本章开始学习springboot整合ElasticSearch 7.X版本并通过小demo实现基本的增删改查。实现如下案例:
1、当向数据新增一个商品信息时,同时向rabbitMQ发起消息(异步实现),让监听到消息的类去向ElasticSearch 也新增这个商品信息。
2、当去修改数据库的商品信息时,同时向rabbitMQ发起消息(异步实现),让监听到消息的类去向ElasticSearch 也去修改这个商品信息。
3、当删除数据库的商品信息时,同时也向rabbitMQ发起消息(异步实现),让监听到消息的类去向ElasticSearch 也去删除这个商品信息。
4、实现ElasticSearch的条件查询。
5、实现ElasticSearch的分页查询。
6、实现ElasticSearch的条件+分页查询。
7、实现ElasticSearch的高亮显示与查询条件相符合的值。
8、实现ElasticSearch的高亮显示与查询条件相符合的值并分页和排序。
最终效果:
qq交流群导航——>231378628
注意: 本章整合的ElasticSearch下载的客户端是windows版本,然后现在时间是2022.3.31。
官网提供的最新最新版本是8.1.1。最新版的使用跟以前7.X版本的完全不同,网上学习资料太少了,不得不降低版本学习7.X,本章节的学习下载的是elasticsearch-7.3.2,尝试了8.1.1的学习,问题实在是太多了,能力卑微,先不强求自己了。
注意:客户端下载的什么版本最好别去下最新版本,太难搞了。
学习路线:
二、下载安装elasticsearch图像化插件(elasticsearch-head-master)
十一、实现ElasticSearch 高亮显示与查询条件相符合的值
十二、实现ElasticSearch的高亮显示与查询条件相符合的值并分页和排序
下载本章节所用版本:
安装完成elasticsearch之后,需要安装一个插件去图形化操作elasticsearch,教程上讲的需要先下载node,然后用node自带的npm下载grunt,随后去修改一下elasticsearch的配置文件即可通过9100端口访问图形界面,教程如下:
执行命令运行head插件。

ES双击elasticsearch-7.3.2\bin目录下的elasticsearch.bat即可。
启动后长这个样子(启动时若会提示需要密码,这时需要去修改elasticsearch的配置文件)。


为了测试上述功能,先建立一个父子工程,在学习RabbitMQ和KafKa时都有建过,直接拿来使用,如下:

在开始之前,先做好准备工作,如下:
1、构建好父子模块的关系:
此处不讲了,在前面的章节有讲过。
2、在父工程引入所需依赖
此次学习需要用到mybatis-plus和rabbitMQ和elasticsearch,所有依赖情况如下:

