索引
直接进入正题吧。
带★的是可能遇到的问题可以看一下,以防后续操作出问题。
内容可能来自博主自己手搓、吸取同学的经验、网络上内容的整合等等,仅供参考,更多内容可以查看大三下速通指南专栏。
有了前几次的经验这次就简单一点了。
直接在官网下载的spark-2.4.0,注意是下载这个153M的压缩包。
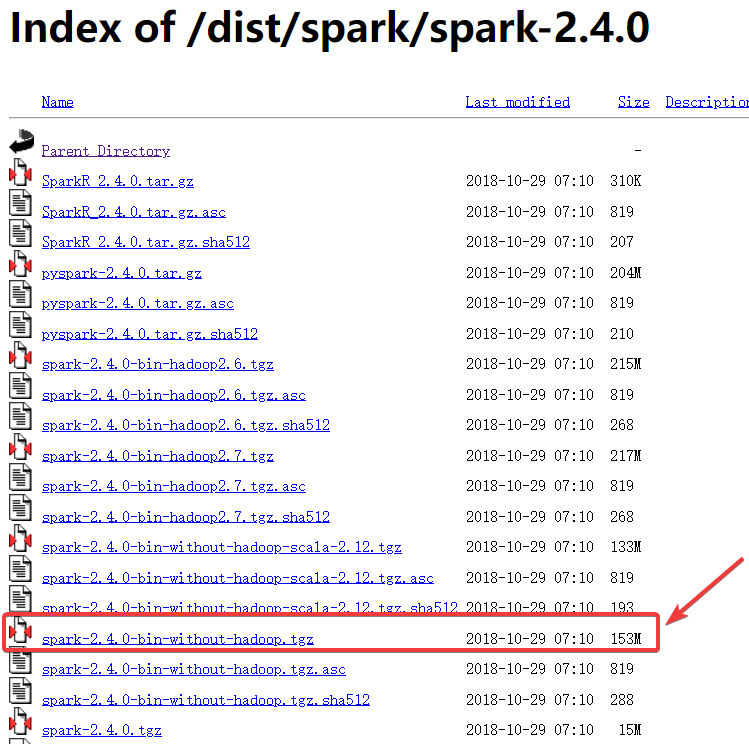
首先把压缩包放到/usr/local目录下
然后依次执行下面的指令(在哪里打开终端都行):
cd /usr/localtar -zxvf spark-2.4.0-bin-without-hadoop.tgzmv spark-2.4.0-bin-without-hadoop sparkchown -R root:root spark此时你的/usr/local目录下就有spark目录了。
首先vi /etc/profile,在文件的末尾加入以下内容:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export JAVA_LIBRARY_PATH=/user/hadoop/hadoop-3.3.1/lib/native
第三行是Hadoop路径/lib/native,根据自己的调整!
:wq保存后关闭,之后使用指令source /etc/profile刷新一下。
配置文件的路径是/usr/local/spark/conf。
cd /usr/local/spark/conf 进入配置文件目录
cp slaves.template slaves 将文件重命名为slaves
vi slaves 进入修改文件,后面添加上两个从机的主机名(根据自己的改!)
