 论文链接:https://link.springer.com/article/10.1007/s11263-022-01737-y论文备份链接:https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf代码:https://github.com/layumi/U_turn作者:Zhedong Zheng, Liang Zheng, Yi Yang and Fei Wu与早期版本相比,
论文链接:https://link.springer.com/article/10.1007/s11263-022-01737-y论文备份链接:https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf代码:https://github.com/layumi/U_turn作者:Zhedong Zheng, Liang Zheng, Yi Yang and Fei Wu与早期版本相比,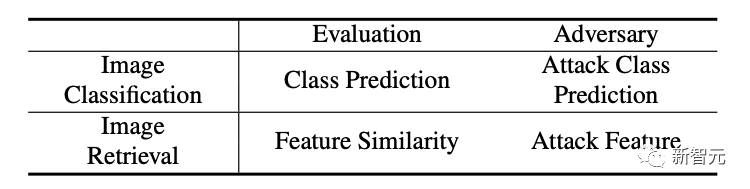 3. 检索问题还有一个特点就是open set也就是说测试的时候类别往往是训练时没见过的。如果大家熟悉cub数据集,在检索设置下,训练的时候训练集合100多种鸟,和测试时测试100多种鸟,这两个100种是没有overlapp种类的。纯靠提取的视觉特征来匹配和排序。所以一些分类攻击方法不适合攻击检索模型,因为攻击时基于类别预测的graident往往是不准的。4. 检索模型在测试时,有两部分数据一部分是查询图像query,一部分是图像库 gallery(数据量较大,而且一般不能access)。考虑到实际可行性,我们方法将主要瞄准攻击query的图像来导致错误的检索结果。
3. 检索问题还有一个特点就是open set也就是说测试的时候类别往往是训练时没见过的。如果大家熟悉cub数据集,在检索设置下,训练的时候训练集合100多种鸟,和测试时测试100多种鸟,这两个100种是没有overlapp种类的。纯靠提取的视觉特征来匹配和排序。所以一些分类攻击方法不适合攻击检索模型,因为攻击时基于类别预测的graident往往是不准的。4. 检索模型在测试时,有两部分数据一部分是查询图像query,一部分是图像库 gallery(数据量较大,而且一般不能access)。考虑到实际可行性,我们方法将主要瞄准攻击query的图像来导致错误的检索结果。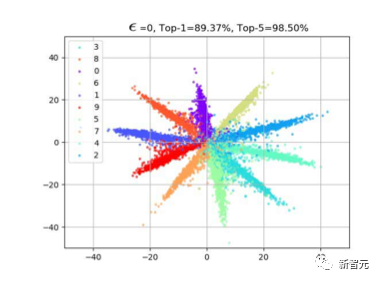 2. 所以我们提出了一个特别简单的方法,就是让特征调头。如下图,其实有两种常见的分类攻击方法也可以一起可视化出来。如(a)这种就是把分类概率最大的类别给压下去(如Fast Gradient),通过给-Wmax,所以有红色的梯度传播方向沿着反Wmax;如(b)还有一种就是把最不可能的类别的特征给拉上来(如Least-likely),所以红色的梯度沿着Wmin。3. 这两种分类攻击方法在传统分类问题上当然是很直接有效的。但由于检索问题中测试集都是没见过的类别(没见过的鸟种),所以自然f的分布没有那么紧密贴合Wmax或者Wmin,因此我们的策略很简单,既然有了f,那我们直接把f往-f去移动就好了,如图(c)。这样在特征匹配阶段,原来排名高的结果,理想情况下,与-f算cos similarity,从接近1变到接近-1,反而会排到最低。达成了我们攻击检索排序的效果。4. 一个小extension。在检索问题中,我们还常用multi-scale来做query augmentation,所以我们也研究了一下怎么在这种情况下维持攻击效果。(主要难点在于resize操作可能把一些小却关键的抖动给smooth了。)其实我们应对的方法也很简单,就如model ensemble一样,我们把多个尺度的adversarial gradient做个ensemble平均就好。
2. 所以我们提出了一个特别简单的方法,就是让特征调头。如下图,其实有两种常见的分类攻击方法也可以一起可视化出来。如(a)这种就是把分类概率最大的类别给压下去(如Fast Gradient),通过给-Wmax,所以有红色的梯度传播方向沿着反Wmax;如(b)还有一种就是把最不可能的类别的特征给拉上来(如Least-likely),所以红色的梯度沿着Wmin。3. 这两种分类攻击方法在传统分类问题上当然是很直接有效的。但由于检索问题中测试集都是没见过的类别(没见过的鸟种),所以自然f的分布没有那么紧密贴合Wmax或者Wmin,因此我们的策略很简单,既然有了f,那我们直接把f往-f去移动就好了,如图(c)。这样在特征匹配阶段,原来排名高的结果,理想情况下,与-f算cos similarity,从接近1变到接近-1,反而会排到最低。达成了我们攻击检索排序的效果。4. 一个小extension。在检索问题中,我们还常用multi-scale来做query augmentation,所以我们也研究了一下怎么在这种情况下维持攻击效果。(主要难点在于resize操作可能把一些小却关键的抖动给smooth了。)其实我们应对的方法也很简单,就如model ensemble一样,我们把多个尺度的adversarial gradient做个ensemble平均就好。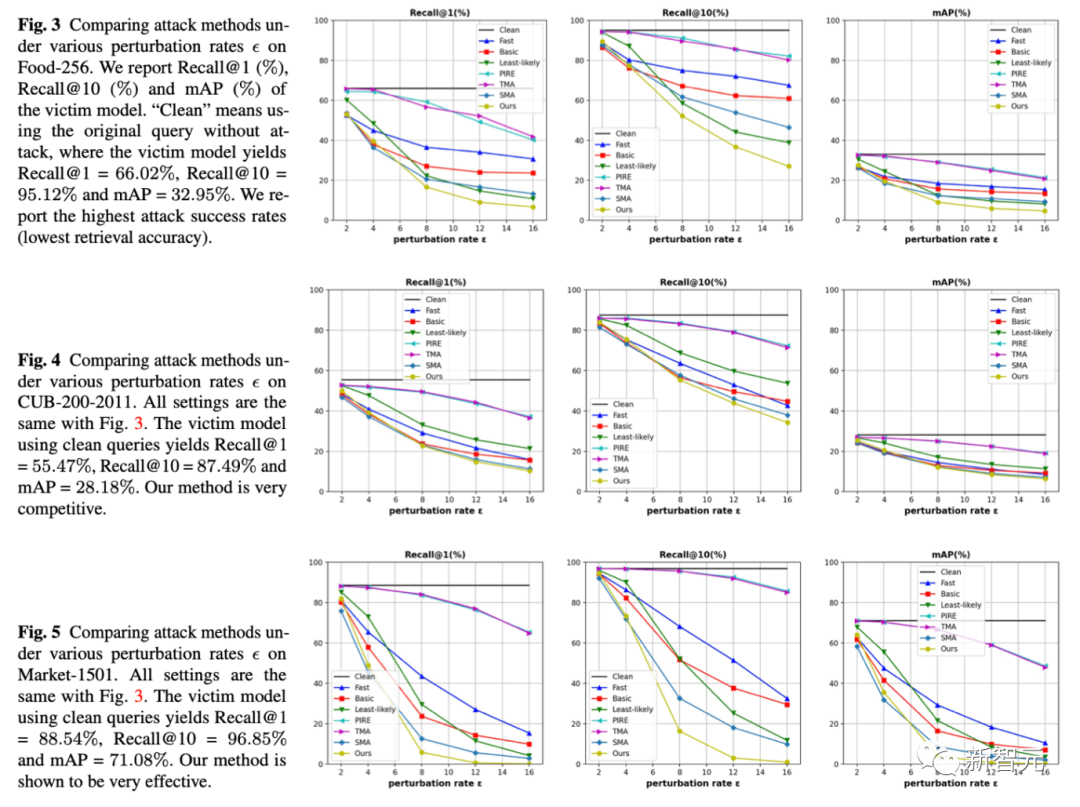 2. 同时我们也提供了在5个数据集上(Food,CUB,Market,Oxford,Paris)的定量实验结果
2. 同时我们也提供了在5个数据集上(Food,CUB,Market,Oxford,Paris)的定量实验结果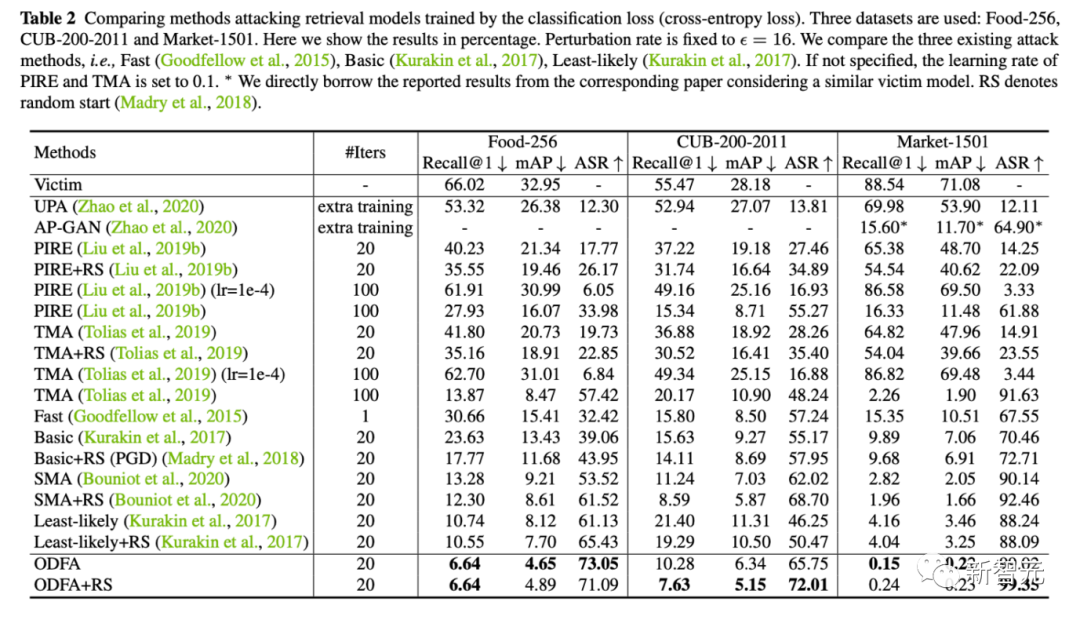
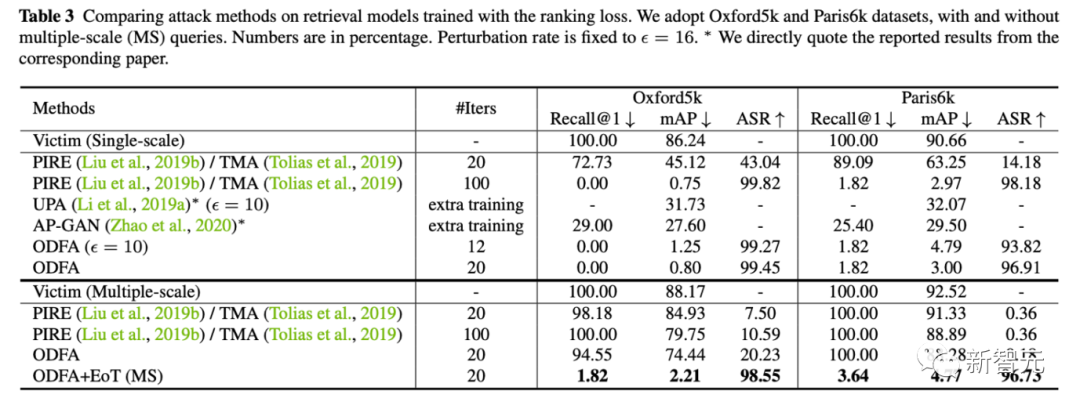 3. 为了展示模型的机制,我们也尝试攻击了Cifar10上的分类模型。可以看到我们改变最后一层特征的策略,对于top-5也有很强的压制力。对于top-1,由于没有拉一个候选类别上来,所以会比least-likely略低一些,但也差不多。
3. 为了展示模型的机制,我们也尝试攻击了Cifar10上的分类模型。可以看到我们改变最后一层特征的策略,对于top-5也有很强的压制力。对于top-1,由于没有拉一个候选类别上来,所以会比least-likely略低一些,但也差不多。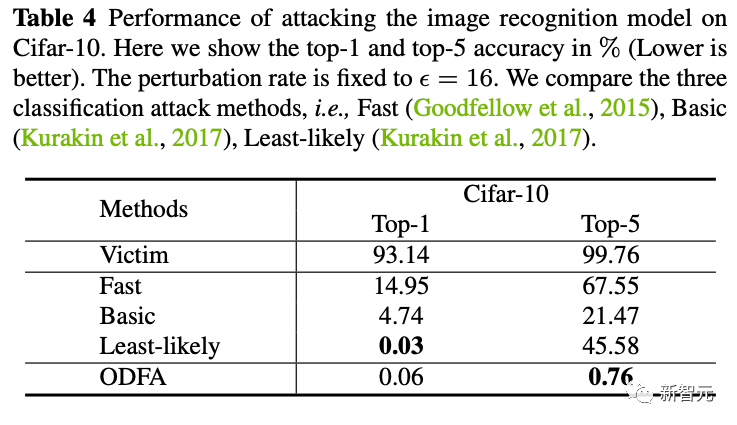 4. 黑盒攻击我们也尝试了使用ResNet50生成的攻击样本去攻击一个黑盒的DenseNet模型(这个模型的参数我们是不可获取的)。发现也能取得比较好的迁移攻击能力。
4. 黑盒攻击我们也尝试了使用ResNet50生成的攻击样本去攻击一个黑盒的DenseNet模型(这个模型的参数我们是不可获取的)。发现也能取得比较好的迁移攻击能力。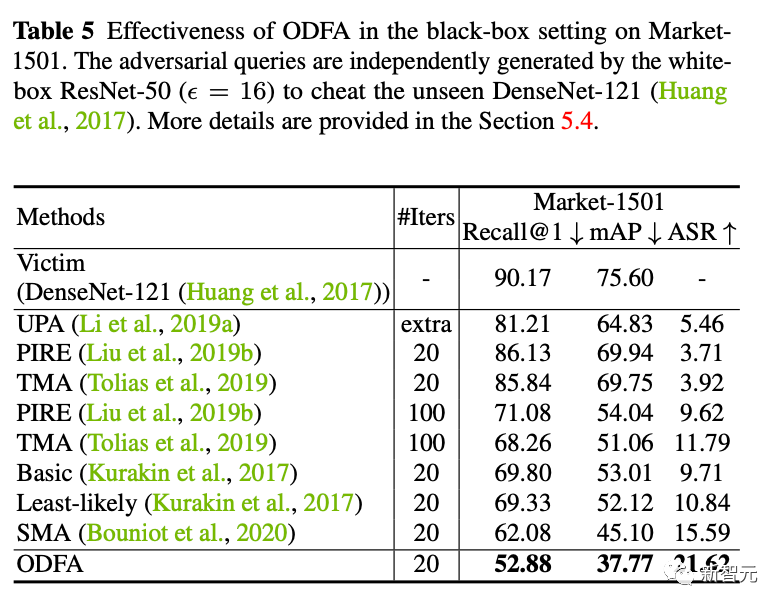 5. 对抗防御我们采用online adversarial training的方式来训练一个防御模型。我们发现他在接受新的白盒攻击的时候依然是不行的,但是比完全没有防御的模型在小抖动上会更稳定一些(掉点少一些)。
5. 对抗防御我们采用online adversarial training的方式来训练一个防御模型。我们发现他在接受新的白盒攻击的时候依然是不行的,但是比完全没有防御的模型在小抖动上会更稳定一些(掉点少一些)。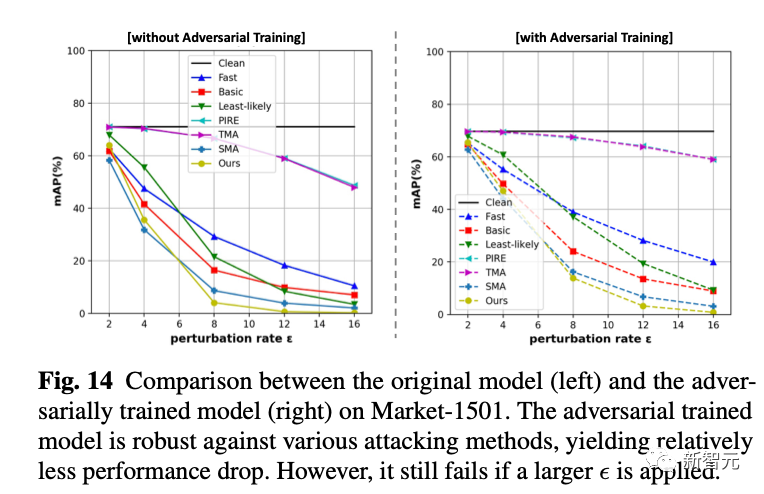 6. 特征移动的可视化这也是我觉得最喜欢的一个实验。我们利用Cifar10,把最后分类层的维度改为2,来plot分类层的feature的变化。如下图,随着抖动幅度epsilon的变大,我们可以看到样本的特征慢慢「调头」了。比如大部分橙色的特征就移动到对面去了。