我的springboot版本是:2.6.4,其他依赖不加版本会根据springboot版本去自动匹配版本导入。
3、provider的配置文件

4、consumer的配置文件
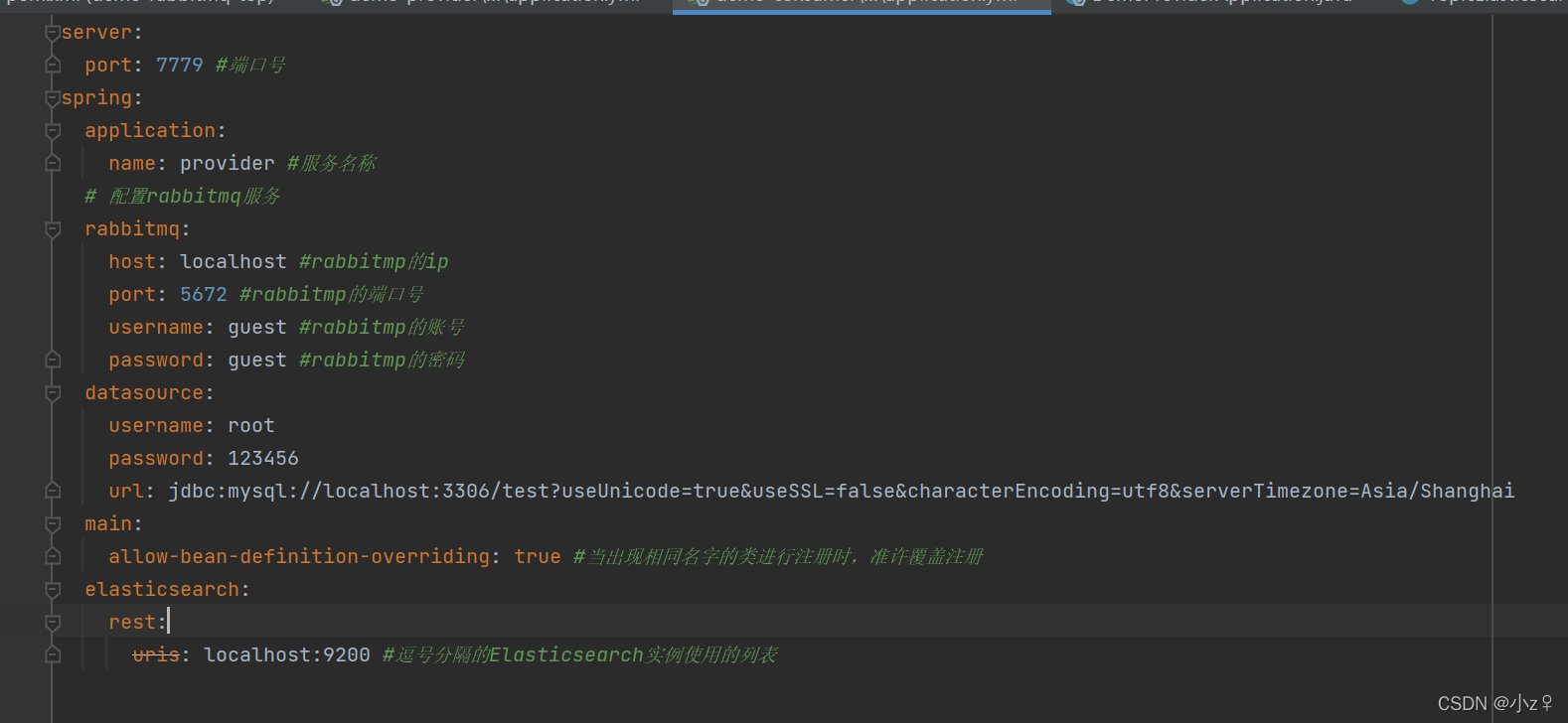
两者配置文件差不多,主要就是连接rabbitmq和elasticsearch,上图main:allow-bean-definition-overriding: true是我在测试时的一个报错,根据报错的一个bean的重复解决方案。
注意:版本不一样,连接elasticsearch的写法不一样,高版本好像最基本的配置不需要了。
5、mysql表如下:

6、common模块代码如下:
 此处我的这个实体类有两个用处:
此处我的这个实体类有两个用处:
7、在消费者模块准备rabbitMQ的绑定配置类

@Configuration
public class TopicElasticSearchConfig {
@Bean
public TopicExchange saveExchange() {
return new TopicExchange("es_save_exchange", true, false);
}
@Bean
public TopicExchange deleteExchange() {
return new TopicExchange("es_delete_exchange", true, false);
}
@Bean
public Queue esSaveQueue() {
return new Queue("es.save.queue", true);
}
@Bean
public Queue esDeleteQueue() {
return new Queue("es.delete.queue", true);
}
@Bean
public Binding esSaveBinding() {
return BindingBuilder.bind(esSaveQueue()).to(saveExchange()).with("es");
}
@Bean
public Binding esDeleteBinding() {
return BindingBuilder.bind(esDeleteQueue()).to(deleteExchange()).with("es");
}
}
建立一个接收修改和新增消息的交换机(因为对于elasticsearch来说,新增和修改方法一样),再建立一个接收删除消息的交换机,建立两个队列和绑定,如上图。
8、建立消费端的监听器

 监听上面建立的两个队列。
监听上面建立的两个队列。
9、建立mybatis-plus所需要的mapper层

10、建立测试用controller
准备工作完成。
要实现向mysql数据库新增数据的同时通过rabbitMQ接收消息然后向elasticsearch也插入数据,所以实现如下:
先在controller编写新增接口
 向数据库新增数据,同时向rabbitmq发送新增的消息。
向数据库新增数据,同时向rabbitmq发送新增的消息。
然后再新增消息队列监听器编写向elasticsearch新增数据的逻辑。
 操作elasticsearch是通过继承Repository接口完成的,在消费者服务和生产者服务都新增如下类
操作elasticsearch是通过继承Repository接口完成的,在消费者服务和生产者服务都新增如下类

