1)kettle的官网下载地址:Pentaho from Hitachi Vantara - Browse Files at SourceForge.net
2)如果需要下载其他版本:
直接点击对应的版本Name(8.0以下的是在Data Integration文件夹里面)进去,再选择client-tools点击进去,最后选择pdi-ce-xxx.zip进行下载。

3)安装
不管是windows和linux环境下安装都是直接解压即可,再配置jdk环境。同步数据时,需要在lib加入对应的数据库驱动包。
当然,可以给他加后缀设置不一样的路径,或者直接把对应文件的路径放进去
以ElasticSearch为输入源,数据库为输出为例,es可能是驼峰命名字段,数据库可能是下划线命名。处理时可以在idea通过camelBar插件进行辅助转换。(快捷键:Alt+Shift+U 或者通过Edit-->camelBar)
异常原因:在kettle的big-data-plugin插件的源码中把批量提交的方法关闭了,所以其只能单挑插入,效率就非常低。
解决办法:
1)下载big-data-plugin插件源码(github上面直接搜索),选择与当前kettle版本对应的源码版本,如cdh510;
2)kettle官网下载kettle程序(暂且称为安装版);
3)在Idea上新建一个Java Project,把下载的插件源码解压,src下的文件拷贝到工程目录src下,工程中新建lib目录,把kettle安装版目录/lib下的kettle-core-版本号.jar、kettle-dbdialog-版本号.jar、kettle-engine-版本号.jar、kettle-ui-版本号.jar 四个jar包拷贝到工程lib目录并buildpath;
4)把工程src下除了org.pentaho.di.core.database 包之外的其他包都删除(这里只用hive2数据库连接,所以其他大数据插件就不要了,个人可以根据自身需求而定。);
5)修改Hive2DatabaseMeta类中的 public boolean supportsBatchUpdates()方法,把返回值由false改为true;
6)把工程达成jar包,名称参考安装版 plugins/pentaho-big-data-plugin/下的pentaho-big-data-plugin-版本号.jar的名字,然后替换安装版这个jar包为工程导出的jar包,重启kettle,DB连接的HadoopHive2连接的特征列表的supportsBatchUpdate已经是Y了,实际转换中的表输出速度也提高到几千条每秒。后台spark界面看提交的sql语句也变成batchinsert而不是之前的insert。
参考文章:https://download.csdn.net/download/weixin_43861380/11166617?utm_source=bbsseo
异常原因:如果使用kettle版本过高,hive版本过低,可能会导致连接不上hive。
解决方案:① 可以通过修改源码来解决。
② 也可以直接下载个低版本的kettle,修改plugin.properties配置文件(active.hadoop.configuration=),指定对应的CDH的版本(假设使用使用cdh)
在data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations可以看到对应的大数据一些组件版本。
异常原因:① 如果目标表有主键,过来的数据为空,也会报主键不能为空的问题。② 如果是通过REST client就可能是查询条件出问题。
解决方案:① 确保同步同步过来的数据不为空
② 检查查询语句是否有异常
异常原因:通常情况,Mysql数据编码格式为“utf-8”,对于汉字来说足够;Mysql中utf8占3个字节,但是,3个字节对于表情符号是不够的,需4个字节;此时使用utf8,会出现‘\xF0\x9F\x8D\x83\xF0\x9F’的问题。
utf8mb4编码是utf8编码的超集,兼容utf8,并且能存储4字节的表情字符。
解决方案:
① 设置kettle的数据库连接的配置(这种设置后可能连接不上数据库,数据库那边可能还要调整)
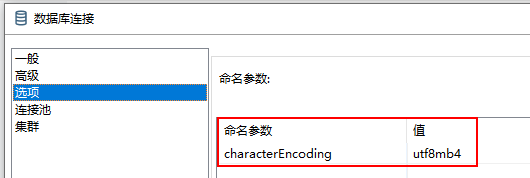
② 针对字段修改编码格式为utf8mb4(推荐使用)
ALTER TABLE table_name CHANGE field_name field_name VARCHAR(64) CHARACTER SET utf8mb4 ;
③ 修改数据库表的编码格式,修改为utf8mb4;修改Mysql配置文件my.cnf(windows下为my.ini),然后重启数据库 。
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
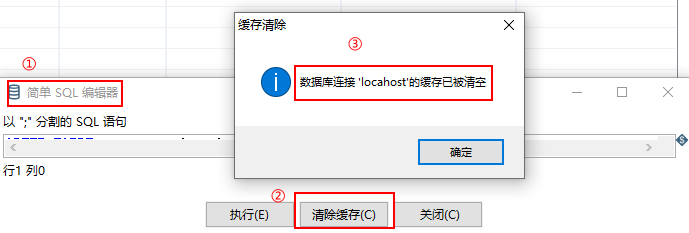
异常原因:主要是kettle缓存问题导致的
解决方案:直接在最后的输出步骤里,点击下方的SQL进行缓存清理。
#!/bin/sh
# @date 2023-01-03
# kettle启动停止工具脚本
KJB_NAME=$2
## kettle的父路径
KETTLE_PATH='/opt/module/kettle/pdi-ce-8.2.0.0-342'
## 使用说明,用来提示输入参数
usage(){
echo "Usage: sh 脚本名.sh [start|stop|restart|status|tail] [KJB_NAME]"
exit 1
}
## 检查执行的文件是否存在
is_exist(){
if [[ ! -e ${KETTLE_PATH}/jobs/${KJB_NAME}.kjb ]]; then
echo "该${KJB_NAME}.kjb在${KETTLE_PATH}/jobs/下不存在!"
exit 1
fi
}
## 检查程序是否在运行
is_running(){
pid=`ps -ef|grep ${KJB_NAME}.kjb|grep -v grep|awk '{print $2}'`
}
## 启动方法
start(){
is_exist
is_running
echo "pid=${pid}"
if [[ -z "${pid}" ]]; then
nohup ${KETTLE_PATH}/data-integration/kitchen.sh -file=${KETTLE_PATH}/jobs/${KJB_NAME}.kjb >> ${KETTLE_PATH}/logs/${KJB_NAME}.log 2>&1 &
echo "${KJB_NAME} start success!"
else
echo "${KJB_NAME} is already running."
fi
}
## 关闭方法
stop(){
is_running
if [[ -z "${pid}" ]]; then
echo "${KJB_NAME} is not running!"
else
echo "${KJB_NAME}, Trying to kill the pid=${pid}."
kill -9 ${pid}
echo "${KJB_NAME} stop success!"
fi
}
## 重启方法
restart(){
stop
start
}
## 启动方法
status(){
is_exist
is_running
echo "pid=${pid}"
if [[ -z "${pid}" ]]; then
nohup ${KETTLE_PATH}/data-integration/kitchen.sh -file=${KETTLE_PATH}/jobs/${KJB_NAME}.kjb >> ${KETTLE_PATH}/logs/${KJB_NAME}.log 2>&1 &
echo "${KJB_NAME} start success!"
else
echo "${KJB_NAME} is already running."
fi
}
if [[ $# -lt 2 ]]; then
usage
fi
case $1 in
"start")
echo "=================== start kettle_kjb ==================="
start
;;
"stop")
echo "=================== stop kettle_kjb ==================="
stop
;;
"restart")
echo "=================== restart kettle_kjb ==================="
restart
;;
"status")
echo "=================== status kettle_kjb ==================="
ps -ef|grep ${KJB_NAME}.kjb|grep -v grep
;;
"tail")
echo "=================== tail kettle_kjb ==================="
tail -60f ${KETTLE_PATH}/logs/${KJB_NAME}.log
;;
*)
echo "Input Args Error..."
;;
esac
参考文章:https://www.cnblogs.com/hls-code/p/16282329.html
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121