 想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.comCentOS社区还存不存在?CentOS项目还存不存在?众多CentOS用户将何去何从?伴随CentOS停更,大家可能会有这样那样的疑问,今天针对以上问题,我来进行一一解答。CentOS实际上有两个变种,一个叫做CentOS Linux,另外一个叫CentOS Stream。CentOS Linux出现比较早,大家所知道的CentOS都是CentOS Linux。而CentOS Stream是两年前红帽对外推出的,推出CentOS Stream之后就相当于把CentOS Linux逐渐做了升级换代。这就好比是,你过去用的是iphone4,现在是iphone5,相当于是一个升级换代,换代之后主打的名字也发生了一些变化——从CentOS Linux到CentOS Stream,后面我会讲到,这个变化本身是跟开源开发模式的演进,以及市场需求的变化有关系的。接下来我相信大家还会有其他的一些疑虑,比如CentOS Linux到CentOS Stream是不是稳定的?我先简单一句话回答,它是稳定的。具体怎么稳定,听我一点点给大家引出来后面的一些细节。
想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.comCentOS社区还存不存在?CentOS项目还存不存在?众多CentOS用户将何去何从?伴随CentOS停更,大家可能会有这样那样的疑问,今天针对以上问题,我来进行一一解答。CentOS实际上有两个变种,一个叫做CentOS Linux,另外一个叫CentOS Stream。CentOS Linux出现比较早,大家所知道的CentOS都是CentOS Linux。而CentOS Stream是两年前红帽对外推出的,推出CentOS Stream之后就相当于把CentOS Linux逐渐做了升级换代。这就好比是,你过去用的是iphone4,现在是iphone5,相当于是一个升级换代,换代之后主打的名字也发生了一些变化——从CentOS Linux到CentOS Stream,后面我会讲到,这个变化本身是跟开源开发模式的演进,以及市场需求的变化有关系的。接下来我相信大家还会有其他的一些疑虑,比如CentOS Linux到CentOS Stream是不是稳定的?我先简单一句话回答,它是稳定的。具体怎么稳定,听我一点点给大家引出来后面的一些细节。 Linux发行版有社区版、企业版,我们主要讲有了企业需求之后,Linux发展的几大阶段。
Linux发行版有社区版、企业版,我们主要讲有了企业需求之后,Linux发展的几大阶段。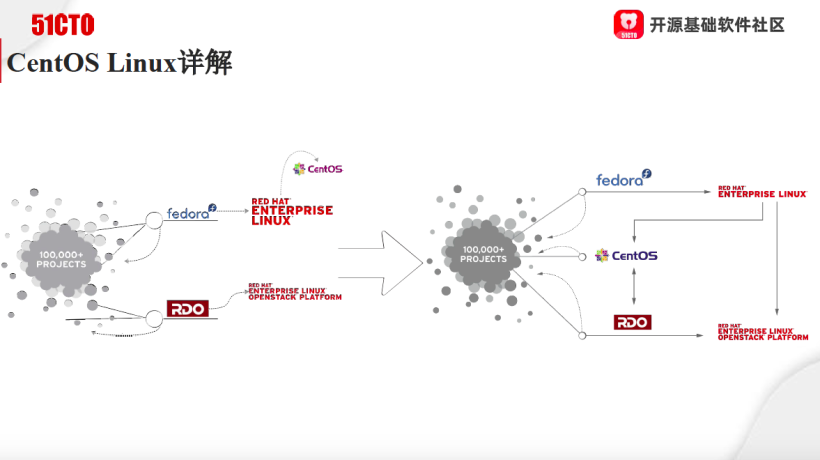 所以我刚才讲的这一段历史,就是上边这幅图里所展现的。但是我相信可能我们有好多朋友了解CentOS,可能只知道左边这一部分——我们知道RHEL红帽企业级Linux是来自于Fedora的,可以说Fedora是RHEL的试验场。CentOS是基于RHEL出现的一个下游复刻版本,跟RHEL近乎是一样的,所以它的稳定性是毫不怀疑的。但是右边这一部分很多人不了解——实际上当云、虚拟化这些成为一个主要的应用负载的时候,我们会发现其实CentOS里面的东西已经不仅仅是RHEL里面的东西了,它里面还有大量来自于RDO的东西,RDO是红帽的OpenStack社区版。有很多像比如虚拟化,像Libvirt、oVirt,类似于这样的东西也加到了CentOS里面。所以坦白讲,CentOS里面并不光是红帽企业级的Linux包,它还包括很多其他的包。坦白讲,其他的包在CentOS里面,它的品质就应该不如RHEL了,因为RHEL是经过严格测试的,对于像社区版里的RDO里面的东西并不是严格测试的。但是RDO这个东西,社区版的OpenStack经过严格测试之后,生成红帽企业版的OpenStack,这是严格测试的。所以在CentOS里面我们看这个箭头的指向,它一方面有RHEL里稳定的操作系统的包,同时也有关于云方面的、从测试各方面看没有那么稳定的包在CentOS Linux里面,实际上这是CentOS Linux那个时代的模式。
