目录
在学习内连接与外连接之前,你不妨思考为什么要引入这两种连接方式,带着问题去学习,更有助于我们对知识的学习。
其实在单表查询中,我们是不会接触到内外连接查询的,内外连接查询的方式只是针对我们对于多表的查询,只不过这种方式在实际应用中的方式会根据不同业务需求去使用不同的方式来查询多表。
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
语法:
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
类似这样:
方式一:
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d
ON (e.department_id = d.department_id);
方式二:
SELECT employee_id,department_name
FROM employees e,departments d
WHERE e.`department_id` = d.department_id;
先看这样一段代码:
select 员工表.id,部门表.department
from 员工表,部门表
where 员工表.部门id=部门表.部门id; 这种查询方式:
它会把所有的符合where条件的字段查询出来。听起来十分合理,但是有这样一种这样的情况:就是两张表的数据有的不存在某种关系。(例如:员工表中有的员工他没有部门)

缺点:如果我们想要把不满足条件的数据也查询出来,内连接就做不到。
于是我们引入外连接。
查询多表时一般要求中出现:查询所有的数据时,就一定会用到外连接。(重点记忆)
外连接:
两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的 行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
(mysql不支持sql92,所以我们在写的外连接的语法都是sql99的)
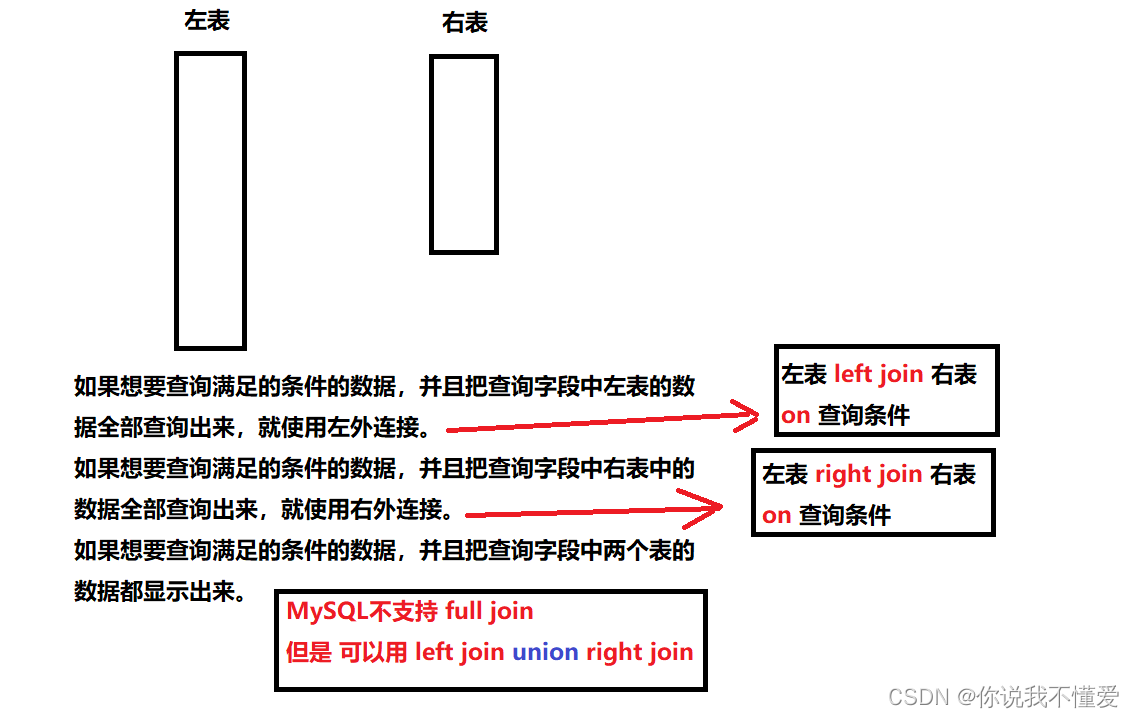
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句;
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
FROM A表 RIGHT JOIN B表
ON 关联条件
WHERE 等其他子句;
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
由于mysql不支持FULL JOIN,于是我们需要用 LEFT JOIN UNION RIGHT join代替。
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
普通查询:
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;
使用union关键字查询:
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90; (把这种数据查询出来取并集)具体用法:
UNION:会执行去重操作
UNION ALL:不会执行去重操作
结论:如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,
则尽量使用UNION ALL语句,以提高数据查询的效率。
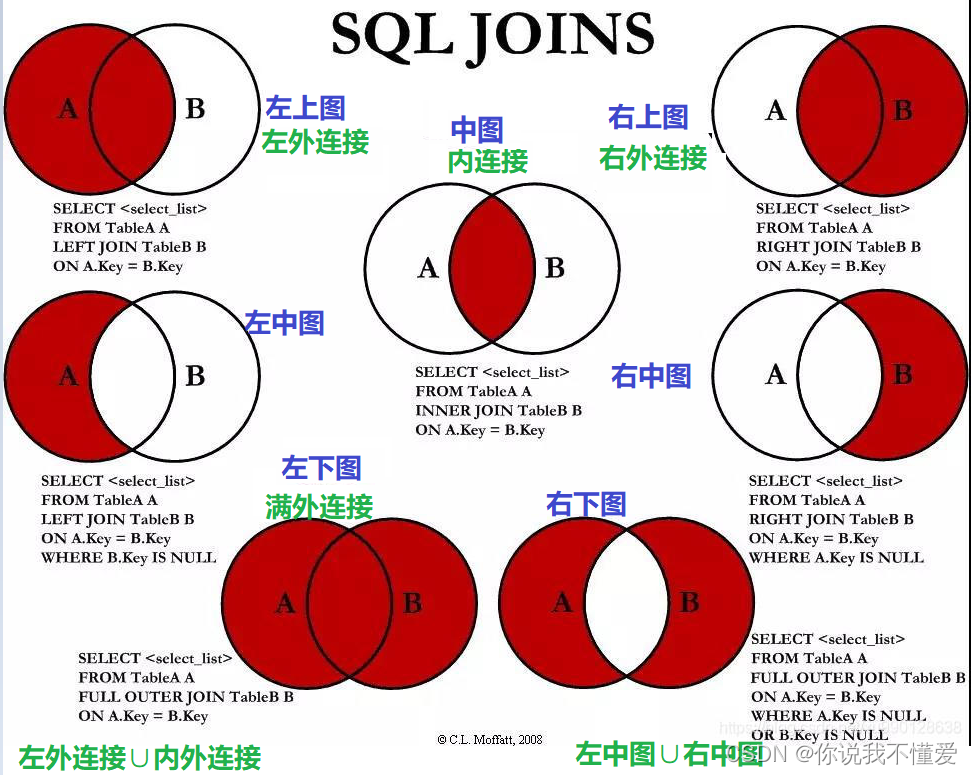
中图、左上图与右上图我们已经解决过了,分别对应内连接、左外连接以及右外连接。
思路:把左外连接查询出来的数据进行条件筛选
#实现A - A∩B
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句; (把数据进行剔除)
例子:
#左中图:A - A∩B SELECT employee_id,last_name,department_name FROM employees e LEFT JOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` IS NULL先进行查询 再把数据进行where筛选
思路:把右外连接查询出来的数据进行条件筛选
#实现B - A∩B
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
例子:
#右中图:B-A∩B SELECT employee_id,last_name,department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL把数据查询出来 再进行筛选
思路:使用union关键字来把数据库中查询的左外连接与右外连接查询出来的数据进行合并
值得注意的是:
用union all 来合并两个表中数据效率会高一些。
#实现查询结果是A∪B
#用左外的A,union 右外的B
select 字段列表
from A表 left join B表
on 关联条件
where 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 等其他子句;例子:
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
思路:将左中图与右中图的数据合并起来
#实现A∪B - A∩B 或 (A - A∩B) ∪ (B - A∩B)
#使用左外的 (A - A∩B) union 右外的(B - A∩B)
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
例子:
#右下图
#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
考虑一下:现在这些情况:#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2我需要用其他字符串输出URL。我如何保证&符号不会被转义?由于我无法控制的原因,我无法发送&。求助!把我的头发拉到这里:\编辑:为了澄清,我实际上有一个像这样的数组:@images=[{:id=>"fooid",:url=>"http://
我有一个super简单的脚本,它几乎包含了FayeWebSocketGitHub页面上用于处理关闭连接的内容:ws=Faye::WebSocket::Client.new(url,nil,:headers=>headers)ws.on:opendo|event|p[:open]#sendpingcommand#sendtestcommand#ws.send({command:'test'}.to_json)endws.on:messagedo|event|#hereistheentrypointfordatacomingfromtheserver.pJSON.parse(event.d
我有一个ruby脚本可以打开与Apple推送服务器的连接并发送所有待处理的通知。我看不出任何原因,但当Apple断开我的脚本时,我遇到了管道损坏错误。我已经编写了我的脚本来适应这种情况,但我宁愿只是找出它发生的原因,这样我就可以在第一时间避免它。它不会始终根据特定通知断开连接。它不会以特定的字节传输大小断开连接。一切似乎都是零星的。您可以在单个连接上发送的数据传输或有效负载计数是否有某些限制?看到人们的解决方案始终保持一个连接打开,我认为这不是问题所在。我看到连接在3次通知后断开,我看到它在14次通知后断开。我从未见过它能超过14点。有没有人遇到过这种类型的问题?如何处理?
我的意思是之前建立的那个DB=Sequel.sqlite('my_blog.db')或DB=Sequel.connect('postgres://user:password@localhost/my_db')或DB=Sequel.postgres('my_db',:user=>'user',:password=>'password',:host=>'localhost')等等。Sequel::Database类没有名为“disconnect”的公共(public)实例方法,尽管它有一个“connect”。也许有人已经遇到过这个问题。我将不胜感激。 最佳答案
我有一个遗留数据库,我正在努力让ActiveRecord使用它。我遇到了连接表的问题。我有以下内容:classTvShow然后我有一个名为tvshowlinkepisode的表,它有2个字段:idShow、idEpisode所以我有2个表和它们之间的连接(多对多关系),但是连接使用非标准外键。我的第一个想法是创建一个名为TvShowEpisodeLink的模型,但没有主键。我的想法是,由于外键是非标准的,我可以使用set_foreign_key并进行一些控制。最后,我想说一些类似TvShow.find(:last).episodes或Episode.find(:last).tv_sho
我正在使用PostgreSQL9.1.3(x86_64-pc-linux-gnu上的PostgreSQL9.1.3,由gcc-4.6.real(Ubuntu/Linaro4.6.1-9ubuntu3)4.6.1,64位编译)和在ubuntu11.10上运行3.2.2或3.2.1。现在,我可以使用以下命令连接PostgreSQLsupostgres输入密码我可以看到postgres=#我将以下详细信息放在我的config/database.yml中并执行“railsdb”,它工作正常。开发:adapter:postgresqlencoding:utf8reconnect:falsedat