例子1:
看一个需求
int num= 100这个int 类型的数据保存到文件中,注意不是100 数字,而是int 100,并且能够从文件中直接恢复 int 100Dog dog = new Dog("小黄",3)这个Dog对象保存到文件中,并且能够从文件恢复。上面的要求,就是能够将 基本数据类型 或者 对象 进行 序列化 和 反序列化操作

Serializable //这是一个标记接口,没有方法(推荐)Externalizable //该接口有方法需要实现,因此推荐实现上面的Serializable接口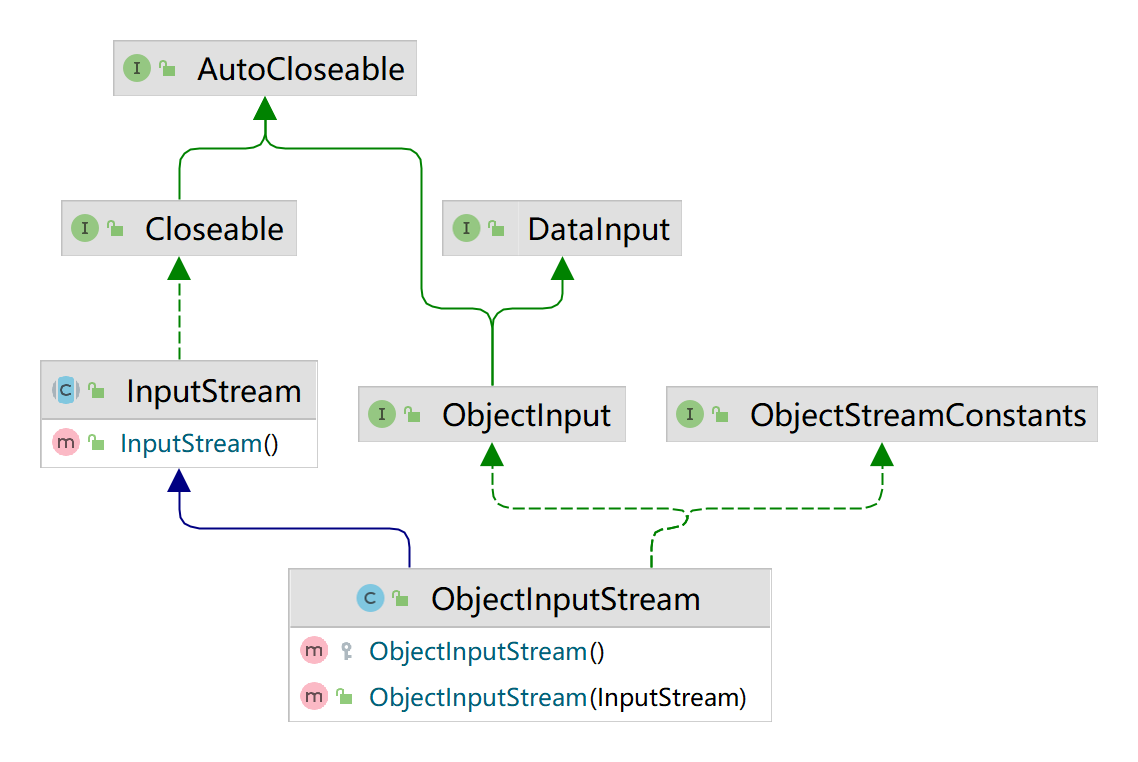
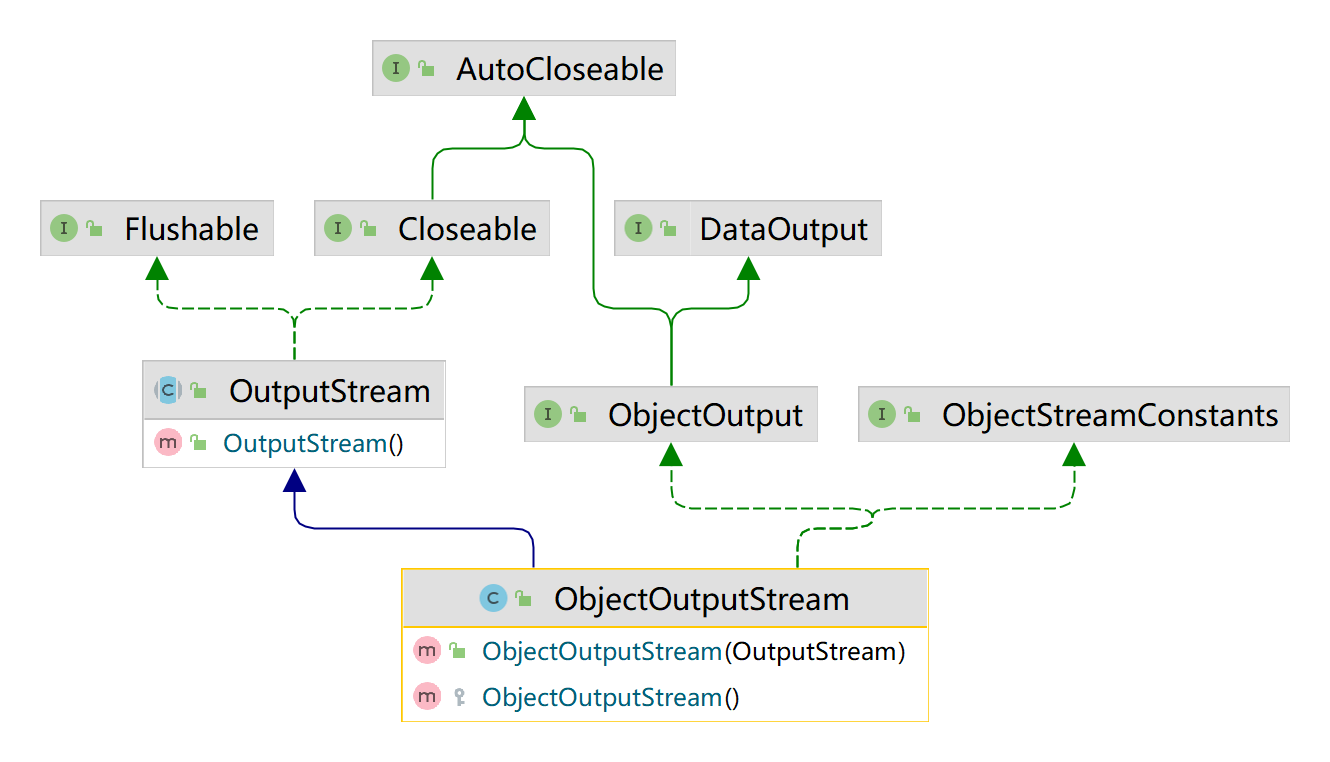
例子1:序列化应用
使用ObjectOutputStream序列化 基本数据类型 和一个 Dog对象(name,age),并保存到data.dat文件中。
package li.io.outputstream_;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
//演示ObjectOutputStream的使用,完成数据的序列化
public class ObjectOutputStream_ {
public static void main(String[] args) throws Exception {
//序列化后,保存的文件格式不是纯文本格式,而是按照它自己的格式来保存
String filePath = "d:\\data.dat";
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(filePath));
//存储
//序列化数据到文件d:\data.dat
oos.writeInt(100);//100在底层实现了自动装箱,int ->Integer (Integer实现了Serializable接口)
oos.writeBoolean(true);//boolean ->Boolean (Boolean实现了Serializable接口)
oos.writeChar('a');// char ->Char (实现了Serializable接口)
oos.writeDouble(9.5);//double ->Double (实现了Serializable接口)
oos.writeUTF("你好火星");//String(实现了Serializable接口)
//保存一个Dog对象
oos.writeObject(new Dog("旺财", 10));
//关闭外层流
oos.close();
System.out.println("数据保存完毕(序列化形式)");
}
}
//如果需要序列化某个对象,必须实现接口Serializable或者 Externalizable接口
class Dog implements Serializable {
private String name;
private int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
}

例子2:反序列化应用
使用ObjectInputStream读取data.dat并且反序列化恢复数据
Dog:
package li.io.outputstream_;
import java.io.Serializable;
//如果需要序列化某个对象,必须实现接口Serializable或者 Externalizable接口
public class Dog implements Serializable {
private String name;
private int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
}
ObjectInputStream_:
package li.io.inputstream_;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import li.io.outputstream_.Dog;
public class ObjectInputStream_ {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//指定反序列化的文件
String filePath = "d:\\data.dat";
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(filePath));
//读取
//1.读取(反序列化)的顺序要和你保存数据(序列化)的顺序一致,否则会出现异常
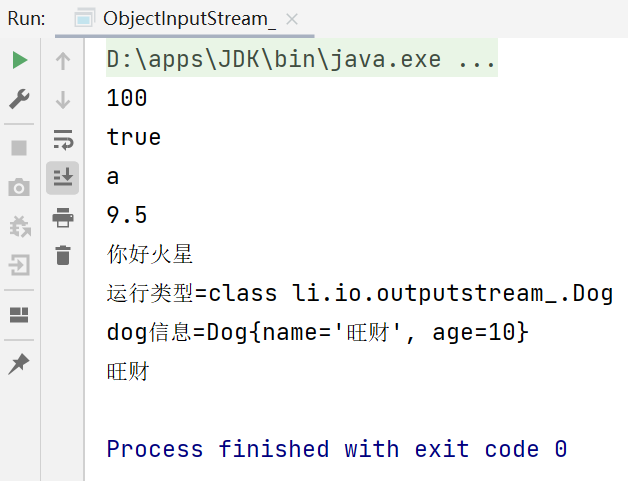
System.out.println(ois.readInt());
System.out.println(ois.readBoolean());
System.out.println(ois.readChar());
System.out.println(ois.readDouble());
System.out.println(ois.readUTF());
//dog的编译类型是Object ,dou的运行类型是 Dog
Object dog = ois.readObject();
System.out.println("运行类型=" + dog.getClass());//Dog
System.out.println("dog信息=" + dog);//底层 Object->Dog
//一些重要细节:
//1. 如果我们希望调用Dog的方法,需要向下转型
//2. 需要我们将Dog类的定义拷贝到可以引用的位置然后导入类(将Dog类创建为公共类,重新序列化,再反序列化)
Dog dog1 = (Dog) dog;
System.out.println(dog1.getName());
//关闭外层流
ois.close();
}
}
Serializable或者Externalizable SerialVersionUID,是为了提高版本的兼容性在完成序列化操作后,如果对序列化对象进行了修改,比如增加某个字段,那么我们再进行反序列化就会抛出InvalidClassException异常,这种情况叫不兼容问题。
解决的方法是:在对象中手动添加一个 serialVersionUID 字段,用来声明一个序列化版本号,之后再怎么添加属性也能进行反序列化,凡是实现Serializable接口的类都应该有一个表示序列化版本标识符的静态变量。
序列化对象时,默认将里面的所有属性都进行序列化,但除了static或transient修饰的成员
序列化对象时,要求里面属性的类型也需要实现序列化接口
例如:在(实现了Serializable接口的)Dog类中创建一个Master类型的属性master,而Master类没有实现Serializable接口,所以在序列化时,Dog类中的master属性无法序列化,也不能反序列化
不懂这些,你敢说自己知道Java标准输入输出流? - 简书 (jianshu.com)
介绍:
| 类型 | 默认设备 | |
|---|---|---|
| System.in 标准输入 | InputStream | 键盘 |
| System.out标准输出 | PrintStream | 显示器 |
例子1:
package li.io.standard;
public class InputAndOutput {
public static void main(String[] args) {
// System 类 的 public final static InputStream in = null;
// System.in 编译类型 InputStream
// System.in 运行类型 BufferedInputStream
// 表示的是标准输入--用来读取键盘录入的数据
System.out.println(System.in.getClass());//class java.io.BufferedInputStream-字节处理输入流
// 1. System.out public final static PrintStream out = null;
// 2.编译类型 PrintStream
// 3.运行类型 PrintStream
// 4.表示标准输出显示器--将数据输出到命令行
System.out.println(System.out.getClass());//class java.io.PrintStream - 字节输出流
}
}
应用案例1:
传统方法: System.out.println(" ");是使用out对象将数据输出到显示器
应用案例2:
传统方法,Scanner是从标准输入 键盘接收数据
// 给Scanner扫描器传入的就是BufferedInputStream,
// 表示的是标准输入--用来读取键盘录入的数据
// 因此 scanner会到键盘去 获取输入的数据
Scanner scanner = new Scanner(System.in);
System.out.println("请输入内容:");
//会去键盘去得到输入流
String next = scanner.next();
System.out.println(next);
scanner.close();
先来看一个例子:
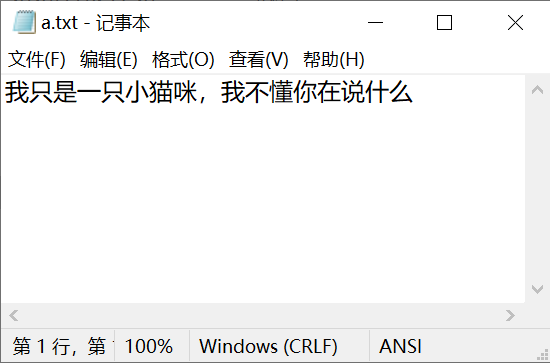
在d:\盘的根目录下有一个a.txt文件,内容如下:

现在想把该文件读取到程序中:
package li.io.transformation;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
//一个中文乱码问题
public class CodeQuestion {
public static void main(String[] args) throws IOException {
//读取a.txt文件到程序中
//思路:
// 1.创建一个字符输入流 这里用 BufferedRead[处理流]
// 2.使用 BufferedRead 对象读取 a.txt
// 3.在默认情况下,读取文件是按照 UTF-8 编码
String filePath = "d:\\a.txt";
BufferedReader br = new BufferedReader(new FileReader(filePath));
String s = br.readLine();
System.out.println("读取到的内容=" + s);
br.close();
}
}
在a.txt文件编码为uft-8的时候,输出:
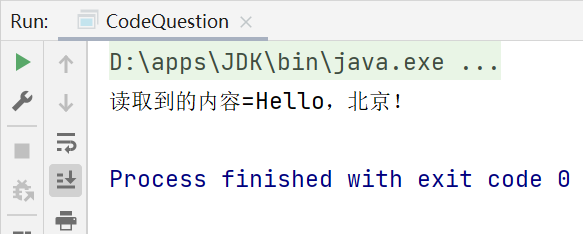
在a.txt文件编码为ANSI的时候,输出:
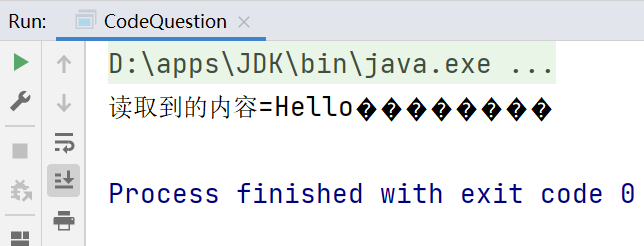
出现乱码的根本问题是:没有指定文件的编码方式。
转换流也是一种处理流,它提供了字节流和字符流之间的转换。
在Java IO流中提供了两个转换流:InputStreamReader 和 OutputStreamWriter,这两个类都属于字符流。
转换流的原理是:字符流 = 字节流 + 编码表
我们需要明确的是字符编码和字符集是两个不同层面的概念。
编码是依赖于字符集的,一个字符集可以有多个编码实现,就像代码中的接口实现依赖于接口一样。
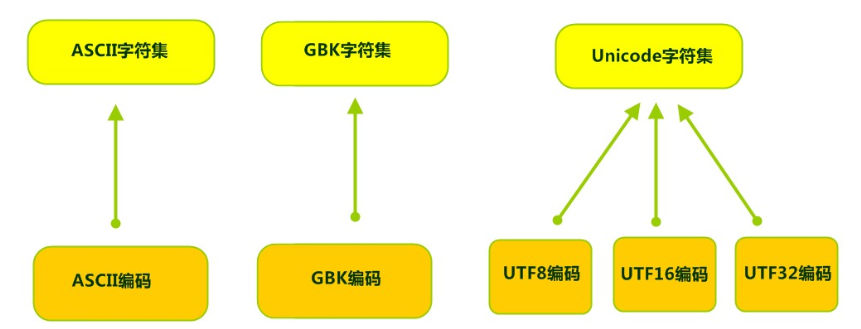
在转换流中选择正确的编码非常的重要,因为指定了编码,它所对应的字符集自然就指定了,否则很容易出现乱码,所以编码才是我们最终要关心的。
转换流的特点:其是字符流和字节流之间的桥梁。
可对读取到的字节数据经过指定编码转换成字符
可对读取到的字符数据经过指定编码转换成字节
那么何时使用转换流?
当字节和字符之间有转换动作时
流操作的数据需要编码或解码时

Java IO流详解(六)----转换流(字节流和字符流之间的转换) - 唐浩荣 - 博客园 (cnblogs.com)
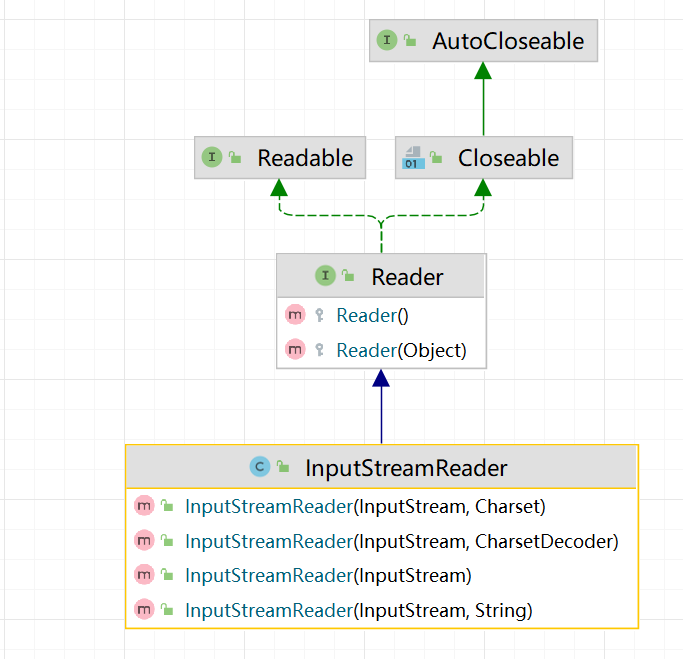
InputStreamReader:
如下图,InputStreamReader有一个重要的构造器InputStreamReader(InputStream, Charset):也就是说,我们可以通过这个方法,将传入的字节流转为一个字符流并指定处理的编码方式
OutputStreamWriter:
如下图,OutputStreamWriter也有一个重要的构造器:
OutputStreamWriter(OutputStream, Charset):即我们也可以通过这个方法,将写出的字节流转为一个字符流并指定处理的编码方式
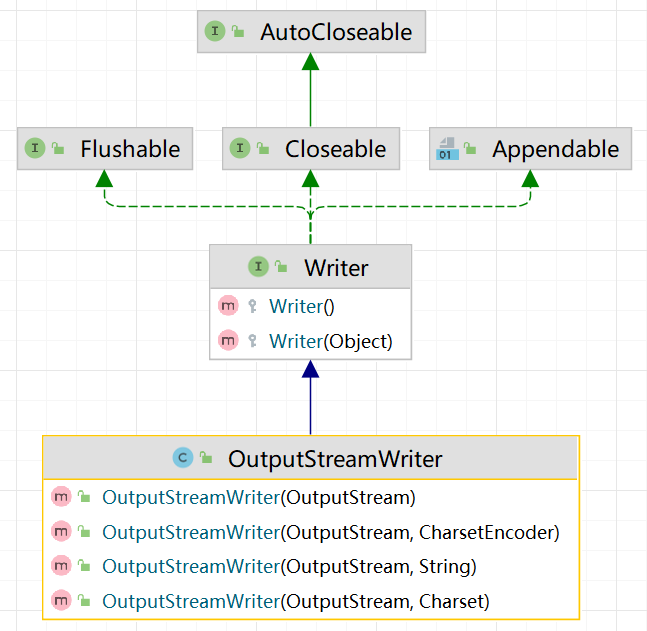
应用案例1:
编程将字节流FileInputStream转换成(包装成)字符流InputStreamReader,对文件进行读取(按照UTFF-8格式),进而再包装成 BufferedReader
package li.io.transformation;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.io.IOException;
//演示使用 InputStreamReader 转换流解决中文乱码问题
//将字节流转 FileInputStream 换成字符流 InputStreamReader,并指定编码 gbk/utf-8
public class InputStreamReader_ {
public static void main(String[] args) throws IOException {
String filePath = "d:\\a.txt";
// 1.将 FileInputStream流(字节流),转成了 InputStreamReader流(字符流)
// 2.指定了gbk编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(filePath), "UTF-8");
// 3. 把 InputStreamReader 传入 BufferedReader
BufferedReader br = new BufferedReader(isr);
// 4. 读取
String s = br.readLine();
System.out.println("读取内容=" + s);
// 5.关闭外层流
br.close();
}
}
应用案例2:
编程将字节流FileOutputStream 包装(转换)成字符流OutputStreamWriter,对文件进行写入(按照GBK格式,可以指定其他,比如UTF-8)
package li.io.transformation;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.IOException;
/**
* 演示使用 OutputStreamWriter
* 将字节流转 FileOutputStream 换成字符流 OutputStreamWriter
* 指定处理的编码 gbk/utf-8/utf8
*/
public class OutputStreamWriter_ {
public static void main(String[] args) throws IOException {
String filePath = "d:\\a.txt";
String charSet = "GBK";
//创建对象
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath), charSet);
//写入
osw.write("我只是一只小猫咪,我不懂你在说什么");
//关闭外层流
osw.close();
System.out.println("按照 " + charSet + " 保存文件成功~");
}
}
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
print"Enteryourpassword:"pass=STDIN.noecho(&:gets)puts"Yourpasswordis#{pass}!"输出:Enteryourpassword:input.rb:2:in`':undefinedmethod`noecho'for#>(NoMethodError) 最佳答案 一开始require'io/console'后来的Ruby1.9.3 关于ruby-为什么不能使用类IO的实例方法noecho?,我们在StackOverflow上
我试图在Ubuntu14.04中使用Curl安装RVM。我运行了以下命令:\curl-sSLhttps://get.rvm.io|bash-sstable出现如下错误:curl:(7)Failedtoconnecttoget.rvm.ioport80:Networkisunreachable非常感谢解决此问题的任何帮助。谢谢 最佳答案 在执行curl之前尝试这个:echoipv4>>~/.curlrc 关于ruby-在Ubuntu14.04中使用Curl安装RVM时出错,我们在Stack
我有一个任务列表(名称、starts_at),我试图在每日View中显示它们(就像iCal)。deftodays_tasks(day)Task.find(:all,:conditions=>["starts_atbetween?and?",day.beginning,day.ending]end我不知道如何将Time.now(例如“2009-04-1210:00:00”)动态转换为一天的开始(和结束),以便进行比较。 最佳答案 deftodays_tasks(now=Time.now)Task.find(:all,:conditio
安装Rails时,一切都很好,但后来,我写道:rails-v和输出:/home/toshiba/.rvm/rubies/ruby-2.2.1/lib/ruby/site_ruby/2.2.0/rubygems/core_ext/kernel_require.rb:54:in`require':cannotloadsuchfile--rails/cli(LoadError)from/home/toshiba/.rvm/rubies/ruby-2.2.1/lib/ruby/site_ruby/2.2.0/rubygems/core_ext/kernel_require.rb:54:in`r
什么是0day漏洞?0day漏洞,是指已经被发现,但是还未被公开,同时官方还没有相关补丁的漏洞;通俗的讲,就是除了黑客,没人知道他的存在,其往往具有很大的突发性、破坏性、致命性。0day漏洞之所以称为0day,正是因为其补丁永远晚于攻击。所以攻击者利用0day漏洞攻击的成功率极高,往往可以达到目的并全身而退,而防守方却一无所知,只有在漏洞公布之后,才后知后觉,却为时已晚。“后知后觉、反应迟钝”就是当前安全防护面对0day攻击的真实写照!为了方便大家理解,中科三方为大家梳理当前安全防护模式下,一个漏洞从发现到解决的三个时间节点:T0:此时漏洞即0day漏洞,是已经被发现,还未被公开,官方还没有相
提供3种Ubuntu系统安装微信的方法,在Ubuntu20.04上验证都ok。1.WineHQ7.0安装微信:ubuntu20.04安装最新版微信--可以支持微信最新版,但是适配的不是特别好;比如WeChartOCR.exe报错。2.原生微信安装:linux系统下的微信安装(ubuntu20.04)--微信适配的最好,反应最快,但是微信版本只到2.1.1,版本太老,很多功能都没有。3.深度deepin-wine6安装微信:ubuntu20.04+系统deepin-wine6安装新版微信--综合比较好,当前个人使用此种方法1个月,微信版本3.4;没什么大问题,尚可。一、WineHQ7.0安装微信