6. 特征移动的可视化这也是我觉得最喜欢的一个实验。我们利用Cifar10,把最后分类层的维度改为2,来plot分类层的feature的变化。如下图,随着抖动幅度epsilon的变大,我们可以看到样本的特征慢慢「调头」了。比如大部分橙色的特征就移动到对面去了。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
我是Cucumber测试的新手。我创建了两个特征文件:events.featurepartner.feature并将我的步骤定义放在step_definitions文件夹中:./step_definitions/events.rbpartner.rbCucumber似乎在所有.rb文件中查找步骤信息。有没有办法限制该功能查看特定的步骤定义文件?我之所以要这样做,是因为即使我使用了--guess标志,我也会遇到不明确的匹配错误。我之所以要这样做,有以下几个原因。我正在测试CMS,并希望在不同的功能中测试每种不同的内容类型(事件和合作伙伴)。事件.特征Feature:AddpartnerA
我们在Ubuntu14.04和Gitlab9.3.7上运行,运行良好。我们正在尝试更新到Gitlabv9.3.8的最新安全补丁,但它给我们这个错误:Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension.currentdirectory:/home/git/gitlab/vendor/bundle/ruby/2.3.0/gems/re2-1.0.0/ext/re2/usr/local/bin/ruby-r./siteconf20170720-19622-15i0edf.rbextconf.rbcheckingformain(
capybara找不到在我的cucumber测试中用它的id标记。当我save_and_open_page时,我能够看到该元素.但我无法通过has_css?找到它或find:pry(#)>page.html.scan(/notice_sent/).count=>1pry(#)>page.html.scan(/id=\"notice_sent\"/).count=>1pry(#)>page.find('#notice_sent')Capybara::ElementNotFound:Unabletofindcss"#notice_sent"from/Users/me/.gem/ruby/2
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url
在开发模式下:nil.id=>"Calledidfornil,whichwouldmistakenlybe4--ifyoureallywantedtheidofnil,useobject_id"在生产模式中:nil.id=>4为什么? 最佳答案 在您的环境配置中查找包含以下内容的行:#Logerrormessageswhenyouaccidentallycallmethodsonnil.config.whiny_nils=true#orfalseinproduction.rb这是为了防止您在开发模式下调用nil上的方法。我猜他们在生
完成这个有困难。我正在使用seed.rb+factory_girl来使用rakedb:seed填充数据库。(我知道固定装置存在,但我想以这种方式完成,这只是一个示例,数据库将填充复杂的关联对象。)我的种子.rb:require'factory_girl_rails'["QM","CDC","SI","QS"].eachdo|n|FactoryGirl.create(:grau,nome:n)end还有我的/factories/graus.rbFactoryGirl.definedofactory:graudonomeendend但是当我运行时:rakedb:seed我得到:rakeab
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但
我有一组名为Tasks和Posts的资源,它们之间存在has_and_belongs_to_many(HABTM)关系。还有一个连接它们的值的连接表。create_table'posts_tasks',:id=>falsedo|t|t.column:post_id,:integert.column:task_id,:integerend所以我的问题是如何检查特定任务的ID是否存在于从@post.tasks创建的数组中?irb(main):011:0>@post=Post.find(1)=>#@post.tasks=>[#,#]所以我的问题是,@post.tasks中是否存在"@task