摘要:高性能、大容量、低成本、强稳定性,广告业务需要的Ta都有
本文分享自华为云社区《广告业务存储神器:华为云GaussDB for Redis》,作者: GaussDB 数据库。
在互联网时代,媒体平台逐渐成为广告业务的主体,而作为广告主的企业往往每年需花费数亿甚至数十亿广告费,却依然难以准确触达目标用户,这就造成大量资金浪费。在这样的需求场景下,RTA广告业务模式逐渐流行起来。
RTA 即Realtime API的简称,是一套接口服务,用于满足广告主实时个性化的投放需求,在竞价中减少资金浪费。简单来说,RTA大体流程如下:
RTA广告业务流程图
RTA让广告投放变得更精准,更省钱,还可以满足许多不同的投放需求,例如获取新用户、召回流失用户等。
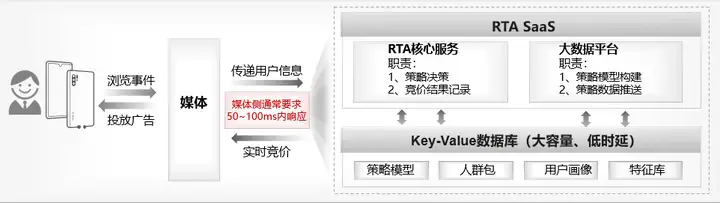
对广告主来说,RTA业务价值明显,但媒体侧可是设置了不小的技术门槛,一般要求RTA系统高峰承载20w+ QPS,50到100ms快速响应。当不达标时,媒体侧会有降级和清退机制,例如暂时关闭广告主的RTA接入通道。
因此,RTA业务的首要需求是使用靠谱的画像数据库:
根据经验,很多公司会使用开源Redis集群来做这件事,但其实开源Redis并不太适合这类大数据场景:
一方面,虽然开源Redis并发性能和响应都很优秀,但终究只是缓存,无法提供数据库级的稳定性保障,丢数据、fork抖动、分片不均OOM、扩容耗时久等等,都是很常见的问题。
另一方面,由于开源Redis中存放的数据无法突破内存限制,上百GB的数据存储价格非常昂贵,例如512GB规格的开源Redis接近5w/月。
在这类大数据业务场景下,我们推荐使用华为云数据库GaussDB for Redis做画像数据存储。
GaussDB for Redis是华为云企业级存算分离Redis数据库,使用上与开源Redis别无二致,并且能够兼顾缓存与存储两类典型场景:
1. 内存+分布式存储池
提供毫秒级响应,同时实现大幅降本
2. 命令兼容度>98%
支持业务零改造平迁
3. 容量最大支持36TB
保障数据库级别可靠存储,压缩比高
4. 算力按需原配
用多少买多少,最大支持千万级QPS
5. 无感热扩容
128GB到512GB也只需一秒
6. 增强版ACL
支持多DB访问权限隔离
RTA广告业务对画像存储的核心需求是:响应快、稳定性高、大容量且不贵,GaussDB for Redis充分满足这类大数据业务需求。
根据现网的案例经验,在数十万QPS流量下,GaussDB for Redis可稳定保持平均时延1ms,p99时延2ms。
媒体侧一般对广告主端到端响应要求在50~100ms,这其中包括了业务及网络链路的耗时,GaussDB for Redis可以很好地满足响应要求,并给业务链路留有充足的余量。
为什么GaussDB for Redis在存算分离的架构下还能提供低时延访问?

开源Redis的稳定性问题存在已久,单线程、fork机制、Gossip协议……这些都是让开源Redis稳定性不够好的原因。在小数据量缓存场景问题不一定经常出现,但在百GB的大数据存储场景下很容易成为打破系统稳定的隐患。
GaussDB for Redis存算分离架构对稳定性的提升是巨大的。在扩容场景,只需调整存储池配合,即可1秒完成扩容,业务0感知。由于数据全部存储在分布式存储池中,当计算节点发生故障,数据依然可见,业务只感知秒级抖动。同时,也不会发生分片数据不均OOM问题。
GaussDB for Redis在这类场景下能够帮助企业实现有效降本,原因是:
1、内存+分布式存储池(Nvme SSD)
开源Redis技术上无法突破内存限制,因此成本会随着每涨1GB而线性增长,大数据业务中很容易带来成本痛点。
GaussDB for Redis分布式存储池采用的高性能Nvme SSD硬件成本虽然比普通SSD高,但是跟内存相比还是比较高性价比的。另外还支持根据实际所需QPS购买计算节点,避免不必要的算力成本浪费。
2、高压缩比
很多画像类业务使用protobuf格式,GaussDB for Redis采用了逻辑数据+块数据双重压缩机制,对于protobuf的压缩比效果很好。根据现网案例经验,500GB的protobuf数据写入GaussDB for Redis后,实际占用的存储空间可压缩到160G,压缩率30%。
RTA广告竞价业务近年来发展潜力巨大,一方面要满足媒体侧的性能指标要求,另一方面又要承担企业降本重任。在这类典型大数据业务中,往往需要一款能够兼顾性能与存储降本需求的KV数据库来做画像存储,华为云数据库GaussDB for Redis无论从性能、稳定性,还是大容量、低成本,都充分满足这类场景的需求,是其最佳存储选型。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
有什么方法可以告诉sidekiq一项工作依赖于另一项工作,并且在后者完成之前无法开始? 最佳答案 仅使用Sidekiq;答案是否定的。正如DickieBoy所建议的那样,您应该能够在依赖作业完成时将其启动。像这样。#app/workers/hard_worker.rbclassHardWorkerincludeSidekiq::Workerdefperform()puts'Doinghardwork'LazyWorker.perform_async()endend#app/workers/lazy_worker.rbclassLaz
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
我的一个模型中有一个名为sui的字段。它代表“标准用户标识符”。当该字段出现验证错误时,Rails会打印“Suiisrequired”或“Suiisalreadytaken”。如何告诉Rails'sui'.titleize是“SUI”?我查看了Inflector.human,但这并不完全正确。 最佳答案 在这种情况下,我使用custom_err_msg插入。安装后,您可以提供如下自定义错误消息:validates_presence_of:sui,:message=>'^SUIisrequired'当您将^放在开头时,Rails不会输
我正在使用mechanize登录网站,然后检索页面。我遇到了一些问题,我怀疑这是由于cookie中的某些值造成的。当Mechanize登录网站时,我假设它存储了cookie。如何通过Mechanize打印出存储在cookie中的所有数据? 最佳答案 代理有一个cookie方法。agent=Mechanize.newpage=agent.get("http://www.google.com/")agent.cookiesagent.cookies.to_scookie返回一个Mechanize::Cookiesobject
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
有没有办法将RubyVM::InstructionSequence存储到文件中并稍后读取?我尝试了Marshal.dump但没有成功。我收到以下错误:`dump':no_dump_dataisdefinedforclassRubyVM::InstructionSequence(TypeError) 最佳答案 是的,有办法。首先,您需要使InstructionSequence的load方法可访问,默认情况下该方法是禁用的:require'fiddle'classRubyVM::InstructionSequence#RetrieveR