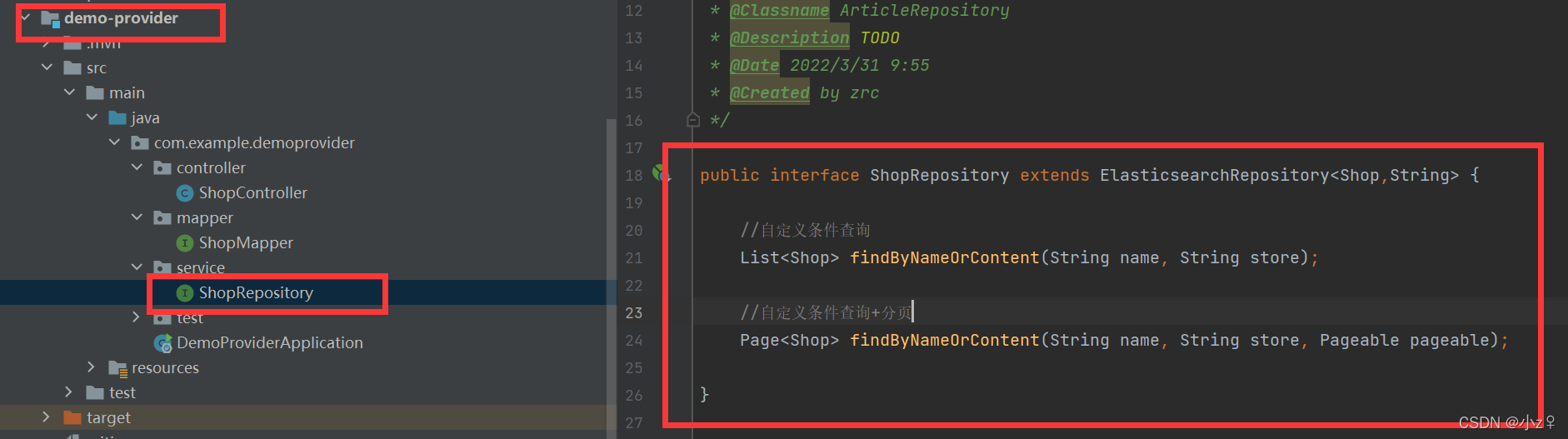
里面自定义的方法是后面所用到的,继承ElasticsearchRepository接口后默认提供了最基本的增删改查操作,类似Mybatis-plus的BaseMapper。
ElasticsearchRepository可以直接调用save方法进行报错。
结果如下:



同步保存成功。
elasticsearch的修改操作也是调用Repository的save方法,若传入的id已存在则是执行修改,若传入的id不存在,则是新增。代码如下:

同样在controller里加上修改接口,然后向数据修改,然后发送消息到MQ,然后再MQ的队列监听器进行处理。
 还是上面的新增逻辑,原因已经讲了。
还是上面的新增逻辑,原因已经讲了。
查看效果:
 这是原来的数据。
这是原来的数据。
 调用接口后,这是现在的数据
调用接口后,这是现在的数据


修改成功。
删除跟新增修改差不多,代码如下:
controller新增删除接口。

在删除队列监听器处理elasticsearch的删除方法。

测试结果删除成功。
后面就只针对provider服务实现了,不通过MQ了。
基本的增删改完了,然后一步一步的实现各种查询操作,指令实现基本的条件查询,如下。
新增条件查询测试接口。
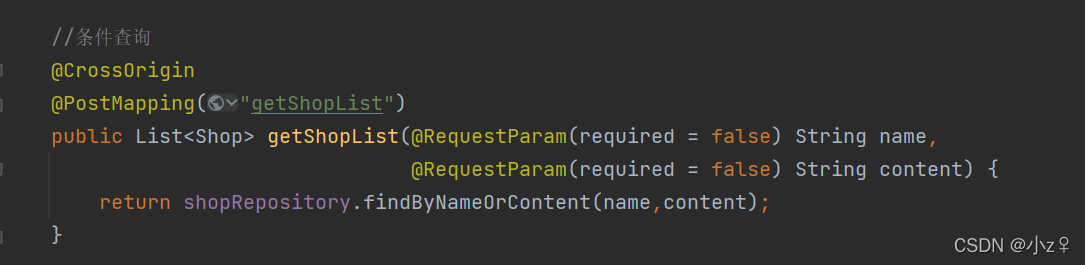
根据name和content模糊查询,采用自定义查询语句的方式实现,这里要注意Repository的写法。

