Mysql版本:8.0.26
可视化客户端:sql yog
目录
提示:以下是本篇文章正文内容,下面案例可供参考
DDL,英文全称为Data Definition Language,中文释义为“数据库模式定义语言”,即是用于创建库、创建表、修改库和表的结构,虽说有了可视化客户端,可以很方便的使用上述功能,但在批量修改的业务场景下,以此DDL写成的sql脚本比在可视化客户端下执行相比,简直好用太多。
👉语法:
CREATE DATABASE 数据库名
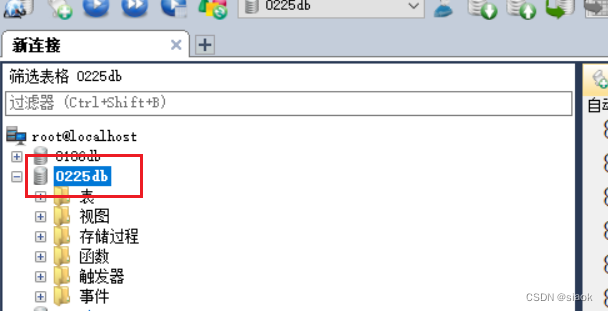
案例: 创建数据库0225db
CREATE DATABASE 0225db;
👉语法:
DROP DATABASE IF EXISTS 数据库名称
案例:删除数据库0225db
DROP DATABASE IF EXISTS 0225db;
👉语法:
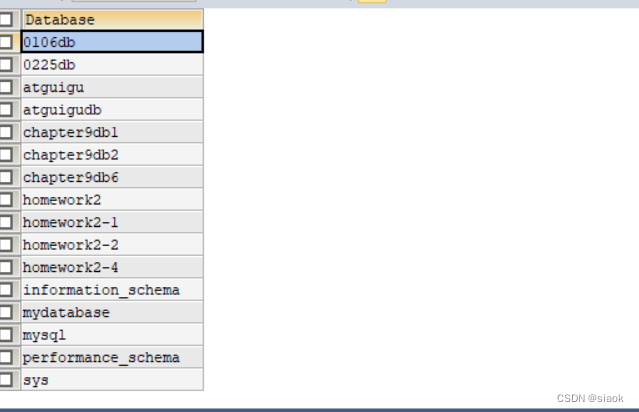
SHOW DATABASES:
SHOW DATABASES:
👉语法:
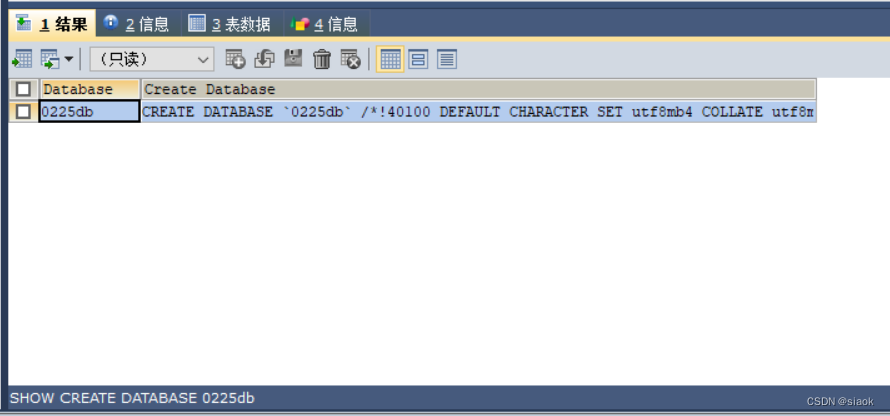
SHOW CREATE DATABASE 数据库名称;
案例:查看0225db的详细定义
代码演示如下:
SHOW CREATE DATABASE 0225db;
