摘要:GaussDB(DWS) 中锁等待可以设置等待超时相关参数,一旦等锁的时间超过参数配置值会抛错。
本文分享自华为云社区《GaussDB(DWS) 锁相关参数及视图详解》,作者: yd_220527686。
GaussDB(DWS) 中锁等待可以设置等待超时相关参数,一旦等锁的时间超过参数配置值会抛错。跟锁相关的参数有4个,具体含义如下:
1.deadlock_timeout
表示死锁检测时间,到达该时间后进行死锁检测,默认1秒。
2.lockwait_timeout
当出现表锁冲突的时候生效,当等待表锁的时间超过配置的时间,抛错返回,默认20分钟。
3.update_lockwait_timeout
当出现记录锁冲突的时候生效,如果等待记录锁的时间超过update_lockwait_timeout,抛错返回,默认2分钟。
4.ddl_lock_timeout
当出现八级表锁冲突的时候生效,当等待获取八级锁的时间超过配置的时间,抛错返回,默认值为0,表示不生效,需用户手动开启(在8.1.3版本及更高版本生效)。
在8.1.3版本中,新增加参数ddl_lock_timeout,其优先级高于lockwait_timeout。deadlock_timeout、lockwait_timeout和ddl_lock_timeout的逻辑关系如下:
构建3个元素的死锁场景如下:

首先执行第一行(按照session号从小到大执行)然后执行第二行(按照session号从小到大执行),可以通过获取对应锁的SQL语句,获得锁。表锁还可以手动的使用SQL语句的方式进行强制上锁,SQL语句的格式如下所示:
LOCK TABLE [ name ] IN [ lockmode ] MODE;其中 lockmode 可以是以下之一:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE
| SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
要注意的是LOCK语句只能在事务块中执行,事务结束会释放。
设置deadlock_timeout、lockwait_timeout和ddl_lock_timeout的值,预期如下:
1.当ddl_lock_timeout = 0,lockwait_timeout>deadlock_timeout > 0:
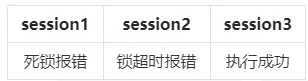
2.当ddl_lock_timeout = 0,deadlock_timeout>lockwait_timeout > 0:
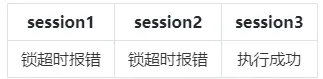
3.当ddl_lock_timeout != 0,ddl_lock_timeout>deadlock_timeout > 0:
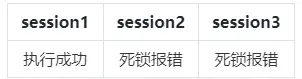
4.当ddl_lock_timeout != 0,deadlock_timeout>ddl_lock_timeout > 0:

5.当ddl_lock_timeout != 0,deadlock_timeout=ddl_lock_timeout > 0:

locktype | database | relation | page | tuple | virtualxid | transactionid | classid | objid | objsubid | virtualtransaction | pid | mode | granted | fastpath
---------------+----------+----------+------+-------+------------+---------------+---------+-------+----------+--------------------+-----------------+--------------------------+---------+----------
relation | 15835 | 11835 | | | | | | | | 13/3755 | 139776366208768 | AccessShareLock | t | t
virtualxid | | | | | 13/3755 | | | | | 13/3755 | 139776366208768 | ExclusiveLock | t | t
virtualxid | | | | | 12/38 | | | | | 12/38 | 139776382990080 | ExclusiveLock | t | t
virtualxid | | | | | 8/263 | | | | | 8/263 | 139776720103168 | ExclusiveLock | t | t
virtualxid | | | | | 7/314 | | | | | 7/314 | 139776736884480 | ExclusiveLock | t | t
virtualxid | | | | | 5/717 | | | | | 5/717 | 139776778299136 | ExclusiveLock | t | t
transactionid | | | | | | 210480 | | | | 12/38 | 139776382990080 | ExclusiveLock | t | f
relation | 15835 | 16980 | | | | | | | | 12/38 | 139776382990080 | ShareUpdateExclusiveLock | t | f
relation | 15835 | 16980 | | | | | | | | 12/38 | 139776382990080 | ShareRowExclusiveLock | t | f其中:
locktype:表示锁类型,包括表锁、事务锁、扩展锁、自定义锁等;
relation:表示表的oid,如果是表锁,relation列会显示表的oid
transactionid:表示事务号,如果是事务锁,transactionid列会显示session的事务号
mode:表示锁级别,级别1-8级;
pid:表示session的线程号;
granted:'t’表示持有锁,'f’表示等待锁;
1、pgxc_lockwait_detail系统视图,显示每个节点中锁等待链详细信息
查询语句:
select * from pgxc_lockwait_detail;
其中:
level:表示等待链中的层级,以1开始,每显示一层等待关系level会加1。
lock_wait_hierarchy:表示等待链,以节点名称:进程号->几点名称:等待进程号->节点名称:等待进程号->…。
wait_for_pid:表示锁冲突线程的线程号
conflict_mode:表示锁冲突线程持有的冲突锁级别
query:表示查询语句
2、pgxc_wait_detail系统视图,显示所有节点SQL等待从上之下的等待链详细信息,包括wait_node、query等
查询语句:
select * from pgxc_wait_detail;
level | lock_wait_hierarchy | node_name | db_name | thread_name | query_id | tid | lwtid | ptid | tlevel | smpid | wait_status | wait_event | exec_cn | wait_node | query | application_name | backend_start | xact_start | query_start | waiting | state
-------+---------------------------------------------------------+--------------+----------+-------------+--------------------+-----------------+-------+------+--------+-------+----------------------------------+------------+---------+--------------+-----------------------------------------------------------------------------------+------------------+-------------------------------+-------------------------------+-------------------------------+---------+--------
1 | cn_5002:140698314475264 | cn_5002 | postgres | OM | 144959613006392061 | 140698314475264 | 21820 | | 0 | 0 | wait node(total 3): dn_6005_6006 | | t | dn_6005_6006 | +| OM | 2022-10-08 18:02:55.810858+08 | 2022-10-08 18:03:10.478458+08 | 2022-10-08 18:02:55.819575+08 | t | active
| | | | | | | | | | | | | | | INSERT INTO scheduler.bandwidth_history_table +| | | | | |
| | | | | | | | | | | | | | | SELECT timestamp, node_name, "rxpck/s", "txpck/s", "rxkB/s", "txkB/s"+| | | | | |
| | | | | | | | | | | | | | | FROM (select '2022-10-08 18:02:55' as timestamp), PGXC_COMM_STATUS; +| | | | | |
| | | | | | | | | | | | | | | | | | | | |
2 | cn_5002:140698314475264 -> dn_6005_6006:140246537033472 | dn_6005_6006 | postgres | cn_5002 | 144959613006392061 | 140246537033472 | 1587 | | 0 | 0 | none | | f | | SELECT * FROM pg_comm_status; | cn_5002 | 2022-10-08 12:01:38.70103+08 | 2022-10-08 18:03:10.478458+08 | 2022-10-08 18:03:10.493286+08 | f | active其中:
wait_status:当前线程的等待状态
wait_event:持有此锁或者在等待此锁的事务的虚拟id
exec_cn:是否执行sql语句的cn节点
wait_node:锁级别级别
query:查询语句
backend_start:后端进程启动时间,即客户端连接服务器的时间
xact_start:当前事务的启动时间
query_start:开始当前活跃查询的时间
waiting:是否正处于等待状态
state:后端当前总体状态
tips:为保证查询链条正确,在使用pgxc_wait_detail和pgxc_lockwait_detail时不能进行排序和分组。
想了解GuassDB(DWS)更多信息,欢迎微信搜索“GaussDB DWS”关注微信公众号,和您分享最新最全的PB级数仓黑科技,后台还可获取众多学习资料哦。
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告