根据什么查询就写findBy什么然后加字段名And或者Or之类的,然后写下一个字段名,这里只学习了最基本的使用,详细的就不展开了,后面再面向百度学习,然后方法传入的参数会根据参数位置一一匹配方法名前面写的字段名,Repository会自动生成查询语句。
测试结果如下:

条件查询成功。
然后实现一下分页查询,需要用到Pageable类,提供分页参数,Repository的方法支持这个类来查询,代码如下:
依旧新增一个测试接口。

测试结果:

测试成功。注意:Pageable默认的入参是第0页,按每页20条查询。网上有说默认是(0,10),可能是该类的版本不同,我用的版本是默认0,20。对于elasticsearch来说是先从0开始的。还要注意传参是page和size,别写错了。返回的Page数据结构如下:

当完成了分页查询和条件查询,下面写一个接口同时满足上面两个,代码如下。

新增一个测试接口,然后同时传入查询条件和分页参数,重载一个刚才的方法,修改入参和返回值。

测试结果如下。
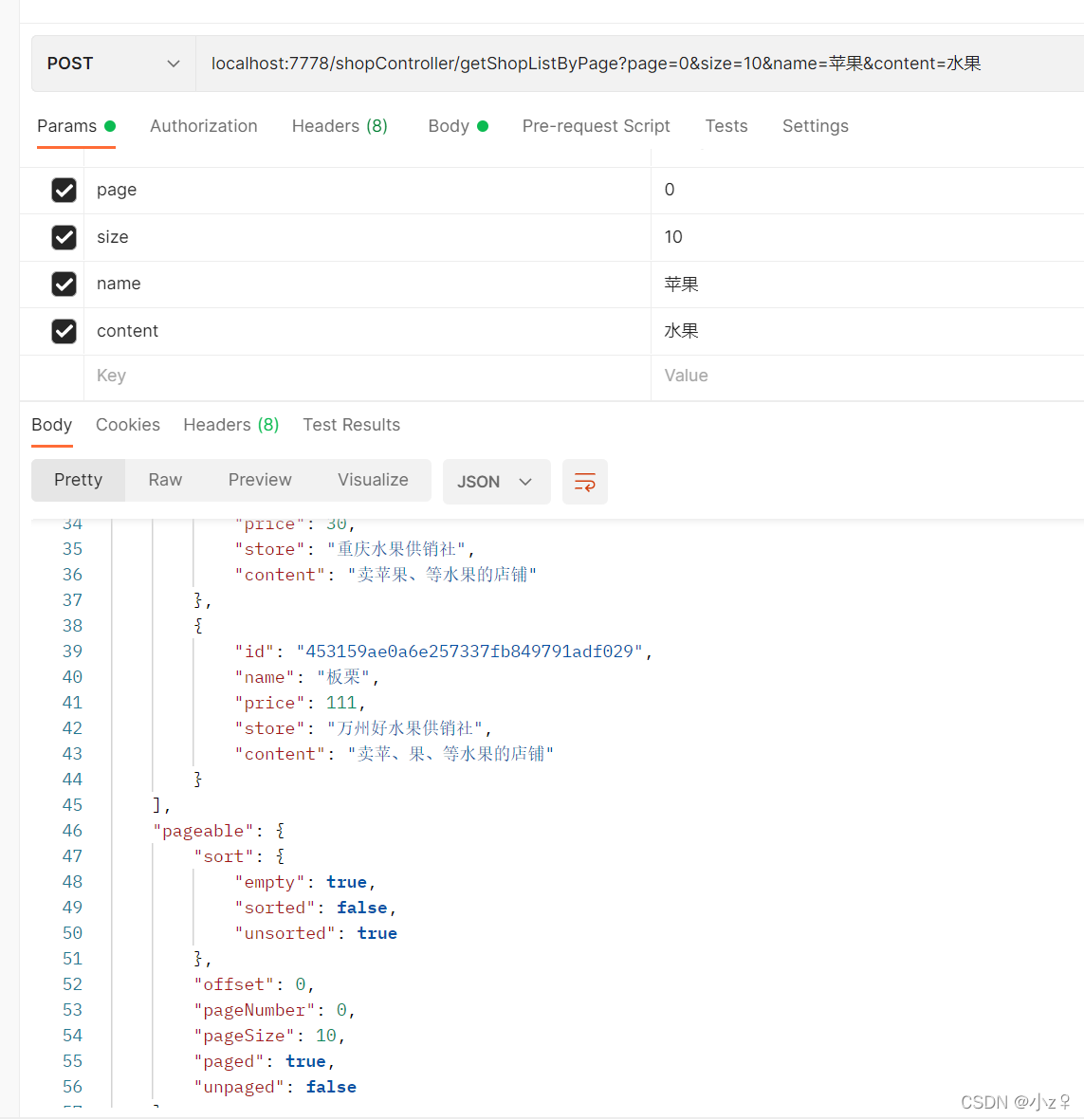
测试成功。
下面简单实现一个elasticsearch的特色,高亮显示。当我们在百度搜索时,例如搜索牛批。