👉语法
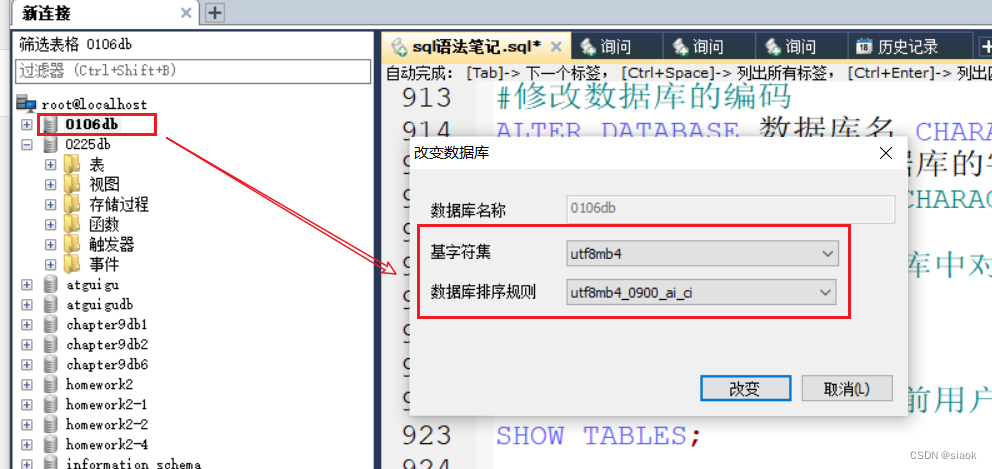
ALTER DATABASE 数据库名 CHARACTER SET 新的字符集名称 COLLATE 校对规则
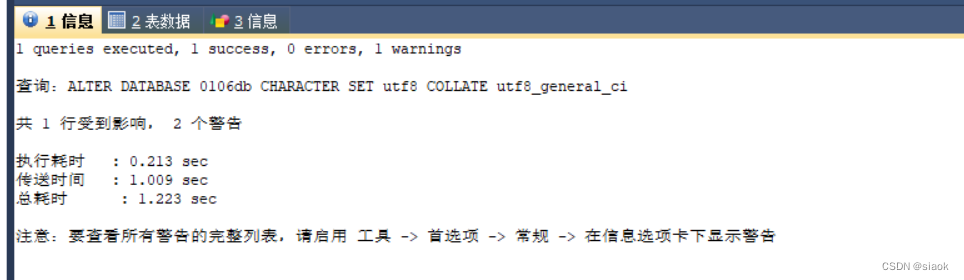
案例:修改数据库0106db的编码规则
修改之前:
代码修改如下所示:
ALTER DATABASE 0106db CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE DATABASE `0106db` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */

注意:
假如你现在修改了数据库的字符集规则,原来已经存放的数据表的字符集规则不变
👉语法:
use 数据库名;
一般先要指定在哪个数据库,才能对表进行操作
👉语法
USE 数据库名;
SHOW TABLES;
show tables from 数据库名;
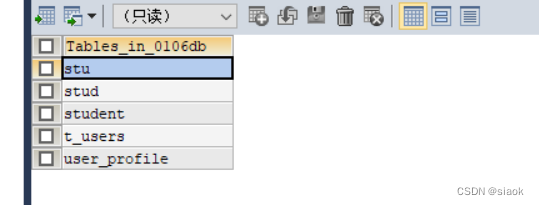
案例:查看0106db下的所有数据表
代码演示如下:
USE 0106db;
SHOW TABLES;
SHOW TABLES FROM 0106db;
👉语法