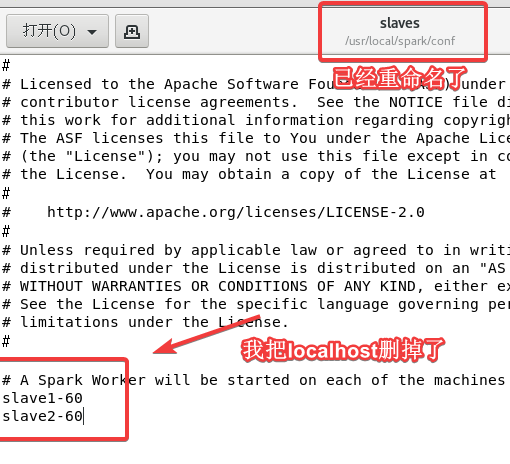
这里一定要仔细修改!大部分问题都出自这里。
cp spark-env.sh.template spark-env.sh 重命名为spark-env.sh
vi spark-env.sh 进入修改文件,在文件末尾添加以下内容:
export SPARK_DIST_CLASSPATH=$(/user/hadoop/hadoop-3.3.1/bin/hadoop classpath)
export HADOOP_CONF_DIR=/user/hadoop/hadoop-3.3.1/etc/hadoop
export SPARK_MASTER_IP= master60
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64
export HADOOP_HOME=/user/hadoop/hadoop-3.3.1
export SPARK_WORKER_MEMORY=1024m
export SPARK_WORKER_CORES=1
其中第1、2、5行是修改Hadoop的路径;第3行修改主机的主机名;第4行是JDK的路径;第6、7行不需要改。
如果忘了在哪里可以看一下自己的~/.bashrc或者/etc/profile文件之前配置过的。
在主机依次进行以下操作:
cd /usr/localtar -zcf spark.master.tar.gz sparkscp spark.master.tar.gz slave1-60:/usr/local/spark.master.tar.gz(修改为从机1的主机名)scp spark.master.tar.gz slave2-60:/usr/local/spark.master.tar.gz(修改为从机2的主机名)在两个从机依次执行以下操作(两台从机都执行依次!):
cd /usr/localtar -zxf spark.master.tar.gzchown -R root /usr/local/spark在主机使用下面两个指令即可:
/user/hadoop/hadoop-3.3.1/sbin/start-all.sh(启动Hadoop)/usr/local/spark/sbin/start-all.sh(启动Spark)注意路径!注意路径!注意路径!Hadoop路径可能与我的不同。
这里就会出现问题,Spark和Hadoop都有start-all.sh的指令并且都被写到了环境变量中,你直接使用start-all.sh大概率是会用Spark的指令。为了避免这种不必要的误会,之后再重启请使用完整的路径来start-all.sh。
并且这次实验与上一次没关系,不需要打开Zookeeper以及HBase。
在主机上jps可以看到至少以下两个进程:

在从机上jps可以看到至少以下两个进程:

浏览器打开主机的主机名或IP:8080。
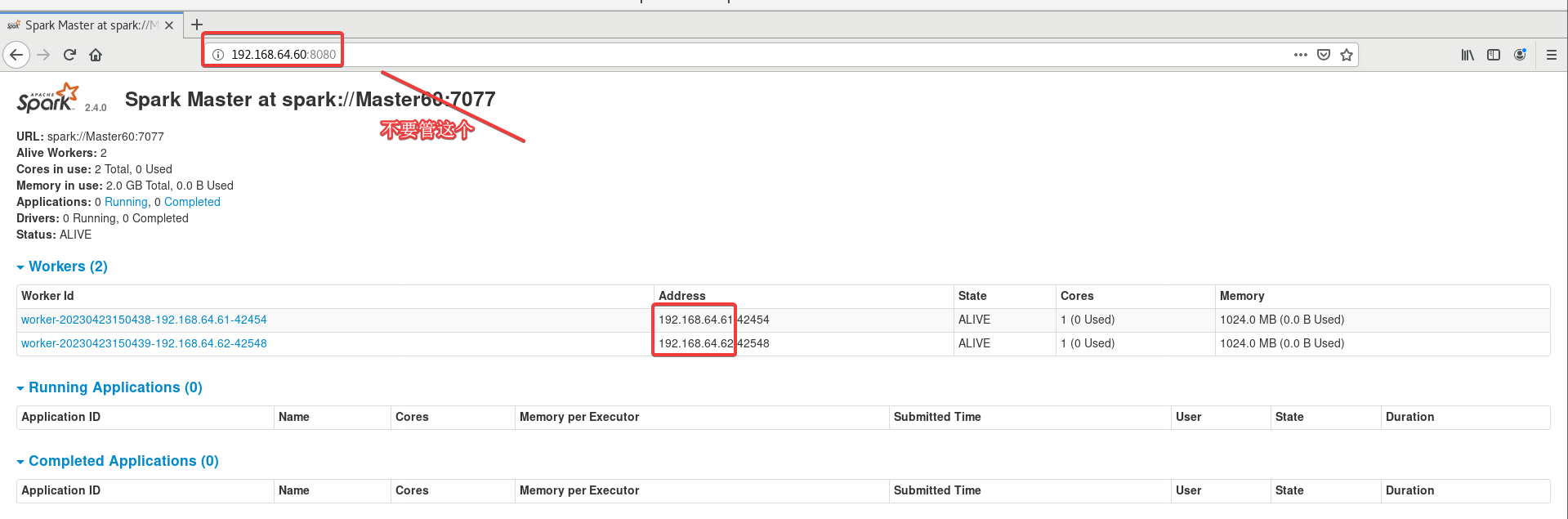
打不开就把三台虚拟机重启之后按照1.6操作一遍。
再查看一下spark-shell,退出的指令是:quit有:的!!!,如果不正常退出,之后再启动可能也打不开4040端口。
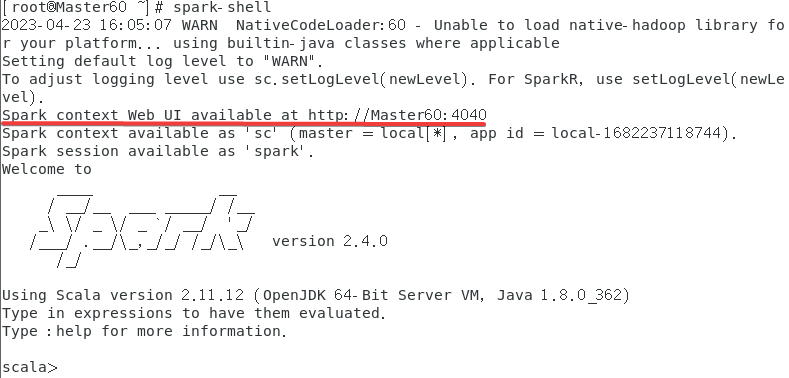
再看一下4040端口,注意需要运行spark-shell才能进入,上图也可以看的出来再使用了spark-shell之后才开启了这个端口。
连接失败是因为没开spark-shell。
一直加载打不开,可能是因为强制关闭了spark-shell,虚拟机重开再打开服务可以解决。
19级是单词计数,感兴趣可以看一下涛哥的博客。
直接下载,点了之后就下载了。
拖到usr/local。
终端通过指令解压一下:tar -zxvf scala-SDK-4.7.0-vfinal-2.12-linux.gtk.x86_64.tar.gz
解压出来的是一个eclipse目录,
之后的编程是通过这个目录中的eclipse!不要用桌面上的!
如果打不开可以参考2.10的解决方法
注意确保Spark版本是2.4.0(前面下载的就是)
直接依次执行以下操作:
cd /usr/localwget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgztar -zxvf scala-2.11.8.tgzmv scala-2.11.8 scala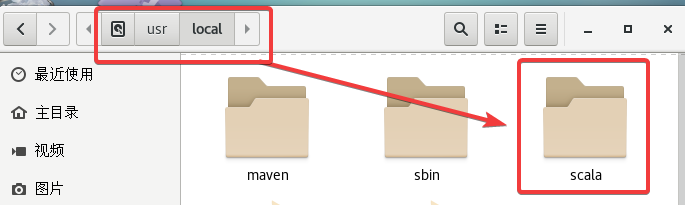
vi /etc/profile 进入文件在末尾添加以下内容:
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
然后source /etc/profile刷新一下。
在终端输入scala看一下是否配置成功,:quit退出。
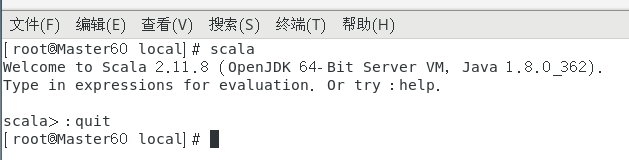
注意!Scala主机从机都需要下载,也就是2.3、2.4三台虚拟机都要操作。
打开Scala IDE,
创建一个Scala项目,
随便起了个名,无所谓的,
右键项目 ->Configure ->Convert to Maven Project,
没改直接下一步了,后面还可以在pom.xml里改,
如果找不到类什么的错误可以重新创建一个项目,要先转换成Maven项目然后从2.6.2继续即可。2.6.1配置之后不会自动变化了。
两个地方要改。
点击Window -> Preferences -> Maven -> Installations。
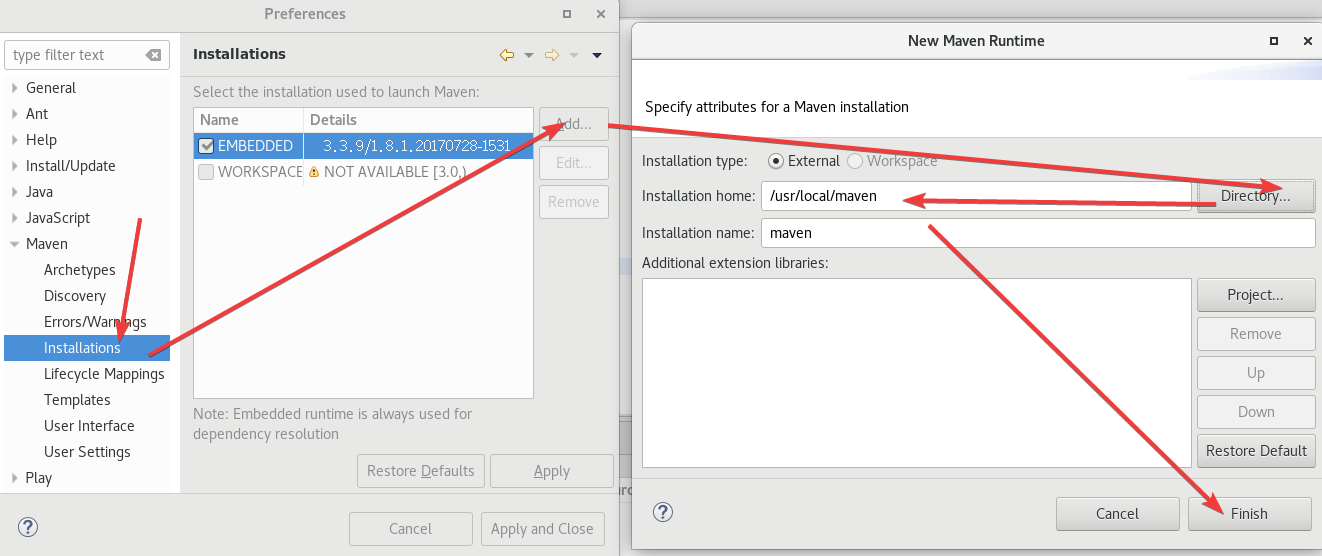
添加了以后记得选上,
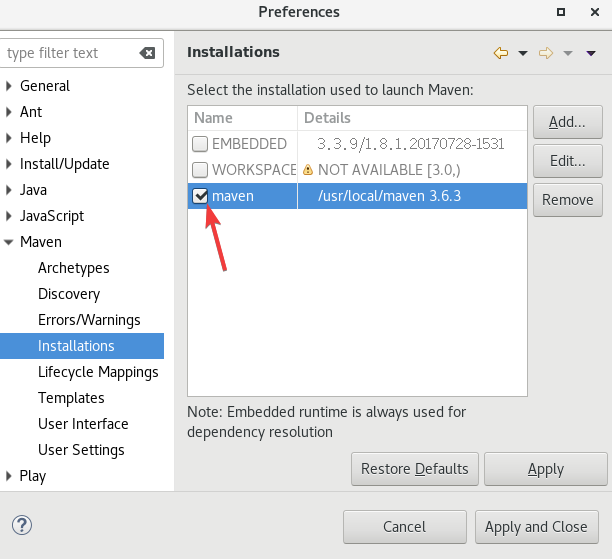
点击Window -> Preferences -> Maven -> User Settings。
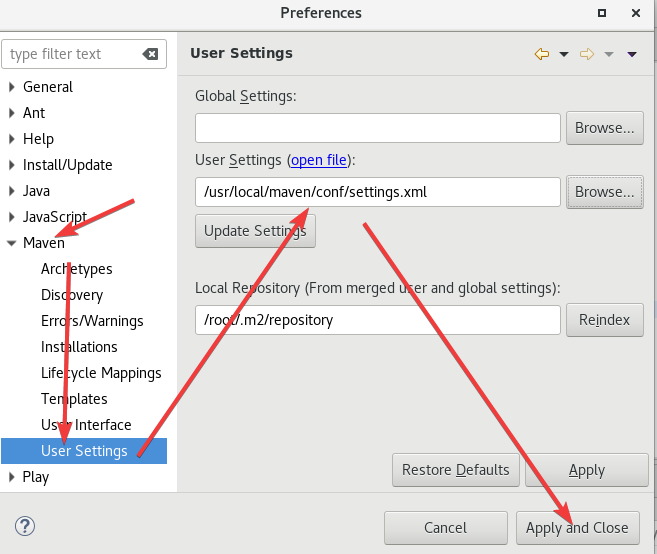
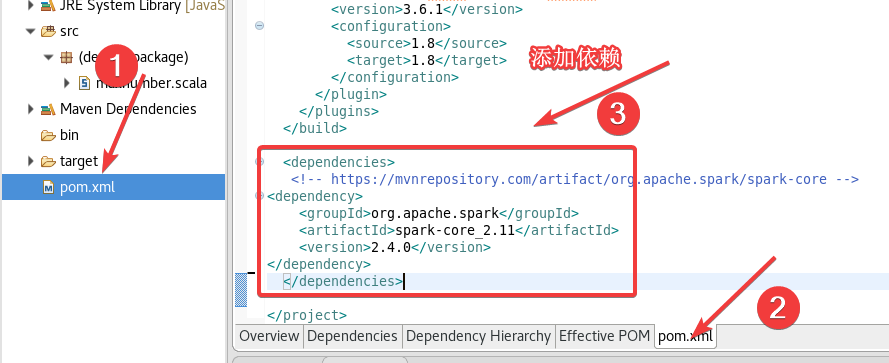
打开pom.xml,添加以下内容:
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>
右键项目,打开Properties,
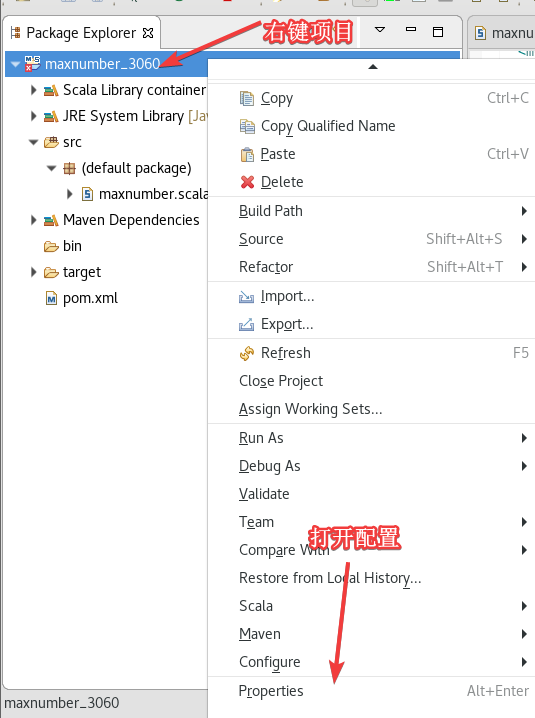
按照下图选择Scala Compiler然后确认,
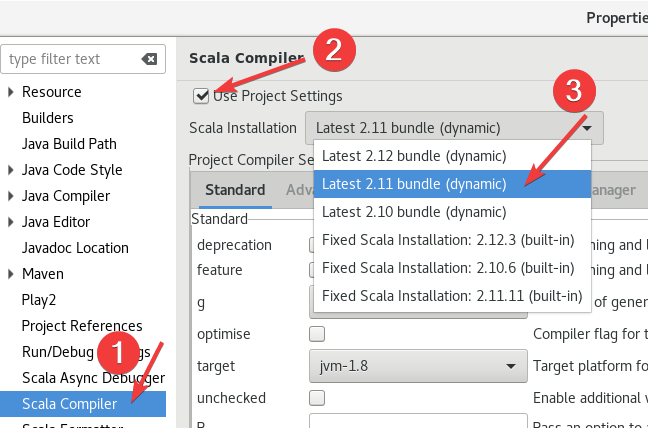
右键项目 ->Build Path ->Configure Build Path。

上次做过这个,直接添加就行了,
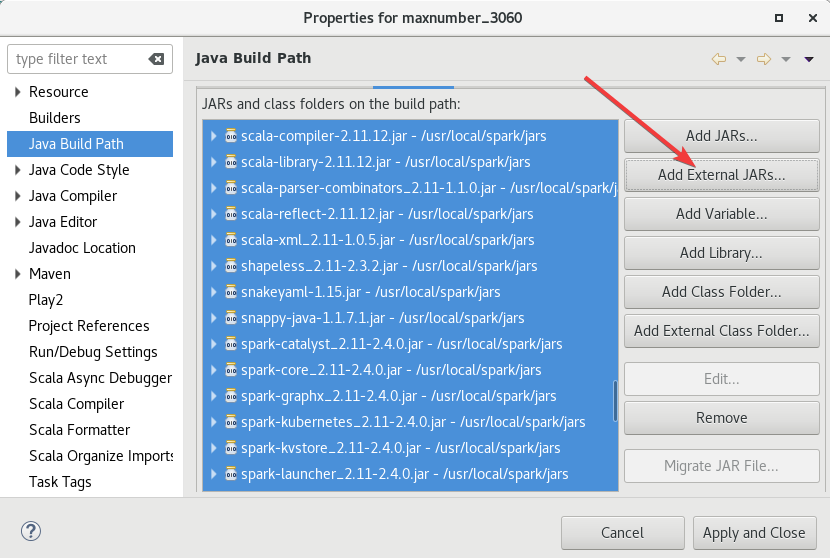
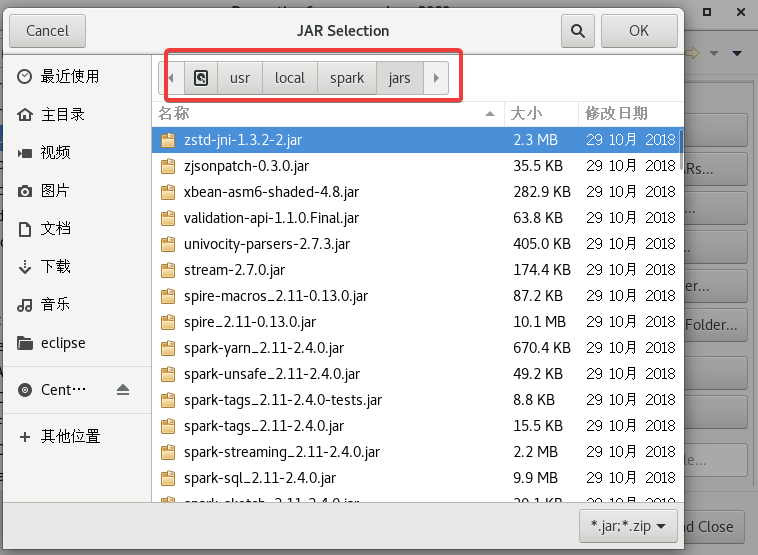
添加的路径是/usr/local/spark/jars,直接ctrl+A全选添加就可以。
右键src -> new ->Scala Object,名字随便起。两个代码一个Random一个Max。
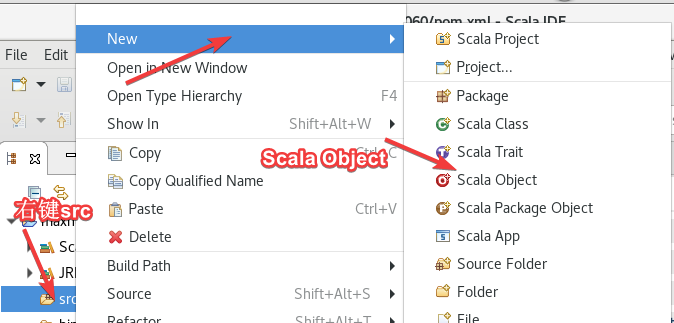
把主机名全改了!
Random代码如下,这个是生成50个1到10000之间随机数,并保存到HDFS下面的/tmp/maxnumber/word_060.txt(根据自己学号改)
import org.apache.spark.{SparkConf, SparkContext}
object Random{
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Random").setMaster("local")
val sc = new SparkContext(conf)
val randoms = sc.parallelize(Seq.fill(50)(scala.util.Random.nextInt(10000)+1))
// 输出到控制台
randoms.collect().foreach(println)
// 将随机数和最大值保存到 HDFS 目录
val outputPath = "hdfs://192.168.64.60:9000/tmp/maxnumber"
randoms.saveAsTextFile(outputPath + "/word_060.txt")
sc.stop()
}
}
Max代码如下,这个是读取word_060.txt文件然后找最大值输出到/tmp/maxnumber/max(无所谓自己改)
import org.apache.spark.{SparkConf, SparkContext}
object Max{
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Max").setMaster("local")
val sc = new SparkContext(conf)
val filePath = "hdfs://192.168.64.60:9000/tmp/maxnumber/word_060.txt"
val max = sc.textFile(filePath)
.map(_.toInt)
.cache()
.max()
println(s"The maximum number is: $max")
val outputPath = "hdfs://192.168.64.60:9000/tmp/maxnumber/max"
sc.parallelize(Seq(max)).saveAsTextFile(outputPath)
sc.stop()
}
}
……卡的要命,我又多分配了点运存之后才好一点。
Run As ->Scala Application。
先运行Random生成随机数输出到控制台,并且保存。
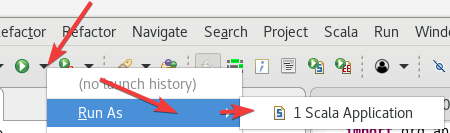
运行成功之后,再运行第二个Max程序。
打开9870端口的网页,打开HDFS的目录

进去以后打开tmp文件,
进入到tmp/maxnumber看一下,
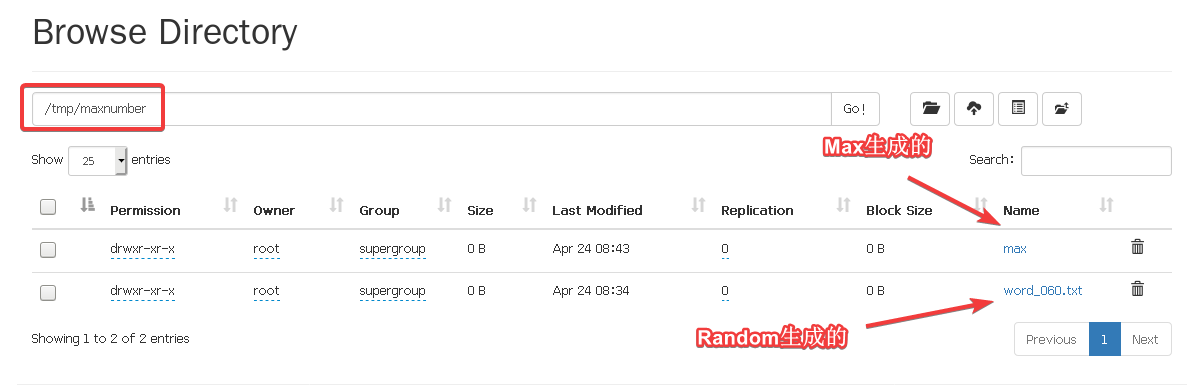
具体怎么看用max演示一下,
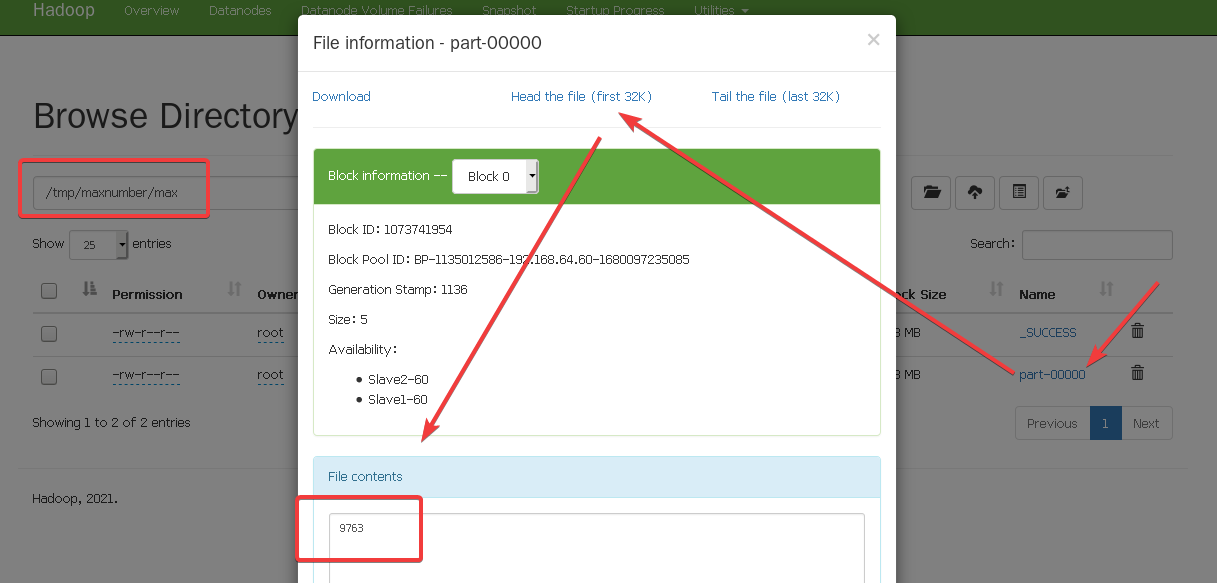
OK!到此结束。
如果运行报错内存什么什么玩意,
在Run Configurations的Arguments的VM arguments里添加一句:
-Xmx512m。
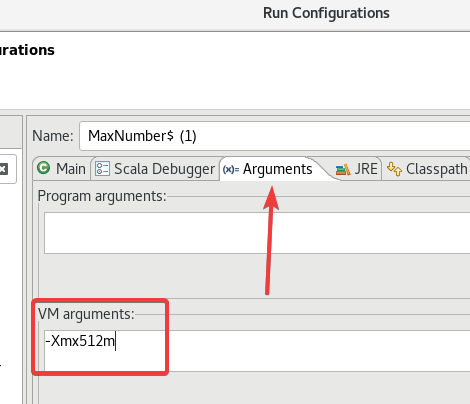
或者是给虚拟机多分配点内存……大概。
其他问题一般重启虚拟机然后重开Hadoop以及Spark就行了。
如果出现以下错误,
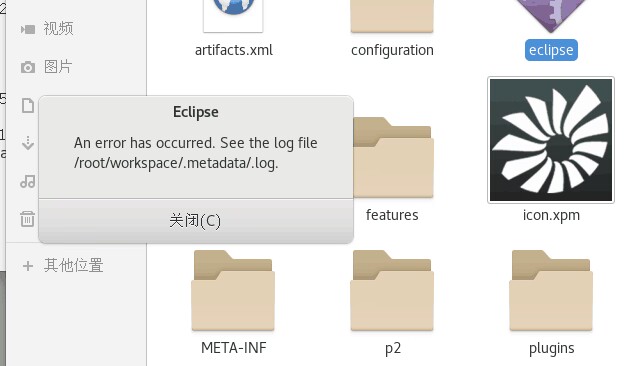
可以尝试更换一下工作目录,修改为其他的如/root/work之类的随便改。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
如何计算两个字符串之间的字符交集?例如(假设我们有一个名为String.intersection的方法):"abc".intersection("ab")=2"hello".intersection("hallo")=4好的,男孩女孩们,感谢你们的大量反馈。更多示例:"aaa".intersection("a")=1"foo".intersection("bar")=0"abc".intersection("bc")=2"abc".intersection("ac")=2"abba".intersection("aa")=2一些补充说明:维基百科定义intersection如下:Int
给定一个包含各种语言字符的UTF-8文件,我如何计算它包含的唯一字符的数量,同时排除选定数量的符号(例如:“!”、“@”、"#",".")从这个算起? 最佳答案 这是一个bash解决方案。:)bash$perl-CSD-ne'BEGIN{$s{$_}++forsplit//,q(!@#.)}$s{$_}++||$c++forsplit//;END{print"$c\n"}'*.utf8 关于python-如何计算文件中唯一字符的数量?,我们在StackOverflow上找到一个类似的问题