它能够高亮显示搜索到的信息中所匹配的值,下面通过elasticsearch简单实现一下,代码如下。
//高亮显示
@CrossOrigin
@GetMapping("getLightShopList")
public List<Shop> getLightShopList(@RequestParam(required = false) String name) {
//构建查询条件,只要name或者content其中一个满足传入的name的查询条件即可
// QueryBuilder queryBuilder1 = new MatchQueryBuilder("name", name);
// QueryBuilder queryBuilder2 = new MatchQueryBuilder("content", name);
//上面这样写只能用到最后一个,要下面这样写,组合查询
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("name", name))
.should(QueryBuilders.matchQuery("content", name));
//查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
//添加高亮显示字段
.withHighlightFields(
new HighlightBuilder.Field("name")
, new HighlightBuilder.Field("content"))
//自定义高亮显示颜色
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:yellow'>").postTags("</span>"))
.build();
//开始查询
SearchHits<Shop> search = elasticsearchRestTemplate.search(searchQuery, Shop.class);
//得到查询返回的内容
List<SearchHit<Shop>> searchHits = search.getSearchHits();
//设置一个最后需要返回的实体类集合
List<Shop> shops = new ArrayList<>();
//遍历返回的内容进行处理
for (SearchHit<Shop> searchHit : searchHits) {
//高亮的内容
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
//将高亮的内容填充到content中
searchHit.getContent().setName(highlightFields.get("name") == null ? searchHit.getContent().getName() : highlightFields.get("name").get(0));
searchHit.getContent().setContent(highlightFields.get("content") == null ? searchHit.getContent().getContent() : highlightFields.get("content").get(0));
//放到实体类中
shops.add(searchHit.getContent());
}
return shops;
}上面的例子都是通过Repository提供的APi方法实现的,高亮显示通过它加上注解好像也可以实现,上面的方法是引入elasticsearchRestTemplate来实现的。
测试结果如下:


name和content字段中,相匹配的就会查询出来并高亮显示。具体的匹配规则和优先级都是可以设置的。
完成了最基本的高亮显示,最后再同时整点分页和排序。
代码如下。
//高亮显示+分页+条件+排序
@CrossOrigin
@GetMapping("getLightShopByPageList")
public Map getLightShopByPageList(@RequestParam(required = false) String name,Pageable pageable) {
//组合查询
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("name", name))
.should(QueryBuilders.matchQuery("content", name));
//构建排序,如果实体类上该字段没有加type,这里排序字段上面要加keyword,不然会报错。
// FieldSortBuilder priceSortBuilder = SortBuilders.fieldSort("price.keyword").order(SortOrder.ASC);
FieldSortBuilder priceSortBuilder = SortBuilders.fieldSort("price").order(SortOrder.ASC);
//查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(queryBuilder)
//添加高亮显示字段
.withHighlightFields(new HighlightBuilder.Field("name"), new HighlightBuilder.Field("content"))
//自定义高亮显示颜色
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:yellow'>").postTags("</span>"))
.withPageable(pageable)
.withSorts(priceSortBuilder)
.build();
//开始查询
SearchHits<Shop> search = elasticsearchRestTemplate.search(searchQuery, Shop.class);
//得到查询返回的内容
List<SearchHit<Shop>> searchHits = search.getSearchHits();
//设置一个最后需要返回的实体类集合
List<Shop> shops = new ArrayList<>();
//遍历返回的内容进行处理
for (SearchHit<Shop> searchHit : searchHits) {
//高亮的内容
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
//将高亮的内容填充到content中
searchHit.getContent().setName(highlightFields.get("name") == null ? searchHit.getContent().getName() : highlightFields.get("name").get(0));
searchHit.getContent().setContent(highlightFields.get("content") == null ? searchHit.getContent().getContent() : highlightFields.get("content").get(0));
//放到实体类中
shops.add(searchHit.getContent());
}
Map map = new HashMap();
map.put("currentPageSIze",pageable.getPageSize());
map.put("currentNumber",pageable.getPageNumber());
map.put("content",shops);
return map;
}对比上一个就是增加了排序和分页,所有直接在上面改动了。
注意:排序时,若实体类上price字段没加@Field(type = FieldType.Integer), 查询会报错,在查询时查询字段必须写成price.keyword,否则就必须在实体类上加@Field注解,不然请求接口测试会报elasticsearch的错。若一个分区的数据(不设置默认在一个分区),若存在price数据不是同种类型,排序也会失效,不知道对不对,反正我测试时遇到了这个问题,后面测试时把前面该索引(shop)直接删了重新来过的(为了保证price类型一致)。
测试结果如下。

若修改成SortOrder.DESC。

查看排序成功。
(2022.4.3新增)上面是通过elasticsearchRestTemplate的方法实现的,下面简单使用注解方式实现一下:
修改Repository类:

仍然借助Repository自动给我们生成查询语句,不同的是,我们自定义高亮显示字段,配合Highlight注解、HighlightField注解、HighlightParameters注解实现。
controller层新增测试接口:
然后写了一个简单的前端界面进行测试。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous">
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.5.1/jquery.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script>
<body>
<div class="row" style="margin-left: 30%;margin-top: 30px;">
<div class="col-lg-6">
<div class="input-group">
<div class="input-group-prepend">
<span class="input-group-text " id="basic-addon1">名称</span>
</div>
<input type="text" class="form-control name" placeholder="搜索">
<div class="input-group-prepend" style="margin-left: 20px;">
<span class="input-group-text " id="basic-addon1">内容</span>
</div>
<input type="text" class="form-control content" placeholder="搜索">
<span class="input-group-btn">
<button class="btn btn-primary" type="button" onclick="fun1()">搜索</button>
</span>
</div><!-- /input-group -->
</div><!-- /.col-lg-6 -->
</div><!-- /.row -->
<div class="neirong" style="width: 100%;height: 500px;background-color: aliceblue;display: flex;justify-content: center;">
</div>
</body>
<script>
function fun1(){
console.log("点击");
$.ajax({
url:"http://localhost:7778/shopController/hightLightShow2",
data:{"page":"0","size":"10","name":$(".name").val(),"content":$(".content").val()},
type:"get",
dataType: "json",
success: function(data) {
$(".neirong").html('');
console.log(data);
var html="";
for(var i=0;i<data.length;i++){
name = data[i].highlightFields.name==undefined?data[i].content.name:data[i].highlightFields.name
content = data[i].highlightFields.content==undefined?data[i].content.content:data[i].highlightFields.content
html = html+`
<div class="card" style="width: 18rem;height:18rem;margin-right:10px">
<div class="card-body">
<h5 class="card-title">`+name+`</h5>
<p class="card-text">`+content+`</p>
<a href="#" class="btn btn-primary">购买</a>
</div>
</div>
`
}
$(".neirong").append(html);
}
});
}
</script>
</html>
最终效果就是下图这个样子:

后面继续学习elasticsearch。
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