所以我刚才讲的这一段历史,就是上边这幅图里所展现的。但是我相信可能我们有好多朋友了解CentOS,可能只知道左边这一部分——我们知道RHEL红帽企业级Linux是来自于Fedora的,可以说Fedora是RHEL的试验场。CentOS是基于RHEL出现的一个下游复刻版本,跟RHEL近乎是一样的,所以它的稳定性是毫不怀疑的。但是右边这一部分很多人不了解——实际上当云、虚拟化这些成为一个主要的应用负载的时候,我们会发现其实CentOS里面的东西已经不仅仅是RHEL里面的东西了,它里面还有大量来自于RDO的东西,RDO是红帽的OpenStack社区版。有很多像比如虚拟化,像Libvirt、oVirt,类似于这样的东西也加到了CentOS里面。所以坦白讲,CentOS里面并不光是红帽企业级的Linux包,它还包括很多其他的包。坦白讲,其他的包在CentOS里面,它的品质就应该不如RHEL了,因为RHEL是经过严格测试的,对于像社区版里的RDO里面的东西并不是严格测试的。但是RDO这个东西,社区版的OpenStack经过严格测试之后,生成红帽企业版的OpenStack,这是严格测试的。所以在CentOS里面我们看这个箭头的指向,它一方面有RHEL里稳定的操作系统的包,同时也有关于云方面的、从测试各方面看没有那么稳定的包在CentOS Linux里面,实际上这是CentOS Linux那个时代的模式。[root@centos ~]# dnf swap centos-linux-repos centos-stream-repos
[root@centos ~]# dnf distro-sync 但是对于CentOS Stream和RHEL来讲就不会,因为这两个东西是基于Fedora某一个特定版本,比如基于Fedora28,我要做一个稳定的企业版,我拉一个分支出来。但这个稳定版有些新的功能会加入进来,这个加入进来叫Backport,Backport是说我需要一些新的特性、Bug fix,而不是说一股脑的把所有东西都加过来。
但是对于CentOS Stream和RHEL来讲就不会,因为这两个东西是基于Fedora某一个特定版本,比如基于Fedora28,我要做一个稳定的企业版,我拉一个分支出来。但这个稳定版有些新的功能会加入进来,这个加入进来叫Backport,Backport是说我需要一些新的特性、Bug fix,而不是说一股脑的把所有东西都加过来。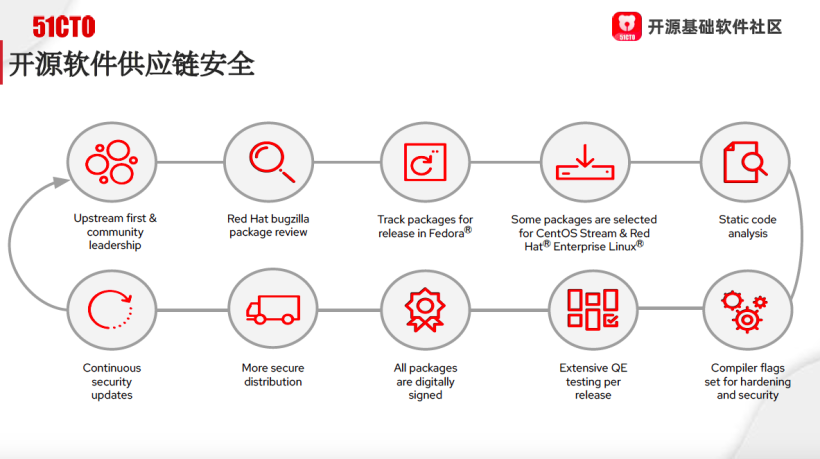 这个过程我们会发现跟现在的DevSecOps的理念很像,我们不能保证你进来的时候一定没有漏洞,我们的目的是打造一个对开源软件供应链安全提供保障的闭环。第一步,我们在UpStream阶段肯定有一个甄选和识别,是不是存在一些恶意的代码成分呢?甄别出后,是不是有一个规范的流程可以帮助我们去选;选完之后,我们打包对它进行测试;到最后你的传播过程中,是不是有一些很好的校验手段;特别是最关键的,到最后一步我们已经把这个东西给到用户,但我们出现问题的时候,是不是能够有效的去解决。所以我们认为开源软件的供应链安全,实际上主要是技术问题。
这个过程我们会发现跟现在的DevSecOps的理念很像,我们不能保证你进来的时候一定没有漏洞,我们的目的是打造一个对开源软件供应链安全提供保障的闭环。第一步,我们在UpStream阶段肯定有一个甄选和识别,是不是存在一些恶意的代码成分呢?甄别出后,是不是有一个规范的流程可以帮助我们去选;选完之后,我们打包对它进行测试;到最后你的传播过程中,是不是有一些很好的校验手段;特别是最关键的,到最后一步我们已经把这个东西给到用户,但我们出现问题的时候,是不是能够有效的去解决。所以我们认为开源软件的供应链安全,实际上主要是技术问题。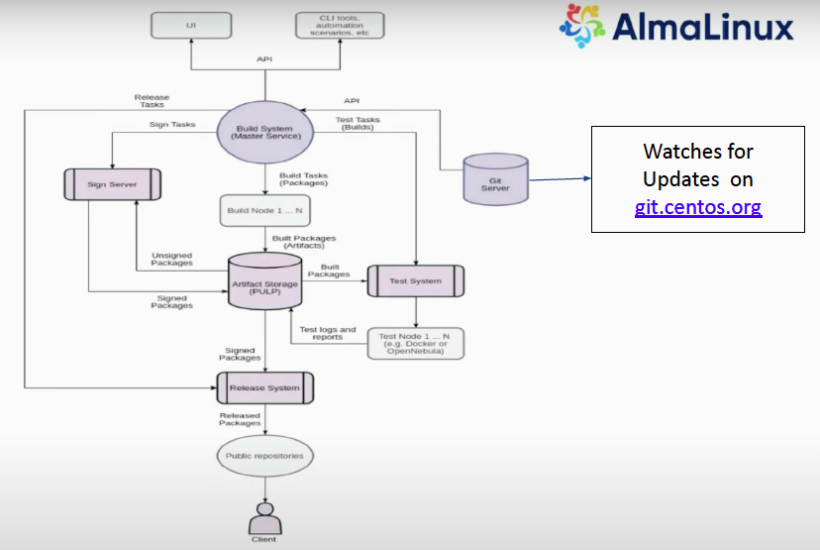
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最