CREATE TABLE 表名称(
字段名1 数据类型,
字段名2 数据类型,
字段名3 数据类型
)
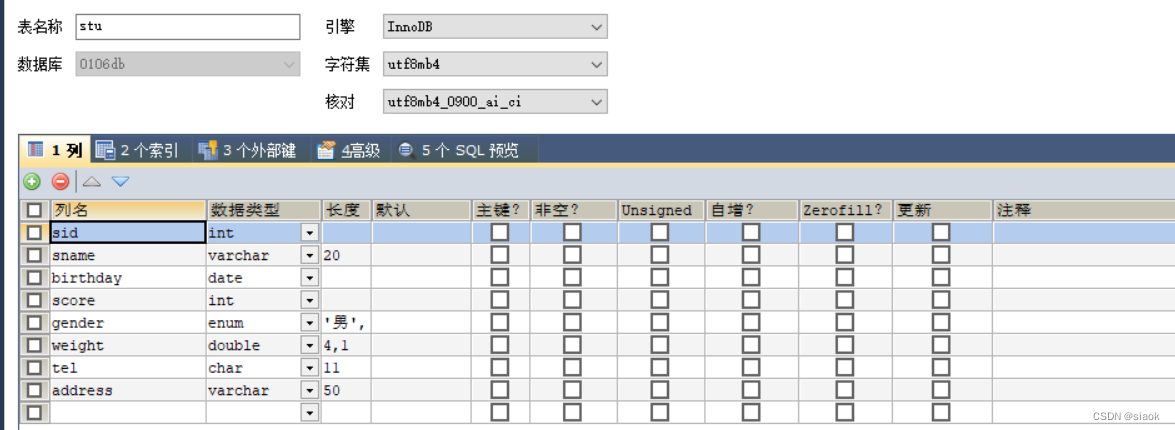
案例:创建学生表Stu,其中包含学生学号,姓名,出生日期,成绩,体重,性别,电话等字段。
代码演示如下:
CREATE TABLE Stu(
sid INT,
sname VARCHAR(20),
birthday DATE,
score INT,
gender ENUM('男','女'),
weight DOUBLE(4,1),
tel CHAR(11)
)
👉语法:
SHOW CREATE TABLE 表名称;
案例:查看表stu的详细定义信息
SHOW CREATE TABLE STU;

👉语法:
DESC 数据表名;
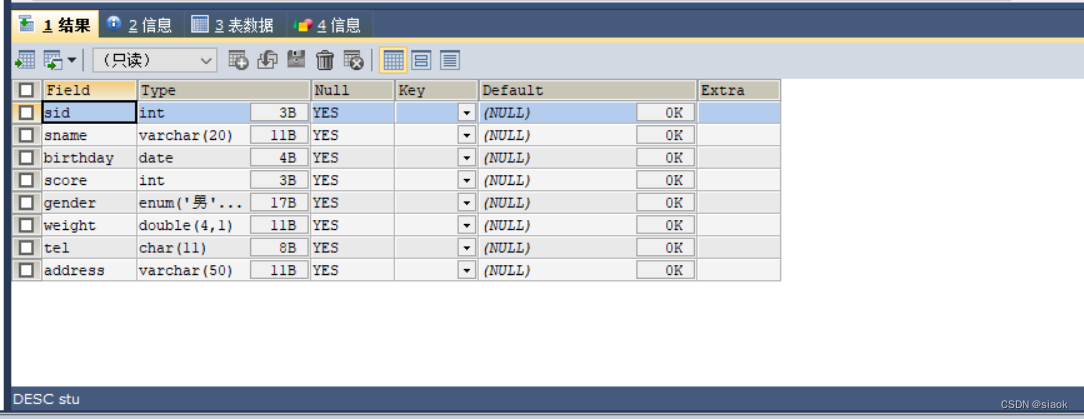
案例:查看数据表stu的表结构
代码演示如下:
DESC stu;
👉语法:
①DROP TABLE 表名称;
②DROP TABLE stu IF EXISTS;
第二句的意思是:如果数据库中存在stu表,就把它从数据库0102db中删掉。,
👉推荐使用第二种,避免出现“Unknown table ‘0106db.stu’”报错信息。
案例:删除学生表stu
代码演示如下:
DROP TABLE IF EXISTS stu;
👉语法:
ALTER TABLE 表名称 CHARSET=新字符集 COLLATE=新校对规则;
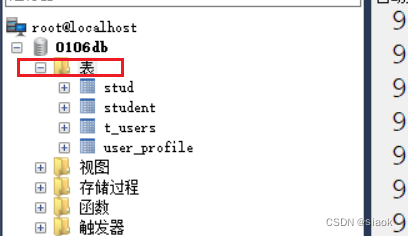
案例:修改表stu的字符集为utf8mb4,校队规则为utf8mb4_0900_ai_ci
修改之前:
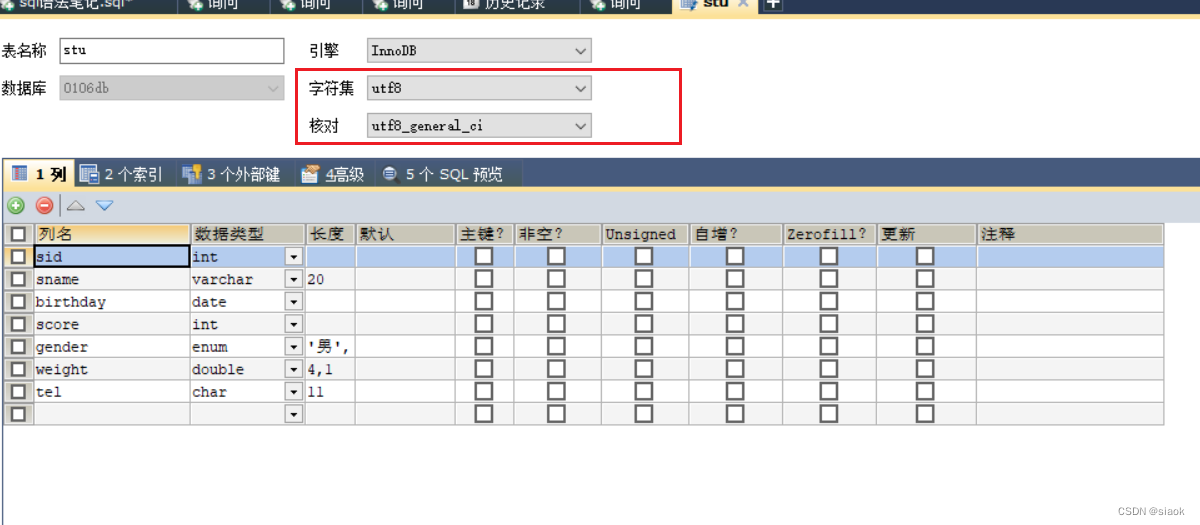
代码修改如下:
ALTER TABLE stu CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
👉语法:
ALTER TABLE 表名称 ADD COLUMN 字段名 数据类型;
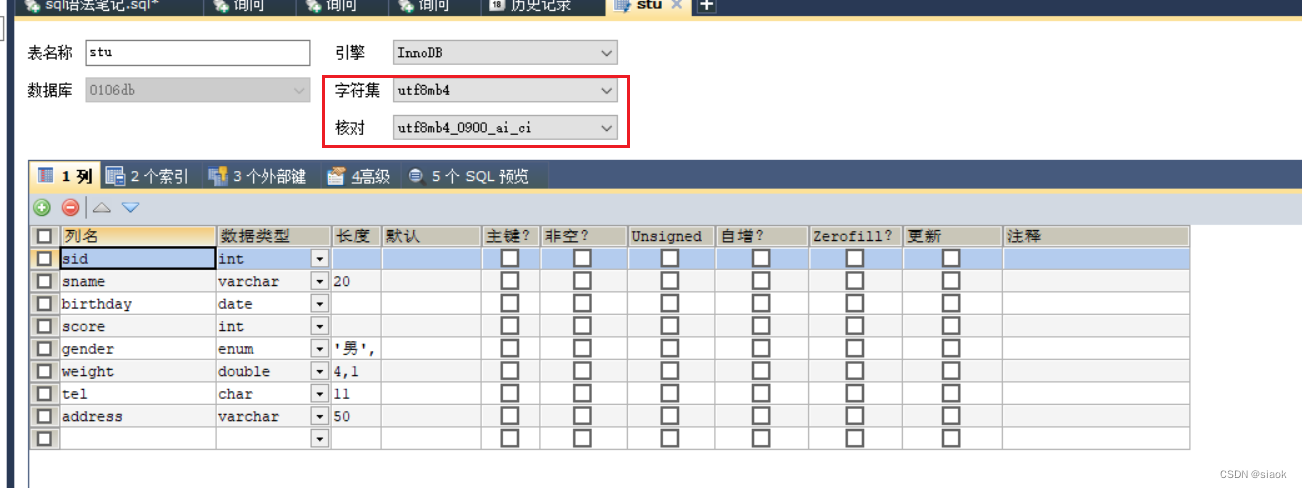
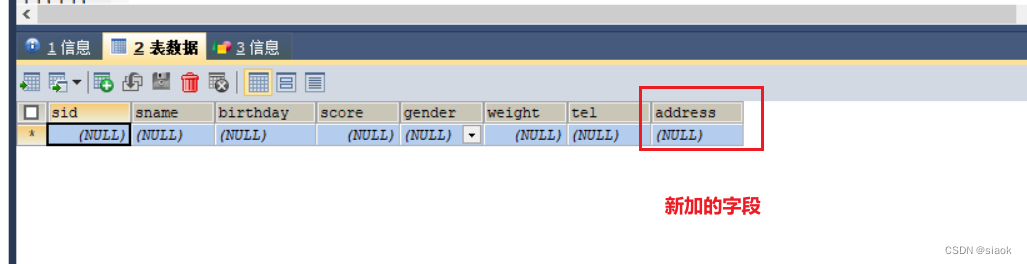
案例:给学生表stu增加一个varchar(50) 的字段address
代码演示如下:
ALTER TABLE stu ADD COLUMN address VARCHAR(50);
👉语法:
ALTER TABLE 表名称 DROP COLUMN 字段名;
案例:在学生表中删除刚才新加的字段address
代码演示如下:
ALTER TABLE stu DROP COLUMN address ;

👉语法:
ALTER TABLE 表名称 CHANGE 旧字段名称 新的字段名称 数据类型;
案例:将stu表的tel字段改名为phone
修改之前:

代码修改之后;
ALTER TABLE stu CHANGE tel phone CHAR(11);

👉语法:
ALTER TABLE 表名称 MODIFY 字段名称 新数据类型;
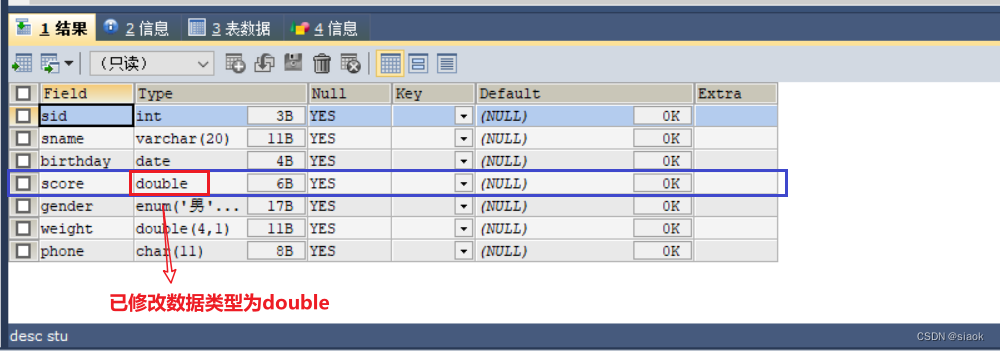
案例:将stu表的score字段的数据类型修改为double
修改之前:
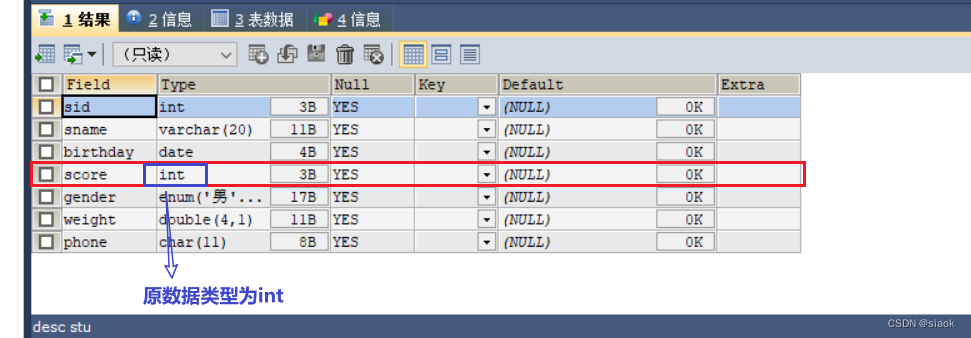
代码修改之后:
ALTER TABLE stu MODIFY score DOUBLE:
👉语法:
①ALTER TABLE 表名 MODIFY 字段名称 数据类型 AFTER 另一个字段;
👉上述代码的意思:将要修改位置的字段挪到指定字段的后面
②ALTER TABLE 表名称 MODIFY 字段名称 数据类型 FIRST;
👉上述代码的意思:将要修改位置的字段挪到表格第一行
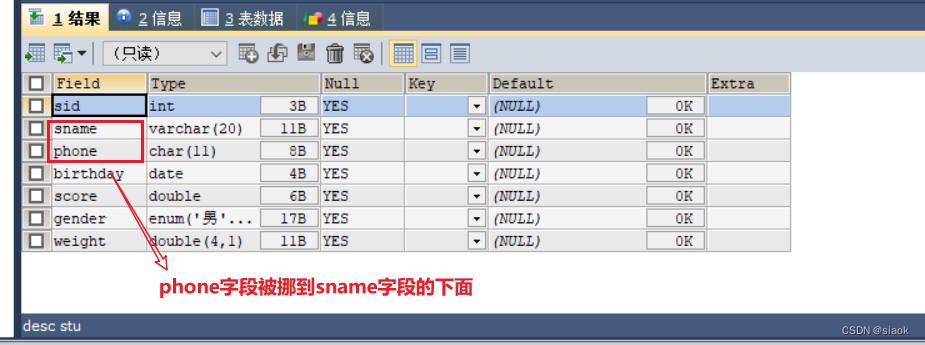
案例:在stu表中将phone字段挪到sname字段之后
修改之前:
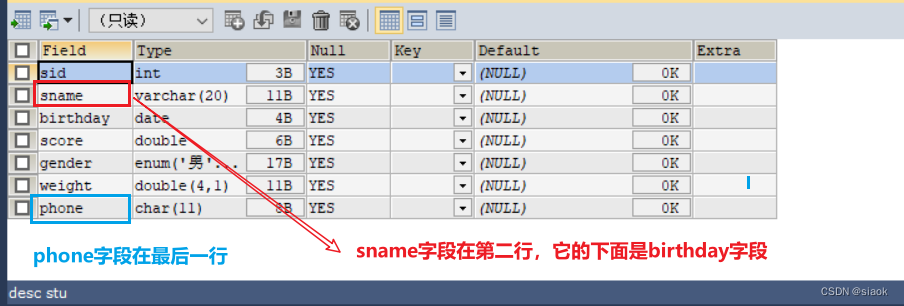
代码修改之后:
ALTER TABLE stu MODIFY phone CHAR(11) AFTER sname
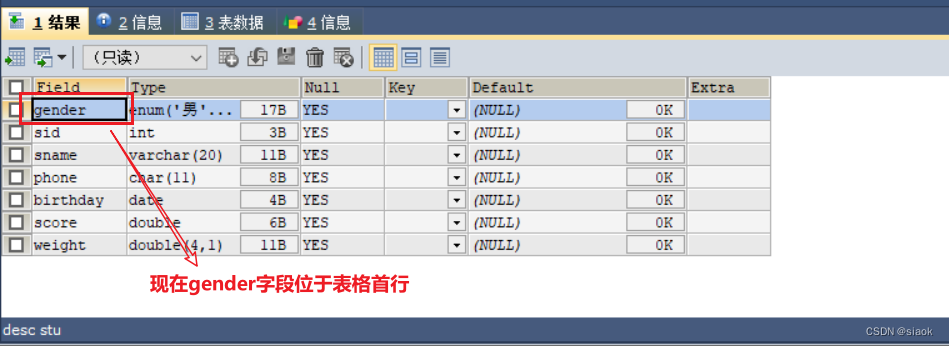
案例:将表stu中的字段gender挪到表格首行
修改之前:
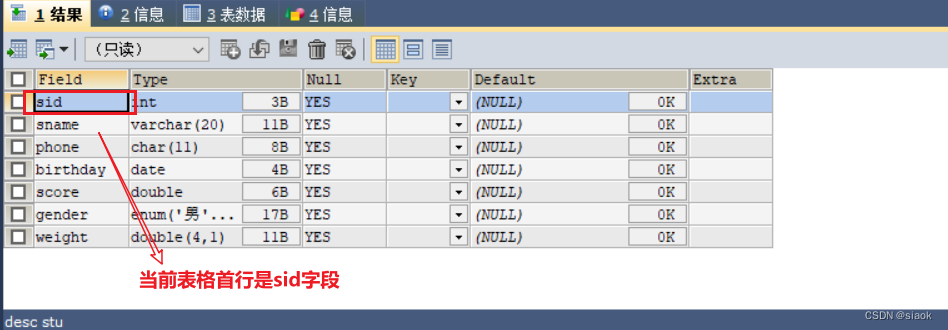
代码修改之后;
ALTER TABLE stu MODIFY gender ENUM('男','女') FIRST;
👉语法;
ALTER TABLE 表名称 RENAME TO 新名称;
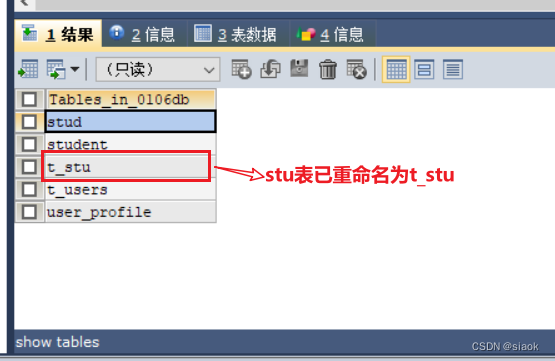
案例:将表stu重命名为t_stu
代码演示如下:
ALTER TABLE stu RENAME TO t_stu;
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
这个问题在这里已经有了答案:WhatisRuby'sdouble-colon`::`?(12个答案)关闭8年前。什么是::?@song||=::TwelveDaysSong.new
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl