start tag)到结束标签(end tag)的所有代码。find_element或find_elements 方法来定位元素。
find_element使用给定的方法定位和查找一个元素find_elements使用给定的方法定位和查找所有元素,并以列表(list)的形式返回。(1)By_id
说明:
当所定位的元素具有id属性的时候我们可以通过by_id来定位该元素。
例如:打开百度首页,定位搜索框。
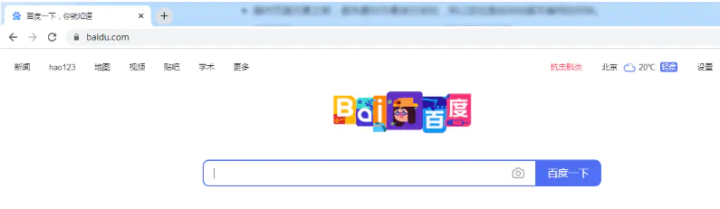
搜索框页面源代码:属性id值为kw。
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="255" autocomplete="off">
示例:
"""
1.学习目标
必须掌握selenium中元素定位方法,id定位方法
2.操作步骤(语法)通过元素id属性定位
driver.find_element_by_id(id属性的值)
3.需求
在百度页面中使用id属性定位百度输入框
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器(获取浏览器对象)
driver = webdriver.Chrome()
# 3.输入网址
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.元素定位(id定位方法),百度输入框
"""
注意:
如果有多个相同属性值的元素,单数形式,定位第一个.
"""
srk = driver.find_element_by_id("kw")
# 打印srk对象
print(srk)
# 查看元素对应的源码
print(srk.get_attribute("outerHTML"))
# 5.关团浏览器
driver.quit()
"""
输出结果:
<selenium.webdriver.remote.webelement.WebElement
(session="6fbad6d63614e1cae6cd346153a7105e",
element="0dd374b6-74ed-4f4c-b610-5c772fd8c366")>
我们可以看到srk是一个WebElement类型的对象。
查看元素对应的源码如下:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
说明我们已经把百度首页的输入框获取到了。
"""
复数形式:
"""
学习目标
复数形式
复数定位形式:driver.find_elements_XXX
复数定位,返回的列表类型数据<list>
遍历列表操作具体元素
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.输入网址
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.通过by_id复数定位
srk = driver.find_elements_by_id("kw")
# 5.查看返回结果数据类型
print("结果数据类型", type(srk))
print("元素个数", len(srk))
# 6.遍历结果,查看源码
for i in srk:
# 查看元素对应的源码
print(i.get_attribute("outerHTML"))
# 7.关团浏览器
driver.quit()
"""
结果数据类型 <class 'list'>
元素个数 1
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
"""
异常总结:
异常1:
AttributeError:'list' object has no attribute 'get_attribute' :
表示定位元素返回的是一个列表格式,原因:使用复数定位方式 find_elements获取的定位
异常2
NoSuchElementException :
表示元素没找到元素,原因是定位方式出现问题,有一种情况是属性值写错了。
(2)by_name
说明:
当所定位的元素具有name属性的时候,我们可以通过by_name来定位该元素。
如上图中的百度搜索页面
搜索框页面源代码:属性name值为wd
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
示例:
使用name属性定位百度搜索框
"""
1.学习目标:
必须掌握selenium的元素定位方法by_name
2.语法
name定位
driver.find_element_by_name(name属性的值)
3.需求
使用name属性定位百度搜索框
4.总结
当元素中有name属性时才能使用上述定位方法
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器(获取浏览器对象)
driver = webdriver.Chrome()
# 3.输入网址
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4. 使用name定位百度搜索框
"""
注意:
如果有多个相同属性值的元素,单数形式,定位第一个.
"""
srk = driver.find_element_by_name("wd")
# 打印srk对象
print(srk)
# 打印定位元素所在行的源码
print(srk.get_attribute("outerHTML"))
# 5.关闭浏览器
driver.quit()
"""
输出结果:
<selenium.webdriver.remote.webelement.WebElement
(session="3149d334336f0eab9e4d8d394e4efd72",
element="0.1359081202533734-1")>
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
"""
复数形式:
"""
学习目标
复数形式
复数定位形式:driver.find_elements_XXX
复数定位,返回的列表类型数据<list>
遍历列表操作具体元素
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.输入网址
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.通过by_id复数定位
srk = driver.find_elements_by_name("wd")
# 5.查看返回结果数据类型
print("结果数据类型", type(srk))
print("元素个数", len(srk))
# 6.遍历结果,查看源码
for i in srk:
# 查看元素对应的源码
print(i.get_attribute("outerHTML"))
# 7.关团浏览器
driver.quit()
"""
结果数据类型 <class 'list'>
元素个数 1
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
"""(3)by_class_name
说明:
当所定位的元素具有class属性的时候,我们可以通过by_class_name来定位该元素。
搜索框页面源代码:属性classname值为s_ipt
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="255" autocomplete="off">
示例:
使用class属性定位百度搜索框
"""
1.学习目标:
必须掌握selenium的元素定位方法by_class_name
2.语法
classname定位
driver.find_element_by_class_name(class属性值)
3.需求
使用class属性定位百度搜索框
4.总结
当元素中有class属性时才能使用上述定位方法
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器(获取浏览器对象)
driver = webdriver.Chrome()
# 3.输入网址
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4. 使用name定位百度搜索框
"""
注意:
如果有多个相同属性值的元素,单数形式,定位第一个.
