将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例1:
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例2:
输入:l1 = [], l2 = []
输出:[]
示例3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
[0, 50]-100 <= Node.val <= 100l1 和 l2 均按 非递减顺序 排列我们可以如下递归地定义两个链表里的 merge 操作(忽略边界情况,比如空链表等):
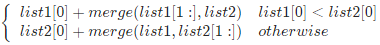
也就是说,两个链表头部值较小的一个节点与剩下元素的 merge 操作结果合并。
我们直接将以上递归过程建模,同时需要考虑边界情况。如果 l1 或者 l2 一开始就是空链表 ,那么没有任何操作需要合并,所以我们只需要返回非空链表。否则,我们要判断 l1 和 l2 哪一个链表的头节点的值更小,然后递归地决定下一个添加到结果里的节点。如果两个链表有一个为空,递归结束。

#include <iostream>
#include <vector>
using namespace std;
// 定义链表节点
struct ListNode {
int val; // 节点值
ListNode *next; // 节点存储的next节点地址
ListNode() : val(0), next(nullptr) {} // 无参构造函数:节点值为0,next节点地址为空
ListNode(int x) : val(x), next(nullptr) {} // 有参构造函数:节点值为x,next节点地址为空
ListNode(int x, ListNode *next) : val(x), next(next) {} // 有参构造函数:节点值为x,next节点地址为next
};
ListNode* createList(const vector<int>& nums) { // 使用&:因为无需拷贝nums;使用const:因为无需改变nums中元素的值
ListNode dummy(0); // 定义哑结点(方式一):在栈上开辟空间,由系统自动分配内存并销毁
//ListNode* dummy = new ListNode(); // 定义哑结点(方式二):在堆上开辟空间,手动分配内存并需要手动销毁
// 为什么在这里要采用方式一:因为后面在销毁链表时,并没有处理哑结点。如果采用方式二,需要在后面处理哑结点。
ListNode* node = &dummy;
for (const int& n: nums) {
node->next = new ListNode(n);
node = node->next;
}
return dummy.next;
}
void printList(ListNode* head) {
while (head) {
cout << head->val << " ";
head = head->next;
}
cout << endl;
}
void destroyList(ListNode* head) {
while (head) {
ListNode* delNode = head;
head = head->next;
delete delNode;
}
}
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (l1 == nullptr) {
return l2;
} else if (l2 == nullptr) {
return l1;
} else if (l1->val < l2->val) {
l1->next = mergeTwoLists(l1->next, l2);
return l1;
} else {
l2->next = mergeTwoLists(l1, l2->next);
return l2;
}
}
};
int main() {
vector<int> nums1{1, 2, 4};
ListNode* l1 = createList(nums1);
printList(l1);
vector<int> nums2{1, 3, 4};
ListNode* l2 = createList(nums2);
printList(l2);
Solution s;
printList(s.mergeTwoLists(l1, l2));
destroyList(l1);
destroyList(l2);
return 0;
}
我们可以用迭代的方法来实现上述算法。当 l1 和 l2 都不是空链表时,判断 l1 和 l2 哪一个链表的头节点的值更小,将较小值的节点添加到结果里,当一个节点被添加到结果里之后,将对应链表中的节点向后移一位。
首先,我们设定一个哨兵节点 prehead ,这可以在最后让我们比较容易地返回合并后的链表。我们维护一个 prev 指针,我们需要做的是调整它的 next 指针。然后,我们重复以下过程,直到 l1 或者 l2 指向了 null :如果 l1 当前节点的值小于等于 l2 ,我们就把 l1 当前的节点接在 prev 节点的后面同时将 l1 指针往后移一位。否则,我们对 l2 做同样的操作。不管我们将哪一个元素接在了后面,我们都需要把 prev 向后移一位。
在循环终止的时候, l1 和 l2 至多有一个是非空的。由于输入的两个链表都是有序的,所以不管哪个链表是非空的,它包含的所有元素都比前面已经合并链表中的所有元素都要大。这意味着我们只需要简单地将非空链表接在合并链表的后面,并返回合并链表即可。

#include <iostream>
#include <vector>
using namespace std;
// 定义链表节点
struct ListNode {
int val; // 节点值
ListNode *next; // 节点存储的next节点地址
ListNode() : val(0), next(nullptr) {} // 无参构造函数:节点值为0,next节点地址为空
ListNode(int x) : val(x), next(nullptr) {} // 有参构造函数:节点值为x,next节点地址为空
ListNode(int x, ListNode *next) : val(x), next(next) {} // 有参构造函数:节点值为x,next节点地址为next
};
ListNode* createList(const vector<int>& nums) { // 使用&:因为无需拷贝nums;使用const:因为无需改变nums中元素的值
ListNode dummy(0); // 定义哑结点(方式一):在栈上开辟空间,由系统自动分配内存并销毁
//ListNode* dummy = new ListNode(); // 定义哑结点(方式二):在堆上开辟空间,手动分配内存并需要手动销毁
// 为什么在这里要采用方式一:因为后面在销毁链表时,并没有处理哑结点。如果采用方式二,需要在后面处理哑结点。
ListNode* node = &dummy;
for (const int& n: nums) {
node->next = new ListNode(n);
node = node->next;
}
return dummy.next;
}
void printList(ListNode* head) {
while (head) {
cout << head->val << " ";
head = head->next;
}
cout << endl;
}
void destroyList(ListNode* head) {
while (head) {
ListNode* delNode = head;
head = head->next;
delete delNode;
}
}
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* preHead = new ListNode(-1);
ListNode* prev = preHead;
while (l1 != nullptr && l2 != nullptr) {
if (l1->val < l2->val) {
prev->next = l1;
l1 = l1->next;
} else {
prev->next = l2;
l2 = l2->next;
}
prev = prev->next;
}
// 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可
prev->next = l1 == nullptr ? l2 : l1;
return preHead->next;
}
};
int main() {
vector<int> nums1{1, 2, 4};
ListNode* l1 = createList(nums1);
printList(l1);
vector<int> nums2{1, 3, 4};
ListNode* l2 = createList(nums2);
printList(l2);
Solution s;
printList(s.mergeTwoLists(l1, l2));
destroyList(l1);
destroyList(l2);
return 0;
}
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
我从用户Hirolau那里找到了这段代码:defsum_to_n?(a,n)a.combination(2).find{|x,y|x+y==n}enda=[1,2,3,4,5]sum_to_n?(a,9)#=>[4,5]sum_to_n?(a,11)#=>nil我如何知道何时可以将两个参数发送到预定义方法(如find)?我不清楚,因为有时它不起作用。这是重新定义的东西吗? 最佳答案 如果您查看Enumerable#find的文档,您会发现它只接受一个block参数。您可以将它发送两次的原因是因为Ruby可以方便地让您根据它的“并行赋
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
原始问题Letd(n)bedefinedasthesumofproperdivisorsofn(numberslessthannwhichdivideevenlyinton).Ifd(a)=bandd(b)=a,whereab,thenaandbareanamicablepairandeachofaandbarecalledamicablenumbers.Forexample,theproperdivisorsof220are1,2,4,5,10,11,20,22,44,55and110;therefored(220)=284.Theproperdivisorsof284are1,2,
我已经有很多两个值数组,例如下面的例子ary=[[1,2],[2,3],[1,3],[4,5],[5,6],[4,7],[7,8],[4,8]]我想把它们分组到[1,2,3],[4,5],[5,6],[4,7,8]因为意思是1和2有关系,2和3有关系,1和3有关系,所以1,2,3都有关系我如何通过ruby库或任何算法来做到这一点? 最佳答案 这是基本Bron–Kerboschalgorithm的Ruby实现:classGraphdefinitialize(edges)@edges=edgesenddeffind_maximum_
我有两个文本文件,master.txt和926.txt。如果926.txt中有一行不在master.txt中,我想写入一个新文件notinbook.txt。我写了我能想到的最好的东西,但考虑到我是一个糟糕的/新手程序员,它失败了。这是我的东西g=File.new("notinbook.txt","w")File.open("926.txt","r")do|f|while(line=f.gets)x=line.chompifFile.open("master.txt","w")do|h|endwhile(line=h.gets)ifline.chomp!=xputslineendende