最近ChatGPT大火,其实去年11月份就备受关注了,最近火出圈了,还是这家伙太恐怖了,未来重复性的工作很危险。回归主题,ChatGPT就是由无数个(具体也不知道多少个,哈哈哈哈)Transformer语言模型组成,Transformer最开始在2017年提出,目的是解决序列数据的训练,大多数应用到了语言相关,最近在图像领域也很有作为,属于是多点开花了。今天来简单看看他的实现吧。
目录
说实话,介绍这个东西优点太伤神了,我想把有限的时间浪费在有意义的事情上,不对其数学原理发表什么了(主要是不会),简单介绍他的组成结构吧。
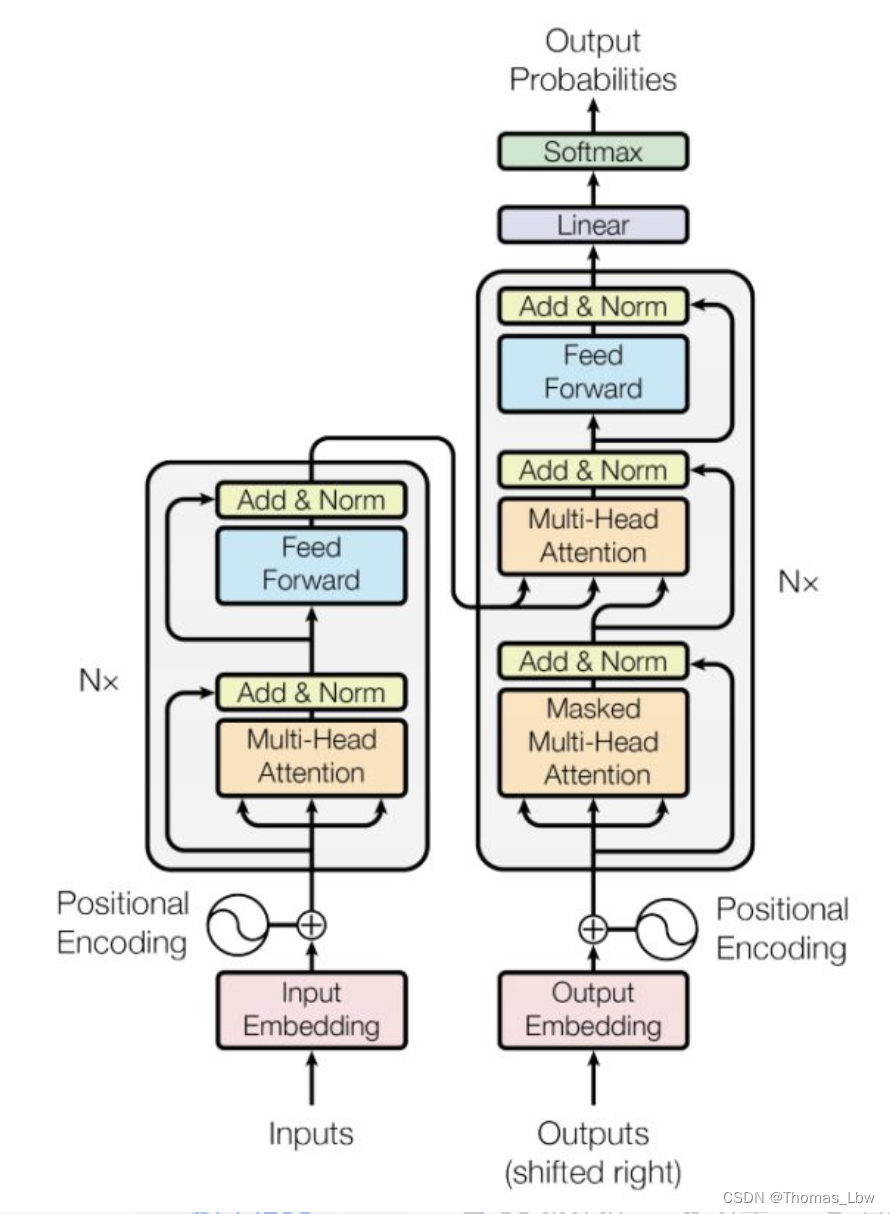
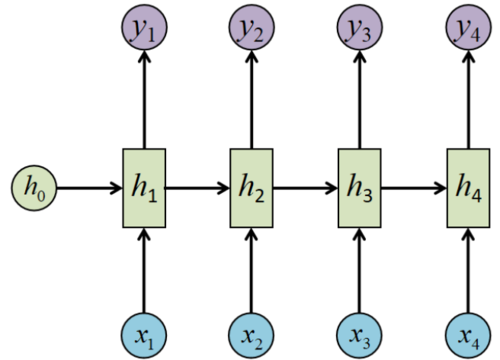
上图是组成transformer的一部分,他可以被分为编码层和解码层,对于语言这样的序列来讲,必须对其进行编码才能使用其数据信息。最简单的编码便是一个字符对应一个数字,这个大家心中有数就好,真实的Transformer编码原理肯定比这个复杂,不过现在的torch里你可以不需要知道内部的细节,可以直接调用。为了更直观的理解,你可以预习RNN的编码解码。总之,这个过程是一种信息转化、提取的过程,将计算机不懂的字符变为它能计算的数字。RNN图如下:
具体原理实现可以看下面的链接:
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerEncoder(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(TransformerEncoder, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.num_layers = num_layers
def forward(self, x, mask=None):
attn_output, _ = self.self_attn(x, x, x, attn_mask=mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
ff = self.feed_forward(x)
x = x + self.dropout(ff)
x = self.norm2(x)
return x
class TransformerDecoder(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(TransformerDecoder, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.src_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.num_layers = num_layers
def forward(self, x, src, mask=None, src_mask=None):
attn_output, _ = self.self_attn(x, x, x, attn_mask=mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
attn_output, _ = self.src_attn(x, src, src, attn_mask=src_mask)
x = x + self.dropout(attn_output)
x = self.norm2(x)
ff = self.feed_forward(x)
x = x + self.dropout(ff)
x = self.norm3(x)
return x
class Transformer(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(Transformer, self).__init__()
self.encoder = TransformerEncoder(d_model, nhead, num_layers, dim_feedforward, dropout)
self.decoder = TransformerDecoder(d_model, nhead, num_layers, dim_feedforward, dropout)
self.d_model = d_model
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
memory = self.encoder(src, src_mask)
output = self.decoder(tgt, memory, tgt_mask, src_mask)
return output
if __name__ == "__main__":
d_model = 512
nhead = 8
num_layers = 6
dim_feedforward = 2048
dropout = 0.1
transformer = Transformer(d_model, nhead, num_layers, dim_feedforward, dropout)
src = torch.randn(10, 32, d_model)
tgt = torch.randn(20, 32, d_model)
output = transformer(src, tgt)
print(src)
print("########################")
print(output)
src 和 tgt 分别是输入的源数据和目标数据,大小为 batch_size x sequence_length x d_model。src_mask 和 tgt_mask 分别是对于 src 和 tgt 的有效位置的掩码,大小为 batch_size x sequence_length x sequence_length,为了实现对填充位置的忽略。d_model 是模型中间语义空间的维数。nhead 是多头注意力机制中每个头的数量。num_layers 是编码器和解码器的层数。dim_feedforward 是前馈网络的隐藏层大小。dropout 是 dropout 的比率。在语言领域,Transformer有很强大的序列特征提取能力,具体多强我并没有感受,因为没用过,没法对比。不过ChatGPT的大量使用Transformer足可以证明它正值年壮,没道理我们不用它。
在图像领域同样很强,不过需要大量数据来训练,否则它不如CNN,这个也都是大量先人的经验,踩过坑自然知道。缺点还有就是模型太大,需要很大的算力。
你可以把它当成黑盒来用,这个是Transformer用于翻译:

用于图像领域,如果是图像像素点判断(图像分割),那么需要将FC去掉,根据自己需要修改吧:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerEncoder(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(TransformerEncoder, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.num_layers = num_layers
def forward(self, x, mask=None):
attn_output, _ = self.self_attn(x, x, x, attn_mask=mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
ff = self.feed_forward(x)
x = x + self.dropout(ff)
x = self.norm2(x)
return x
class ImageTransformer(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(ImageTransformer, self).__init__()
self.encoder = TransformerEncoder(d_model, nhead, num_layers, dim_feedforward, dropout)
self.fc = nn.Linear(d_model, 1024)
def forward(self, x):
x = self.encoder(x)
x = self.fc(x)
x = F.relu(x)
return x
if __name__ == "__main__":
# 实例化ImageTransformer模型
model = ImageTransformer(d_model=16, nhead=8, num_layers=6, dim_feedforward=2048, dropout=0.1)
# 使用图像数据输入模型
image = torch.randn(3, 16, 16)
features = model(image)
print(features)
Transformer用来训练语言模型一点问题没有,人家本来就是为序列而生。但是训练图像需要甄别自己的实际情况。随着ChatGPT的爆火,你不了解它,但是它在了解你。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o