| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 100 |
| · Estimate | · 估计这个任务需要多少时间 | 480 | 600 |
| Development | 开发 | 180 | 240 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 60 | 50 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 90 | 120 |
| · Coding | · 具体编码 | 40 | 40 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 210 |
| Reporting | 报告 | 30 | 50 |
| · Test Repor | · 测试报告 | 20 | 15 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 35 |
| · 合计 | 480 | 600 |
本文使用SimHash和海明距离计算文章重复率,原理参考自:https://blog.csdn.net/wxgxgp/article/details/104106867
在分词与权重计算部分参考自jieba库的Github:https://github.com/fxsjy/jieba
stopWords = [' ', '!', ',', '.', '?', '!', '?', ',', '。', '\n', '\t', '\b', '"', '“', '”', ':', '《', '》', '<', '>']
splitWords = jieba.lcut(source)
splitWords = del_stopWords(splitWords, stopWords)
#删除停用词
def del_stopWords(split_sentence, stopWords):
i = 0
while (len(split_sentence) != 0):
if (i >= len(split_sentence)):
break
#匹配停用词
tmp = False
for n in stopWords:
if (split_sentence[i] == n):
tmp = True
break
if (tmp):
split_sentence.pop(i)
continue
i += 1
return split_sentence
# 哈希函数,输入单个分词
def string_hash(source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2**128 - 1
for c in source:
x = ((x*m)^ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
return str(x)
#计算权重并加权,输入分词列表,可以去重并重新排序
def count_weight(split_sentence, listSize):
keyWords = jieba.analyse.extract_tags("|".join(split_sentence), topK=listSize, withWeight=True)
list_weightPluse = list()
a = list(map(int, string_hash(keyWords[0][0])))
for index in range(len(keyWords)):
tmp = list(map(int, string_hash(keyWords[index][0])))
tmp = np.subtract(np.multiply(tmp, 2), 1) #把0 1转换为-1 1
list_weightPluse.append(np.multiply(tmp, keyWords[index][1]))
return list_weightPluse
#合并加权后的哈希值,输入加权哈希值列表
def mergeHash(list_weightPluse):
mergeHash_list = [0] * 64
for index in range(len(list_weightPluse)):
mergeHash_list = np.add(mergeHash_list, list_weightPluse[index])
return mergeHash_list
#降维,大于0的输出1,小于等于0的输出0
def reduction(mergeHash_list):
reduction_list = list()
for index in range(len(mergeHash_list)):
if (mergeHash_list[index] > 0):
reduction_list.append(1)
else:
reduction_list.append(0)
return reduction_list
#海明距离
def getDistance(list_1, list_2):
distance = 0
for index in range(len(list_1)):
if (list_1[index] ^ list_2[index] == 1):
distance += 1
return distance
#将汉明距离转换为相似度
similarity = round((64 - hanmingDistance) / 64 * 100, 2)
address_orig = sys.argv[1]
address_copy = sys.argv[2]
address_out = sys.argv[3]
#读入并计算源文件的simhash
file_1 = open(address_orig, encoding= 'UTF-8')
s1 = file_1.read()
list_1 = simhash(s1, stopWords)
#print(list_1)
file_1.close()
#将相似度写入新建文件
file_3 = open(address_out, 'w', encoding= 'UTF-8')
file_3.write(str(similarity))
file_3.close()
尝试输出结果
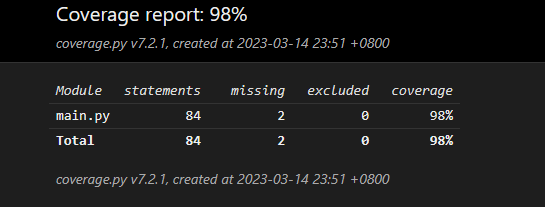
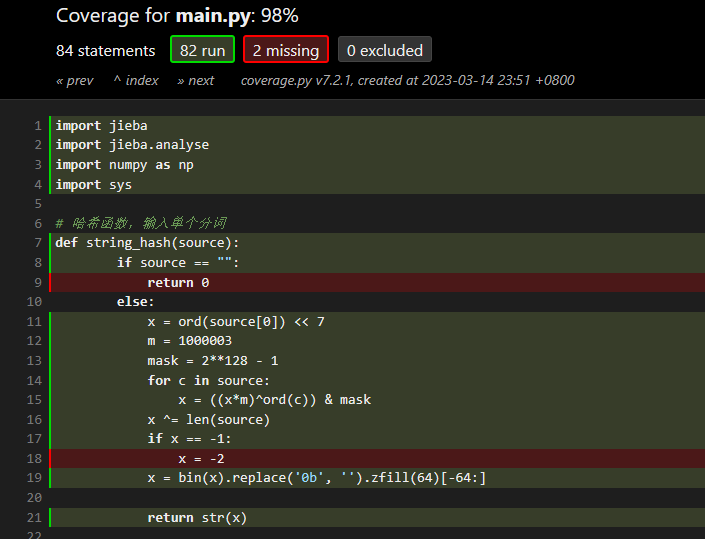
因为分词的准确性直接关系到最后输出结果过的准确性,所以这次我主要测试分词功能是否完善
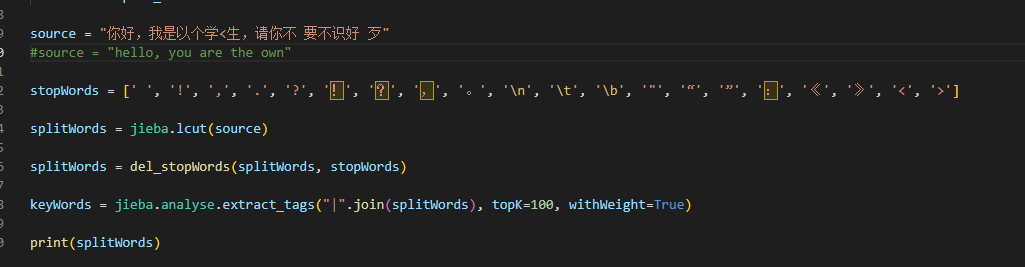

可见,当完整的词语被空格或者其它符号打断时,jieba库似乎不能很好的检测出来,如果是一些比较重要的词出现增删改的情况,很有可能会影响相似度的计算。
如果考虑在分词前将停用词去除,如果处理的文章里有英文,则会导致单词粘连的情况而无法正确识别英文单词。
也许有更好的方法解决这个问题,比如区分各种情况,再根据不同情况用不同的方法去除干扰词。
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
是否可以在所有delayed_job任务之前运行一个方法?基本上,我们试图确保每个运行delayed_job的服务器都有我们代码的最新实例,所以我们想运行一个方法来在每个作业运行之前检查它。(我们已经有了“check”方法并在别处使用它。问题只是关于如何从delayed_job中调用它。) 最佳答案 现在有一种官方方法可以通过插件来做到这一点。这篇博文通过示例清楚地描述了如何执行此操作http://www.salsify.com/blog/delayed-jobs-callbacks-and-hooks-in-rails(本文中描述
我的Rails应用程序中安装了carrierwave。但是,当用户上传多页pdf时,我只希望应用程序获取文档中的第一页并将其转换为jpeg。这可能吗?用什么命令?这是我的uploader。#encoding:utf-8classImageUploader[200,300]##defscale(width,height)##dosomething#end#Createdifferentversionsofyouruploadedfiles:version:thumbdoprocess:resize_to_fill=>[150,210]process:convert=>:jpgdefful
有没有办法跳过CSV文件的第一行,让第二行作为标题?我有一个CSV文件,第一行是日期,第二行是标题,所以我需要能够在遍历它时跳过第一行。我尝试使用slice但它会将CSV转换为数组,我真的很想将其读取为CSV,以便我可以利用header。 最佳答案 根据您的数据,您可以使用另一种方法和skip_lines-option此示例跳过所有以#开头的行require'csv'CSV.parse(DATA.read,:col_sep=>';',:headers=>true,:skip_lines=>/^#/#Markcomments!)do|
我查看了Stripedocumentationonerrors,但我仍然无法正确处理/重定向这些错误。基本上无论发生什么,我都希望他们返回到edit操作(通过edit_profile_path)并向他们显示一条消息(无论成功与否)。我在edit操作上有一个表单,它可以POST到update操作。使用有效的信用卡可以正常工作(费用在Stripe仪表板中)。我正在使用Stripe.js。classExtrasController5000,#amountincents:currency=>"usd",:card=>token,:description=>current_user.email)
我的任务是从数组中选择最高和最低的数字。我想我很清楚我想做什么,但只是努力以正确的格式访问信息以满足通过标准。defhigh_and_low(numbers)array=numbers.split("").map!{|x|x.to_i}array.sort!{|a,b|ba}putsarray[0,-1]end数字可能看起来像"80917234100",要通过,我需要输出"9234"。我正在尝试putsarray.first.last,但一直无法弄明白。 最佳答案 有Array#minmax完全满足您需要的方法:array=[80,