伴随政府信息化建设的推进,数字政府建设从“量增长”向“质提升”的发展,为解决长期以来困扰政府数字化转型建设的“各自为政、条块分割、烟囱林立、信息孤岛”等多种问题,一体化的政务云建设呈现出蓬勃发展的态势。

在国产化趋势和国家政策引导的背景下,尤其是在“十四五”规划期间,推进政务云架构逐步过渡和迁移至国产化平台已成为重要发展趋势。
同时,基于“OpenStack + KVM”的开源产品不断推陈出新,国产云厂商在市场和技术方面的实力不断提升,原本使用VMware虚拟化平台的用户转而使用国产化云/虚拟化平台,或将部分业务转移到其他虚拟化平台上,这样的异构环境对数据备份和迁移提出了更高的要求。
某市政务云异构虚拟化平台迁移实例
该市政务云为地级市政务云,具备相当规模的数据中心,运行G2G、G2B、G2C等多种政务系统,涉及面广,数据体量大,主要业务系统运行在VMware平台上,拥有大量的虚拟机。
需求与挑战
该客户过去已采用云祺数据备份方案,对数据中心进行了完整容灾备份保护。但根据政策指导性意见,该市政务云需要采用国产虚拟化平台,替换原有的VMware平台,对异构平台的虚拟机进行整机迁移,且迁移过程需确保所有数据的安全性和一致性,减少迁移对业务系统正常运行的影响。
传统迁移方案需要在虚拟机操作系统中安装代理插件,虚拟机只能恢复到原虚拟化平台,迁移过程中无法保证原虚拟机的正常运行,在海量虚拟机场景下流程更为繁琐,并伴有兼容性风险,出现虚拟化平台级别的故障时,无法快速的恢复业务系统,迁移授权的成本也较高。
云祺解决方案
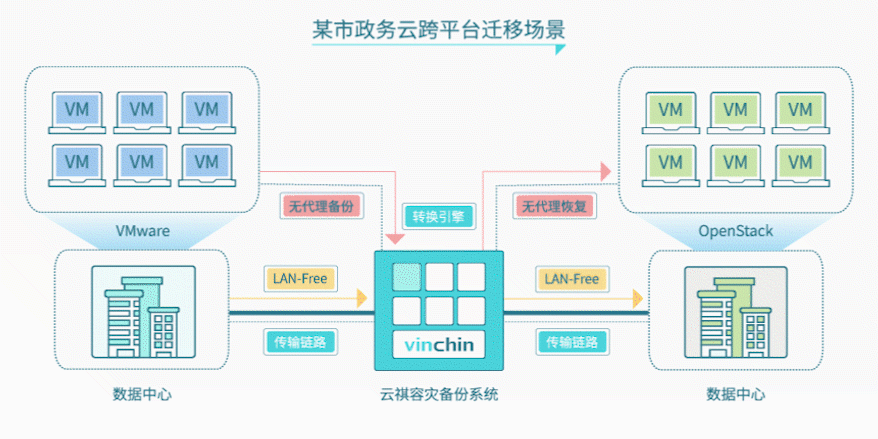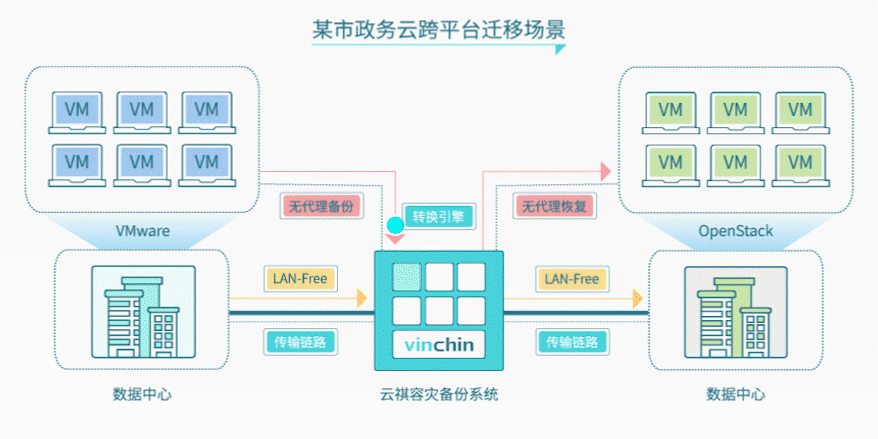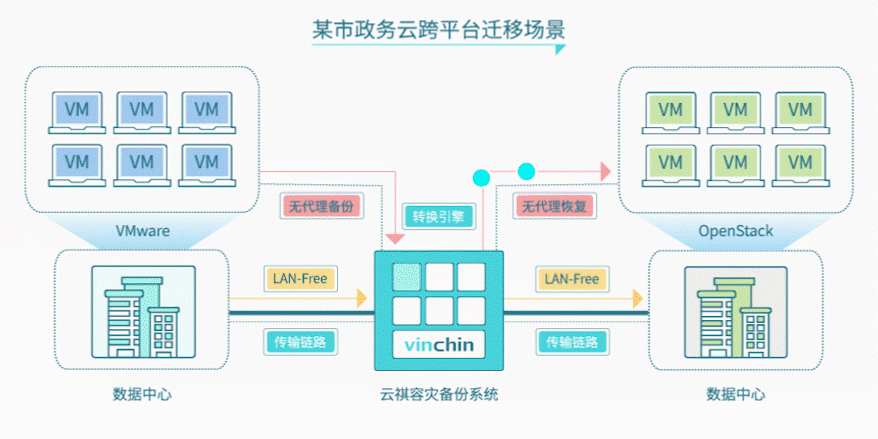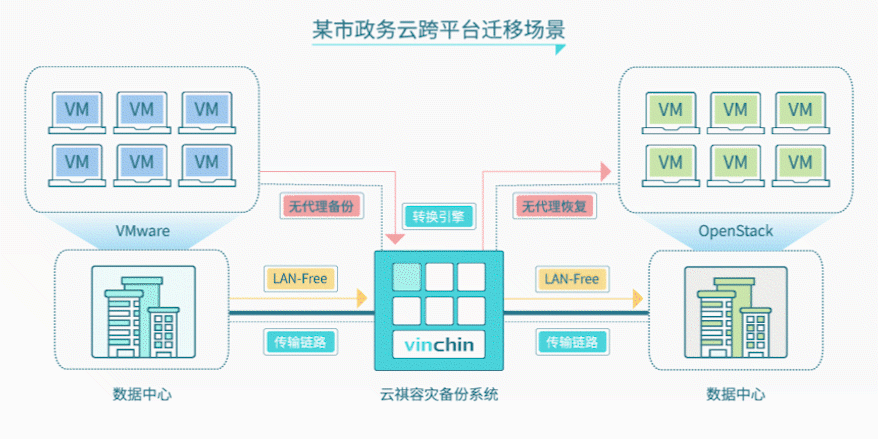
针对该政务云现有环境和迁移需求,云祺为其提供无代理跨平台迁移解决方案:
1、利用原有云祺容灾备份系统,开通虚拟机V2V无代理恢复功能;
2、将原虚拟化平台(VMware)备份系统数据直接恢复至新云平台中(OpenStack);
3、无需在虚拟机安装代理,直接恢复虚拟机整机,避免安全隐患;
4、通过增量备份方式备份源虚拟机,再直接恢复到新的云平台中,减少对虚拟机的影响。
客户收益
数据集中迁移:批量无代理恢复虚拟机,提高迁移效率;
良好的兼容性:无需在虚拟机安装代理,防止出现不兼容现象;
迁移时间可控:海量虚拟机快速迁移,迁移工作时长可观;
极简的操作和管理:全中文图形可视化界面,操作简单,通过简单培训即可独立操作。
不仅是政务云平台,混合云环境下实现异构虚拟化恢复与迁移,一直是各行各业用户面临的难题。
不同于市面上有代理的恢复方案,云祺虚拟机无代理跨平台恢复解决方案利用自主研发的虚拟化跨平台转换引擎(Virtual Machine Convert Engine)对已备份虚拟机文件进行高效的存储格式转换和转信息转换,满足数据迁移、异构恢复、海量虚拟机等不同场景下的需求。
