今年初,英特尔正式发布了第四代英特尔®至强®可扩展处理器。与前一代产品最大的差别在于,除了增加的核心数量和制造工艺之外,第四代英特尔®至强®可扩展处理器专门针对人工智能、5G网络、数据分析、科学计算等现代工作负载,引入针对实际工作负载优化加速的设计理念,采用系统级设计方法,在CPU芯片架构中内置专用的工作负载加速器,以提升性能和效率。
这样的设计,到底能够为现代化的工作负载带来多大的性能提升呢?八周之后,采用第四代英特尔®至强®可扩展处理器的实例应运而生。近期,来自于英特尔的多位技术专家,通过不同的应用案例,详细介绍了第四代英特尔®至强®可扩展处理器在不同应用场景下的性能提升。
七大算力神器之外,再添vRAN Boost
1月11日,英特尔正式推出了第四代英特尔至强可扩展处理器(代号“Sapphire Rapids”),与上一代产品相比,第四代英特尔至强可扩展处理器采用Intel 7制程工艺制造,集成了高性能核心、更多内核数量,英特尔 AMX、英特尔 IAA、英特尔 QAT、英特尔 DLB、英特尔 DSA、英特尔 SGX、英特尔至强CPU MAX系列这七大算力神器,以及业界领先的DDR5、CXL1.1、PCIe 5.0,共同构成了新一代产品的最大特色。
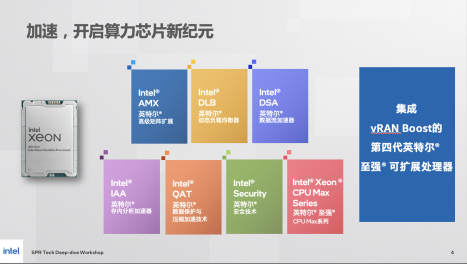
距离发布不到八周时间内,英特尔在七大“算力神器”的基础上,又添加了vRAN Boost。英特尔市场营销集团副总裁、中国区数据中心销售总经理兼中国区运营商销售总经理庄秉翰表示,英特尔vRAN Boost使得运营商能够在通用虚拟化平台上整合所有基站层。未来,客户通过通用处理器来实现基站功能,能够带来很大的性价比提升。
庄秉翰指出,随着“双碳”、新基建、“东数西算”等的发展,对未来数据中心能耗需求越来越严苛,绿色计算也成为可持续发展的关键动力。为此,第四代英特尔至强可扩展处理器通过内置加速器,能够更加高效、以更低能耗处理复杂度越来越高的工作负载。他强调,第四代英特尔至强可扩展处理器包含丰富的内置加速器,帮助提高能效和性能,是英特尔最具可持续性的数据中心处理器。除此之外,通过电源管理解决方案,能够更好地提升处理器运算中的能效比。
目前,大多数主流OEM和ODM厂商都在出货基于该处理器的系统设计,前十大云服务提供商也将在今年部署基于该款处理器的云实例。在新处理器得到越来越多应用的同时,一批采用新处理,利用新处理器优势特性的案例也浮出水面。
引入AMX加速器,最强大的AI通用处理器
在第四代英特尔至强可扩展处理器当中,笔者最关注的是AMX加速器。
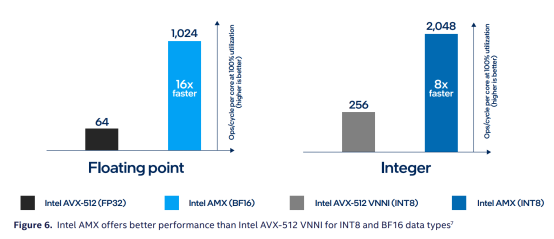
AMX加速器支持INT8和BF16两种计算精度,且两种使用频次都非常高。其中,INT8常用于推理。众所周知,在日常生产环境中,推理用的频次要远远高于训练的次数,比如,每次刷脸完成身份验证就是一次推理过程,社交软件里每一次语音转文字,文字转语音都是推理过程。
混合精度浮点BF16也常用在训练场景中,并且,使用频次在近年来逐渐增加。其主要优势是在可以在保持较高精度的同时,提高计算速度和减少存储空间。与AVX-512相比,每一个计算周期的计算性能大大提升。
借助英特尔专家分享的一组数据,我们能够看到加入AMX加速器之后,第四代英特尔至强可扩展处理器所带来的性能提升。(见下图)
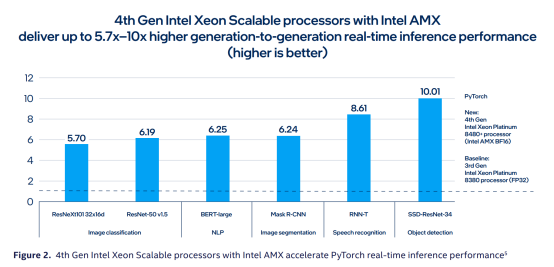
与上一代相比,第四代至强处理器推理性能提高了5.7-10倍
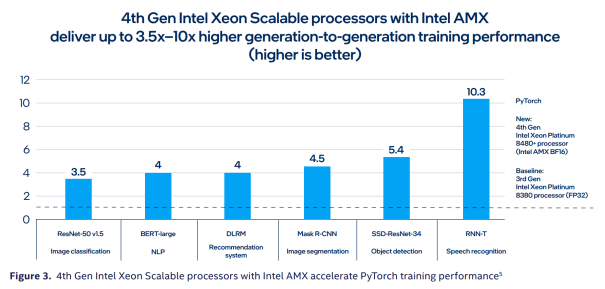
与上一代相比,第四代至强处理器训练性能提高了3.5-10倍
在AMX加速引擎的助力下,英特尔至强不仅能用来做推理,还能用来处理一些机器学习训练的工作负载,这也让英特尔至强成了最适合机器学习的通用x86处理器。由于支持INT8和BF16两种计算精度,这也就意味着至强处理器事实上可以覆盖很多场景。
为多种场景提速,推动AI应用迈上新台阶
AMX加速器在互联网场景、OCR场景、以及生成式模型、大语言模型中的均有多种应用案例。
