文章目录
论文地址:https://arxiv.org/pdf/2108.10257.pdf
预训练模型下载:https://github.com/JingyunLiang/SwinIR/releases
训练代码下载:https://github.com/cszn/KAIR
测试代码:https://github.com/JingyunLiang/SwinIR
论文翻译:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/124434886
测试:https://wanghao.blog.csdn.net/article/details/124517210
在写这边文章之前,我已经翻译了论文,讲解了如何使用SWinIR进行测试?
接下来,我们讲讲如何SwinIR完成训练,有于作者训练了很多任务,我只复现其中的一种任务。
地址:https://github.com/cszn/KAIR
这是个超分的库,里面包含多个超分的模型,比如SCUNet、VRT、SwinIR、BSRGGAN、USRNet等模型。


[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B5Md9i7H-1651410061139)(https://gitee.com/wanghao1090220084/cloud-image/raw/master/img/face_09_comparison.png)]
下载后解压,训练SwinIR的REANDME.md,路径:./docs/README_SwinIR.md
训练和测试集可以下载如下。 请将它们分别放在 trainsets 和 testsets 中。
| 任务 | 训练集 | 测试集 |
|---|---|---|
| classical/lightweight image SR | DIV2K (800 training images) or DIV2K +Flickr2K (2650 images) | set5 + Set14 + BSD100 + Urban100 + Manga109 download all |
| real-world image SR | SwinIR-M (middle size): DIV2K (800 training images) +Flickr2K (2650 images) + OST (10324 images,sky,water,grass,mountain,building,plant,animal) SwinIR-L (large size): DIV2K + Flickr2K + OST + WED(4744 images) + FFHQ (first 2000 images, face) + Manga109 (manga) + SCUT-CTW1500 (first 100 training images, texts) | RealSRSet+5images |
| color/grayscale image denoising | DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) | grayscale: Set12 + BSD68 + Urban100 color: CBSD68 + Kodak24 + McMaster + Urban100 download all |
| JPEG compression artifact reduction | DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) | grayscale: Classic5 +LIVE1 download all |
我下载了DIV2K数据集和 Flickr2K数据集,DIV2K大小有7G+,Flickr2K约20G。如果网速不好建议只下载DIV2K。
注:在选用classical任务,做训练时,只能使用DIV2K或者Flickr2K,不能把两种数据集放在一起训练,否则就出现维度对不上的情况,如下图:
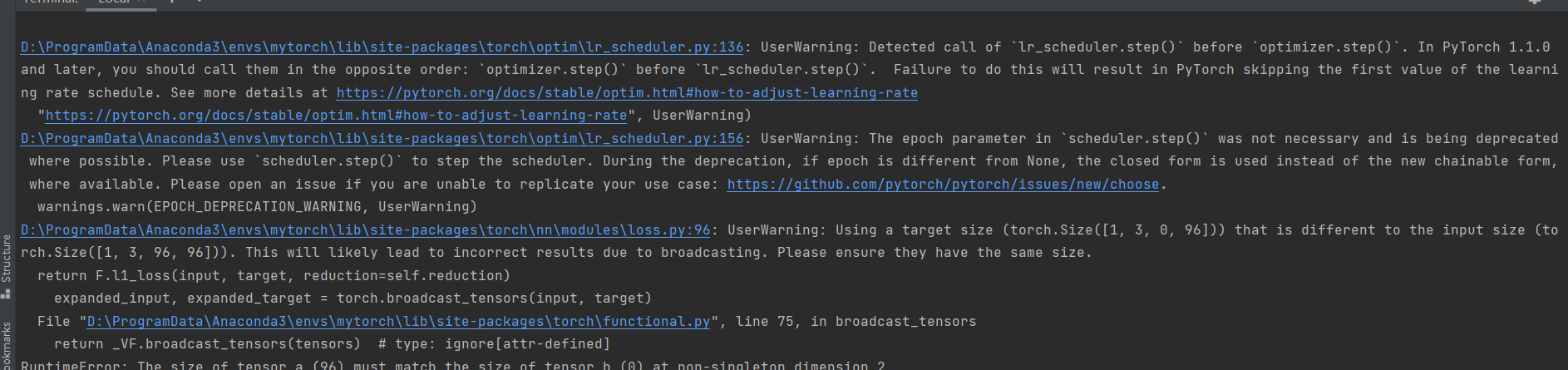
暂时没有找到原因。
构建测试集,测试集的路径如下图:
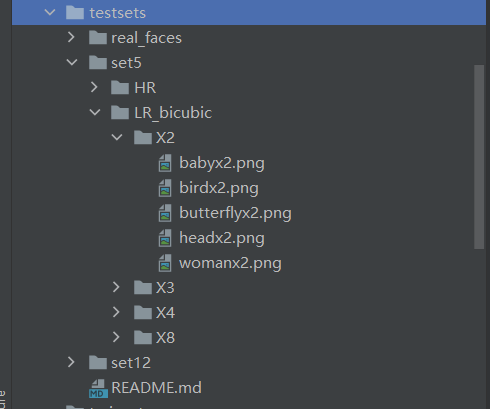
由于表格中的测试集放在google,我不能下载,但是SwinIR的测试代码中有测试集,代码链接:https://github.com/JingyunLiang/SwinIR,下载下来直接复制到testsets文件夹下面。
构建训练集,将下载下来的DIV2K解压。将DIV2K_train_HR复制到trainsets文件夹下面,将其改为trainH。

将DIV2K_train_LR_bicubic文件夹的X2文件夹复制到trainsets文件夹下面,然后将其改名为trainL。
到这里,数据集部分就完成了,接下来开始训练。
首先,打开options/swinir/train_swinir_sr_classical.json文件,查看里面的内容。
"task": "swinir_sr_classical_patch48_x2"
训练任务的名字。
"gpu_ids": [0,1]
选择GPU的ID,如果只有一快GPU,改为 [0]。如果有更多的GPU,直接往后面添加即可。
"scale": 2 //2,3,48
放大的倍数,可以设置为2、3、4、8.
"datasets": {
"train": {
"name": "train_dataset" // just name
, "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
, "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images)
, "dataroot_L": "trainsets/trainL" // path of L training dataset
, "H_size": 96 // 96/144|192/384 | 128/192/256/512. LR patch size is set to 48 or 64 when compared with RCAN or RRDB.
, "dataloader_shuffle": true
, "dataloader_num_workers": 4
, "dataloader_batch_size": 1 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
}
, "test": {
"name": "test_dataset" // just name
, "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
, "dataroot_H": "testsets/Set5/HR" // path of H testing dataset
, "dataroot_L": "testsets/Set5/LR_bicubic/X2" // path of L testing dataset
}
}
上面的参数是对数据集的设置。
“H_size”: 96 ,HR图像的大小,和下面的img_size有对应关系,大小设置为img_size×scale。
“dataloader_num_workers”: 4,CPU的核数设置。
“dataloader_batch_size”: 32 ,设置训练的batch_size。
dataset_type:sr,指的是数据集类型SwinIR。
"netG": {
"net_type": "swinir"
, "upscale": 2 // 2 | 3 | 4 | 8
, "in_chans": 3
, "img_size": 48 // For fair comparison, LR patch size is set to 48 or 64 when compared with RCAN or RRDB.
, "window_size": 8
, "img_range": 1.0
, "depths": [6, 6, 6, 6, 6, 6]
, "embed_dim": 180
, "num_heads": [6, 6, 6, 6, 6, 6]
, "mlp_ratio": 2
, "upsampler": "pixelshuffle" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
, "resi_connection": "1conv" // "1conv" | "3conv"
, "init_type": "default"
}
upscale:2,放大的倍数,和上面的scale参数对应。
img_size:48,这里可以设置两个数值,48和64。和测试的training_patch_size参数对应。
官方提供的指令是基于DDP方式,比较复杂一下,好处是速度快。如下:
# 001 Classical Image SR (middle size)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_classical.json --dist True
# 002 Lightweight Image SR (small size)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_lightweight.json --dist True
# 003 Real-World Image SR (middle size)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_realworld_psnr.json --dist True
# before training gan, put the PSNR-oriented model into superresolution/swinir_sr_realworld_x4_gan/models/
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_realworld_gan.json --dist True
# 004 Grayscale Image Deoising (middle size)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_denoising_gray.json --dist True
# 005 Color Image Deoising (middle size)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_denoising_color.json --dist True
# 006 JPEG Compression Artifact Reduction (middle size)
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_car_jpeg.json --dist True
我没有使用上面的方式,而是选择用DP的方式,虽然慢一点,但是简单,更稳定。
在Terminal里面输入:
python main_train_psnr.py --opt options/swinir/train_swinir_sr_classical.json
即可开始训练。
运行结果如下:
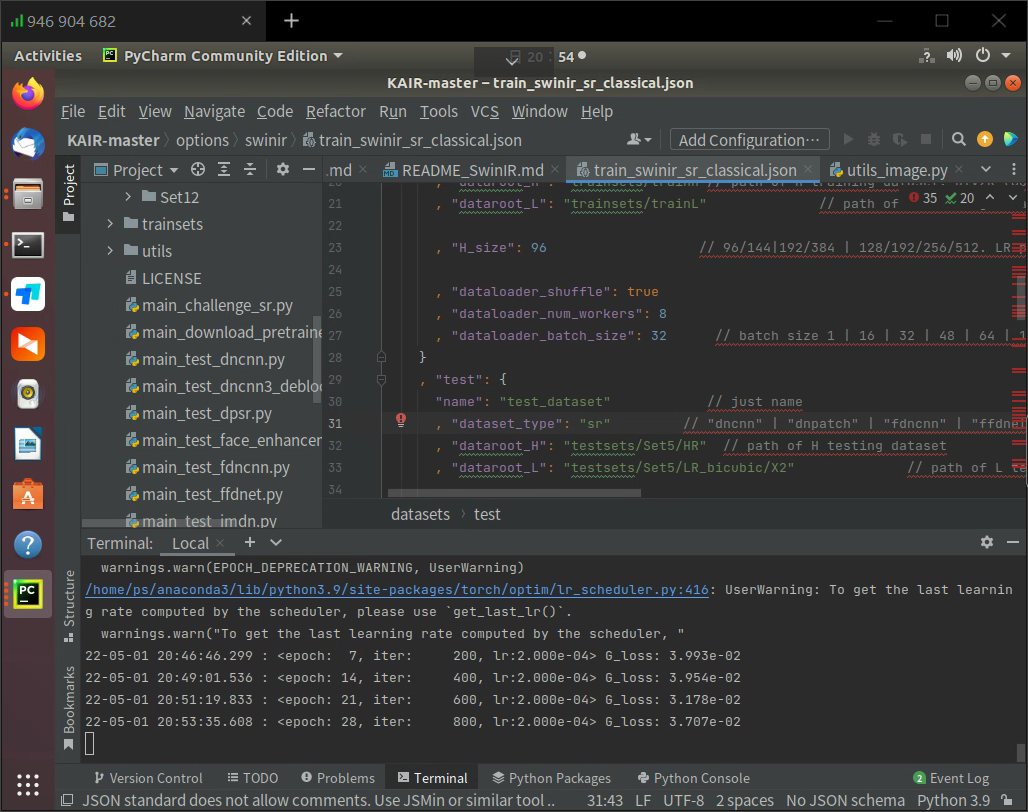
等待训练完成后,我们使用测试代码测试。将模型复制到./model_zoo/swinir文件夹下面
输入命令:
python main_test_swinir.py --task classical_sr --scale 2 --training_patch_size 48 --model_path model_zoo/swinir/45000_G.pth --folder_lq testsets/Set5/LR_bicubic/X2
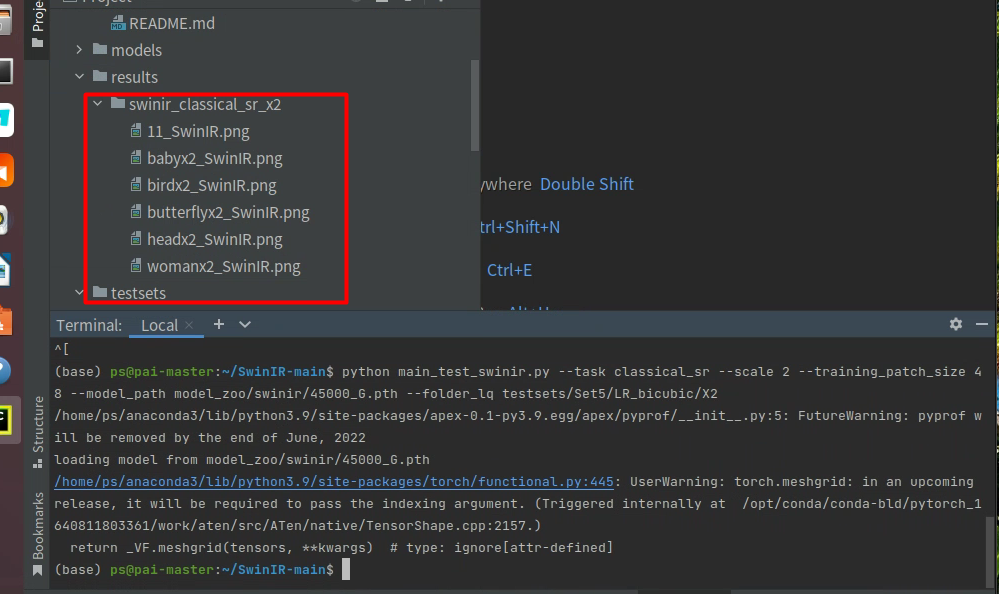
然后在result下面可以看到测试结果。
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/85258387
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
在许多ruby类之间共享记录器实例的最佳(正确)方法是什么?现在我只是将记录器创建为全局$logger=Logger.new变量,但我觉得有更好的方法可以在不使用全局变量的情况下执行此操作。如果我有以下内容:moduleFooclassAclassBclassC...classZend在所有类之间共享记录器实例的最佳方式是什么?我是以某种方式在Foo模块中声明/创建记录器还是只是使用全局$logger没问题? 最佳答案 在模块中添加常量:moduleFooLogger=Logger.newclassAclassBclassC..
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果