文章目录
四、启动 rabbitmq 内置 web 插件, 管理 rabbitmq 账号等信息 (3 台)
RabbitMQ一般以集群方式部署,主要提供消息的接受和发送,实现各微服务之间的消息异步。
单一模式:即单机情况不做集群,就单独运行一个 rabbitmq 而已。
普通模式:默认模式,以两个节点(rabbit01、rabbit02)为例,对于 Queue 来说,消息实体只存在于其中一个节点 rabbit01(或者 rabbit02),rabbit01 和 rabbit02 两个节点仅有相同的元数据,即队列的结构。当消息进入 rabbit01 的 Queue 后,consumer 从 rabbit02 消费时,RabbitMQ 会临时在 rabbit01、rabbit02 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给 consumer。
镜像模式: 把需要的队列做成镜像队列,存在与多个节点属于 RabbitMQ 的 HA 方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
3台centos7操作系统,ip分别为
192.168.22.155
192.168.22.157
192.168.22.161
关闭防火墙,selinux
[root@rabbitmq1 ~]# vi /etc/hosts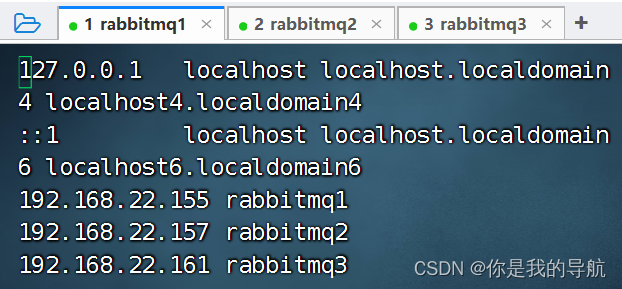
安装 erlang 环境和rabbitmq-server (3 台)--centos7
[root@rabbitmq1 ~]# yum install -y epel-release && yum -y install erlang erlang是rabbitmq的开发语言
[root@rabbitmq1 ~]# yum -y install rabbitmq-server
启动服务 (3 台)
[root@rabbitmq1 ~]# systemctl start rabbitmq-server.service
[root@rabbitmq1 ~]# systemctl stop rabbitmq-server.service
[root@rabbitmq1 ~]# systemctl enable rabbitmq-server.service
[root@rabbitmq1 ~]# systemctl restart rabbitmq-server.service
安装启动后其实还不能在其它机器访问,rabbitmq 默认的 guest 账号只能在本地机器访问, 如果想在其它机器访问必须配置其它账号
配置管理员账号
[root@rabbitmq1 ~]# rabbitmqctl add_user admin admin 可以创建管理员用户,负责整个 MQ 的运维
[root@rabbitmq1 ~]# rabbitmqctl set_user_tags admin administrator 赋予其 administrator 角色
[root@rabbitmq1 ~]# rabbitmqctl add_user user_monitoring passwd_monitor 创建 RabbitMQ 监控用户,负责整个 MQ 的监控
[root@rabbitmq1 ~]# rabbitmqctl set_user_tags user_monitoring monitoring 创建某个项目的专用用户,只能访问项目自己的 virtual hosts
[root@rabbitmq1 ~]# rabbitmqctl set_user_tags user_monitoring management
[root@rabbitmq1 ~]# rabbitmqctl list_users 创建和赋角色完成后查看并确认
[root@rabbitmq1 ~]# rabbitmq-plugins enable rabbitmq_management
[root@rabbitmq1 ~]# systemctl restart rabbitmq-server.service 重启服务
启动起来就可以访问,三台机器哪台都行, http:// 你的地址:15672

centos7使用用户guest、密码guest登录,这个账户拥有所有的权限
页面如下:

统一 erlang.cookie 文件中 cookie 值
必须使集群中也就是rabbitmq2,rabbitmq3这两台机器的.erlang.cookie 文件中 cookie 值一致,且权限为 owner 只读。
[root@rabbitmq1 ~]# scp /var/lib/rabbitmq/.erlang.cookie 192.168.22.157:/var/lib/rabbitmq/.erlang.cookie
[root@rabbitmq1 ~]# scp /var/lib/rabbitmq/.erlang.cookie 192.168.22.161:/var/lib/rabbitmq/.erlang.cookie
[root@rabbitmq2 ~]# chmod 600 /var/lib/rabbitmq/.erlang.cookie
[root@rabbitmq3 ~]# chmod 600 /var/lib/rabbitmq/.erlang.cookie
查看集群状态
[root@rabbitmq1 ~]# rabbitmqctl status
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
重启 rabbitmq1机器中 rabbitmq 的服务
在 rabbitmq2,rabbitmq3 分别执行。
[root@rabbitmq1 ~]# systemctl restart rabbitmq-server.service
[root@rabbitmq2 ~]# rabbitmqctl stop_app
[root@rabbitmq2 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq1
[root@rabbitmq2 ~]# rabbitmqctl start_app
[root@rabbitmq2 ~]# rabbitmq-plugins enable rabbitmq_management

如此便可以啦,你可以做下测试。
首先镜像模式要依赖policy模块,这个模块是做什么用的呢?
policy中文来说是政策,策略的意思,那么他就是要设置,那些Exchanges或者queue的数据需要复制,同步,如何复制同步?对就是做这些的。
[root@rabbitmq1 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
参数意思为:
ha-all:为策略名称。
^:为匹配符,只有一个^代表匹配所有,^zlh为匹配名称为zlh的exchanges或者queue。
ha-mode:为匹配类型,他分为3种模式:
all-所有(所有的 queue),
exctly-部分(需配置ha-params参数,此参数为int类型比如3,众多集群中的随机3台机器),
nodes-指定(需配置ha-params参数,此参数为数组类型比如["3rabbit@F","rabbit@G"]这样指定为F与G这2台机器。)。
镜像队列是基于普通的集群模式
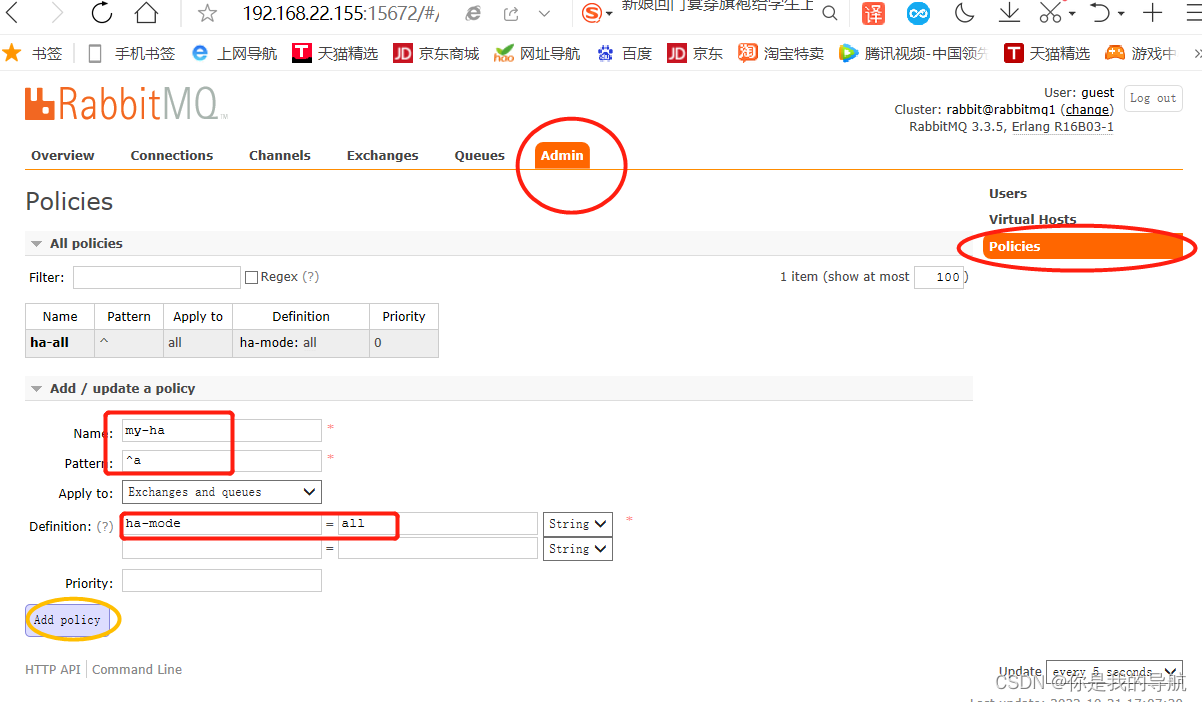
1.点击admin菜单–>右侧的Policies选项–>左侧最下下边的Add / update a policy
2.按照图中的内容根据自己的需求填写
3.点击Add policy添加策略的,所以你还是得先配置普通集群,然后才能设置镜像队列.
【注意】书到用时方恨少,知识需要一定的积累。少熬夜,多看书。
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我是ruby的新手,正在配置IRB。我喜欢pretty-print(需要'pp'),但总是输入pp来漂亮地打印它似乎很麻烦。我想做的是默认情况下让它漂亮地打印出来,所以如果我有一个var,比如说,'myvar',然后键入myvar,它会自动调用pretty_inspect而不是常规检查。我从哪里开始?理想情况下,我将能够向我的.irbrc文件添加一个自动调用的方法。有什么想法吗?谢谢! 最佳答案 irb中默认pretty-print对象正是hirb被迫去做。Theseposts解释hirb如何将几乎所有内容转换为ascii表。虽