AMX加速器在腾讯太极机器学习平台支撑搜索和广告业务中应用,解决了搜索数量多,以及对于搜索延迟要求高的问题。太极机器学习平台支撑的搜索业务部署在腾讯云上,所使用的云主机就基于新一代英特尔至强而构建,配合软件上的优化,不仅帮降低了所使用的CPU的数量,同时性能也有2到3倍的提升。
AMX加速器应用于阿里淘宝业务中,使用INT8精度加上软件优化的技术,支撑淘宝的“地址标准化”服务,该服务涉及到语义分析等技术,而AMX则提高了语义分析的性能。此外,阿里还将AMX的BF16计算精度用于手机淘宝首页个性化推荐的场景,配合软件层面上的优化,每天承载着高达亿次的请求,得益于AMX所带来的提升,其最终性能达到了原来的3倍。
在亚信开发的电信智能营业厅方案中,用OCR来识别客户提交上来的身份证件和工商营业执照图片,OCR这种推理负载的需求量非常大,每年大概需要2000万次服务。当把业务迁移到第四代至强可扩展处理器,并针对AMX做了优化之后,性能达到了3.94倍的提升。
用友企业ERP软件中有一个OCR模块,该模块主要是用于识别办公和财务领域发票内容,该业务每年需要支持3000万次的服务请求。当迁移到第四代至强可扩展处理器之后,结合AMX的优势,实际性能达到了原来的3.83倍。
除此之外,AMX加速器还应用于生成式模型、大语言模型中。英特尔技术专家通过Stable Diffusion的案例,进行了详细的介绍。据了解, Stable Diffusion的技术构成上大量使用了注意力机制,而注意力机制需要矩阵相乘和指数运算能力。而新一代英特尔至强的AMX BF16可用于加速矩阵计算,AVX-512可以用来加速指数计算。经测试发现,配合英特尔PyTorch扩展插件用Stable Diffusion,生成512x512图片吞吐性能提高了3.82倍,720P图片的吞吐性能提高了5.26倍。
不难发现,由于AMX加速器的加持,使得机器学习的效率和经济性方面迈向一个新的台阶,也将使得第四代英特尔至强成为目前市场上,最适合人工智能负载的通用x86处理器。
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
我正在使用carrierwave上传视频然后有一个名为thumb的版本,带有自定义处理器,可以获取视频并使用streamio-ffmpeg创建屏幕截图。视频和文件都已正确上传,但在调用uploader.url(:thumb)时我得到:ArgumentError:Versionthumbdoesn'texist!VideoUploader.rbrequire'carrierwave/processing/mime_types'require'streamio-ffmpeg'classVideoUploader5)File.renamethumb_path,current_pathendd
我有一个PORO(普通旧Ruby对象)来处理一些业务逻辑。它接收一个ActiveRecord对象并对其进行分类。为了简单起见,以下面为例:classClassificatorSTATES={1=>"Positive",2=>"Neutral",3=>"Negative"}definitializer(item)@item=itemenddefnameSTATES.fetch(state_id)endprivatedefstate_idreturn1if@item.value>0return2if@item.value==0return3if@item.value但是,我还想根据这些st
我有33个规范以大约5秒的速度运行,以这种速度运行会导致测试套件变慢。我追踪到请求规范(4秒以上),因为模型规范只用了一小部分时间。我已经检查过,我的请求规范没有任何过于复杂或不必要的东西,所以我不知道该去哪里让它们更快,而不是只在推送代码之前运行它们以确保一切正常.加快请求规范的最佳方法是什么? 最佳答案 我使用Spork来加速我的测试。它保持整个环境加载以赢得时间。看看这个博客:http://ykyuen.wordpress.com/2010/12/14/rails-running-rspec-with-spork-test-s
