launch模式启动,最多支持256个本地或远程的MPI集群应用进行调试。
在调试过程中,开发者可实时查看每个进程的全局rank排序,所在计算节点IP和PID,方便开发者查找指定进程。同时开发者可以通过按键切换显示源文件目录数,查看被调用程序的源代码列表,切换不同源代码阅读,能够直接对应匹配上源码位置。
开发者还可以点选分组列表中不同进程进行切换,查看不同进程运行位置,在调试信息区可以看到调用站,支持变量修改断点、添加和删除。鲲鹏调试器支持按照全局单进程或单通信组方式进行同步调试。当程序执行到某一关键步骤时,开可以选择单独调试执行关键的一个或者一个组的进程,排除其余进程对该调试干扰,在非关键步骤情况下,再切回全局进行调试。

可以看到通信组变化界面,鲲鹏调试器支持通信组生命周期的展示。当开发者点开详情页面后,鲲鹏调试器会在时间轴上展示每一个通信组程序时间段,方便用户了解对应时间段执行通信组的情况,帮助开发者去更好的定位问题,提高调试效率。
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它: