有时 Logstash Grok 没有我们需要的模式。 幸运的是我们有正则表达式库:Oniguruma。在很多时候,如果 Logstash 所提供的正则表达不能满足我们的需求,我们选用定制自己的表达式。
如果你已经在运行 Logstash,则无需安装额外的正则表达式库,因为 Grok 位于正则表达式之上,因此任何正则表达式在 grok 中也有效 —— Elastic 文档。
Grok 语法如下:
%{SYNTAX:SEMANTIC}
oniguruma 语法如下:
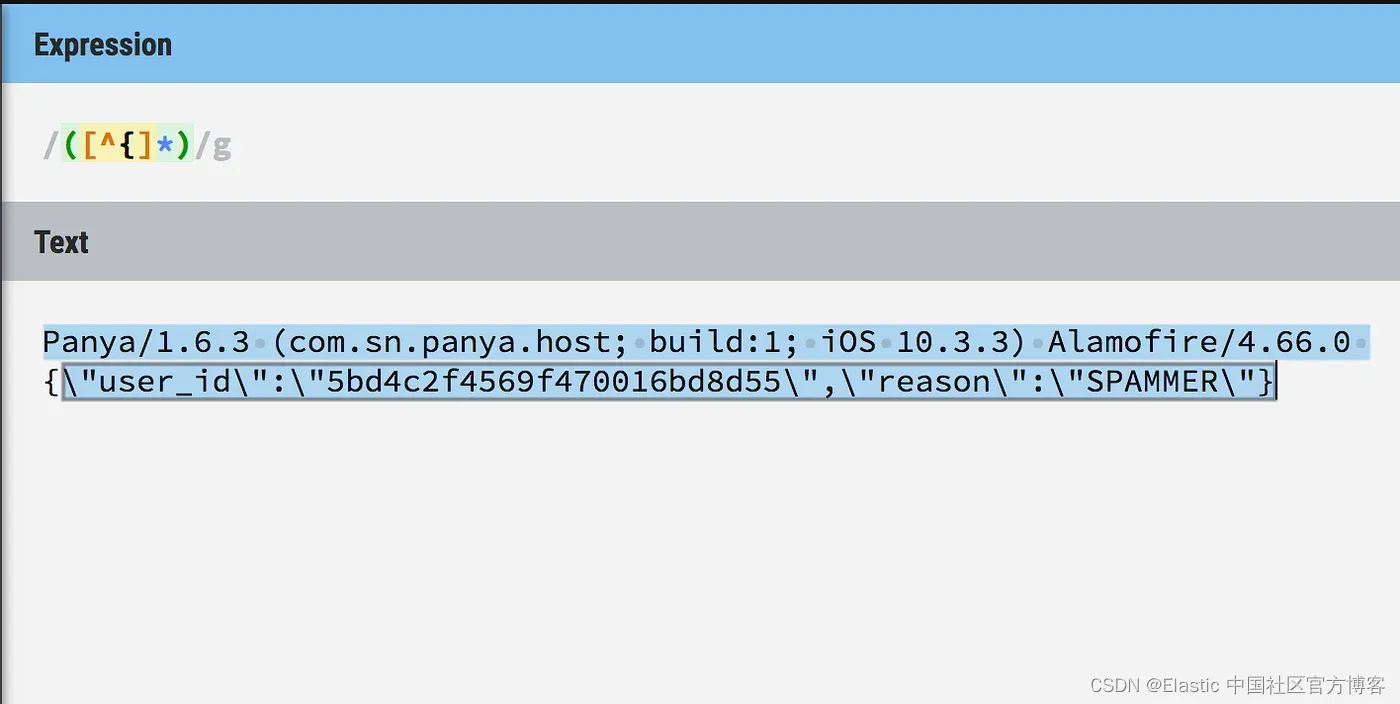
(?<field_name>the pattern here)
你可以像下面这样组合 Grok 和 Oniguruma:
%{SYNTAX:SEMANTIC} (?<field_name>the pattern here)
为了演示我们如何将 Oniguruma 与 Grok 结合使用,我们将在示例中使用下面的日志数据。
production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {\"user_id\":\"5bd4c2f4569f470016bd8d55\",\"reason\":\"SPAMMER\"}
production == environment
GET == method
/v2/blacklist == url
200 == response_status
24ms == response_time
5bc6e716b5d6cb35fc9687c0 == user_id
Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 == user_agent
{\"user_id\":\"5bd4c2f4569f470016bd8d55\",\"reason\":\"SPAMMER\"} == req.body目标是找到一种模式来构造非结构化日志数据。为此,我们将使用 Kibana 里的 Grok Debugger 来进行测试:
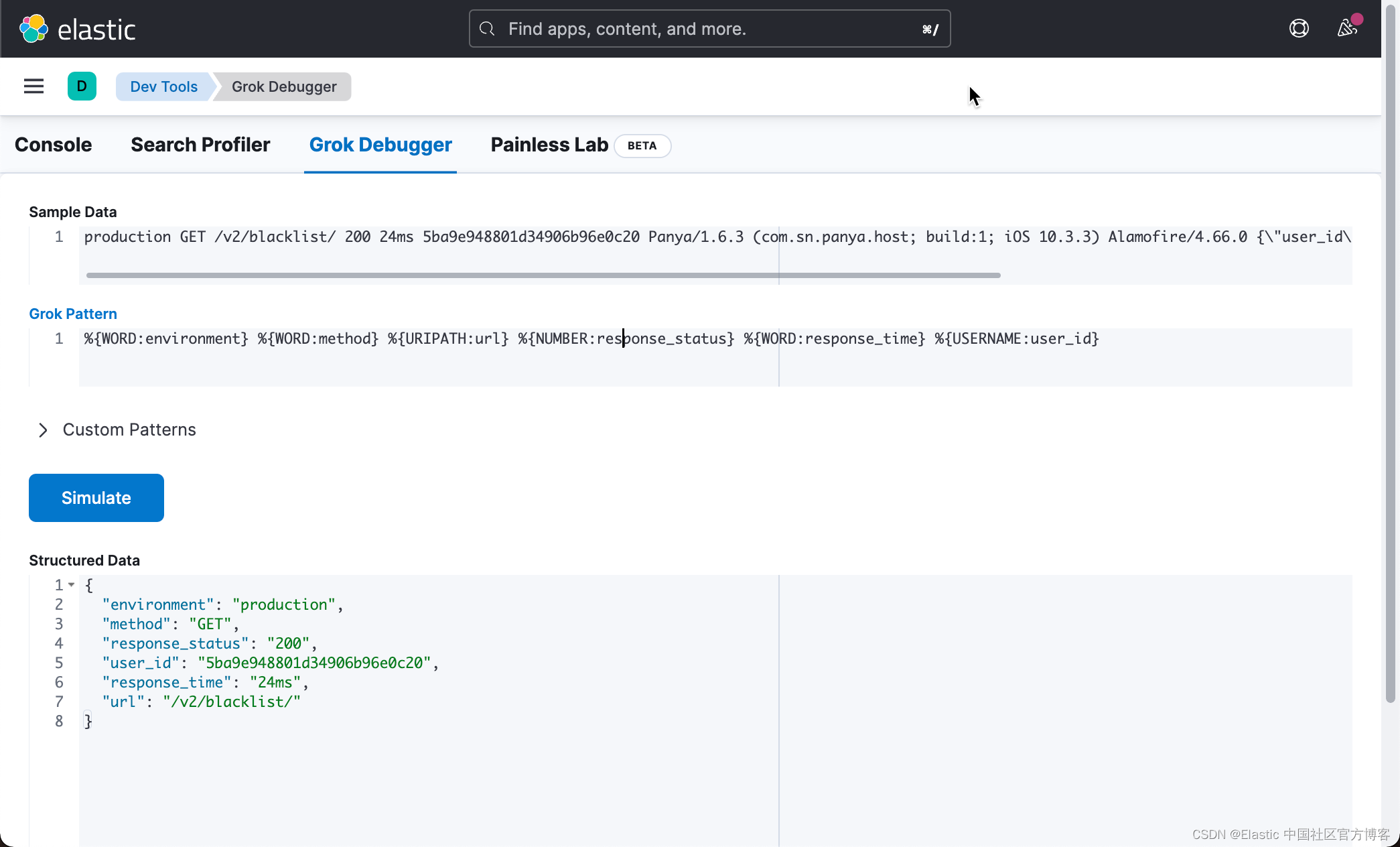
其中,我们的 Grok pattern 定义如下:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}如上所示,上面的 Grok pattern 产生如下的结果:
{
"environment": "production",
"method": "GET",
"response_status": "200",
"user_id": "5ba9e948801d34906b96e0c20",
"response_time": "24ms",
"url": "/v2/blacklist/"
}这是一个不错的开始,但还不完整。 没有 user_agent 和 req.body 的映射。要提取 user_agent 和 req.body,我们需要仔细检查其结构。
值 production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 由空格分隔,这很容易使用。
但是,对于 user_agent,可以有动态数量的空格,具体取决于发送请求的硬件类型。
Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 我们如何解释这种持续变化?
提示:看一下 req.body 的结构。
{\”user_id\”:\”5bd4c2f4569f470016bd8d55\”,\”reason\”:\”SPAMMER\”}我们可以看到 req.body 是由花括号 {} 组成的。
利用这些知识,我们可以构建一个自定义正则表达式模式来查找第一个左括号之前的所有内容,然后获取之后的所有内容。
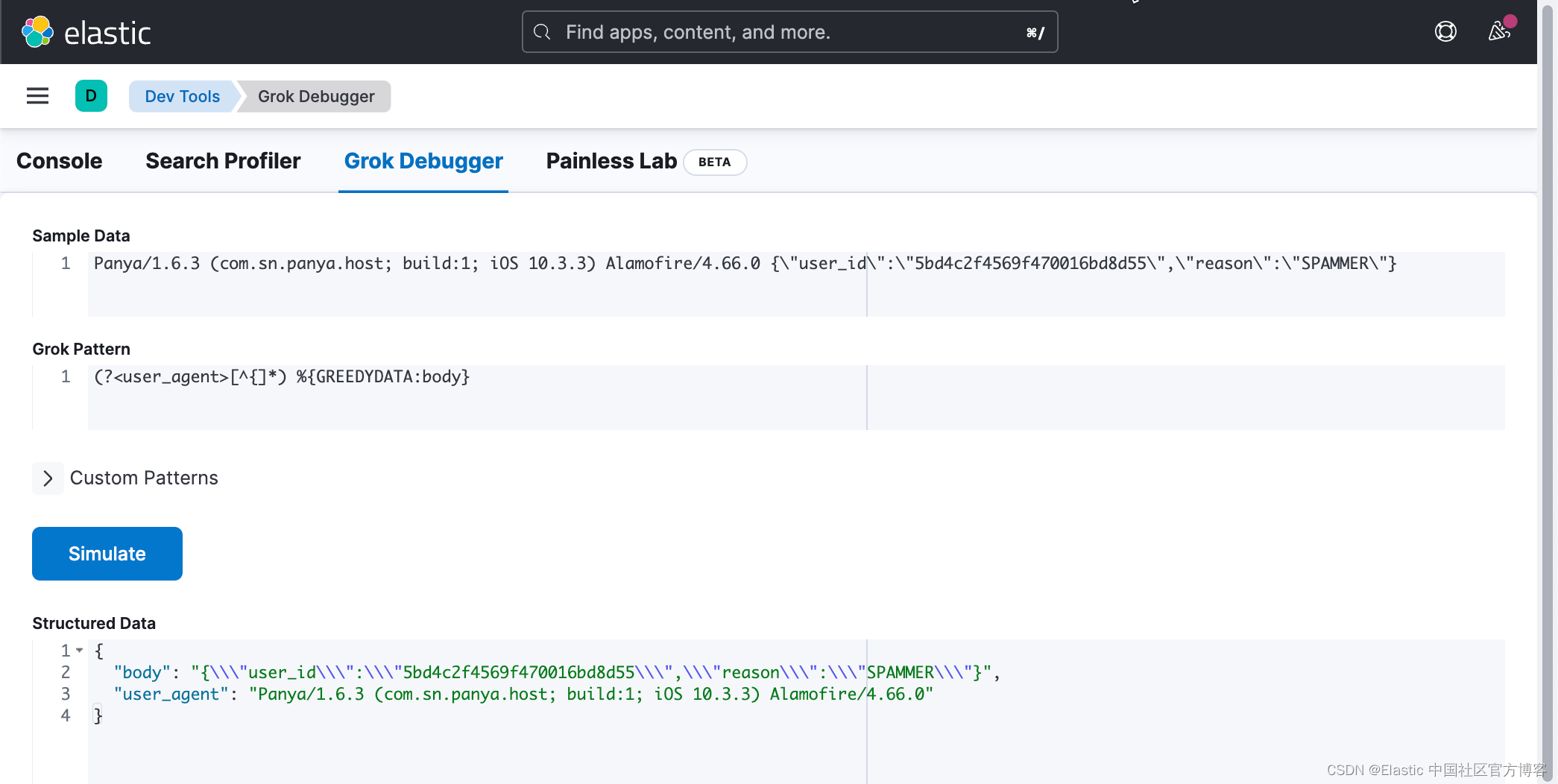
在上面,我们使用 Grok pattern:
(?<user_agent>[^{]*) %{GREEDYDATA:body}你可在这个链接中找到 “regex match everything until character”。
将其应用于 grok 调试器中的自定义正则表达式模式,我们得到了我们想要的结果:
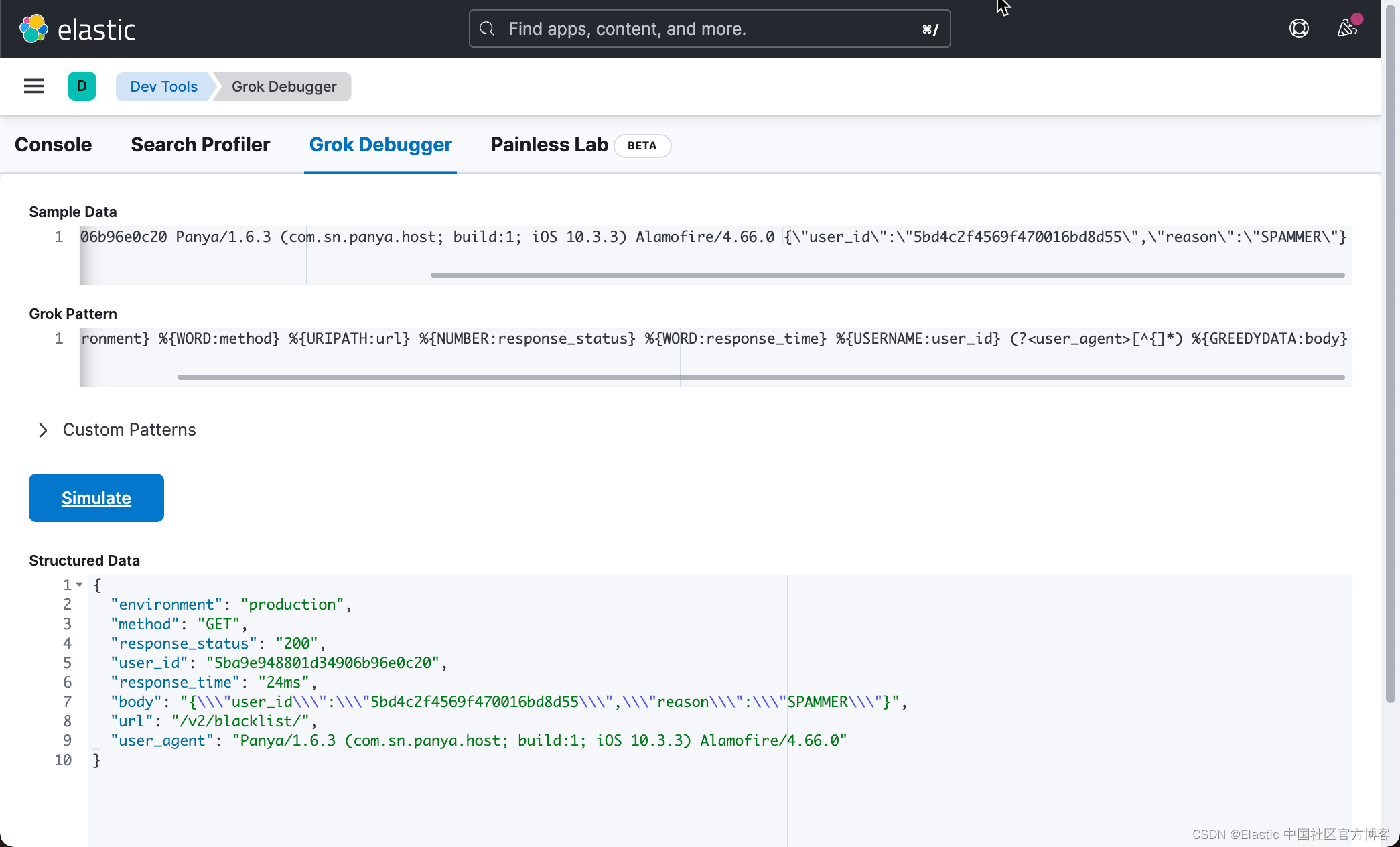
我们的 Grok pattern 为:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id} (?<user_agent>[^{]*) %{GREEDYDATA:body}
为了能够测试我们的 Grok pattern 是否正确,我们创建如下的一个 logstash.conf 文件。我们可以参考之前的文章 “Logstash:在实施之前测试 Logstash 管道/过滤器”。
logstash.conf
input {
generator {
message => 'production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {"user_id":"5bd4c2f4569f470016bd8d55","reason":"SPAMMER"}'
count => 1
}
}
filter {
grok {
match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id1} (?<user_agent>[^{]*) %{GREEDYDATA:body}"}
}
mutate {
remove_field => ["message", "event", "host", "@version"]
}
}
output {
stdout {
codec => rubydebug
}
}我们使用如下的命令来启动 Logstash pipeline:
./bin/logstash -f logstash.conf
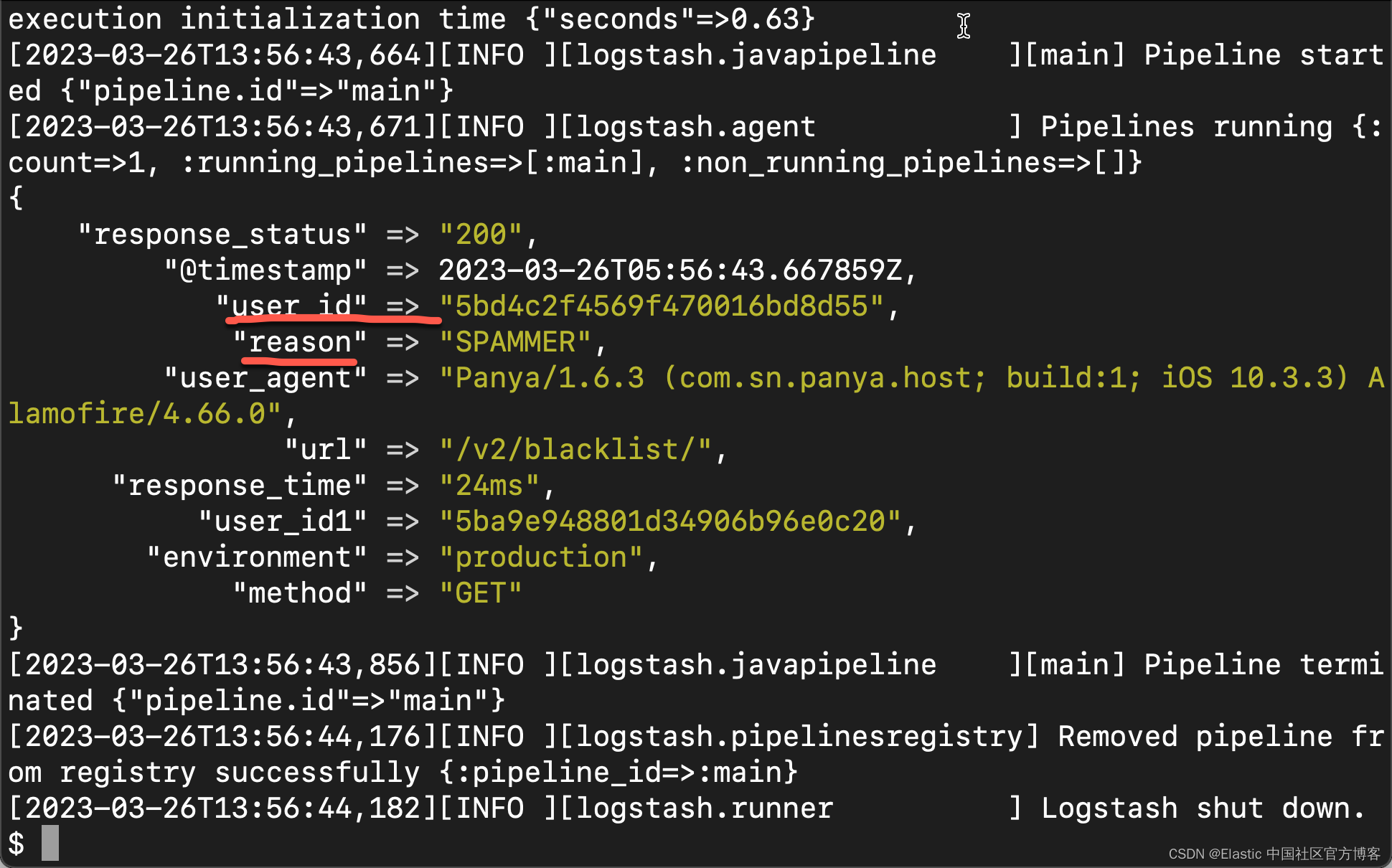
从上面的输出中,我们可以看出来原始的数据已经变为结构化的数据了。我们可以看到美中不足的是 body 这个数据是一个 JSON 格式的数据,还没有被结构化。我们进一步修改我们的 logstash.conf 配置文件:
logstash.conf
input {
generator {
message => 'production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {"user_id":"5bd4c2f4569f470016bd8d55","reason":"SPAMMER"}'
count => 1
}
}
filter {
grok {
match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id1} (?<user_agent>[^{]*) %{GREEDYDATA:body}"}
}
json {
source => "body"
}
mutate {
remove_field => ["message", "event", "host", "@version", "body"]
}
}
output {
stdout {
codec => rubydebug
}
}在上面,我们添加了 json 过滤器来处理 body,从而更进一步结构化数据。我们再次运行 Logstash。我们可以看到如下的结果:

从上面,我们可以看到 body 也被结果化了。我们可以看到 user_id 及 reason 两个字段。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t