对于一个项目,我需要解析一些非常大的CSV文件。一些条目的内容存储在MySQL数据库中。我正在尝试使用多线程来加快速度,但到目前为止,这只会减慢速度。我解析了一个CSV文件(最大10GB),其中一些记录(20M+记录CSV中的大约5M)需要插入到MySQL数据库中。为了确定需要插入的记录,我们使用Redis服务器和包含正确ID/引用的集合。由于我们在任何给定时间处理大约30个这样的文件,并且存在一些依赖关系,我们将每个文件存储在一个Resque队列中,并让多个服务器处理这些(优先级)队列。简而言之:classWorkerdefself.perform(file)CsvParser.ea
在编译sass时,我的编译时间往往很长(在当前的中型项目中长达9秒),而我的笔记本电脑速度非常快,而且带有ssd。我通过grunt-contrib-sass使用sassass一个grunt任务,但是直接从命令行运行sass时编译时间差别不大。Libsass另一方面,同一个项目只需要大约100毫秒,但它不支持我需要的几个功能。所以我想知道我有什么可能加快编译过程?拆分文件当然有帮助,但是还有其他副作用更小的方法吗?编辑:此外,我也很乐意解释libsass为什么比ruby-sass快得多。不知何故,我非常怀疑这只是因为ruby比C/C++慢得多。还是我错了?编辑2:当我使用Ubun
我使用Octopress作为我的博客引擎。这是完美的。但是如果帖子很多,比如400+,生成速度就很慢了。那么,有什么方法可以加快Jekyll/Octopress的生成速度吗?谢谢。 最佳答案 显然,如果您只处理一篇文章,则无需等待整个站点生成。您正在寻找的是rakeisolate[partial_post_name]任务。使用rakeisolate,您可以仅“隔离”您正在处理的帖子,并将所有其他帖子移至source/_stash文件夹。partial_post_name参数只是帖子文件名中的一些单词。例如,如果我想将帖子与前面的示例
(本题试图找出为什么一个程序在不同的处理器上运行会有所不同,所以它与编程的性能方面有关。)以下程序在配备2.2GHzCore2Duo的Macbook上运行需要3.6秒,在配备2.53GHzCore2Duo的MacbookPro上运行需要1.8秒。这是为什么?这有点奇怪……当CPU的时钟速度仅快15%时,为什么要加倍速度?我仔细检查了CPU仪表,以确保2个内核中没有一个处于100%使用率(以便查看CPU是否忙于运行其他东西)。难道是因为一个是MacOSXLeopard,一个是MacOSXSnowLeopard(64位)?两者都运行Ruby1.9.2。pRUBY_VERSIONpRUBY_
InternetDownloadManager介绍2023最佳下载利器。InternetDownloadManager(简称IDM)是一款Windows平台功能强大的多线程下载工具,国外非常受欢迎。支持断点续传,支持嗅探视频音频,接管所有浏览器,具有站点抓取、批量下载队列、计划任务下载,自动识别文件名、静默下载、网盘下载支持等功能。一款下载器软件,也可以叫它网页嗅探下载工具可以理解为和迅雷差不多,但是没有迅雷那么多广告,而且功能也更加强大(ps:我也是不久前知道迅雷可以下载网页的视频了)。这是一款互联网下载管理器,看着名字挺长的,但它还有一个简称,你一定知道:IDM,在很多论坛技术贴中被称为H
Ruby社区最近出现了大量关于使用更好的OO设计的好处的博客文章、推文和评论,特别是将业务逻辑与持久性逻辑分开。特别是对于较大的应用程序,我认为这是很好的建议。http://solnic.eu/2011/08/01/making-activerecord-models-thin.htmlhttp://blog.steveklabnik.com/2011/09/06/the-secret-to-rails-oo-design.htmlhttp://avdi.org/devblog/2011/11/15/early-access-beta-of-objects-on-rails-now-a