有些时候想要把在线观看的视频保存下来,或由于在线看很卡顿想离线看,但官方并没有提供下载工具,如果使用录频软件则电脑同时不能进行其他操作,而且有些电影看过一遍也不会想再看,因此想到用脚本下载。
在浏览器种按F12查看网络情况,发现下载的都是ts文件:(图片为其他图片,和本文没关系,只是介绍查看的方式)
因此,本脚本只适用于下载基于m3u8和ts的视频。
查阅相关blog了解到,ts文件是切片的视频,一般几秒钟不等,而浏览器加载ts的前提是先获取到了对应m3u8文件,所有ts的url都在该m3u8文件中。
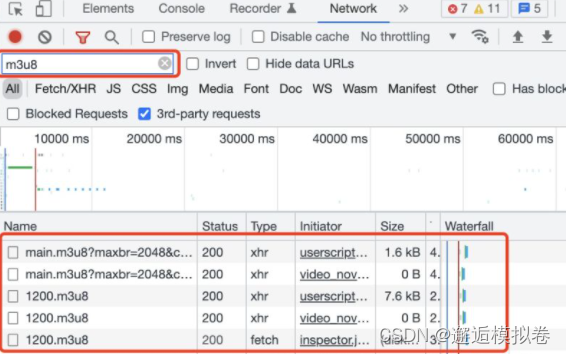
而m3u8文件一般在对应视频网页刚打开的时候加载的。
因此可以联想到,先请求url得到m3u8,再通过解析m3u8下载ts,最后将所有切片的ts合并,得到完整的视频!
那么需要解决的问题就分为以下几个部分:
这里主要做了几个工作:
def _check_url(self, html_url):
""" 从url获取 title 和 m3u8_url """
print(f"html_url:{html_url}")
html = requests.get(html_url, headers=headers, cookies=cookiejar_from_dict(self.cookie_dict)).text
if '您没有权限访问此数据' in html:
print(f"update cookie:")
self.cookie_dict = get_cookie_dict()
return self._check_url(html_url)
elif 'vcontainer' not in html:
print(f"{type(html)}")
print(html)
print('404')
return False
soup = BeautifulSoup(html, "html.parser")
iframes = soup.find(class_='video-title')
for iframe in iframes:
self.title = iframe.text
print(f"title:{self.title}")
iframes = soup.find(class_='vcontainer')
for iframe in iframes:
if 'index.m3u8' in iframe.text:
match_res = re.search('https:.*index[.]m3u8', iframe.text)
if match_res:
self.m3u8_url = match_res.group().replace("\\/", "/")
return True
else:
print('not find m3u8_url')
return False
其中,获取cookies可以单独写一个函数:
def get_cookie_dict():
"""
获取登录的cookie。
如果需要验证码则会更麻烦一点,然而一般需要验证码登录的网站都提供了下载方法。
"""
login_url = 'https://www.xxxxxx.com/user/login.html' # 改为对应网站的登录页
headers = {
'Content-Type': "application/json"
}
payload = {
"user_name": "xxxxxx",
"user_pwd": "xxxxxx"
}
try:
res = requests.post(url=login_url, headers=headers, json=payload)
cookie_dict = dict_from_cookiejar(res.cookies)
print(f"cookie_dict = {cookie_dict}")
return cookie_dict
except Exception as err:
print('获取cookie失败:\n{0}'.format(err))
cookie有两种格式,一个是dict,另一个是cookiejar。
dict的长这个样子
cookie_dict = {‘xxx’: ‘xxx’, ‘xxx’: ‘x91%98’, ‘user_check’: ‘00c2xxx809’, ‘user_id’: ‘xxx’, ‘user_name’: ‘xxx’, ‘user_portrait’: ‘%2Fsxxmagesx’}
如果不知道可以看浏览器中的请求头,一般登录之后会生成一个新的。如果这个dict过期了获取一个新的就行,这里不过多介绍。
此外,用的时候最好确认一下m3u8的格式,需要根据实际情况修改对应的正则表达式:
re.search('https:.*index[.]m3u8', iframe.text)
如果有多个.m3u8的url那也需要另作判断,这都不是大问题。
得到 m3u8_url 之后就需要继续请求 m3u8_url ,并且解析里面的内容。
def _check_m3u8_url(self, m3u8_url):
"""
Args:
m3u8_url: 'https://www.xxxxxx.xxxxxx/xxxxxx/index.m3u8'
"""
print(f"m3u8_url:{m3u8_url}")
datas = requests.get(m3u8_url, headers=headers).text
key = None
# print(datas)
for line in datas.split('\n'):
if line.endswith('.m3u8'):
idx = m3u8_url.find(line[:7])
new_m3u8_url = m3u8_url[:idx] + line
return self._check_m3u8_url(new_m3u8_url)
elif 'key.key' in line:
# print('key:', line)
key_url = re.search('https:.*key[.]key', line).group()
key = get_key(key_url).encode('utf8')
self.aes = AES.new(key, AES.MODE_CBC, key)
elif line.endswith('.ts'):
# print('ts:', line)
self.ts_url_list.append(line)
print(f"key:{key}, num of ts:{len(self.ts_url_list)}")
return self.ts_url_list
因为我这个网站的 m3u8_url 又包了一层,所以用了递归的思路,如果发现里面还有m3u8_url,则继续访问这个,如果发现很多.ts的url,才下载ts。
注意到,ts文件可能是加密的,直接下载下来会打不开,或者是花屏,则需要看m3u8文件中有没有表明加密格式。这里展示的是用AES.MODE_CBC加密的情况,其中密钥在.key文件中,这key的url也在m3u8文件中。
那获取key就很简单了,其实就是一串字符串
def get_key(key_url):
"""
Args:
key_url: 'https://www.xxxxxx.com/xxxxxxxxxxx/key.key'
Returns:
b'xxxxxx'
"""
return requests.get(key_url, headers=headers).text
这里顺便提供一个测试脚本,比如已经下好了没有解密的ts文件,可以测试一下解密方式对不对
from Crypto.Cipher import AES
key = b'efe42adecfbddfbb'
aes = AES.new(key, AES.MODE_CBC, key) # 创建一个aes对象
data_in = open('./out/00001.ts', 'rb').read()
data_out = aes.decrypt(data_in)
with open('outts_decrypt.ts', 'wb') as f:
f.write(data_out)
一般下载的时候顺便解密了,这样每个ts文件也能打开播放了。
这里提供三个多线程的方式:
合并ts的步骤,但其实硬盘读写的速度比较快,合并完了再删也不会花多少时间,而且还方便了中间结束程序,之后继续下载剩余的ts文件)。def load_ts_video_threds(outdir, ts_url_list, num_thred, aes):
"""
多线程批量下载ts文件
Args:
outdir: 输出目录
ts_url_list: ts的url列表
num_thred: 使用的线程数
aes: ts文件的解密器
"""
length = len(ts_url_list)
global index
index = 0
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = threadID
self.indice = list(range(threadID, length, num_thred))
self.cnt = 0
def run(self):
global index
while index <= length:
i = index
index += 1
ts_path = outdir / f"{i:05d}.ts"
ts_url = ts_url_list[i]
if not os.path.exists(ts_path):
try:
self.cnt += 1
print(f"线程 {self.threadID} 下载第 {self.cnt}({i + 1}/{length}) 条:{ts_url}")
# _t0 = time.time()
response = requests.get(ts_url, stream=True, headers=headers)
# print(time.time() - _t0)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=8192000):
if chunk:
if aes:
file.write(aes.decrypt(chunk))
else:
file.write(chunk)
except Exception as e:
print("异常请求:%s" % e)
else:
print(f'{ts_path} already exist.')
time.sleep(5)
# 创建新线程
print(f'启用多线程({num_thred})下载')
threads = [myThread(id) for id in range(num_thred)]
# 开启线程
for thread in threads:
thread.start()
return
注意:chunk_size要大一点,这里单位是字节(B),因为切片文件本来就不大,尽量整个下载了,如果太小也会存在花屏的现象,所以设置到几MB的大小就差不多了。
def load_ts_video_threds_每个线程固定下标(outdir, ts_url_list, num_thred, aes):
"""
多线程批量下载ts文件
Args:
outdir: 输出目录
ts_url_list: ts的url列表
num_thred: 使用的线程数
aes: ts文件的解密器
"""
length = len(ts_url_list)
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = threadID
self.indice = list(range(threadID, length, num_thred))
self.cnt = 0
def run(self):
for i in self.indice:
ts_path = outdir / f"{i:05d}.ts"
ts_url = ts_url_list[i]
if not os.path.exists(ts_path):
# _log = f"线程 {self.threadID} 下载第 {self.cnt}({i + 1}/{length}) 条:{ts_url}"
# print(_log)
_t0 = time.time()
self.cnt+=1
_try = 1
while _try<10:
try:
# _t1 = time.time()
response = requests.get(ts_url, stream=True, headers=headers, timeout=15)
# _t2 = time.time()
# _t3 = time.time()
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=8192000):
file.write(aes.decrypt(chunk))
# _t4 = time.time()
# print(f"{_log} {time.time() - _t0:.4f}s({_try})")
# print(f"get:{_t2-_t1:.4f}s, save1:{_t3-_t2}s, save2:{_t4-_t3}s, all:{_t4-_t0}s({_try})")
break
except Exception as e:
print(f"线程 {self.threadID},异常请求:{e},try:{_try}")
_try+=1
# else:
# print(f"{_log} try:{_try} 放弃!")
#
# else:
# print(f'{ts_path} already exist.')
# 创建新线程
print(f'启用多线程({num_thred})下载')
threads = [myThread(id) for id in range(num_thred)]
# 开启线程
for thread in threads:
thread.start()
return
特别注意的是,因为可能出现延时,所以最好做try的保护,可以缺包程序下了一半自己退出了,或者是大部分线程下完了,其中某一个线程卡死了半天没反应,这样就算慢也不会停滞不前。
经过我几天的测试,timeout=15还是比较合适的,可以根据对应网站的情况设置。可以先不设置,控制台看看平均需要多少时间,设置为平均的两倍左右基本就不会误杀了。就算误杀也有十次补回机会,一般情况足够了。
控制台输出的内容可以自己设置,相信会使用python下视频的,都有一定的编程基础,基本都能看懂什么意思,就不过多解释了。
要注意的是,所有线程run了之后,代码会继续往下走,所以在合并之前要判断是不是下完了,这里要写在调用load的函数里面。
##### load的函数上半部分这里不展示了,每个人的写法可能都不一样(在最后完整代码里有)
load_ts_video_threds_每个线程固定下标(ts_dir, self.ts_url_list, self.num_thred, self.aes)
# load_ts_video_threds(ts_dir, self.ts_url_list, self.num_thred, self.aes)
### 等待下载
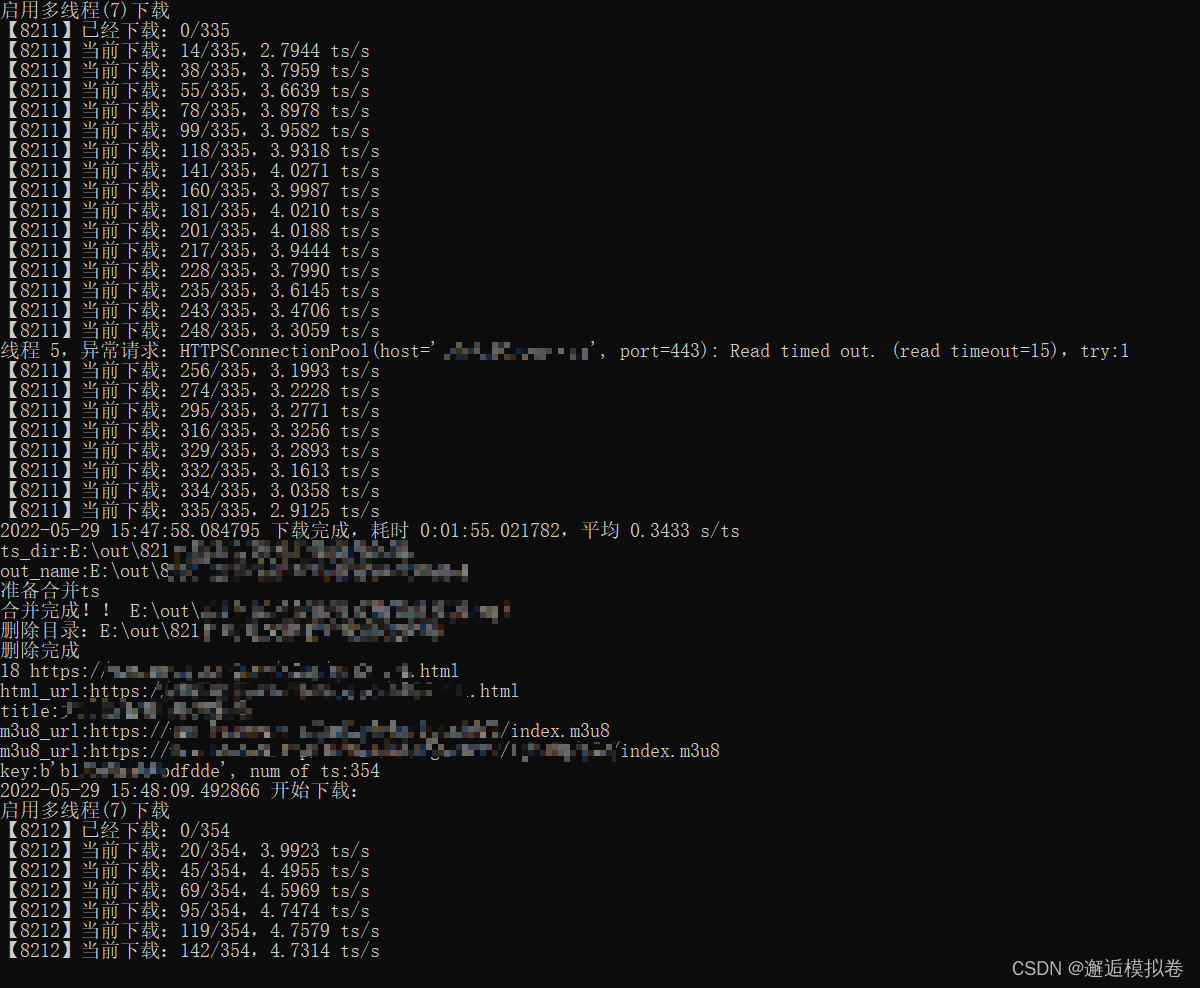
print(f"【{urlid}】已经下载:{num_loaded_old}/{num_ts}")
num_loaded = 0
while num_loaded < num_ts:
time.sleep(5)
num_loaded = len(os.listdir(ts_dir))
print(f"【{urlid}】当前下载:{num_loaded}/{num_ts},{(num_loaded-num_loaded_old) / (datetime.datetime.now()-_t0).total_seconds() :.4f} ts/s")
_t1 = datetime.datetime.now()
print(f"{_t1} 下载完成,耗时 {_t1-_t0},平均 {(_t1-_t0).total_seconds()/num_ts:.4f} s/ts")
print(f"ts_dir:{ts_dir}")
print(f"out_name:{out_name}")
### 合成视频
time.sleep(1)
ts2video(ts_dir, out_name, aes=None)
time.sleep(5)
if deldir:
### 删除ts目录
print(f"删除目录:{ts_dir}")
try:
shutil.rmtree(ts_dir)
except Exception as e:
print('再等待2秒再删除...')
time.sleep(2)
shutil.rmtree(ts_dir)
print(f"删除完成")
其中urlid之类的东西都是自己设置的,不需要也可以,我是为了方便控制台看下到哪里了。
重点在等待下载的部分,num_loaded 的数量我是通过判断文件夹内下载了多少ts来判断的,当然如果有更好的方式也欢迎评论区告诉我!
这里我测试过,如果一个文件夹五六百个ts文件的话,len(os.listdir(ts_dir)读10000下也就花一秒左右,问题不大。
计得判断完了需要sleep几秒,不然合并可能漏了,会发生读写异常。
def load_ts_video_threds_下载到内存(urlid, ts_url_list, num_thred, aes):
"""
多线程批量下载ts文件
Args:
urlid: 没啥用,为了显示日志用
ts_url_list: ts的url列表
num_thred: 使用的线程数
aes: ts文件的解密器
"""
num_ts = len(ts_url_list)
res = [None]*num_ts
global num_loaded
num_loaded = 0
_t0 = time.time()
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = threadID
self.indice = list(range(threadID, num_ts, num_thred))
def run(self):
global num_loaded
for i in self.indice:
_try = 1
while _try<10:
try:
_t0 = time.time()
response = requests.get(ts_url_list[i], stream=True, headers=headers, timeout=15)
_t1 = time.time()
for chunk in response.iter_content(chunk_size=8192000):
res[i] = aes.decrypt(chunk)
print(f"[{i:>2}]requests:{_t1-_t0:.4f}s, chunk:{time.time()-_t1:.4f}s")
num_loaded+=1
break
except Exception as e:
print(f"线程 {self.threadID},异常请求:{e},try:{_try}")
_try+=1
# 创建新线程
print(f'启用多线程({num_thred})下载')
threads = [myThread(id) for id in range(num_thred)]
# 开启线程
for thread in threads:
thread.start()
### 等待下载
# print(f"【{urlid}】已经下载:{num_loaded_old}/{num_ts}")
while num_loaded < num_ts:
time.sleep(5)
print(f"【{urlid}】当前下载:{num_loaded}/{num_ts},{(num_loaded) / (time.time()-_t0) :.4f} ts/s")
return res
上面两个都是下载到文件夹了,这里是下到内存里,所以要在函数里判断是否下完了,如果不用全局变量也可以用all()来判断是否下完了,只是不方便看日志。
这里下完之后不需要再合并了删,相当于是直接下好了,输出最终文件就行。
如果是使用方法一和方法二,需要遍历文件夹中的ts,合并到一个文件。
def ts2video(tsdir, outpath, aes=None):
print("准备合并ts")
with open(outpath, 'wb+') as f:
for ts_path in Path(tsdir).glob('*.ts'):
if aes:
f.write(aes.decrypt(open(ts_path, 'rb').read()))
else:
f.write(open(ts_path, 'rb').read())
print("合并完成!!", outpath)
需要修改的内容:
# -*- coding: utf-8 -*-
# @Time : 2022/5/29 9:39
# @Author : 模拟卷
# @Github : https://github.com/monijuan
# @CSDN : https://blog.csdn.net/qq_34451909
# @File : demo_下载ts视频.py
# @Software: PyCharm
# ===================================
import os
import shutil
import re
import time
import requests
import datetime
import threading
from pathlib import Path
from bs4 import BeautifulSoup
from requests.utils import dict_from_cookiejar, cookiejar_from_dict
from Crypto.Cipher import AES
from requests.adapters import HTTPAdapter
# s = requests.Session()
# s.mount('http://', HTTPAdapter(max_retries=3))
# s.mount('https://', HTTPAdapter(max_retries=3))
headers = {
"User-Agent": ""
}
cookie_dict = {}
def get_key(key_url):
"""
Args:
key_url: 'https://www.xxxxxx.com/xxxxxxxxxxx/key.key'
Returns:
b'xxxxxx'
"""
return requests.get(key_url, headers=headers).text
def get_cookie_dict():
"""
获取登录的cookie。
如果需要验证码则会更麻烦一点,然而一般需要验证码登录的网站都提供了下载方法。
"""
login_url = 'https://www.xxxxxx.com/user/login.html' # 改为对应网站的登录页
headers = {
'Content-Type': "application/json"
}
payload = {
"user_name": "xxxxxx",
"user_pwd": "xxxxxx"
}
try:
res = requests.post(url=login_url, headers=headers, json=payload)
cookie_dict = dict_from_cookiejar(res.cookies)
print(f"cookie_dict = {cookie_dict}")
return cookie_dict
except Exception as err:
print('获取cookie失败:\n{0}'.format(err))
def load_ts_video_threds_方法一_每个线程顺序下载(outdir, ts_url_list, num_thred, aes):
"""
多线程批量下载ts文件
Args:
outdir: 输出目录
ts_url_list: ts的url列表
num_thred: 使用的线程数
aes: ts文件的解密器
"""
length = len(ts_url_list)
global index
index = 0
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = threadID
self.indice = list(range(threadID, length, num_thred))
self.cnt = 0
def run(self):
global index
while index <= length:
i = index
index += 1
ts_path = outdir / f"{i:05d}.ts"
ts_url = ts_url_list[i]
if not os.path.exists(ts_path):
try:
self.cnt += 1
print(f"线程 {self.threadID} 下载第 {self.cnt}({i + 1}/{length}) 条:{ts_url}")
# _t0 = time.time()
response = requests.get(ts_url, stream=True, headers=headers)
# print(time.time() - _t0)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=8192000):
if chunk:
if aes:
file.write(aes.decrypt(chunk))
else:
file.write(chunk)
except Exception as e:
print("异常请求:%s" % e)
else:
print(f'{ts_path} already exist.')
time.sleep(5)
# 创建新线程
print(f'启用多线程({num_thred})下载')
threads = [myThread(id) for id in range(num_thred)]
# 开启线程
for thread in threads:
thread.start()
return
def load_ts_video_threds_方法二_每个线程固定下标(outdir, ts_url_list, num_thred, aes):
"""
多线程批量下载ts文件
Args:
outdir: 输出目录
ts_url_list: ts的url列表
num_thred: 使用的线程数
aes: ts文件的解密器
"""
length = len(ts_url_list)
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = threadID
self.indice = list(range(threadID, length, num_thred))
self.cnt = 0
def run(self):
for i in self.indice:
ts_path = outdir / f"{i:05d}.ts"
ts_url = ts_url_list[i]
if not os.path.exists(ts_path):
# _log = f"线程 {self.threadID} 下载第 {self.cnt}({i + 1}/{length}) 条:{ts_url}"
# print(_log)
_t0 = time.time()
self.cnt+=1
_try = 1
while _try<10:
try:
# _t1 = time.time()
response = requests.get(ts_url, stream=True, headers=headers, timeout=15)
# _t2 = time.time()
# _t3 = time.time()
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=8192000):
file.write(aes.decrypt(chunk))
# _t4 = time.time()
# print(f"{_log} {time.time() - _t0:.4f}s({_try})")
# print(f"get:{_t2-_t1:.4f}s, save1:{_t3-_t2}s, save2:{_t4-_t3}s, all:{_t4-_t0}s({_try})")
break
except Exception as e:
print(f"线程 {self.threadID},异常请求:{e},try:{_try}")
_try+=1
# else:
# print(f"{_log} try:{_try} 放弃!")
#
# else:
# print(f'{ts_path} already exist.')
# 创建新线程
print(f'启用多线程({num_thred})下载')
threads = [myThread(id) for id in range(num_thred)]
# 开启线程
for thread in threads:
thread.start()
return
def load_ts_video_threds_方法三_下载到内存(urlid, ts_url_list, num_thred, aes):
"""
多线程批量下载ts文件
Args:
urlid: 没啥用,为了显示日志用
ts_url_list: ts的url列表
num_thred: 使用的线程数
aes: ts文件的解密器
"""
num_ts = len(ts_url_list)
res = [None]*num_ts
global num_loaded
num_loaded = 0
_t0 = time.time()
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = threadID
self.indice = list(range(threadID, num_ts, num_thred))
def run(self):
global num_loaded
for i in self.indice:
_try = 1
while _try<10:
try:
_t0 = time.time()
response = requests.get(ts_url_list[i], stream=True, headers=headers, timeout=15)
_t1 = time.time()
for chunk in response.iter_content(chunk_size=8192000):
res[i] = aes.decrypt(chunk)
print(f"[{i:>2}]requests:{_t1-_t0:.4f}s, chunk:{time.time()-_t1:.4f}s")
num_loaded+=1
break
except Exception as e:
print(f"线程 {self.threadID},异常请求:{e},try:{_try}")
_try+=1
# 创建新线程
print(f'启用多线程({num_thred})下载')
threads = [myThread(id) for id in range(num_thred)]
# 开启线程
for thread in threads:
thread.start()
### 等待下载
# print(f"【{urlid}】已经下载:{num_loaded_old}/{num_ts}")
while num_loaded < num_ts:
time.sleep(5)
print(f"【{urlid}】当前下载:{num_loaded}/{num_ts},{(num_loaded) / (time.time()-_t0) :.4f} ts/s")
return res
class Loader():
def __init__(self, base_dir=Path('./out'), num_thred=10):
self.title = f'notitle{time.time()}'
self.m3u8_url = None
self.ts_url_list = []
self.aes = None
self.base_dir = base_dir
self.num_thred = num_thred
self.cookie_dict = cookie_dict
# self.cookiejar = cookiejar_from_dict(cookie_dict)
print(f"now cookie_dict:{cookie_dict}")
def _reinit(self):
self.title = f'notitle{time.time()}'
self.m3u8_url = None
self.ts_url_list = []
self.aes = None
def _check_url(self, html_url):
""" 从url获取 title 和 m3u8_url """
print(f"html_url:{html_url}")
html = requests.get(html_url, headers=headers, cookies=cookiejar_from_dict(self.cookie_dict)).text
if '您没有权限访问此数据,请升级会员' in html:
print(f"update cookie:")
self.cookie_dict = get_cookie_dict()
return self._check_url(html_url)
elif 'vcontainer' not in html:
print(f"{type(html)}")
print(html)
print('404')
return False
soup = BeautifulSoup(html, "html.parser")
iframes = soup.find(class_='video-title')
for iframe in iframes:
self.title = iframe.text
print(f"title:{self.title}")
iframes = soup.find(class_='vcontainer')
for iframe in iframes:
if 'index.m3u8' in iframe.text:
match_res = re.search('https:.*index[.]m3u8', iframe.text)
if match_res:
self.m3u8_url = match_res.group().replace("\\/", "/")
return True
else:
print('not find m3u8_url')
return False
def _check_m3u8_url(self, m3u8_url):
""" m3u8_url: 'https://www.xxxxxx.xxxxxx/xxxxxx/index.m3u8' """
print(f"m3u8_url:{m3u8_url}")
datas = requests.get(m3u8_url, headers=headers).text
key = None
# print(datas)
for line in datas.split('\n'):
if line.endswith('.m3u8'):
idx = m3u8_url.find(line[:7])
new_m3u8_url = m3u8_url[:idx] + line
return self._check_m3u8_url(new_m3u8_url)
elif 'key.key' in line:
# print('key:', line)
key_url = re.search('https:.*key[.]key', line).group()
key = get_key(key_url).encode('utf8')
self.aes = AES.new(key, AES.MODE_CBC, key)
elif line.endswith('.ts'):
# print('ts:', line)
self.ts_url_list.append(line)
print(f"key:{key}, num of ts:{len(self.ts_url_list)}")
return self.ts_url_list
def loadurl(self, html_url, load=True, deldir=False):
if self.ts_url_list:
self._reinit()
### index.m3u8
if not self._check_url(html_url): # 解析最外层url:获取 m3u8_url 和 title
print(f"check url 失败,跳过!")
