目录
经过前段时间研究,从LeNet-5手写数字入门到最近研究的一篇天气识别。我想干一票大的,因为我本身从事的就是C++/Qt开发,对Qt还是比较熟悉,所以我想实现一个界面化的一个人脸识别。
对卷积神经网络的概念比较陌生的可以看一看这篇文章:卷积实际上是干了什么
想了解神经网络的训练流程、或者环境搭建的可以看这篇文章:环境搭建与训练流程
如果想学习本项目请先去看
第一篇:基于卷积神经网络(tensorflow)的人脸识别项目(一)
第二篇:基于卷积神经网络(tensorflow)的人脸识别项目(二)
第三篇:基于卷积神经网络(tensorflow)的人脸识别项目(三)
具体步骤如下:
本篇主要是对上述步骤中的第四步进行实现。最后分享整个全流程的完整项目代码。
通过OpenCV打开摄像头捕捉人脸区域,然后对图片进行预处理(如灰度化、归一化等等),然后加载模型,把处理后的图片放入模型中进行预测,然后对预测的结果进行一个精度过滤就是对识别率低于90%的结果认为识别不准确,就会输出other表示不能高度识别。正常情况下输出每个文件所对应的label。
将我们之前训练好的模型通过load_model方法进行加载。
MODEL_PATH = './me.face.model.h5'
def load_model(self, file_path=MODEL_PATH):
self.model = load_model(file_path)
这里对图片进行了归一化处理,并对预测结果进行了精度过滤。
注意:K.image_dim_ordering() =\= 'th': 如果报错的话请替换为K.image_data_format() == 'channels_first' “channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。
def face_predict(self, image):
if K.image_data_format() == 'channels_first' and image.shape != (1, 3, IMAGE_SIZE, IMAGE_SIZE):
image = resize_image(image) # 尺寸必须与训练集一致都应该是IMAGE_SIZE x IMAGE_SIZE
image = image.reshape((1, 3, IMAGE_SIZE, IMAGE_SIZE)) # 与模型训练不同,这次只是针对1张图片进行预测
elif K.image_data_format() == 'channels_last' and image.shape != (1, IMAGE_SIZE, IMAGE_SIZE, 3):
image = resize_image(image)
image = image.reshape((1, IMAGE_SIZE, IMAGE_SIZE, 3))
# 浮点并归一化
image = image.astype('float32')
image /= 255
# 给出输入属于各个类别的概率
result = self.model.predict_proba(image)
print('result:', result)
my_result = list(result[0]).index(max(result[0]))
max_result = max(result[0])
print("result最大值下标:", my_result)
if max_result > 0.90:
return my_result
else:
return -1
主要分为以下几步骤:
这个逻辑不是很复杂,下面直接进行代码展示,在代码中也有详细的注释说明:
import cv2
from keras_train import Model
if __name__ == '__main__':
model = Model()# 加载模型
model.load_model(file_path='./model/me.face.model.h5')
color = (0, 255, 0)# 框住人脸的矩形边框颜色
cap = cv2.VideoCapture(0)# 捕获指定摄像头的实时视频流
cascade_path = "./model/haarcascade_frontalface_alt2.xml"# 人脸识别分类器本地存储路径
# 循环检测识别人脸
while True:
_, frame = cap.read() # 读取一帧视频
# 图像灰化,降低计算复杂度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(cascade_path)
# 利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
# 截取脸部图像提交给模型识别这是谁
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
faceID = model.face_predict(image)
#
human = {0: 'use2', 1: 'use3', 2: 'use4', -1: 'others', 3: 'use5', 4: 'LinXi07',
5: 'use7', 6: 'use8', 7: 'use1', 8: 'use9'}
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
# 文字提示是谁
cv2.putText(frame, human[faceID],
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
cv2.imshow("Face Identification System", frame)
# 等待10毫秒看是否有按键输入
k = cv2.waitKey(10)
# 如果输入q则退出循环
if k & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
这里对模型进行测试,并支持多个人脸同时识别,且识别率较高。(忽略掉人脸)
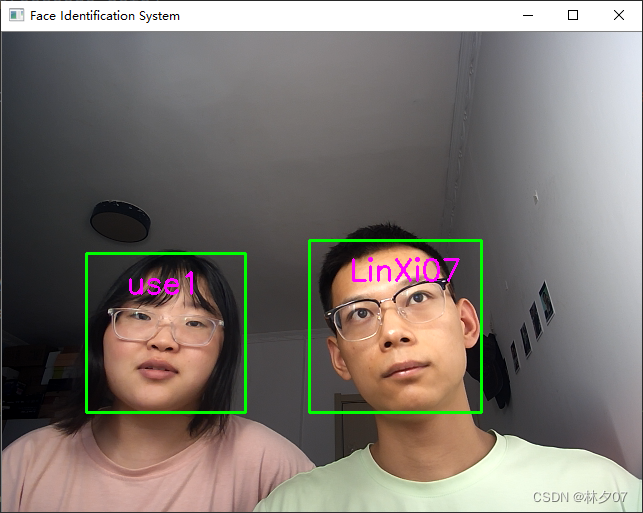
从最开始的收集数据到中间的预处理再到后来的模型建立到最后的测试效果,这一路非常坎坷,不是数据格式不匹配导致报错,就是版本不匹配来回重装环境再就是模型识别率上不去。总算把这个完整的做出来了,路途坎坷但收获不菲。让我们一起加油吧!!!!
这里我以文件进行分类,总共四个文件。
| 文件名 | 说明 |
|---|---|
| frame_capture.py | 制作数据集 |
| keras_train.py | 训练模型 评估模型 |
| load_data.py | 加载数据,预处理 |
| face_predict_use_keras.py | 预测模型 |
然后deep_learning用来存放每个人的照片。model用来存放模型好的模型以及harr分类器。
import cv2
import sys
def catch_usb_video(window_name, camera_idx):
'''使用cv2.imshow()的时候,如果图片太大,会显示不全并且无法调整。
因此在cv2.imshow()的前面加上这样的一个语句:cv2.namedWindow('image', 0),
得到的图像框就可以自行调整大小,可以拉伸进行自由调整。'''
cv2.namedWindow(window_name, 0)
# 视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx)
# 告诉OpenCV使用人脸识别分类器 级联分类器
'''
Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。
'''
classfier = cv2.CascadeClassifier("./model/haarcascade_frontalface_alt2.xml")
# 识别出人脸后要画的边框的颜色,RGB格式
color = (0, 0, 255)
num = 0
while cap.isOpened():
ok, frame = cap.read() # 读取一帧数据
if not ok:
break
# 将当前帧转换成灰度图像
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
# faceRects = [405 237 222 222]
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
# 在原图上框出需要保存的图
x, y, w, h = faceRect
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 将当前帧保存为图片
# frame 是原图,(x - 10, y - 10) 是图片的左上角的那个点,(x + w + 10, y + h + 10)是图片右下角的点
# color, 2 颜色和线的宽度
img_name = '%s/%d.jpg' % ('./deep_learning/zm', num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > (500): # 如果超过指定最大保存数量退出循环
break
# 画出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, 'num:%d' % (num), (x + 30, y + 30), font, 1, (255, 0, 255), 4)
# 超过指定最大保存数量结束程序
if num > (500):
break
# 显示图像
cv2.imshow(window_name, frame)
c = cv2.waitKey(1)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
catch_usb_video("face", 0)
import random
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.models import load_model
from keras import backend as K
from load_data import load_dataset, resize_image, IMAGE_SIZE
class Dataset:
def __init__(self, path_name):
# 训练集
self.train_images = None
self.train_labels = None
# 验证集
self.valid_images = None
self.valid_labels = None
# 测试集
self.test_images = None
self.test_labels = None
# 数据集加载路径
self.path_name = path_name
# 当前库采用的维度顺序
self.input_shape = None
# 加载数据集并按照交叉验证的原则划分数据集并进行相关预处理工作
def load(self, img_rows=IMAGE_SIZE, img_cols=IMAGE_SIZE,
img_channels=3, nb_classes=3):
# 加载数据集到内存
images, labels = load_dataset(self.path_name)
train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size=0.2,
random_state=random.randint(0, 100))
_, test_images, _, test_labels = train_test_split(images, labels, test_size=0.5,
random_state=random.randint(0, 100))
# 当前的维度顺序如果为'th',则输入图片数据时的顺序为:channels,rows,cols,否则:rows,cols,channels
# 这部分代码就是根据keras库要求的维度顺序重组训练数据集
# if K.image_dim_ordering() == 'th': “channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。
if K.image_data_format() == 'channels_first':
train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols)
valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols)
test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols)
self.input_shape = (img_channels, img_rows, img_cols)
else:
train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels)
# 输出训练集、验证集、测试集的数量
print(train_images.shape[0], 'train samples')
print(valid_images.shape[0], 'valid samples')
print(test_images.shape[0], 'test samples')
# 我们的模型使用categorical_crossentropy作为损失函数,因此需要根据类别数量nb_classes将
# 类别标签进行one-hot编码使其向量化,在这里我们的类别只有两种,经过转化后标签数据变为二维
train_labels = np_utils.to_categorical(train_labels, nb_classes)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
test_labels = np_utils.to_categorical(test_labels, nb_classes)
# 像素数据浮点化以便归一化
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
test_images = test_images.astype('float32')
# 将其归一化,图像的各像素值归一化到0~1区间
train_images /= 255
valid_images /= 255
test_images /= 255
self.train_images = train_images
self.valid_images = valid_images
self.test_images = test_images
self.train_labels = train_labels
self.valid_labels = valid_labels
self.test_labels = test_labels
# CNN网络模型类
class Model:
def __init__(self):
self.model = None
# 建立模型
def build_model(self, dataset, nb_classes=3):
# 构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
self.model = Sequential()
# 以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=dataset.input_shape)) # 1 2维卷积层
self.model.add(Activation('relu')) # 2 激活函数层
self.model.add(Convolution2D(32, 3, 3)) # 3 2维卷积层
self.model.add(Activation('relu')) # 4 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 5 池化层
self.model.add(Dropout(0.25)) # 6 Dropout层
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) # 7 2维卷积层
self.model.add(Activation('relu')) # 8 激活函数层
self.model.add(Convolution2D(64, 3, 3)) # 9 2维卷积层
self.model.add(Activation('relu')) # 10 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 11 池化层
self.model.add(Dropout(0.25)) # 12 Dropout层
self.model.add(Flatten()) # 13 Flatten层
self.model.add(Dense(512)) # 14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) # 15 激活函数层
self.model.add(Dropout(0.5)) # 16 Dropout层
self.model.add(Dense(nb_classes)) # 17 Dense层
self.model.add(Activation('softmax')) # 18 分类层,输出最终结果
# 输出模型概况
self.model.summary()
# 训练模型
def train(self, dataset, batch_size=20, nb_epoch=10, data_augmentation=True):
# 参数batch_size的作用即在于此,其指定每次迭代训练样本的数量
# nb_epoch 训练轮换次数
sgd = SGD(lr=0.01, decay=1e-6,
momentum=0.9, nesterov=True) # 采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy']) # 完成实际的模型配置工作
# 不使用数据提升,所谓的提升就是从我们提供的训练数据中利用旋转、翻转、加噪声等方法创造新的
# 训练数据,有意识的提升训练数据规模,增加模型训练量
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size=batch_size,
nb_epoch=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels),
shuffle=True)
# 使用实时数据提升
else:
# 定义数据生成器用于数据提升,其返回一个生成器对象datagen,datagen每被调用一
# 次其生成一组数据(顺序生成),节省内存,其实就是python的数据生成器
datagen = ImageDataGenerator(
featurewise_center=False, # 是否使输入数据去中心化(均值为0),
samplewise_center=False, # 是否使输入数据的每个样本均值为0
featurewise_std_normalization=False, # 是否数据标准化(输入数据除以数据集的标准差)
samplewise_std_normalization=False, # 是否将每个样本数据除以自身的标准差
zca_whitening=False, # 是否对输入数据施以ZCA白化
rotation_range=20, # 数据提升时图片随机转动的角度(范围为0~180)
width_shift_range=0.2, # 数据提升时图片水平偏移的幅度(单位为图片宽度的占比,0~1之间的浮点数)
height_shift_range=0.2, # 同上,只不过这里是垂直
horizontal_flip=True, # 是否进行随机水平翻转
vertical_flip=False) # 是否进行随机垂直翻转
# 计算整个训练样本集的数量以用于特征值归一化、ZCA白化等处理
datagen.fit(dataset.train_images)
# 利用生成器开始训练模型
self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels,
batch_size=batch_size),
samples_per_epoch=dataset.train_images.shape[0],
nb_epoch=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels))
MODEL_PATH = './me.face.model.h5'
def save_model(self, file_path=MODEL_PATH):
self.model.save(file_path)
def load_model(self, file_path=MODEL_PATH):
self.model = load_model(file_path)
def evaluate(self, dataset):
score = self.model.evaluate(dataset.test_images, dataset.test_labels, verbose=1)
print("%s: %.2f%%" % (self.model.metrics_names[1], score[1] * 100))
def face_predict(self, image):
# if K.image_dim_ordering() == 'th': “channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。
if K.image_data_format() == 'channels_first' and image.shape != (1, 3, IMAGE_SIZE, IMAGE_SIZE):
image = resize_image(image) # 尺寸必须与训练集一致都应该是IMAGE_SIZE x IMAGE_SIZE
image = image.reshape((1, 3, IMAGE_SIZE, IMAGE_SIZE)) # 与模型训练不同,这次只是针对1张图片进行预测
elif K.image_data_format() == 'channels_last' and image.shape != (1, IMAGE_SIZE, IMAGE_SIZE, 3):
image = resize_image(image)
image = image.reshape((1, IMAGE_SIZE, IMAGE_SIZE, 3))
# 浮点并归一化
image = image.astype('float32')
image /= 255
# 给出输入属于各个类别的概率
result = self.model.predict_proba(image)
print('result:', result)
my_result = list(result[0]).index(max(result[0]))
max_result = max(result[0])
print("result最大值下标:", my_result)
if max_result > 0.90:
return my_result
else:
return -1
if __name__ == '__main__':
dataset = Dataset('.\\deep_learning')
dataset.load(nb_classes=9)
# 训练模型
model = Model()
model.build_model(dataset, nb_classes=9)
model.train(dataset)
model.save_model(file_path='./model/me.face.model.h5')
# 评估模型,确认模型的精度是否能达到要求
model = Model()
model.load_model(file_path='./model/me.face.model.h5')
model.evaluate(dataset)
import os
import numpy as np
import cv2
IMAGE_SIZE = 64
# 按照指定图像大小调整尺寸
def resize_image(image, height=IMAGE_SIZE, width=IMAGE_SIZE):
top, bottom, left, right = (0, 0, 0, 0)
# 获取图像尺寸
h, w, _ = image.shape
# 对于长宽不相等的图片,找到最长的一边
longest_edge = max(h, w)
# 计算短边需要增加多上像素宽度使其与长边等长
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass
# RGB颜色
BLACK = [0, 0, 0]
# 给图像增加边界,是图片长、宽等长,cv2.BORDER_CONSTANT指定边界颜色由value指定
constant = cv2.copyMakeBorder(image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=BLACK)
# 调整图像大小并返回
return cv2.resize(constant, (height, width))
# 读取训练数据
images = []
labels = []
def read_path(path_name):
for dir_item in os.listdir(path_name):
# 从初始路径开始叠加,合并成可识别的操作路径
full_path = os.path.abspath(os.path.join(path_name, dir_item))
#
if os.path.isdir(full_path): # 如果是文件夹,继续递归调用
read_path(full_path)
else: # 文件
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE)
images.append(image)
labels.append(path_name)
return images, labels
# 给文件夹后缀,加标注,使其向量化,如果添加新的人,就可以对应文件夹和下标
# 这里我随便写的label 因为涉及到隐私。
def indentify(label):
if label.endswith('use'):
return 0
elif label.endswith('use'):
return 1
elif label.endswith('use'):
return 2
elif label.endswith('use'):
return 3
elif label.endswith('use'):
return 4
elif label.endswith('use'):
return 5
elif label.endswith('use'):
return 6
elif label.endswith('use'):
return 7
elif label.endswith('use'):
return 8
# 从指定路径读取训练数据
def load_dataset(path_name):
images, labels = read_path(path_name)
# 将输入的所有图片转成四维数组,尺寸为(图片数量*IMAGE_SIZE*IMAGE_SIZE*3)
# 图片为64 * 64像素,一个像素3个颜色值(RGB)
images = np.array(images)
print(images.shape)
labels = np.array([indentify(label) for label in labels])
print(images,labels)
return images, labels
if __name__ == '__main__':
images, labels = load_dataset('./deep_learning')
import cv2
from keras_train import Model
if __name__ == '__main__':
# 加载模型
model = Model()
model.load_model(file_path='./model/me.face.model.h5')
# 框住人脸的矩形边框颜色
color = (0, 255, 0)
# 捕获指定摄像头的实时视频流
cap = cv2.VideoCapture(0)
# 人脸识别分类器本地存储路径
cascade_path = "./model/haarcascade_frontalface_alt2.xml"
# 循环检测识别人脸
while True:
_, frame = cap.read() # 读取一帧视频
# 图像灰化,降低计算复杂度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(cascade_path)
# 利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
# 截取脸部图像提交给模型识别这是谁
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
faceID = model.face_predict(image)
# 这里我随便写的,因为涉及到隐私。
human = {0: 'use3', 1: 'use4', 2: 'use8', -1: 'others', 3: 'use88', 4: 'LinXi07',
5: 'use2', 6: 'use', 7: 'use1', 8: 'use7'}
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
# 文字提示是谁
cv2.putText(frame, human[faceID],
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
cv2.imshow("Face Identification System", frame)
# 等待10毫秒看是否有按键输入
k = cv2.waitKey(10)
# 如果输入q则退出循环
if k & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n