外呼平台是一个与通话相关的多功能管理平台,将通信资源与相关应用技术的管理能力平台化,高效利用通信资源,外呼能力赋能产品服务创新和客户响应能力,同时无缝对接业务、数据、AI等其他能力。外呼平台集成了资源隔离和资源分配,机器人和IVR会话管理,坐席管理等多种应用能力。完成资源的高效利用和运营的高效管理,做到配置化,可视化,分钟级别告警。下面主要围绕外平台,建设过程中遇到哪些问题,又是怎么解决展开的。
外呼给人的第一印象就是打电话,但是加上了平台,就会变成怎么高效拨打电话,高效运营管理和新的赋能,图1是外呼平台的网络拓扑图。
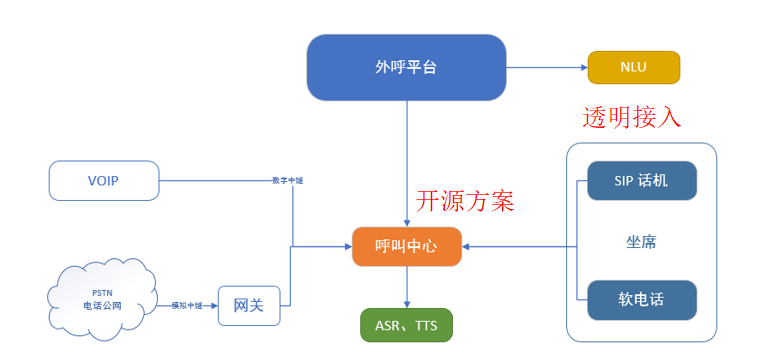
外呼平台网络拓扑图
外呼平台是以开源的呼叫中心服务器作为中心节点,图中左边是运营商网络,通常指三大运营商以及其代理运营商,统称为线路资源;右侧是坐席部分,可以支持sip话机,软电话和web话机;外呼平台通过与呼叫中心服务器交互,来控制通话的建立,挂断,重拨,播放指定语音等功能。外呼平台的建设涉遇到了多个技术选型和问题,下面会逐一说明怎么做的技术选型和问题解决。
1,呼叫中心服务器选型
从图1的外呼中心网络拓扑图中可以看出,外呼中心服务器的选择将直接决定整个系统的架构,目前常见的开源服务器有Asterisk和FreeSwitch(后续简称FS)。Asterisk起步较早,单机性能已经有些落后;FS起步晚,所以更加贴近当前的技术需求,具备跨平台,伸缩性强,也支持多协议,而且社区活跃,遇到问题可以通过社区寻求帮助,可查阅的资料也更多,经过调研也发现,很多厂商的呼叫中心都是采用的FS。其他厂商经过实践结果表明,FS具备更高的性能;由于资料更加完备,学习成本也会更加低,最主要的是,已有的较多成功落地的案例,所以选择FS。
2,开发模式选型
FS的开发模式有两种:一种是面向服务器开发,这种开发模式是基于脚本内嵌的方式,主要开发lua脚本,开发人员的学习成本高,不易维护,且无法控制会话流程,脚本之间无法复用;另外一种是面向客户端开发,如下图所示,FS有java客户端,开发人员可以使用自己熟悉的开发语言(java),通过客户端转换后,控制整个会话流程,方便定制,易扩展,学习成本也低。虽然lua脚本执行效率更高,但是客户端更加方便定制化开发,易于开发,最终选择面向java客户端来控制FS。
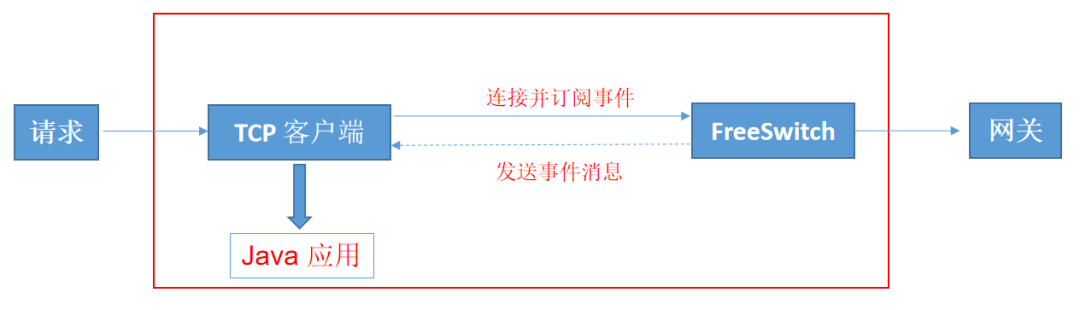
面向客户端开发示意图

通话经过的各个节点示意图
如图3所示,一通电话的建立,需要经过的节点包含FS服务器,网关,运营商三个关键节点,任务一个节点出现问题,都会导致通话失败。
使用FS作为呼叫中心服务器,单台服务器的承载能力只能同时支持1000-1500通会话,外呼平台在建设初期采用VIP实现双机热备,保证外呼过程的高可用。随着业务发展,单台FS服务器已经无法满足业务需要,FS服务器需要从双机热备架构转换到集群架构。
1.2.1 事件处理瓶颈
从双机热备切换到集群架构有个阻塞点:java应用单机处理事件的能力有限,如果不解决这个问题,集群的规模将会受到限制。如图4所示,每一台java后台应用服务器,与每一台FS服务器建立socket连接,如图中红色箭头所示。java后台应用,用事件通信的方式来控制FS,这其中存在一个弊端在于,FreeSwitch每次以广播的方式发送响应事件信息,每台java后台应用需要处理所有FS发送的事件,包含自己需要处理和不需要自己处理的事件,用n表述java后台应用服务器的数量,那么一台java后台服务期望处理的数量是1,但实际处理的事件数量就是n,因为其他n-1台服务器发送的事件,在广播机制,会收到其他n-1台应用服务器的响应事件。这样的话,整个外呼的上线就是单台java应用服务器的单机处理上线。
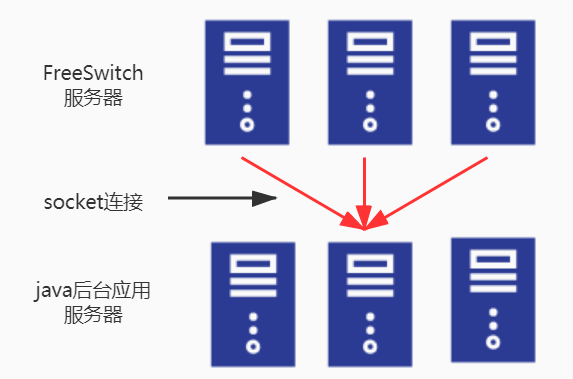
java应用控制FreeSwitch示意图
由于FS支持发送RabbitMQ,业内很多的做法是在FS和java后台应用服务器之间加一层RabbitMQ,然后集中做事件分发,这种方式会导致架构更加复杂,而且事件转发层也会逐渐成为瓶颈。并且当前公司支持的是RocketMQ,如果新搭建一套RabbitMQ,不仅增加了架构复杂性,运维成本也会增加。这种方案只能成为兜底方案。
问题的关键点在于处理了其他n-1台的的事件,如果能够过滤掉非本机应用发送请求的响应事件,那么问题就完美解决。经过各方面的咨询和调研,业内几乎没有碰到这类问题,主要原因在于量级问题,一般遇到这种量变导致的架构瓶颈问题,要么放弃使用面向客户端的开发方式,改为使用lua脚本执行所有的会话流程,这样就不需要java后台应用控制会话流程;要么使用RabbitMQ作为中间层转发。这两条路都不想选择的情况下,就转到socket连接上做文章,如果在socket接受端能够过滤掉非本机事件,那么也能解决这个问题。通过在事件头部添加本机ip信息,依次作为socket过滤事件的依据,最终得以解决这个问题,如图5所示。需要指出的是,虽然最终还是每台java后台服务器接受了所有事件,但是过滤动作从java应用内部过滤提前至socket接收端过滤,而socket过滤效率又是极高的,socket本身不会成为瓶颈。
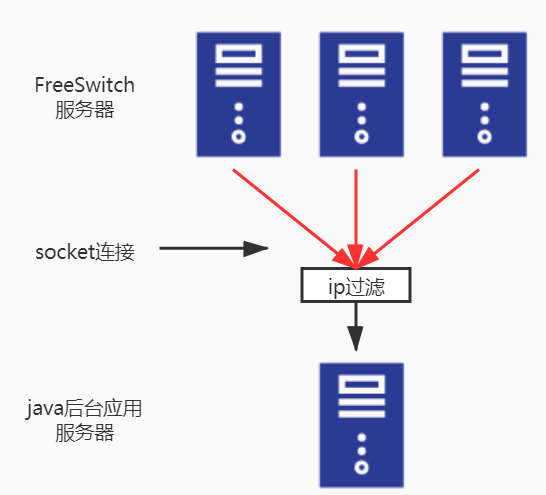
socket执行ip过滤示意图
1.2.2 任务执行要求
外呼平台的主要功能之一是系统自动外呼,其主要工作流程为:不同的业务使用方,批量提交大量任务到外呼平台,形成一个任务池,外呼平台从任务池中获取外呼任务,发起外呼。整个过程,面临这三个难点。
1,速度控制:(1)业务方提交任务的速度远远大于系统处理的速度,外呼平台需要根据自己的能力,自适应的控制处理速度;(2)caps(每秒建立通话数)控制:呼叫中心服务和网关的caps值过大,会造成通话卡顿和延迟;线路商caps值过大,通话请求被拒绝;(3)已经建立会话量控制:如果系统维持的通话量过大,会造成通话卡顿和延迟,甚至服务器宕机。
2,过载保护控制:FS服务器本身不具备过载自我保护能力,当处理的会话过多,会造成通话不顺畅甚至服务器宕机。所以必须控制每台服务器处理外呼的数量,保证服务器运行在一个合理的负载范围内。
3,高触达率和不可重试的业务矛盾:外呼一个重要指标是客户正常触达率,由于外呼过程中经过了多个节点,导致外呼故障的原因多种多样,一种典型的例子:外呼请求已经发出,然后服务器故障,此时用户已经收到电话,但是无法正常的建立通信,所以外呼不能像调用接口一样,多次重试,这样会造成用户投诉,所以需要判断通话无法建立是存在故障还是正常,发生故障时,立即故障转移。目前常见的故障有两种:(1)线路商提供的线路故障;(2)外呼中心服务器故障。
1.2.3 集群建设
外呼平台采用任务调度和心跳检测来完成符合实际需要的集群。
1,秒级任务调度和任务执行隔离:调度执行分离达到各种资源负载均衡,控制caps值和通话量;计数资源使用情况,实现过载保护
2,线路管理控制:实现外呼资源(服务器,线路等)在业务间即可独立,也可共享,通过界面化完成配置;通过实时计算接通率,判断当前线路是否存在故障,及时剔除。
3,状态检测:定时检测java后台应用和FS的连接状态以及FS自身状态,及时剔除不可用的后台应用和FS服务器。
经过上面的建设后,外呼平台的整个任务提交和执行如图6所示。
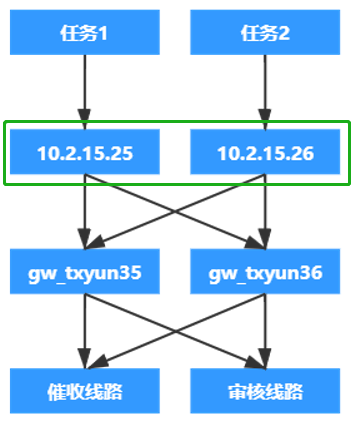
任务调度执行示意图
业务提交的外呼任务会进入到与业务相关的不同待执行队列中,这里采用redis列表数据结构作为任务队列,任务左进右出。需要说明的是,这个地方不需要包装DB数据和缓存数据的一致性,任务在出队执行后,会校验任务状态并采用乐观锁修改任务状态,操作成功后才会执行任务,否则只会做出队操作,不执行。
scheduler层(调度层)每一秒执行一次调度:scheduler层对效率要求比较高,采用线程池并行执行不同的任务队列,在任务调度过程中,需要io的地方只有访问redis,提交任务到worker采用异步rpc接口调用的方式。具体过程如下:
1,获取队列id列表,一个队列从线程池中获取一个线程去执行自己的任务;
2,根据队列id获取自己可以使用的资源列表,并判断资源是否充足,资源的负载均衡和过载保护就是在这里实现的,对于FS的选择,网关的选择,线路的选择,内置了三种算法,分别是随机,轮询和接通率优先,接通率优先算法的主要思路是在worker层任务执行完毕后,主动上报数据,然后按照分钟粒度去统计各个维度的接通率,然后在选择的时候,可以选择接通率更高的资源,该算法主要适用于线路资源的选择;过载保护主要体现在,任务在执行过程中,会把已经占用的资源放到执行中队列中,如果该项资源超过使用上限,则不会继续使用该资源;
3,任务完成调度后,任务执行需要的所有资源信息已经确认完毕,把这些信息提交到下层的worker执行,从scheduler到worker层采用rpc的方式,借用dubbo的接口调用完成了java后台应用的负载均衡。
需要额外指出的是:待执行队列中的任务一般会远远大于系统的执行能力,每个队列中的任务在1秒内是不可能全部提交完毕的,为了保证任务调度是严格按照秒级调度,每个线程执行任务提交的时间必须小于1秒,不然线程池中的线程使用完毕后会造成任务堆积现象,也就是当停止任务调度后,会发现scheduler层还要运行一段时间,才会真正停止。最简单的方案是采用线程池的拒绝策略,但是这种会造成获取线程的队列可以提交任务并且短期内不释放线程,未获取到线程的队列则一直要等待,造成任务执行不均匀;最终采用的方案每个线程最多执行900ms,超过时间后必须释放,由此来保证每个队列都能公平的获得任务提交的机会。
worker层(执行层):每一个worker在启动的时候会与所有的FS建立socket连接,并把连接缓存到本地,然后每间隔固定时间(10s),检测socket通道是否断开连接,如果当前检测socket断开,则本机会拒绝执行任务,会把scheduler提交的任务重新放回待执行队列,同时会发起一次全局投票,判断当前FS是否正常,如果大多数worker都不能与这台FS建立连接,则把这台FS从可用列表中剔除,这样在scheduler层提交任务时就不会使用这台FS。然后等待下一次心跳检测,如果大多数可以重新建立连接,则会重新把FS加入到可用列表中。整个过程如图7所示
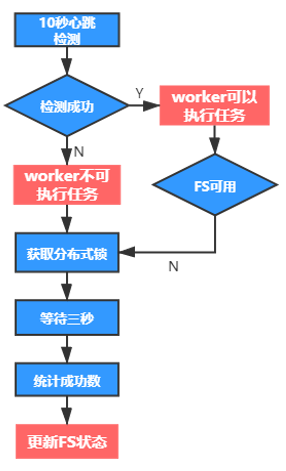
心跳检测示意图
以上主要介绍了后台技术的构建,外呼平台围绕这外呼功能,后台还引入了opensips+rtpengine架构;在使用方面,引入了web话机,去掉了话机的概念,节约了话机成本,机器人和ivr的配置都使用界面配置化,可以方便业务的快速迭代;运维管理可视化,可以及时感知整个外呼平台的运行现状。所有的工作都围绕三个关键词:大体量,高效率,易运营。有关系统方面问题请找博主,看他名字可以微他一起技术交流学习
外呼平台在建设,是一个从零到一的故事,并且建设过程中会面临各种陌生领域(通信)的知识,同时由于公司业务量大,架构升级的过程中,也没有类似的参考案例,在架构升级过程中,各种选择的主要方向在于简单,高效,学习成本低。
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
其实做自媒体的成本并不高,入门只需要一部手机即可!在手机上找视频素材、使用手机剪辑视频、最后使用手机发布视频作品获得收益!方法并不难,今天这期内容就来给粉丝们分享一种小方法,每天稳定收益100-300,抓紧点赞收藏!1、找素材(1)使用手机拍摄自己喜欢的经典段落,使用程序把文案内容提取出来(2)也可以在豆瓣、知乎、微博等网站中找一些自己需要的文案素材(3)把文案进行润色修改,可以加入一些自己的观点(4)视频素材可以使用软件中自带的素材,也可以在素材网站中下载完整版的素材2、文案配音(1)把复制好的文案直接导入小程序中(2)调整音色、音调后一键合成音频即可(3)可以选择自己朗读配音,需要花一点时
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
我有这个代码:context"Visitingtheusers#indexpage."dobefore(:each){visitusers_path}subject{page}pending('iii'){shouldhave_no_css('table#users')}pending{shouldhavecontent('Youhavereachedthispageduetoapermissionic错误')}它会导致几个待处理,例如ManagingUsersGivenapractitionerloggedin.Visitingtheusers#indexpage.#Noreason
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
考虑这个,它工作正常::>.to_proc.curry(2)[9][8]#=>true,because9>8然而,即使>是一个二元运算符,如果没有指定的元数,上面的代码将无法工作::>.to_proc.curry[9][8]#=>ArgumentError:wrongnumberofarguments(0for1)为什么两者不等价?注意:我特别想用提供的一个参数创建中间柯里化(Currying)函数,然后然后调用然后用第二个参数调用它。 最佳答案 curry必须知道传入的过程的数量,对吧?:-1来自arity的负值令人困惑,但基本上