return
### 如果已经下了同名文件,则跳过
urlid = html_url.split('/')[-1].split('-')[0]
# date = str(datetime.datetime.now()).split(' ')[0]
name = self.title.replace(':', '').replace(' ', '')
ts_dir = self.base_dir / f"{urlid}-{name}"
out_name = self.base_dir / f"{urlid}-{name}.mp4"
if os.path.exists(out_name):
print(f"{out_name} 已经存在,跳过下载!")
return
self._check_m3u8_url(self.m3u8_url) # 解析 m3u8_url:获取 key 和 ts列表
if load:
_t0 = datetime.datetime.now()
print(f"{_t0} 开始下载:")
ts_dir.mkdir(exist_ok=True, parents=True)
num_loaded_old = len(os.listdir(ts_dir))
num_ts = len(self.ts_url_list)
# load_ts_video_threds_方法一_每个线程顺序下载(ts_dir, self.ts_url_list, self.num_thred, self.aes)
load_ts_video_threds_方法二_每个线程固定下标(ts_dir, self.ts_url_list, self.num_thred, self.aes)
### 等待下载
print(f"【{urlid}】已经下载:{num_loaded_old}/{num_ts}")
num_loaded = 0
while num_loaded < num_ts:
time.sleep(5)
num_loaded = len(os.listdir(ts_dir))
print(
f"【{urlid}】当前下载:{num_loaded}/{num_ts},{(num_loaded - num_loaded_old) / (datetime.datetime.now() - _t0).total_seconds() :.4f} ts/s")
_t1 = datetime.datetime.now()
print(f"{_t1} 下载完成,耗时 {_t1 - _t0},平均 {(_t1 - _t0).total_seconds() / num_ts:.4f} s/ts")
print(f"ts_dir:{ts_dir}")
print(f"out_name:{out_name}")
### 合成视频
time.sleep(1)
ts2video(ts_dir, out_name, aes=None)
time.sleep(5)
if deldir:
### 删除ts目录
print(f"删除目录:{ts_dir}")
try:
shutil.rmtree(ts_dir)
except Exception as e:
print('再等待2秒再删除...')
time.sleep(2)
shutil.rmtree(ts_dir)
print(f"删除完成")
else:
print(f"load={load}")
### ———————————————— Loader
def ts2video(tsdir, outpath, aes=None):
print("准备合并ts")
with open(outpath, 'wb+') as f:
for ts_path in Path(tsdir).glob('*.ts'):
if aes:
f.write(aes.decrypt(open(ts_path, 'rb').read()))
else:
f.write(open(ts_path, 'rb').read())
print("合并完成!!", outpath)
if __name__ == '__main__':
# cookie_dict = get_cookie_dict()
base_dir = Path('./out')
loader = Loader(base_dir=base_dir, num_thred=10)
urls = [
# 'www.xxxxxx.xxxxxx/xxxxxx ',
]
for urlid, url in enumerate(urls):
print(urlid, url)
loader.loadurl(url, load=True)
# break
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我在理解Enumerator.new方法的工作原理时遇到了一些困难。假设文档中的示例:fib=Enumerator.newdo|y|a=b=1loopdoy[1,1,2,3,5,8,13,21,34,55]循环中断条件在哪里,它如何知道循环应该迭代多少次(因为它没有任何明确的中断条件并且看起来像无限循环)? 最佳答案 Enumerator使用Fibers在内部。您的示例等效于:require'fiber'fiber=Fiber.newdoa=b=1loopdoFiber.yieldaa,b=b,a+bendend10.times.m
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题: