摘要:DWS的负载管理分为两层,第一层为cn的全局并发控制,第二层为资源池级别的并发控制。
本文分享自华为云社区《GaussDB(DWS) 并发管控&内存管控》,作者: fighttingman。
这里将并发管控和内存管控写在一起,是因为内存管控实际是通过限制语句的并发达到内存管控的目的的。内存管控是基于语句的估算内存的前提下进行管控的,通俗的说就是语句有个估算内存,当资源池的剩余内存小于语句的估算内存时,这个语句就会排队等待,等资源池内的语句执行完,资源池有足够的剩余内存的时候,才会让这个语句执行。所以内存管控的实际效果和语句的估算内存有很大关系,估算的大了就会造成大量语句排队,实际没有使用那么多内存,造成内存资源浪费,相反估算的小了,就会有很多语句下发,实际内存使用就会变多,就有语句报内存不足的错误风险。
数据库系统的并发控制,在整个系统中起着很重要的作用,比如很多用户的业务压力过大时,有时会导致连接数量被占满,有时会导致某种计算资源被占满,有时会导致存储空间被占满,这些情况都会导致整个集群进入异常甚至不可用的状态:正在执行的作业互相争抢CPU,会导致大家都不能好好执行;大量作业执行时,占用大量内存,很容易触发到内存瓶颈,造成作业内存不可用问题,导致业务报错等等。在不进行并发控制的情况下,这些情况都很可能会出现,影响到正常业务。
DWS的负载管理分为两层,第一层为cn的全局并发控制,第二层为资源池级别的并发控制。在通过第一层控制的时候,会继续向前走到第二层资源池控制,根据资源池当前的负载资源情况决定作业继续执行或者排队。
基于DWS并发控制逻辑看出,实际作业执行中,可能会在两种队列中排队:
一种是全局队列(global queue)这种队列不区分简单和复杂作业,也不区分是DDL或者是普通语句,这种是每个cn生效。
一种是资源池队列(resource pool queue),用户下发的一般语句会根据资源消耗估算以及复杂程度在这里进行判断是否排队。
在两层队列的过滤下,DWS会筛选出当前能执行的语句,使其正常运行,运行时也会受到其所属资源池资源的限制(只能使用资源池配置的CPU、内存、IO配额)。
这里介绍几个常用视图以及SQL语句,可以迅速判断目前的业务出现问题的原因,受限根据以下视图可以看到目前的作业是不是在排队,之后要迅速分析为什么在排队,是因为负载管理各个参数配置问题,还是因为正在执行的语句占据了过多的资源导致的排队。
pgxc_stat_activity (活跃视图)
查询当前执行时间最长的语句的排队状态,query_id(数据库中作业的唯一标识),以及详细的语句信息。
select coorname,usename, current_timestamp-query_start as duration, enqueue,query_id,query from pgxc_stat_activity where state='active' and usename <> 'Ruby' order by duration desc;
根据该语句可以迅速判断出哪些语句执行时间很长,是什么样的语句执行很慢以及该语句的query_id,便于迅速进入下一步排查。
该视图中enqueue字段中如果显示waiting in global queue就代表在全局排队。全局排队是受GUC参数max_active_statements参数控制的,是单cn生效的,也就是每个cn都可以支持这么大的并发量。比如集群中有3个cn实例,GUC参数max_active_statements参数设置为60,也就是说每个cn都支持60个语句并发执行,集群全局支持3 * 60 = 180并发执行作业。当下发作业大于这个cn设置的max_active_statements的时候就会进行全局排队,在pgxc_stat_activity视图中enqueue字段就会显示waiting in global queue。
当GUC参数enable_dynamic_workload设置为off的时候就代表是静态负载管理模式。静态负载管理的情况下,pgxc_stat_activity视图中enqueue字段只会有waiting in respool queue。并发控制参数为资源池的max_dop(简单作业)和active_statements(复杂作业)。
1)简单作业和复杂作业的定义
在静态负载管理中,简单作业是估算代价cost值小于GUC参数parctl_min_cost值的作业。反之则判定为复杂作业。该GUC参数默认为10W,
当parctl_min_cost为-1时,或者作业估算代价小于10时,作业都判定为简单作业。
2)简单作业并发限制
ALTER RESOURCE POOL resource_pool_a1 WITH (max_dop=10);通过设置资源池的max_dop参数设置简单作业并发,关联资源池resource_pool_a1的用户都受到这个参数的控制。当所有关联这个资源池的用户的所有作业数量之和大于这个参数的时候,就会进行资源池排队,活跃视图enqueue字段就会显示waiting in respool queue。
3)复杂作业并发限制
ALTER RESOURCE POOL resource_pool_a2 WITH (active_statements=10);通过设置资源池的active_statements参数控制复杂作业的并发数,关联资源池resource_pool_a2的用户都受到这个参数的控制。
资源池使用并发点数的计数方式来计算可执行的复杂作业并发数量,并发点数计算公式为
作业使用内存点数:active_points = (query_mem/respool_mem) * active_statements * 100
作业使用并发点数:active_points = 100
资源池总点数:total_points = active_statements * 100
单位点数: 100
4)相关说明
当GUC参数enable_dynamic_workload设置为on的时候就代表是动态负载管理模式。动态负载管理的情况下,pgxc_stat_activity视图中enqueue字段会有waiting in respool queue和waiting in global queue。
1)简单作业和复杂作业的定义
动态负载管理下优化器估算内存大于32M认为是复杂作业,反之认为是简单作业。
运行中的作业复杂简单情况可以通过PG_SESSION_WLMSTAT中的attribute字段查看。
2)动态负载管理相关说明
3)短查询加速(默认开启,建议开启)
混合负载场景下,复杂查询可能会长时间占用大量资源,虽然简单查询执行时间短、消耗资源少,但是因为资源耗尽,简单查询不得不在队列中等待复杂查询执行完成。为提升执行效率、提高系统吞吐量,GaussDB(DWS)的“短查询加速”功能,实现对简单查询的单独管理。
虽然单个简单作业资源消耗少,但是大量简单作业并发运行还是会占用大量资源,因此短查询加速开启情况下,需要对简单查询进行并发管理;资源管理可能会影响查询性能,影响系统吞吐量,因此简单查询不进行资源管理,异常规则也不生效。
设置方法:
资源池的内存管理是基于语句的估算内存进行管理的。
1)资源池可用内存设置方法
ALTER RESOURCE POOL resource_pool_a1 WITH (MEM_PERCENT=20);2)资源池作业估算内存限制设置方法
ALTER RESOURCE POOL resource_pool_a1 WITH (MEMORY_LIMIT="300MB");GaussDB(DWS)对外提供诸多系统视图,可以用来辅助资源管理及资源使用相关问题的分析定位,常用视图及用法说明如下表所示。(☆代表常用程度)
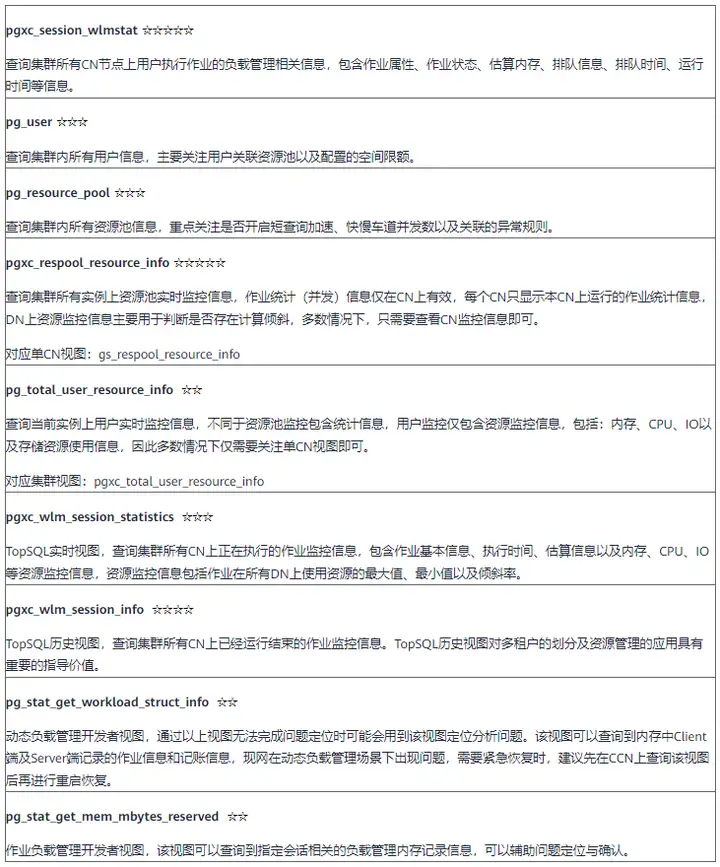
除过上述常用视图,资源管理问题定位过程需要根据实际场景,结合实例日志、集群状态等共同分析定位。
因为并发的配置和业务的复杂程度和集群的规格配置有很大的关系,本推荐仅做参考。推荐基于3CN 12DN,每个dn实例最大可使用64G内存情况下推荐的
在813内核版本及以上版本推荐配置如下。
GUC参数:
资源池参数:
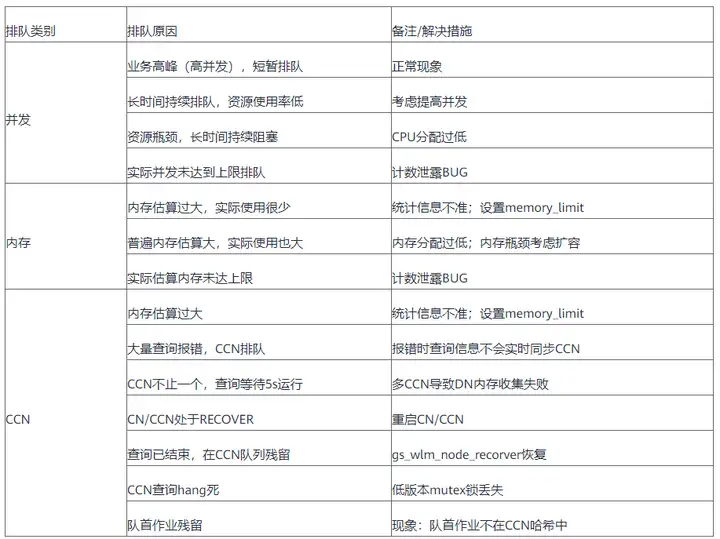
出现业务阻塞、性能下降、查询无响应等类似现网问题时,通过以下方法可以排查是否排队问题并定位排队原因,同时根据排队原因给出相应规避措施。
首先确认是否排队问题,其次排查排队原因,确认是否属于正常排队:
select rpname,slow_run,slow_wait,slow_limit,used_cpu,cpu_limit,used_mem,estimate_mem from gs_respool_resource_info;select resource_pool,attribute,lane,status,enqueue,sum(statement_mem) as stmt_mem,count(1) from pgxc_session_wlmstat where status!='finished' and attribute!='Internal' and usename!='Ruby' group by 1,2,3,4,5;通过视图可以获取到各资源池快慢车道作业运行信息,据此可以判断是否排队问题:
如果有作业处于排队状态,则可能是排队导致的问题,否则排除排队问题;可能的排队原因包括:
排查排队原因
常见排队原因及解决措施
1)全局并发排队
单CN实际运行作业数≥全局并发上限,则全局并发排队正常;
单CN实际运行作业数长时间小于全局并发上限,则可能存在计数泄露。
2)快车道排队
快车道实际运行作业数≥快车道并发上限,则快车道并发排队正常;
快车道实际运行作业数长时间小于快车道并发上限,则可能存在计数泄露。
3)静态慢车道排队
慢车道实际运行作业数≥慢车道并发上限,则慢车道并发排队正常;
慢车道实际运行作业累计估算内存≥慢车道内存上限,则慢车道内存占用达到上限导致排队,关注是否有查询估算内存过大;
如果慢车道并发和内存占用长时间达不到上限,则可能存在计数泄露。
4)动态CCN排队
如果查询在CCN排队,则需要查询CCN开发者视图确认排队原因:
select * from pg_stat_get_workload_struct_info();CCN上可能的排队原因:
1)查询资源池监控视图,确认是否正常排队(813及以上版本)
下面以单CN下发作业为例,多CN下发作业需查询pgxc_respool_resource_info视图。
select rpname,slow_run,slow_wait,slow_limit,used_cpu,cpu_limit,used_mem,estimate_mem from gs_respool_resource_info;通过该查询可以直观的观察各资源池作业负载信息,如果资源池running作业并发、内存长时间无法达到资源池上限,则考虑是否存在排队异常。
2)查询作业负载视图(813以下版本)
813及以上版本建议使用上边方法确认是否有排队异常,当然也可以使用以下方法确认存在排队异常,排除特性BUG影响。
813以下版本仅有pg_session_wlmstat视图,没有pgxc视图,可通过以下语句创建临时pgxc视图:
CREATE OR REPLACE VIEW pgxc_session_wlmstat_tp AS
SELECT * FROM pg_catalog.pgxc_parallel_query('cn', 'SELECT pg_catalog.pgxc_node_str(), * FROM pg_catalog.pg_session_wlmstat') AS (
nodename name,
datid oid,
datname name,
threadid bigint,
processid integer,
usesysid oid,
appname text,
usename name,
priority bigint,
attribute text,
block_time bigint,
elapsed_time bigint,
total_cpu_time bigint,
cpu_skew_percent integer,
statement_mem integer,
active_points integer,
dop_value integer,
control_group text,
status text,
enqueue text,
resource_pool name,
query text,
is_plana boolean,
node_group text,
lane text
);查询集群内各资源池在所有CN上的作业运行、排队统计信息:
select resource_pool,attribute,lane,status,enqueue,sum(statement_mem) as stmt_mem,count(1) from pgxc_session_wlmstat where status!='finished' and attribute!='Internal' and usename!='Ruby' group by 1,2,3,4,5;通过该查询可以直观的观察各资源池作业负载信息,如果资源池running作业并发、内存长时间无法达到资源池上限,则考虑是否存在排队异常。
确认是否存在排队异常
如果经过前两个步骤分析,怀疑可能存在排队异常,可能的原因有以下几种:
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
在我的路线文件中我有:match'graphs/(:id(/:action))'=>'graphs#(:action)'如果是GET请求(工作)或POST请求(不工作),我想匹配它我知道我可以使用以下方法在资源中声明POST请求:post'/'=>:show,:on=>:member但是我怎样才能为比赛做到这一点呢?谢谢。 最佳答案 如果你同时想要POST和GETmatch'graphs/(:id(/:action))'=>'graphs#(:action)',:via=>[:get,:post]编辑默认值可以设置如下match'g
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
在部署在heroku上的Rails应用程序(v:3.1)中,我在内存中获得了更多具有相同ID的对象。我的heroku控制台日志:>>Project.find_all_by_id(92).size=>2>>ActiveRecord::Base.connection.execute('select*fromprojectswhereid=92').to_a.size=>1这怎么可能?可能是什么问题? 最佳答案 解决方案根据您的SQL查询,您的数据库中显然没有重复条目。也许您的类项目中的size或length方法已被覆盖。我试过find_
我的两个不同的Rails应用程序的内存有一些奇怪的问题。这两个应用程序都使用rails3.0.7。每个Controller请求分配20-30-50MB的内存。在生产模式下,这个数量减少到5-10。但这是同样的事情。这是两个应用程序使用的gem列表:gem'pg'gem'haml'gem'sass'gem'devise'gem'simple_form'gem'state_machine'gem"globalize3","0.1.0.beta"gem"easy_globalize3_accessors"gem'paperclip'gem'andand'关闭所有这些gem不会给我任何结果。我
正如标题,我有一个处理大量数据的ruby程序。该程序占用了所有内存,其中调用了系统命令hostname,并且发生错误无法分配内存-主机名我试过GC.start但它不起作用。那么如何强制ruby释放未使用的内存呢?OK,这是别人的测试代码,最后报错是big_var被回收了。但是内存仍然没有释放。require"weakref"defreportputs"#{param}:\t\tMemory"+`psax-opid,rss|grep-E"^[[:space:]]*#{$$}"`.strip.split.map(&:to_i)[1].to_s+'KB'endbig_var=""#big