"""
srk = driver.find_element_by_class_name("s_ipt")
# 打印srk对象
print(srk)
# 查看元素对应的源码
print(srk.get_attribute("outerHTML"))
# 5.关闭浏览器
driver.quit()
"""
输出结果:
<selenium.webdriver.remote.webelement.WebElement
(session="e4f97a48e7f113e681950b62c7789966",
element="0.5782514739919584-1")>
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
"""
复数形式:
"""
学习目标
复数形式
复数定位形式:driver.find_elements_XXX
复数定位,返回的列表类型数据<list>
遍历列表操作具体元素
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.输入网址
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.通过by_id复数定位
srk = driver.find_elements_by_class_name("s_ipt")
# 5.查看返回结果数据类型
print("结果数据类型", type(srk))
print("元素个数", len(srk))
# 6.遍历结果,查看源码
for i in srk:
# 查看元素对应的源码
print(i.get_attribute("outerHTML"))
# 7.关团浏览器
driver.quit()
"""
结果数据类型 <class 'list'>
元素个数 1
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
"""
(4)by_tag_name
说明:
by_tag_name方法可以通过元素的标签名来查找元素。由于搜索到的标签名通常不止一个,所以一般结合使用find_elements方法来使用。
假设页面中有一个bitton按钮
<button type="submitA" value="注册A" title="加入会员A">注册用户A</button>
示例:
"""
1.学习目标:
必须掌握selenium中tag_name定位方法
2.语法
driver.find_element_by_tag_name(标签名) # 单数形式
driver.find_elements_by_tag_name(标签名) # 定位一组标签名相同的元素
3.需求
在页面中,使用tag_name对按钮注册用户A定位
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器(获取浏览器对象)
driver = webdriver.Chrome()
# 3.打开注册A页面
url = "file:///" + os.path.abspath("./练习页面/注册A.html")
driver.get(url)
sleep(2)
# 4.使用tag_name定位按钮
"""
注意:
如果有多个相同标签的元素,单数形式,定位第一个.
"""
button = driver.find_element_by_tag_name("input")
print(button.get_attribute("outerHTML"))
# 5.关闭浏览器
sleep(2)
driver.quit()
"""
输出结果:
<input type="textA" name="userA" id="userA" placeholder="账号A" required="" value="">
"""
复数形式:
"""
1.学习目标:
必须掌握selenium中tag_name定位方法
2.语法
driver.find_element_by_tag_name(标签名) # 单数形式
driver.find_elements_by_tag_name(标签名) # 定位一组标签名相同的元素
3.需求
在页面中,使用tag_name复数形式定位 input标签
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开注册A页面
url = "file:///" + os.path.abspath("./练习页面/注册A.html")
driver.get(url)
sleep(2)
# 4.使用tag_name复数形式定位 input标签
input_elements = driver.find_elements_by_tag_name("input")
# 查看结果类型
print(type(input_elements))
print(len(input_elements))
# 5.遍历列表打印每个元素的源码
for element in input_elements:
print(element.get_attribute("outerHTML"))
# 6.关闭浏览器
driver.quit()
"""
输出结果:
<class 'list'>
16
<input type="textA" name="userA" id="userA" placeholder="账号A" required="" value="">
<input type="password" name="passwordA" id="passwordA" placeholder="密码A" value="">
<input type="telA" name="telA" id="telA" placeholder="电话A" class="telA" value="">
<input type="emailA" name="emailA" id="emailA" placeholder="电子邮箱A" value="">
......等等
"""
总结:
tag_name定位:
单数方式
当页面中如果定位的标签是唯一的,可以直接使用
tag_name方法定位。如果所定位的标签在页面中的索引位置是第一个,也可以用
tag_name方法定位。复数形式
复数定位形式:
driver.find_elements_XXX。复数定位,返回的列表类型数据。
遍历列表操作具体元素。
(5)by_link_text
说明:
by_link_text通过超文本链接上的文字信息来定位元素,这种方式一般专门用于定位页面上的超文本链接。
例如打开百度首页,定位点击超链接地图。
超链接地图源代码:
<a class="mnav" name="tj_trmap" href="http://map.baidu.com">地图</a>
示例:
脚本代码需求:使用link_text定位百度首页地图链接
"""
1.学习目标:
必须掌握selenium中超链接的定位方法
2.语法
link_text # 需要链接的全部文本
driver.find_element_by_link_text(全部文本)
3.需求
在页面中,使用定位连接的方法,访问百度网站,定位点击超链接地图。
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.使用link_text定位
"""
注意:
连接的全部文本,表示<a>标签中的全部内容,有空格也要算。
如果有相同部分文本的元素,单数形式,定位第一个。
"""
linkText = driver.find_element_by_link_text("地图")
print(linkText.get_attribute("outerHTML"))
# 5.关闭浏览器
driver.quit()
"""
输出结果:
<a href="http://map.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">地图</a>
"""
复数形式:
# 定位一组标超链接文本全部内容相同的元素,很少用到。
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.使用link_text定位
"""
注意:
连接的全部文本,表示<a>标签中的全部内容,有空格也要写。
"""
linkText = driver.find_elements_by_link_text("地图")
# 5.遍历列表打印每个元素的源码
for element in linkText:
print(element.get_attribute("outerHTML"))
# 6.关闭浏览器
driver.quit()
"""
输出结果:
<a href="http://map.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">地图</a>
"""
(6)by_partial_link_text
说明:
当你不能准确知道超链接上的文本信息或者只想通过一些关键字进行匹配时,可以使用by_partial_link_text这个方法来通过部分链接文字进行匹配。
例如打开百度首页,定位点击超链接<hao123>。
超链接地图源代码:在代码里用”ao1”进行匹配
<a href="https://www.hao123.com" target="_blank" class="mnav c-font-normal c-color-t">hao123</a>
示例:
脚本代码:使用partial_link_text方法定位百度首页<hao123>链接
"""
1.学习目标:
必须掌握selenium中超链接的定位方法
2.语法
partial_link_text # 需要连接部分文本
driver.find_element_by_partial_link_text(部分文本)
部分文本必须是连续的文字(中可包含空格)
3.需求
在页面中,使用定位连接的方法,访问百度网站,定位点击超链接<hao123>。
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.使用by_partial_link_text定位
"""
注意:
连接的部分文本,表示<a>标签中的连续的部分内容,之中有空格也要算。
如果有相同部分文本的元素,单数形式,定位第一个。
"""
pLinkText = driver.find_element_by_partial_link_text("ao1")
print(pLinkText.get_attribute("outerHTML"))
# 6.关闭浏览器
sleep(2)
driver.quit()
"""
输出结果:
<a href="https://www.hao123.com" target="_blank" class="mnav c-font-normal c-color-t">hao123</a>
"""
复数形式:
# 定位一组标超链接文本目标内容相同的元素,很少用到。
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.使用by_partial_link_text定位
"""
注意:
连接的部分文本,表示<a>标签中的连续的部分内容,之中有空格也要算。
"""
pLinkText = driver.find_elements_by_partial_link_text("ao1")
# 5.遍历列表打印每个元素的源码
for element in pLinkText:
print(element.get_attribute("outerHTML"))
# 6.关闭浏览器
driver.quit()
"""
输出结果:
<a href="https://www.hao123.com" target="_blank" class="mnav c-font-normal c-color-t">hao123</a>
"""这个大纲涵盖了目前市面上企业百分之99的技术,这个大纲很详细的写了你该学习什么内容,企业会用到什么内容。总共十个专题足够你学习

这里我准备了对应上面的每个知识点的学习资料、可以自学神器,已经项目练手。





最后送上一句话:
世界的模样取决于你凝视它的目光,自己的价值取决于你的追求和心态,一切美好的愿望,不在等待中拥有,而是在奋斗中争取。
如果我的博客对你有帮助、如果你喜欢我的文章内容,请 “点赞” “评论” “收藏” 一键三连哦

查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我是HanamiWorld的新人。我已经写了这段代码:moduleWeb::Views::HomeclassIndexincludeWeb::ViewincludeHanami::Helpers::HtmlHelperdeftitlehtml.headerdoh1'Testsearchengine',id:'title'hrdiv(id:'test')dolink_to('Home',"/",class:'mnu_orizontal')link_to('About',"/",class:'mnu_orizontal')endendendendend我在模板上调用了title方法。htm
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1