隐私信息检索(Private information retrieval PIR)也称为隐匿查询或匿踪查询,在医疗、股票、金融、社交等领域中都有大量应用场景。近年来PIR技术研究逐渐丰富,行业对应用PIR实现隐私保护的呼声也随之高涨。
对查询进行了压缩,通信量降低了274倍;
在近年的PIR协议研究中,特别是基于HE的PIR协议有很多进展,且大多数都是和SealPIR进行对比,因此理解SealPIR的原理也就有助于理解和跟踪he-based PIR近年来的发展。
本文将为小伙伴们介绍基于同态的隐私信息检索协议-SealPIR,欢迎大家在本文留言讨论。
隐私信息检索(Private information retrieval PIR)是对信息检索(information retrieval IR)的一种扩展,最早在[CKGS95][3]中提出,用于保护用户查询信息,防止数据持有方得到用户的检索条件。
PIR协议目标可以定义为:Alice有共N行的数据库D,每一行的数据大小为L。Bob希望查询获得其中指定位置的某一行,但是不想告诉Alice自己查询的是哪一行。
隐私信息检索协议(PIR)需要满足正确性和安全性两方面的要求:
正确性:用户得到要查询的数据
安全性:服务端 无法知道 用户查询的是哪条数据
多服务器PIR(MultiServer-PIR)
多服务器PIR协议大体流程如下:
单服务器PIR(SingleServer-PIR)
基于同态的单服务器PIR方案,大体流程如下:
服务端有n个元素的数据库?={?1,?2,…,??},用户查询第?个元素,通过执行PIR协议,用户得到??,服务端不知道用户查询?的信息。由于用户的查询条件在一个连续的集合[1…?],Index PIR也称为Dense-PIR。
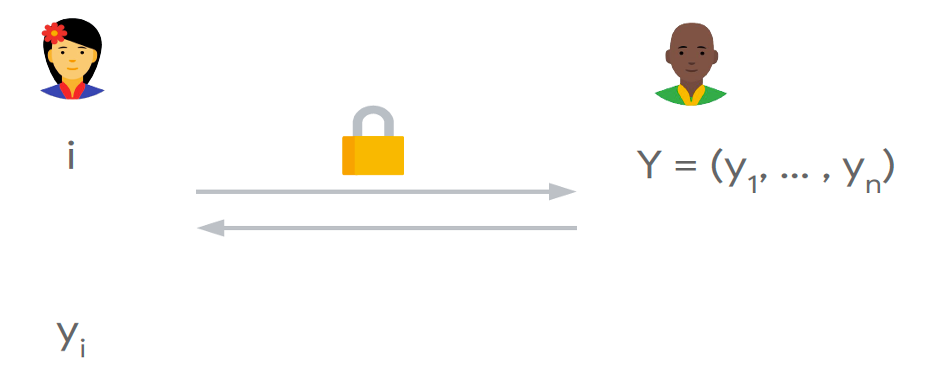
Keyword PIR/Sparse PIR
服务端的数据是(key,value)对构成的n个元素的数据库,用户选择自己要查询的key,通过执行PIR协议,用户得到key对应的value。这里查询条件key不能覆盖一个连续集合,例如:手机号或身份证,也称为Sparse PIR。
PIR的性能指标主要包括计算量和通信量。
计算量:计算量一般指的是服务端的计算量。
通信量:通信量可细分为查询请求的通信量和响应的通信量。
Trivial PIR中服务端没有计算量,将数据全部发给客户端,客户端在本地查询,通信量跟数据库中数据量n相关。因此PIR的通信量要求小于数据库的容量。对比IT-PIR和CPIR的计算量和通信量可以看到,IT-PIR在计算量较少,但通信量较大;CPIR计算量较大,但通信量较小。
除了计算量和通信量两个指标外,有些论文里还引入了成本(monetary)作为指标,成本(monetary)指标实际上是对计算量和通信量平衡得到的指标,更适用于实际业务需求。
| 多项式次数 | 明文模 | 密文模 |
| 2048 |
54bit |
|
|
4096 |
38bit |
109bit 2*36+37 |
|
8192 |
17bit |
218bit 243+344 |
SealPIR中用到的同态运算:
密文加法:
明文?1(?),?2(?)对应的密文是?1和?2,?1+?2是?1(?)+?2(?)的密文。
明文乘密文:
明文?1(?)对应的密文是?1,?2(?)·?1是?1(?)·?2(?)的密文。
替换:
明文?(?)对应的密文是?,对于奇数?,???(?,?)是?(??)的密文。
例如,?(?)=7+?2+2?3,???(?,3)得到?(?3)=7+{?3}2+2{?3}3=7+?6+2?9的密文。
SHE的同态运算会引起噪声的增长,当噪声超过一定限制时,无法解密得到明文,所以要适当选择SHE算法的参数,及控制同态运算的噪声增长。
HE-based PIR基本原理如下图所示:
假设服务端数据量为?,基本流程如下
HE-based PIR协议可以抽象为四个子算法,即(Setup,Query,Answer,Extract),如下图所示:
查询请求的计算量和通信量都大,需要生成和发送?个密文;
查询的db_index需要转换为plaintext_index
假设数据库中数据长度为288字节(SealPIR论文中给出的长度),BFV参数选择:多项式次数8192,明文模16bit,举例说明一下pack的效果:
显著减少通信量,服务端增加一个额外的Expand操作得到查询密文向量。
查询向量(0,...,0,1,0,...,0)压缩到一个HE明文多项式为例,查询向量中的每个分量对应为HE明文多项式中的系数。
?0+?1?+...+??-2??-2+??-1??-1=??????_?????,其中:??=0,?≠?????_????? , ??=1,?=?????_?????。
对查询明文进行加密,得到?(?0+?1?+...+??-2??-2+??-1??-1)=?(??????_?????)。
服务端接收到查询密文后,执行Expand算法,得到查询密文向量:(?(0),...,?(0),?(1),?(0),...,?(0))。
还是以上面packing的参数举例,每个HE明文可以pack 56个数据库数据,客户端查询时,将db_index转换为plain_index,即对HE明文数据库进行查询,最多可以查询8192个HE明文,转换成数据库数据,最多可以查询8192*56=458752条数据,不能满足实际业务中的需求。
为了满足实际将查询向量压缩到多个HE明文来表示查询向量,对于百万数据来讲,需要????(1000000/8192)=123个HE明文,对应123个HE密文,才能表示百万数据的查询向量。为了进一步压缩查询密文的数量,可以使用下面的多维表示方法。
Expand算法的详细描述和证明可以参考[ACLS18][2]论文中的内容。
二维查询时将数据库数据表示为√?*√?的矩阵,减少查询向量
服务端:
客户端:
客户端收到?个密文向量,使用私钥??解密,将其组合成密文???(?[?,?]),对使用私钥??解密???(?[?,?])得到真正的查询HE明文?[?,?],对HE明文?[?,?]中对应的系数进行组合,得到真正查询的数据。
SealPIR论文中还给出了通过PBC(probabilistic batch code)将数据库中的内容分成若干batch,同时执行k个查询时,分别对不同的batch进行查询,降低整体的性能开销。论文给出了基于CuckooHash的PBC构造方案。
CuckooHash的hash数为3,bin数量为1.5?,k为同时查询的数量。
服务端 预处理:
对DB中n个index,分别计算cuckooHash的3个Hash,得到3个bin_index,将(db_index, data)插入到3个bin_index中。
客户端 预处理:
对DB中n个index,分别计算cuckooHash的3个Hash,得到3个bin_index,将(db_index)插入到3个bin_index中。
将k个查询,通过cuckooHash,插入到?=1.5?个bin中,对空的bin进行随机填充。
从上图中可以看到,客户端生成的是CuckooHashTable和SimpleHashTable两张表,服务端生成的SimpleHashTable。客户端和服务端SimpleHashTable的差别在于,服务端SimpleHashTable有实际待查询的数据,服务端SimpleHashTable只是模拟了服务端插入过程,bin中有db_index。
发表在USENIX21年的[ALP+21][7]
发表在CCS21年的OnionPIR:[MCR21][8]
[ALP+21]题目是《Communication–Computation Trade-offs in PIR》是计算量和通信量平衡的PIR方案,该方案显著降低了查询响应的通信量,从成本(monetary)的角度看比SealPIR降低了35%。
OnionPIR利用了somewhat homomorphic encryption(SHE)最新的进展,将两种lattice-based SHE 方案(BFV 和 RGSW)组合在一起,降低了查询响应的大小和计算量。还设计了基于状态(stateful)的PIR。
从上面的数据看到,虽然相应的改进协议对查询响应大小都有较大改进,但整体运行时间方面和SealPIR差别不大,由于引入了更复杂的算法,实现成本也会变得更高,综合来看SealPIR在实际应用中还是相对较好的选择。
[3][CKGS95] B. Chor, O. Goldreich, E. Kushilevitz, and M. Sudan"Private information retrieval", in Proceedings of IEEE 36th Annual Foundations of Computer Science, pp. 41-50, Oct 1995.
[4][BGI16] Elette Boyle, Niv Gilboa, and Yuval Ishai.Function secret sharing: Improvements and extensions. In CCS, 2016.
[5][BFV12] Junfeng Fan and Frederik Vercauteren. 2012.Somewhat Practical Fully Homomorphic Encryption.IACR Cryptol. ePrint Arch. 2012 (2012), 144.
[6][Brakerski12] Zvika Brakerski.Fully Homomorphic Encryption without Modulus Switching from Clas-sical GapSVP. IACR Cryptology ePrint Archive, 2012:78, 2012.
[7][ALP+21] Asra Ali, Tancrède Lepoint, Sarvar Patel, Mariana Raykova, Phillipp Schoppmann, Karn Seth, and Kevin Yeo.
Communication-computation trade-o s in PIR. In USENIX Security, 2021.
[8][MCR21] M. Mughees, Hao Chen, Ling RenOnionPIR: Response Efficient Single-Server PIR, CCS'21.
[9][CGN98] Benny Chor, Niv Gilboa, and Moni Naor.Private information retrieval by keywords.
IACR Cryptology ePrint Archive, 1998:3, 1998.
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at