同时,云祺无代理级别的跨平台恢复与迁移凭借瞬时恢复功能,还可实现多平台容灾,为多云数据中心提供更加灵活的容灾手段。
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在创建一个新的Rails3.1应用程序。我希望这个新应用程序重用现有数据库(由以前的Rails2应用程序创建)。我创建了新的应用程序定义模型,它重用了数据库中的一些现有数据。在开发和测试阶段,一切正常,因为它在干净的表数据库上运行,但是当尝试部署到生产环境时,我收到如下消息:PGError:ERROR:column"email"ofrelation"users"alreadyexists***[err::localhost]:ALTERTABLE"users"ADDCOLUMN"email"charactervarying(255)DEFAULT''NOTNULL但是我在迁移中有这
我想使用PostgreSQL中的point类型。我已经完成了:railsgmodelTestpoint:point最终的迁移是:classCreateTests当我运行时:rakedb:migrate结果是:==CreateTests:migrating====================================================--create_table(:tests)rakeaborted!Anerrorhasoccurred,thisandalllatermigrationscanceled:undefinedmethod`point'for#/hom
我是Rails的新手,我是从Django背景开始接触它的。我已经接受了这样一个事实,即模型和数据库模式在Rails和在线Django中是分开的。但是,我仍在努力处理迁移。我的问题很简单-如何使用迁移向模型添加关系?例如,我现在有Artist和Song作为ActiveRecord::Base子类的空模型,没有任何关系。我需要开始做这件事:classArtist但是我如何使用railsgmigrate更改架构以反射(reflect)这一点?我正在使用Rails3.1.3。 最佳答案 现在,在Rails4中,您可以:classAddPro
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但
我的生产Rails应用程序需要167秒来运行rakedb:migrate。可悲的是,没有要运行的迁移。我试图在检查是否有待处理的迁移时调整运行的迁移,但随后检查花费了同样长的时间。我心目中唯一的“借口”是数据库并不小,那里有1M条记录,但我看不出这有什么关系。我查看了日志,但没有任何迹象表明出了什么问题。我在运行ruby2.2.0rails4.2.0有没有人知道为什么会这样,是否有什么办法可以解决? 最佳答案 运行rakedb:migrate任务还会调用db:schema:dump任务,这将更新您的db/schema.rb。因此,即