摘要:ThreadPoolExecutor是Java线程池中最核心的类之一,它能够保证线程池按照正常的业务逻辑执行任务,并通过原子方式更新线程池每个阶段的状态。
本文分享自华为云社区《【高并发】通过Thread Pool Executor类的源码深度解析线程池执行任务的核心流程》,作者:冰 河。
今天,我们通过Thread Pool Executor类的源码深度解析线程池执行任务的核心流程,小伙伴们最好是打开IDEA,按照步骤,调试下Thread Pool Executor类的源码,这样会理解的更加深刻,好了,开始今天的主题。
Thread PoolExecutor是Java线程池中最核心的类之一,它能够保证线程池按照正常的业务逻辑执行任务,并通过原子方式更新线程池每个阶段的状态。
ThreadPoolExecutor类中存在一个workers工作线程集合,用户可以向线程池中添加需要执行的任务,workers集合中的工作线程可以直接执行任务,或者从任务队列中获取任务后执行。ThreadPoolExecutor类中提供了整个线程池从创建到执行任务,再到消亡的整个流程方法。本文,就结合ThreadPoolExecutor类的源码深度分析线程池执行任务的整体流程。
在ThreadPoolExecutor类中,线程池的逻辑主要体现在execute(Runnable)方法,addWorker(Runnable, boolean)方法,addWorkerFailed(Worker)方法和拒绝策略上,接下来,我们就深入分析这几个核心方法。
execute(Runnable)方法的作用是提交Runnable类型的任务到线程池中。我们先看下execute(Runnable)方法的源码,如下所示。
public void execute(Runnable command) {
//如果提交的任务为空,则抛出空指针异常
if (command == null)
throw new NullPointerException();
//获取线程池的状态和线程池中线程的数量
int c = ctl.get();
//线程池中的线程数量小于corePoolSize的值
if (workerCountOf(c) < corePoolSize) {
//重新开启线程执行任务
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程池处于RUNNING状态,则将任务添加到阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
//再次获取线程池的状态和线程池中线程的数量,用于二次检查
int recheck = ctl.get();
//如果线程池没有未处于RUNNING状态,从队列中删除任务
if (! isRunning(recheck) && remove(command))
//执行拒绝策略
reject(command);
//如果线程池为空,则向线程池中添加一个线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//任务队列已满,则新增worker线程,如果新增线程失败,则执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}整个任务的执行流程,我们可以简化成下图所示。
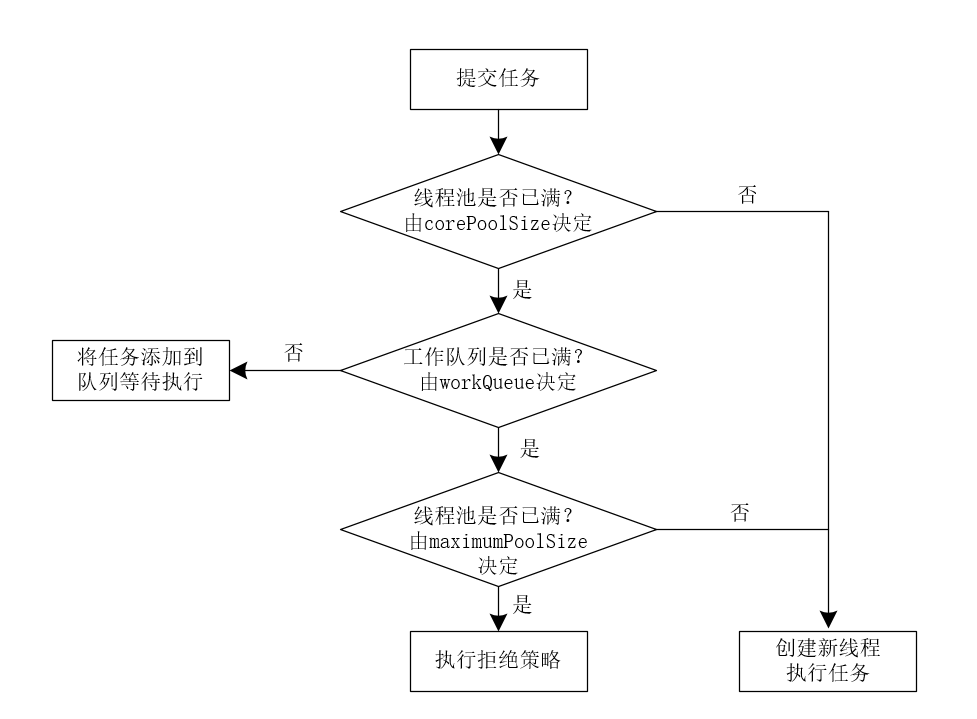
接下来,我们拆解execute(Runnable)方法,具体分析execute(Runnable)方法的执行逻辑。
(1)线程池中的线程数是否小于corePoolSize核心线程数,如果小于corePoolSize核心线程数,则向workers工作线程集合中添加一个核心线程执行任务。代码如下所示。
//线程池中的线程数量小于corePoolSize的值
if (workerCountOf(c) < corePoolSize) {
//重新开启线程执行任务
if (addWorker(command, true))
return;
c = ctl.get();
}(2)如果线程池中的线程数量大于corePoolSize核心线程数,则判断当前线程池是否处于RUNNING状态,如果处于RUNNING状态,则添加任务到待执行的任务队列中。注意:这里向任务队列添加任务时,需要判断线程池是否处于RUNNING状态,只有线程池处于RUNNING状态时,才能向任务队列添加新任务。否则,会执行拒绝策略。代码如下所示。
if (isRunning(c) && workQueue.offer(command)) (3)向任务队列中添加任务成功,由于其他线程可能会修改线程池的状态,所以这里需要对线程池进行二次检查,如果当前线程池的状态不再是RUNNING状态,则需要将添加的任务从任务队列中移除,执行后续的拒绝策略。如果当前线程池仍然处于RUNNING状态,则判断线程池是否为空,如果线程池中不存在任何线程,则新建一个线程添加到线程池中,如下所示。
//再次获取线程池的状态和线程池中线程的数量,用于二次检查
int recheck = ctl.get();
//如果线程池没有未处于RUNNING状态,从队列中删除任务
if (! isRunning(recheck) && remove(command))
//执行拒绝策略
reject(command);
//如果线程池为空,则向线程池中添加一个线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);(4)如果在步骤(3)中向任务队列中添加任务失败,则尝试开启新的线程执行任务。此时,如果线程池中的线程数量已经大于线程池中的最大线程数maximumPoolSize,则不能再启动新线程。此时,表示线程池中的任务队列已满,并且线程池中的线程已满,需要执行拒绝策略,代码如下所示。
//任务队列已满,则新增worker线程,如果新增线程失败,则执行拒绝策略
else if (!addWorker(command, false))
reject(command);这里,我们将execute(Runnable)方法拆解,结合流程图来理解线程池中任务的执行流程就比较简单了。可以这么说,execute(Runnable)方法的逻辑基本上就是一般线程池的执行逻辑,理解了execute(Runnable)方法,就基本理解了线程池的执行逻辑。
注意:有关ScheduledThreadPoolExecutor类和ForkJoinPool类执行线程池的逻辑,在【高并发专题】系列文章中的后文中会详细说明,理解了这些类的执行逻辑,就基本全面掌握了线程池的执行流程。
在分析execute(Runnable)方法的源码时,我们发现execute(Runnable)方法中多处调用了addWorker(Runnable, boolean)方法,接下来,我们就一起分析下addWorker(Runnable, boolean)方法的逻辑。
总体上,addWorker(Runnable, boolean)方法可以分为三部分,第一部分是使用CAS安全的向线程池中添加工作线程;第二部分是创建新的工作线程;第三部分则是将任务通过安全的并发方式添加到workers中,并启动工作线程执行任务。
接下来,我们看下addWorker(Runnable, boolean)方法的源码,如下所示。
private boolean addWorker(Runnable firstTask, boolean core) {
//标记重试的标识
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 检查队列是否在某些特定的条件下为空
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//下面循环的主要作用为通过CAS方式增加线程的个数
for (;;) {
//获取线程池中的线程数量
int wc = workerCountOf(c);
//如果线程池中的线程数量超出限制,直接返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//通过CAS方式向线程池新增线程数量
if (compareAndIncrementWorkerCount(c))
//通过CAS方式保证只有一个线程执行成功,跳出最外层循环
break retry;
//重新获取ctl的值
c = ctl.get();
//如果CAS操作失败了,则需要在内循环中重新尝试通过CAS新增线程数量
if (runStateOf(c) != rs)
continue retry;
}
}
//跳出最外层for循环,说明通过CAS新增线程数量成功
//此时创建新的工作线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//将执行的任务封装成worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//独占锁,保证操作workers时的同步
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//此处需要重新检查线程池状态
//原因是在获得锁之前可能其他的线程改变了线程池的状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
//向worker中添加新任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
//将是否添加了新任务的标识设置为true
workerAdded = true;
}
} finally {
//释放独占锁
mainLock.unlock();
}
//添加新任成功,则启动线程执行任务
if (workerAdded) {
t.start();
//将任务是否已经启动的标识设置为true
workerStarted = true;
}
}
} finally {
//如果任务未启动或启动失败,则调用addWorkerFailed(Worker)方法
if (! workerStarted)
addWorkerFailed(w);
}
//返回是否启动任务的标识
return workerStarted;
}乍一看,addWorker(Runnable, boolean)方法还蛮长的,这里,我们还是将addWorker(Runnable, boolean)方法进行拆解。
(1)检查任务队列是否在某些特定的条件下为空,代码如下所示。
// 检查队列是否在某些特定的条件下为空
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;(2)在通过步骤(1)的校验后,则进入内层for循环,在内层for循环中通过CAS来增加线程池中的线程数量,如果CAS操作成功,则直接退出双重for循环。如果CAS操作失败,则查看当前线程池的状态是否发生了变化,如果线程池的状态发生了变化,则通过continue关键字重新通过外层for循环校验任务队列,检验通过再次执行内层for循环的CAS操作。如果线程池的状态没有发生变化,此时上一次CAS操作失败了,则继续尝试CAS操作。代码如下所示。
for (;;) {
//获取线程池中的线程数量
int wc = workerCountOf(c);
//如果线程池中的线程数量超出限制,直接返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//通过CAS方式向线程池新增线程数量
if (compareAndIncrementWorkerCount(c))
//通过CAS方式保证只有一个线程执行成功,跳出最外层循环
break retry;
//重新获取ctl的值
c = ctl.get();
//如果CAS操作失败了,则需要在内循环中重新尝试通过CAS新增线程数量
if (runStateOf(c) != rs)
continue retry;
}(3)CAS操作成功后,表示向线程池中成功添加了工作线程,此时,还没有线程去执行任务。使用全局的独占锁mainLock来将新增的工作线程Worker对象安全的添加到workers中。
总体逻辑就是:创建新的Worker对象,并获取Worker对象中的执行线程,如果线程不为空,则获取独占锁,获取锁成功后,再次检查线线程的状态,这是避免在获取独占锁之前其他线程修改了线程池的状态,或者关闭了线程池。如果线程池关闭,则需要释放锁。否则将新增加的线程添加到工作集合中,释放锁并启动线程执行任务。将是否启动线程的标识设置为true。最后,判断线程是否启动,如果没有启动,则调用addWorkerFailed(Worker)方法。最终返回线程是否起送的标识。
//跳出最外层for循环,说明通过CAS新增线程数量成功
//此时创建新的工作线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//将执行的任务封装成worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//独占锁,保证操作workers时的同步
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//此处需要重新检查线程池状态
//原因是在获得锁之前可能其他的线程改变了线程池的状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
//向worker中添加新任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
//将是否添加了新任务的标识设置为true
workerAdded = true;
}
} finally {
//释放独占锁
mainLock.unlock();
}
//添加新任成功,则启动线程执行任务
if (workerAdded) {
t.start();
//将任务是否已经启动的标识设置为true
workerStarted = true;
}
}
} finally {
//如果任务未启动或启动失败,则调用addWorkerFailed(Worker)方法
if (! workerStarted)
addWorkerFailed(w);
}
//返回是否启动任务的标识
return workerStarted;在addWorker(Runnable, boolean)方法中,如果添加工作线程失败或者工作线程启动失败时,则会调用addWorkerFailed(Worker)方法,下面我们就来看看addWorkerFailed(Worker)方法的实现,如下所示。
private void addWorkerFailed(Worker w) {
//获取独占锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//如果Worker任务不为空
if (w != null)
//将任务从workers集合中移除
workers.remove(w);
//通过CAS将任务数量减1
decrementWorkerCount();
tryTerminate();
} finally {
//释放锁
mainLock.unlock();
}
}addWorkerFailed(Worker)方法的逻辑就比较简单了,获取独占锁,将任务从workers中移除,并且通过CAS将任务的数量减1,最后释放锁。
我们在分析execute(Runnable)方法时,线程池会在适当的时候调用reject(Runnable)方法来执行相应的拒绝策略,我们看下reject(Runnable)方法的实现,如下所示。
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}通过代码,我们发现调用的是handler的rejectedExecution方法,handler又是个什么鬼,我们继续跟进代码,如下所示。
private volatile RejectedExecutionHandler handler;再看看RejectedExecutionHandler是个啥类型,如下所示。
package java.util.concurrent;
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}可以发现RejectedExecutionHandler是个接口,定义了一个rejectedExecution(Runnable, ThreadPoolExecutor)方法。既然RejectedExecutionHandler是个接口,那我们就看看有哪些类实现了RejectedExecutionHandler接口。
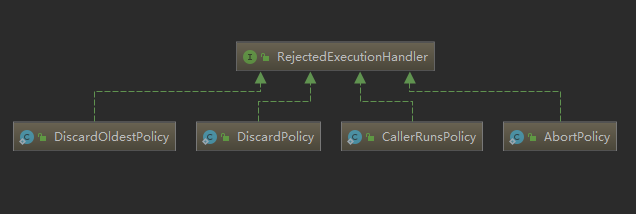
看到这里,我们发现RejectedExecutionHandler接口的实现类正是线程池默认提供的四种拒绝策略的实现类。
至于reject(Runnable)方法中具体会执行哪个类的拒绝策略,是根据创建线程池时传递的参数决定的。如果没有传递拒绝策略,则默认会执行AbortPolicy类的拒绝策略。否则会执行传递的类的拒绝策略。
在创建线程池时,除了能够传递JDK默认提供的拒绝策略外,还可以传递自定义的拒绝策略。如果想使用自定义的拒绝策略,则只需要实现RejectedExecutionHandler接口,并重写rejectedExecution(Runnable, ThreadPoolExecutor)方法即可。例如,下面的代码。
public class CustomPolicy implements RejectedExecutionHandler {
public CustomPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
System.out.println("使用调用者所在的线程来执行任务")
r.run();
}
}
}使用如下方式创建线程池。
new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
Executors.defaultThreadFactory(),
new CustomPolicy());至此,线程池执行任务的整体核心逻辑分析结束。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search